面向小样本的文本分类方法研究与实现开题报告
2020-02-18 20:02:09
1. 研究目的与意义(文献综述)
撰写内容要求(可加页):
1.目的及意义(含国内外的研究现状分析)
背景资料:
2. 研究的基本内容与方案
2.研究(设计)的基本内容、目标、拟采用的技术方案及措施
基本内容与目标:
(1) 通过阅读相关文献,了解小样本#65380;迁移学习#65380;文本分类#65380;主动学习等相关知识。
(2) 针对小样本训练数据容易产生过拟合问题,研究基于迁移学习的小样本文本分类方法;
(3) 收集民航员工各种社交媒体的文本信息,以分析民航员工不安全行为倾向为目标,寻找易于迁移学习的源域数据,并分析源域与目标域数据的特征与关联关系,从而构建面向民航员工不安全行为倾向分析的文本分类迁移学习模型并验证其有效性。
拟采用的技术方案及措施:
1.搭建普通文本分类模型:
(1).获取中文的类别标注文本数据。
从新浪微博,知乎,豆瓣,贴吧,微信,QQ等平台通过爬虫或者人工手段获取3000条左右的民航从业者的社交网络文本数据,人工进行类别的标注。并将其中2000条作为训练集,剩下的1000条作为测试集。
(2)特征向量化:
=1 * GB3 ①读入数据框处理工具pandas,利用pandas的csv读取功能,把数据读入,并且将特征和标签分开 = 2 * GB3 ②利用jieba分词拆分句子为词语 import jieba , 建立一个辅助函数,将分词的结果用空格连接起来。 = 3 * GB3 ③编写一个函数,从中文停用词表里面,把停用词作为列表格式保存并返回。读入CountVectorizer向量化工具,它依据词语出现频率转化向量。转换已经分词的训练集语句,并且将其转化为一个向量矩阵。 = 4 * GB3 ④采用哈尔滨工业大学和百度公司联合发布的中文停用词汇表https://github.com/chdd/weibo/tree/master/stopwords进行过滤,得到新的向量矩阵。
表 1 文本数据向量化
| I | love | hate | the | game |
| 1 | 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
(3) 利用生成的特征矩阵来训练模型:
使用python机器学习框架scikit-learn。scikit-learn框架的许多模型都可以用来处理分类问题。逻辑回归、决策树、SVM、朴素贝叶斯……图1 来自https://scikit-learn.org,是不同模型适应处理的问题。由于我们要处理类别问题,数据有标记,数据lt; 100k,并且是文本数据,于是选用朴素贝叶斯模型进行训练。
fromsklearn.naive_bayes import MultinomialNB
nb= MultinomialNB()
等待训练完成。
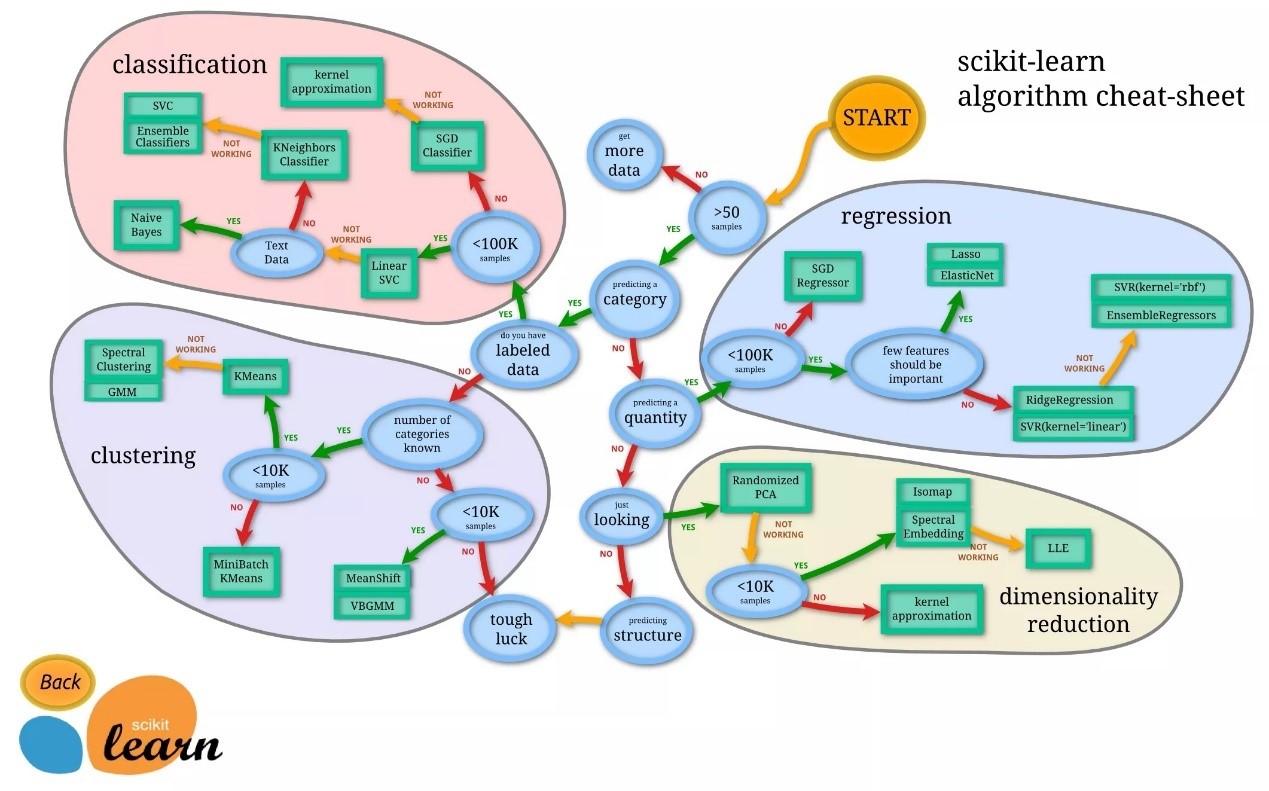
图 1 机器学习框架scikit-learn
2.搭建迁移学习文本分类模型:
(1)载入语言模型数据和分类模型数据,进行标记化和数字化预处理:
=1 * GB3 ①使用!wget命令载入文本数据集,使用!tar命令来进行解压缩 = 2 * GB3 ②从fast.ai 调用一些模块,来获得一些常见的功能:
fromfastai import *
fromfastai.text import *
fromfastai.core import *
=3 * GB3 ③设置 path 指向数据文件夹。
=4 * GB3 ④把数据读入:
data_lm= TextLMDataBunch.from_csv(path, valid='test')
data_clas=TextClasDataBunch.from_csv(path,valid='test',vocab=data_lm.train_ds.vocab)
(2)读入预训练参数,训练并且微调语言模型:
=1 * GB3 ①使用fast.ai 自带的预训练语言模型wt103_v1,下载获取语言模型预训练参数 = 2 * GB3 ②构建一个RNNLearner ,来生成我们自己的语言模型。 = 3 * GB3 ③对预训练的模型参数进行冻结使用“歧视性学习速率”(discriminativelearning rate)进行微调。(既保证靠近输入层的预训练模型结构不被破坏,又尽量让靠近输出层的预训练模型参数尽可能向着我们自己的训练数据拟合。) = 4 * GB3 ④保存训练好的语言模型参数
(3)用语言模型调整后的参数,来训练分类模型:
构建一个新的RNNlearn 将分类模型数据和保存好的语言模型参数套用到分类模型里。
(4)微调分类模型。
将分类模型进行解冻和微调,同样采用的是“歧视性学习速率”。
learn.unfreeze()
learn.fit_one_cycle(1,slice(2e-3/100, 2e-3))
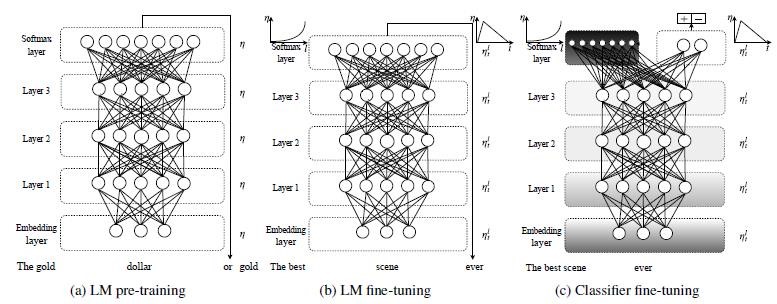
图 2 语言模型和分类模型微调
3.实验以及结果分析
测试数据集采用上述的1000条文本数据,对每条文本,输入模型并且输出分类结果。类别包括:
表2文本数据类别
| 类别 | 描述 |
| 生理问题 | 生理问题人员是指身体突发疾病或职业禁忌症,不适合工作,或者身体虚弱的人员 |
|
心理薄弱 |
心理薄弱包括精神状态不佳、心理压力大、对工作并没有、责任心不强、意志力欠佳等。 |
|
情绪不稳定 |
这类人员是指由于一些原因导致情绪不稳定的人员,导致情绪不稳定的原因有许多,包括家庭变故、失恋、夫妻不和、上下级或同事间出现矛盾等等。 |
续表2
|
技能知识欠缺 |
转岗调岗的职工和刚入职不久的新员工容易成为此类人员,转岗调岗的职工和新员工刚到新的工作岗位不久,各种操作技能都不太熟悉,一些知识可能还没有完全掌握。 |
|
安全意识薄弱 |
这类人员往往不把安全放在心上,心存侥幸,认为违规操作不一定能造成事故。一旦习惯了违规操作,在面对危险时,就会惊慌失措。 |
|
预知危险能力不足 |
这类人员经常忽视生产活动中存在的潜在风险,麻痹大意。当出现危险时,不能进行正确的判断,进而做出错误的决定,酿成事故。 |
|
态度不端正 |
这类人员往往不能明确自己的定位,认为工作是给别人做的,在工作中表现为粗心大意,懒散或消极怠工,很容易发生失误和事故。 |
如果不属于其中任何一个类别,则输出”其他类别”。输出类别和预先人工标注的类别进行比较,假设样本x1的真实分类是Class1,它的预测结果有N种可能( {Class1,Class2, ..., ClassN}中的任何一个)。但是不管预测结果如何,从预测与真实的符合程度来看,只有两种可能: 预测正确 (被预测为Class1),和 预测错误 (被预测为Class1之外的任何一类)。当一个测试集全部被预测完之后, 会有一些实际是Class1 的样本被预测为其他类,也会有一些其实不是Class1 的样本,被预测成Class1 ,这样的话就导致了下面这个结果:
表 3 预测结果指标
|
| 预测结果为Class1(Positive) | 预测结果非Class1(Negtive) |
| 预测结果真实(True) | Class1_TP | Class1_TN |
| 预测结果虚假(False) | Class1_FP | Class1_FN |
根据上表,我们就可以计算:
Class1的准确率:
![]()
即在所有被预测为Class1的测试数据中,预测正确的比率。
Class1的召回率:
R=TPTP FN![]() (2)
(2)
即在所有实际为Class1的测试数据中,预测正确的比率。
Class1的F1值:
F1=2×P×RP R![]() (3)
(3)
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值:
![]() (4)
(4)
微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标:
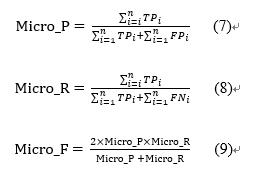
最后得到的宏平均和微平均便代表着模型分类的整体性能。
对“普通文本分类模型”和“迁移学习文本分类模型”,分别求宏平均和微平均数,进行大小比较,得出迁移学习对文本分类的影响和作用。
3. 研究计划与安排
(1) 2019/1/14—2019/2/22:明确选题,查阅相关文献,外文翻译和撰写开题报告;
(2) 2019/2/23—2019/4/30:系统架构,系统设计与开发(或算法研究与设计)、系统测试、分析、比较与完善;
(3) 2019/5/1—2019/5/25:撰写论文初稿;修改论文,定稿并提交论文评审;
4. 参考文献(12篇以上)
4.阅读的参考文献不少于15篇(其中近五年外文文献不少于3篇)
[1] howard j, ruder s. universallanguage model fine-tuning for text classification[c]//proceedings of the 56thannual meeting of the association for computational linguistics (volume 1: longpapers). 2018, 1: 328-339.
[2] wang z, qu y, chen l, et al. label-awaredouble transfer learning for cross-specialty medical named entityrecognition[c]//proceedings of the 2018 conference of the north americanchapter of the association for computational linguistics (volume 1: longpapers). 2018: 1-15.



