基于深度学习的疲劳驾驶检测方法研究毕业论文
2020-02-19 07:53:24
摘 要
随着公路交通的不断发展以及车辆持有量的日益提高,交通事故也日益频繁发生,交通事故不仅会造成财产的损失,更会造成人员的伤亡,给社会上的许多家庭带来不幸与痛苦。由我国交通委调查得知,由于疲劳驾驶导致的交通事故已渐渐成为交通事故的第二大诱因。因此对于我国驾驶员疲劳驾驶检测具有重要意义。
本文首先着重讨论适用于疲劳驾驶检测技术的多种算法并选取其中的KNN算法和HOG SVM算法进行深入研究,比较两种算法的难易程度以及正确率与实现方法。随后本文借助python开发环境pycharm软件,采用py-opencv库处理人脸图像,采用KNN算法进行图片的对比与分类,实现对于驾驶员状态的检测与分类,并随后对测试集进行正确率检测,匹配输出结果与原分类的重合率,从而对结果进行分析。并在opencv上完成了HOG SVM的实现。实验结果表明,训练出的SVM模型具有较高的准确率,在我们选用的测试集中,正确率达到83%。
关键词:深度学习;KNN;HOG;SVM;疲劳驾驶检测
Abstract
With the continuous development of highway traffic and the increasing vehicle ownership, traffic accidents also occur more and more frequently. Traffic accidents not only cause the loss of property, but also cause casualties and bring misfortune and pain to many families in the society.According to the investigation of China's transportation commission, traffic accidents caused by fatigue driving have gradually become the second leading cause of traffic accidents.Therefore, it is of great significance for driver fatigue test in China.
This paper first focuses on the discussion of various algorithms applicable to fatigue driving detection technoHOGy and selects KNN algorithm and HOG SVM algorithm among them for in-depth understanding and learning, and compares the difficulty, accuracy and implementation methods of the two algorithms.Subsequently, this paper USES the python development environment, pycharm software, py-opencv library to process face images, and KNN algorithm to compare and classify images to realize the detection and classification of driver state. Then, the test set is detected for accuracy, and the coincidence rate of matching output results with the original classification is matched, so as to analyze the results.HOG SVM is implemented on opencv.
Keywords: deep learning;KNN.The HOG.The SVM;Fatigue driving test
目录
第1章 绪论 1
1.1研究背景及意义 1
1.2国内外研究现状 2
1.3论文内容和结构 3
第2章 深度学习算法的检测与研究 4
2.1邻近算法 KNN 4
2.1.1KNN算法的简单介绍 4
2.1.2算法计算步骤 4
2.1.3 空间内距离计算方法 5
2.1.4 KNN算法中的常见问题 5
2.1.5 KNN算法的优缺点 6
2.1.6 KNN 算法的改进方法 7
2.2 HOG特征 7
2.2.1 HOG特征整体流程 8
2.2.2 分割图像 8
2.2.3 计算每个区块的方向梯度直方图 9
2.2.4 组成特征 9
2.3 SVM支持向量机 9
2.3.1支持向量与超平面 9
2.3.2最大间隔 10
2.4 本章小结 11
第3章 KNN与HOG SVM实验设计 12
3.1数据集与训练环境的简单叙述 12
3.2 KNN的具体实现 12
3.2.1 KNN分类器的初步实现 13
3.2.2 KNN分类器的最终实现 13
3.3 HOG SVM的具体实现 13
3.4 本章小结 14
第4章 实验结果分析 15
4.1 KNN实验结果分析 15
4.1.1 KNN初步实验结果 15
4.1.2 KNN最终实验结果 17
4.1.3 KNN实验结果分析 19
4.2 HOG SVM实验结果分析 19
4.2.1 HOG特征可视化结果 19
4.2.2 SVM实验结果 20
4.2.3 SVM实验结果分析 20
4.3 KNN实验结果与HOG SVM实验结果对比 20
4.4 本章小结 21
第5章 总结与展望 22
5.1本文总结 22
5.2工作展望 22
参考文献 23
附录A pycharm下的KNN分类器代码 24
附录B opencv下的HOG SVM分类器代码 30
致谢 36
第1章 绪论
1.1研究背景及意义
随着人类进入到21世纪,科学技术有个爆发式的增长,人们在生活的各个阶段有个质的飞跃,其中就包括了交通工具的发展,人们在追求交通工具的快速便捷的同时也应该更加注重安全性。而随着每年私家车数量的不断增加每年的交通事故也在不断的增长,交通事故的频发不仅给我们生活带来不便,更多的带来了财产上的重大损失甚至带来了人身安全的重大事故,而众多交通事故中,因为疲劳驾驶而导致的交通事故更为严重,大多数因疲劳驾驶产生的交通事故多发于高速公路,造成的交通事故导致的一般为连环车祸,事态严重者甚至上百车连环追尾,造成重大人员伤亡与财产损失。随着我们经济的增长,社会需求的提高,人们生活质量越来越好,我国机动车保有量持续上升,导致潜在交通威胁增加,交通事故基数增大,但是伴随着快速增加的机动车保有量来说,人们驾驶机动车的安全意识并没有与快速增加的机动车上升速度相匹配。据公安机关统计,截止到2018年年底机动车保有量达到3.27亿辆。在世界范围内,每年有上百万人因交通事故失去生命,每年因交通事故造成的人员伤亡达到两千万至五千万。下表为我国2007年到2017年交通事故相关数据汇总。
表1.1 2007-2017年交通事故数据汇总
年份 | 交通事故(起) | 死亡人数(人) | 受伤人数(人) | 直接经济损失(亿元) |
2007 | 327209 | 81649 | 380442 | 11.99 |
2008 | 265204 | 73484 | 304919 | 10.10 |
2009 | 238351 | 67759 | 275125 | 9.14 |
2010 | 219521 | 65225 | 254075 | 9.26 |
2011 | 210812 | 62387 | 237421 | 10.79 |
2012 | 204196 | 59997 | 224327 | 11.75 |
2013 | 198394 | 58539 | 213724 | 10.39 |
2014 | 196812 | 58523 | 211882 | 10.75 |
2015 | 187781 | 58022 | 199880 | 10.37 |
2016 | 212846 | 63093 | 226430 | 12.08 |
2017 | 203049 | 63772 | 209654 | 12.13 |
由表1.1数据可知,从2007年起,每年我国由交通事故造成的直接经济损失基本位于10亿元以上,近年来直接经济损失明显上升,而引起交通事故的诱因中,疲劳驾驶已经跃入第二位,因此,解决疲劳驾驶引起的交通问题具有重大意义[1]。近年来,随着人工智能的不断发展,深度学习的越来越热门,人工智能与机器学习越来越多的渗透到我们的生活中。目前,谷歌、Facebook、微软等国际公司以及腾讯、阿里巴巴、百度等国内公司都投入了大量精力与财力来开发人工智能与机器学习。因此,研究基于深度学习的疲劳驾驶检测技术对于减少交通事故、减少经济损失、保障人身安全具有重要意义。
1.2国内外研究现状
国外对于疲劳驾驶检测的研究是从20世纪80年代开始的,现阶段国外已推出多款疲劳驾驶检测装置。
例如,来自美国Attention TechnoHOGies 的DD850是基于驾驶员生理反应特征的驾驶员疲劳监测和警报产品。该产品通过红外摄像头采集驾驶员的眼睛信息,采用PERCLOS作为疲劳报警指标,可直接安装在仪表板上,可以调节报警灵敏度和报警音量。
由美国Digital Installations 开发的S.A.M.疲劳报警装置使用放置在方向盘下的磁条来检测方向盘角度。如果驾驶员在一段时间内没有对方向盘进行任何修正,系统会判断驾驶员是否疲劳并发出警告。
美国的AssistWare技术公司的safeTRAC使用前置摄像头识别车道线路,并在车辆离开车道时发出警报。通过将车道保持状态与方向盘操作特性相结合,该产品还可以用来确定人的疲劳状态。
欧盟的AWAKE项目检测并记录了人眼生理反应信息、方向盘操作转角信息、方向盘转向力信息和车道线信息。利用信息融合技术实现驾驶员疲劳分级评估,利用声音、灯光闪烁和安全带振动实现疲劳预警。
英国的ASTiD Driver Alert考虑驾驶员睡眠信息的睡眠持续时间和类型,以及驾驶员方向盘以确定驾驶员的疲劳状态。该设备要求用户提前24小时输入睡眠信息。当视觉警报达到一定水平时触发声音警报。
外国开发商已经推出了一个名为DriveSafe的谷歌眼镜特定程序,它可以通过设备上的传感器检测到驾车者在驾车过程中出现的分心或打瞌睡的现象,然后它向佩戴者发出警报声音或在眼镜的屏幕上显示一些动画提示。
国内疲劳驾驶检测起步晚,目前还在探索阶段,只有有限已商业化的产品。相对来说国外研究已比较成熟,值得我们借鉴。
gogo850是一种疲劳驾驶预警系统,已在中国商业化。它主要检测驾驶员的眼睛开合情况。
1.3论文内容和结构
本文的章节安排如下:
第一章阐述疲劳驾驶检测的背景以及研究意义。简单阐述了疲劳驾驶检测在日常生活中的重要性以及疲劳驾驶检测检测的发展历史。
第二章对疲劳驾驶检测深度学习的方法进行了介绍。着重介绍了深度学习中的KNN邻近算法与HOG SVM算法。阐述了其具体内容及其实现原理。
第三章对KNN与HOG SVM的具体实现做出了介绍。
第四章重点介绍了KNN与HOG SVM的实验结果说明,并就两种方法做出了对比与准确度的总结。
第五章为对全文的总结与对未来发展的展望。
第2章 深度学习算法的检测与研究
在深度学习中,存在许多的算法,较为常用的就是邻近算法KNN与支持向量机SVM[2],下面我们介绍两种算法以及其各自优缺点。
2.1邻近算法 KNN
2.1.1KNN算法的简单介绍
邻近算法KNN[3]是机器学习中相对简单的算法。所谓邻近算法是在一个样本空间中,计算样本点与其他所有点的距离,然后从中取出前K个距离,统计前K个距离中所属类别最多的类别,即为该样本点所属类别,下面通过图示更为清楚的展示邻近算法KNN的具体内容。
如图2.1所示,如果样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。
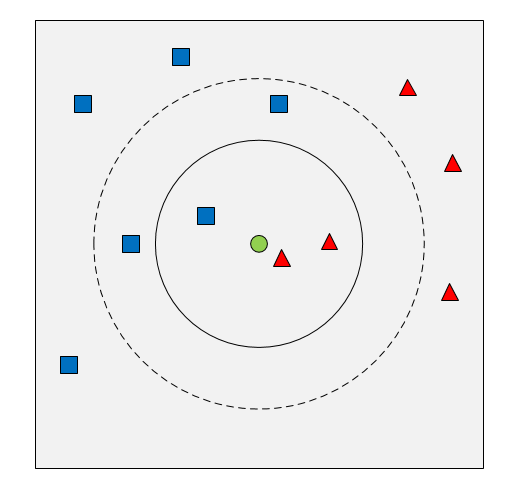 如果K=3时,该样本属于红色方,如果K=5时,该样本属于蓝方。KNN算法比较简单,根据阅读文献,由KNN算法构成的分类器准确率大概为85%左右。
如果K=3时,该样本属于红色方,如果K=5时,该样本属于蓝方。KNN算法比较简单,根据阅读文献,由KNN算法构成的分类器准确率大概为85%左右。
图2.1 KNN算法原理示意图
2.1.2算法计算步骤
1. 准备数据并预处理数据
2. 使用适当的数据结构来存储训练数据和测试元组
3. 设定参数,如k
4.维护大小为k的优先级队列,从大到小,用于存储最近邻训练元组。从训练元组中随机选取k个元组作为初始的最近邻元组,计算测试元组到这k个元组的距离,并将训练元组标号和距离存入优先级队列中
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若Lgt;=Lmax,则舍弃该元组,遍历下一个元组。如果L lt; Lmax,删除优先级队列中最大距离的元组,则将当前训练元组保存到优先级队列中
7. 遍历完成后,计算优先级队列中k 个元组的多数类,并将其用作测试元组的类别
8. 测试元组集测试完毕后,计算误差率,继续设定不同的k值并重新训练,最后取出具有最小误差率的k 值
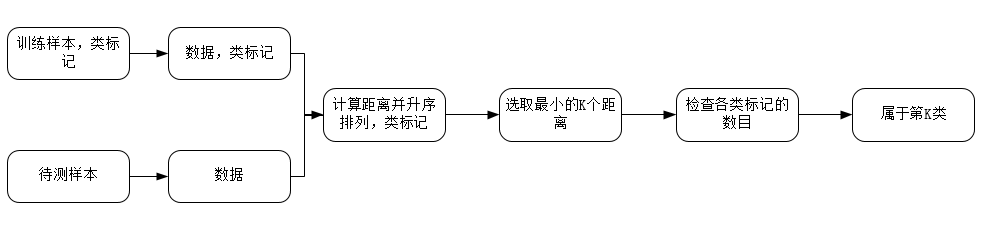
图2.2 KNN流程图
2.1.3 空间内距离计算方法
在KNN中,用空间内两点的距离来度量两点之间的相似程度,距离越大,相似程度约低,距离的计算方法有很多,但一般采用欧式距离作为计算距离的方法,下面介绍常用的距离计算方法[4]。
1.欧式距离:欧式距离为计算两个样本之间数据的平方差。
(2.1)
2.马氏距离:马氏距离是表示数据协方差的距离。
(2.2)
3.曼哈顿距离:曼哈顿距离是两个向量之间数据差异的绝对和。
(2.3)
4.切比雪夫距离:切比雪夫距离是两点之间每个坐标值差的绝对值的最大值。
(2.4)
2.1.4 KNN算法中的常见问题
- K的取值
K的取值一直以来是KNN分类器的热门讨论话题,根据经验来说,一般K的值小于样本的平方根。下面我们来介绍K值取大和取小之后各有什么后果:
- K值偏大:当K值过大之后,如果此时我们的样本数并不多,这时候可能相似度较差的样本也被包含进来,造成了分类准确度的降低。
- K值偏小:当K值偏小时,由于选取的邻近样本数过少,同样也会导致分类准确度的降低。
- 训练样本的选取
为了减少计算量与提高准确率,我们对训练集进行研究,我们对训练集做了两方面的处理。第一方面,我们对训练集的准确度进行了改进,我们从中选取我们需要的更为精准的训练集,剔除一些不适用,不同类的训练样本。第二方面,我们对训练集的特征做出一些提取与放大,突出特征,降低错误率。
- 计算量的问题
因为KNN是一种惰性算法,构成模型简单,因此KNN算法计算量大。KNN算法需要计算检测样本与所有训练集样本的欧式距离,当训练集增大一个数量级,或者训练样本偏大时,这种计算量会称指数上升,迅速增长。
- 空间内距离计算方法的选择
目前KNN算法计算空间内的距离,大部分选取的为欧式距离,其他距离选用的并不多。
2.1.5 KNN算法的优缺点
1.优点:
1).理论成熟,思想简单,可以用于非线性分类
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: