机器阅读理解技术研究毕业论文
2020-02-19 18:16:29
摘 要
机器阅读理解是自然语言处理中的非常重要也非常难的一个任务,其任务是阅读和理解给定的文本段落,然后基于它回答相关问题。这项任务十分具有挑战性,需要全面了解自然语言以及在此基础上进行进一步推理。近几年来,随着由百度推出的DuReader数据集的发布,掀起了对中文语言的机器阅读理解的一股热潮,本文将采用DuReader阅读理解数据集,对中文机器阅读理解做了相关研究。论文主要研究了基于深度学习的中文机器阅读理解的相关技术,以及对中文自然语言处理的相关知识并进行了相关模型实验。论文研究了BiDAF和Match-LSTM两种流行且比较先进的机器阅读理解模型,研究结果表明,由于BiDAF模型采用了双向注意力机制等技术,相比于Match-LSTM效果会更好。因此本文重点对BiDAF模型进行了研究,并使用DuReader数据集进行了训练和评估。
关键词:机器阅读理解;自然语言处理;深度学习;中文语言
Abstract
Machine reading comprehension is a very important and very difficult task in natural language processing. Its task is to read and understand a given paragraph of text, and then answer relevant questions based on it. This task is very challenging and requires a comprehensive understanding of natural language and further reasoning on this basis. In recent years, with the release of the DuReader dataset launched by Baidu, it has set off a wave of machine reading comprehension in Chinese language. This article will use DuReader to read and understand the data set, and do research on Chinese machine reading comprehension. The thesis mainly studies the related techniques of Chinese machine reading comprehension based on deep learning, as well as related knowledge of Chinese natural language processing and carries out related model experiments. This theses studies two popular and advanced machine reading comprehension models of BiDAF and Match-LSTM. The results show that the BiDAF model uses a two-way attention mechanism and other techniques, which is better than Match-LSTM. Therefore, this theses focuses on the BiDAF model and uses the DuReader dataset for training and evaluation.
Key Words:machine reading comprehension; natural language processing; in-depth learning; Chinese language
目 录
第1章 绪论 1
1.1 研究背景以意义 1
1.2 国内外研究现状 2
1.3 研究内容及结构安排 3
第2章 机器阅读理解相关技术研究 4
2.1 神经网络架构 4
2.1.1 卷积神经网络 4
2.1.2 双向长短记忆神经网络 5
2.2 自然语言处理研究 6
2.2.1 中文自动分词 6
2.2.2 词向量实现 8
2.3 本章小结 9
第3章 数据集的构建 10
3.1 数据集来源 10
3.2 数据处理 11
3.3 本章小结 13
第4章 基于深度学习的机器阅读理解方法对比分析 14
4.1 方法选取及对比 14
4.2 深度学习网络结构及训练 15
4.2.1 网络结构 15
4.2.2 模型训练 18
4.3 实验结果和分析 19
4.3.1 评估标准 19
4.3.2 实验环境 21
4.3.3 实验步骤 21
4.3.4 性能评估与分析 21
4.4 本章小结 22
第5章 总结与展望 23
5.1 总结 23
5.2 展望 23
第1章 绪论
1.1 研究背景以意义
阅读理解对于大多数人来说是一个很普遍的问题,人们从小学的时候就会接触各式各样的英文或中文阅读理解。而机器阅读理解类似于人们所做的阅读理解,机器阅读理解(MRC)是自然语言理解中的关键问题之一,其任务是阅读和理解给定的文本段落,然后基于它回答问题。这项任务具有挑战性,需要全面了解自然语言以及在此基础上做进行进一步推理。在所有的人工智能领域,自然语言处理应是最难解决的一个领域,而作为自然语言处理中的关键问题,机器阅读理解,其重要性不言而喻。
让机器阅读文本并理解语义是自然理解语言的重要一步。自然语言理解在人工智能的领域也具有“明珠”的美誉。自人工智能概念出现以来,许多人工智能研究人员都希望机器可以理解语言并且像人们一样用语言进行交流。随着深度神经网络的兴起,人工智能也带来了新的活力。自然语言理解作为人工智能领域长久以来无人力及的明珠,也藉由大规模数据集的出现和计算能力的急剧提升,达到了前所未有的研究热度,无论在学术界还是工业界,成为人工智能领域的必争之地。由此可见,机器阅读理解本身具有极其重要的研究意义。
机器阅读理解任务,通常可以将它分成三种类型:
(1)完型填空型机器阅读理解任务。
(2)答案抽取型机器阅读理解任务。
(3)答案选择型机器阅读理解任务。
第一种任务,顾名思义,就是给定一篇文章,文章中的一个或多个地方的词被挖空,需要读者在空白处填入一个合适的词;或者给定一篇完整的文章,然后给定一个问题,从文章中选择一个词或短语填入空白处。对于这一类任务,现有的数据集有:CNN/Daily Mail[1]数据集、Children 's Book Test(CBT)[2]数据集等。使用的模型有AS Reader[3]等。第二类任务,答案抽取型机器阅读理解任务是指给定一篇文章和一个问题,需要从文章中选取词或短语,作为回答该问题的答案。当然,这个答案也有可能无法从原文中直接获取到,或者需要通过多篇文章才能够获取到完整的答案。对于这一类任务,现有的数据集有:MS MARCO[4]数据集、SQuAD[5]集、中文的则是DuReader[6]数据集等。使用的模型有:BiDAF[7]模型、Match-LSTM[8]模型等。第三类任务,与答案检索任务(如WikiQA、 TrecQA等)有些类似,就是给定一个问题,然后在一个固定的答案集中寻找正确答案。不过与后者不同的是,机器阅读理解在回答问题时,还需要结合给出的文章,通过文章来选取正确的答案,而不是单纯地判断问题和答案是否相关,或者答案是否回答了这个问题。因为这个任务的目的是要选择回答该问题的答案,而不是选择“看似正确”的答案。此类的数据集主要有:RACE[9]数据集等。
1.2 国内外研究现状
自二十一世纪起,深度学习出现在人们眼中,机器阅读理解这一自然语言处理的终极任务也同样回归到世人眼中。自2012年后,深度学习开始进入蓬勃的发展期,机器阅读理解也包括在内。到了2015年由Karl Moritz Herman等人[1]发布了完形填空式英文机器阅读理解数据集CNN/Daily Mail,该数据集是通过网络爬虫爬取美国有线电视新闻网和《每日邮报》新闻数据集构建而成。
接下来的几年,出现了如上节所介绍的各式各样的数据集以及模型,而其中本节针对其中三种比较火热的数据集以及相应的机器阅读理解模型展开阐述,前两者属于英文数据集,最后一个属于中文数据集:
- 斯坦福问答数据集(SQuAD)
该数据集于2016年由Pranav Rajpurkar等人[5]提出,并作为公榜比赛允许大家提交自己的模型,给出排名。该数据集的每一个样本都会提供一个问题和一篇文章,约有10万个问题,以及包含了536篇文章(一篇文章包含多个不同的问题)。一年后由Minjoon Seo等人针对SQuAD[5]数据集提出了BiDAF[7]模型,本文第四节将会重点介绍该模型。到了2018年,谷歌的AI团队又提出了一种BERT模型,这一模型的出现有的人称之为NLP上的里程碑。该模型在SQuAD1.1中的成绩非常好:在官方所给的两个衡量指标上都已经全面超越人类,并且同时也在多种其他阅读理解任务中取得了优秀的成绩,该模型目前仍排在榜首。
- 微软阅读理解数据集(MS MARCO)
该数据集由微软的Tri Nguyen等人[4]提出,其包含了1,010,916个取样于Bing搜索的查询日志的匿名问题,其中每一个问题都是人为生成的答案并且有182,669个完全是人为重写的答案。除此之外,该数据集内包含了8,841,823个段落,这些段落是从Bing检索到的3,563,535个网络文档中所提取出来的,并且这些段落提供了必要的信息来组成自然语言答案。相比于SQuAD[5],MS MARCO[4]数据集比SQuAD[5]大十倍以上,如果想要对大型深度学习模型进行基准测试,这将非常重要,同时SQuAD[5]中的问题是根据所选定的答案块而编辑生成的,而在MS MARCO[4]中,问题是从Bing 的查询日志中采样的。因此MS MARCO[4]会比SQuAD[5]更具有挑战性。同时在模型方面,微软公司也提出了比BiDAF[7]评分更高的R-Net模型,相比于BiDAF[7]模型,R-Net模型主要在问题与答案的交互层有所不同。同样在2018年,猿辅导公司提交了MARS(Multi-Attention ReaderS)模型[1],并登顶微软MS MARCO[4]机器阅读理解测试排行。
- 百度中文阅读理解数据集(DuReader[6])
该数据集为目前最大的面向现实世界的大型开放域中文机器阅读理解数据集,由百度搜索和百度知道的真实应用数据所构建。由于在国内,相关技术相比于国外开展的较晚,因此DuReader[6]数据集的出现填补中文数据集在机器阅读理解领域的一个空缺。针对该数据集中国的奇点机智公司提出了NI-Reader模型[2]并最后以ROUGE-L:63.38%,BLEU-4:59.23%的评分夺得2018年百度机器阅读理解竞赛的冠军。该比赛也同样使中文机器阅读理解开始追赶英文,在未来的时间里也会继续发展。
1.3 研究内容及结构安排
由上文所述可知,中文机器阅读理解起步晚,发展比英文慢,但是这两年有也开始逐渐兴起,因此本文主要对中文机器阅读理解进行了相关研究。作为世界上最复杂的语言,其具有没有分词,语义多重复杂等难度。因此相比于英文机器阅读理解,中文更具有挑战性,为了研究中文机器阅读理解,本文做了以下工作:
(1)利用百度发布的DuReader[6]数据集作为本文数据集,并进行了相关数据清洗以及训练集验证集的格式制作。
(2)研究了两种相关的神经网络以及中文自然语言处理的相关基础技术。
(3)重点研究了BiDAF[7]模型,并使用Tensorflow将其实现,并使用服务器对完整数据集进行了训练和评估。
(4)同时实现了Match-LSTM[8]与BiDAF[7]并做了对比,并调整神经网络的超参数获得不同的结果进行了对比。
本文共分为五章,各章节的内容安排如下:
第1章概述了机器阅读理解的背景意义以及种类,并以三种典型数据集分别简述了近几年国内外现状以及相关技术的发展情况。
第2章研究了两种相关的神经网络、中文自动分词和词向量的实现为后文做下理论基础。
第3章介绍了本文使用的数据集的处理。
第4章实现了基于BiDAF[7]模型的机器阅读理解方法,并对其进行了训练,接着与Match-LSTM[8]模型进行对比。
第5章总结了本文的工作,总结实验的局限性,以及对未来工作进行展望。
第2章 机器阅读理解相关技术研究
2.1 神经网络架构
在介绍本文使用的模型之前,会使用到以下两种常见的神经网络架构,卷积神经网络和长短记忆单元。卷积神经网络通常在图片处理领域使用广泛,最近也被应用在自然语言处理。而在本文的模型中将会使用由卷积神经网络构成的字符级CNNs[12]对字向量编码层进行处理将每个字映射到向量空间;而长短记忆单元在上下文编码层和建模层多次被使用,因此也是本文所介绍的模型的核心模块之一。本节将分别介绍两者。
2.1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN),是一种特殊的神经网络,于1998年由纽约大学的Yann LeCun所提出[13]。一般的卷积神经网络包含输入层、输出层,中间的隐藏层由卷积层、池化层、全连接层和正则化层组成。卷积神经网络中的卷积层本质上还是一个多层感知机,只是它采用了稀疏连接、参数共享和等变表示的方式,这使得CNN能够学习数据的局部特征,并在深层网络中展现全局特征,而且共享权值的方式有效减少了需要学习的参数数量,降低了过度拟合的风险。CNN是一种类似于生物神经网络的特殊的神经网络,其特点是权值共享,网络复杂度低,权值数量少。CNN通常用于解决输入为多维图像的问题,并使图像直接输入到神经网络,而不用像传统方法一样去进行特征提取和数据重建。本节将介绍其中的卷积层、池化层。
- 卷积层
卷积层通常用于提取特征,其使用滑窗的方式在原图中实现,在原图里,利用卷积核在每个位置分别做乘积再求和,接着以相应的步长移动,得到N×N的卷积层。这里有计算N的公式,N =(W-F 2P)/S 1,在这其中W为输入单元的大小(宽或高),F为感受野(receptive field),S为步长(stride),P为补零(zero-padding)的数目,K为输出单元的深度。如图2.1所示,W=4,F=3,P=0,S=1,由公式计算可知N=2,即生成一个2×2的特征图。
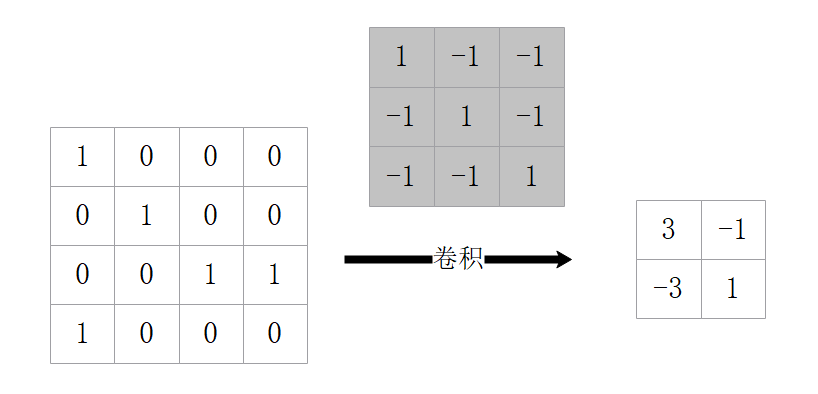
图2.1 卷积层示意图
- 池化层
池化(Pooling)弥补了卷积网络学习局部特征而没有顾及全局特征的缺陷。通过池化,可以整合从卷积层编码出的局部特征,可以有效地保持某些特征的不变性。如图2.2所示分别为最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化是指对邻域内特征点取最大值,而平均池化是取平均值。
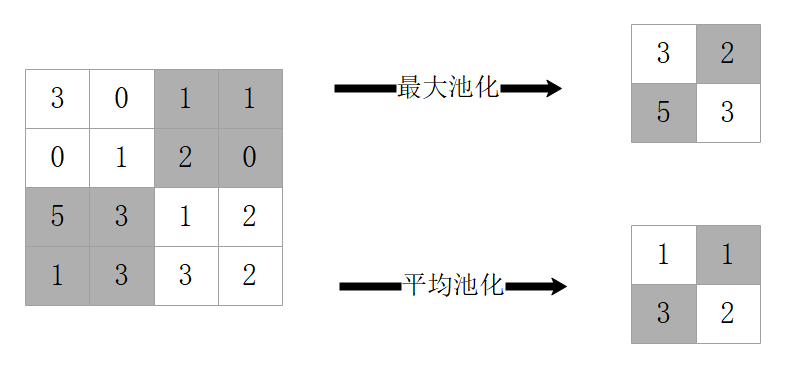
图2.2 池化层示意图
2.1.2 双向长短记忆神经网络
双向长短记忆单元(Bi-directional Long Short-Term Memory,BiLSTM)[14],是由前向LSTM与后向LSTM组合而成,是一种特殊的RNN。在自然语言处理任务中都通常被用来建模上下文信息。
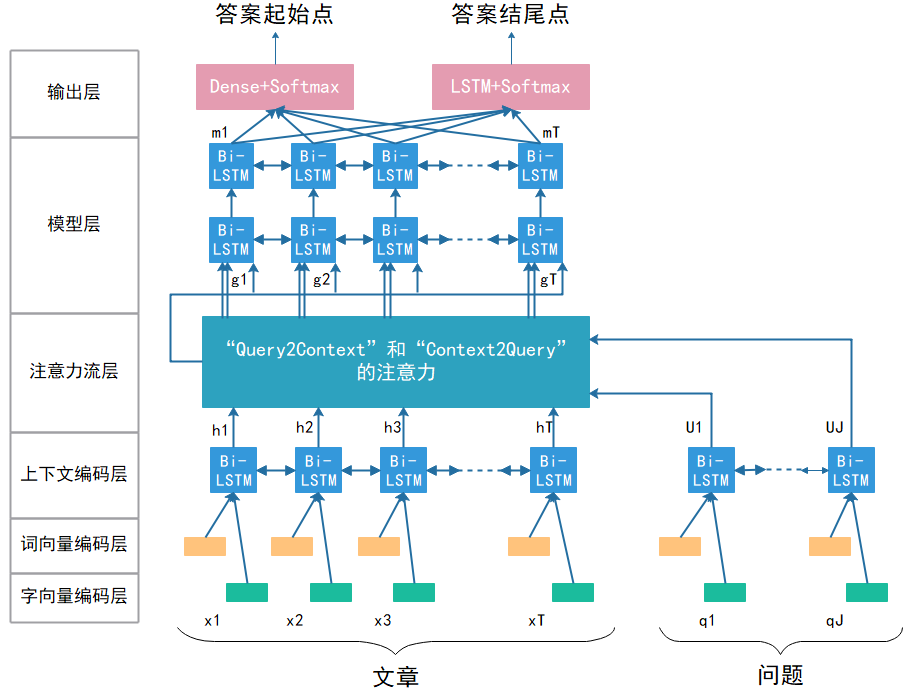
LSTM与一般的RNN相比,LSTM引入了用于内部的自循环的权重,这个权重是根据上下文而改变的。通过对该自循环单元进行门控操作,可以有效控制有用信的流动,尽量减少噪声信息,从而动态地累计所需要的信息。如句子“我不认为这是对的”。“不”字是对后面“对”的否定,即该句子的情感极性是贬义。LSTM模型对于长距离的依赖关系就较好的把握性,因为LSTM模型在训练的过程中会进行选择性记忆相关信息。但是LSTM也具有其局限性,那就是没有考虑到词语在句子中前后顺序,即考虑不到后文对前文的影响。如句子“这个学校大得惊人”,“惊人”一词是对“大”的程度的一种修饰,这时若采用BiLSTM[14]就可以捕捉到双向的语义依赖。BiLSTM[14]的模型图如图2.3所示:
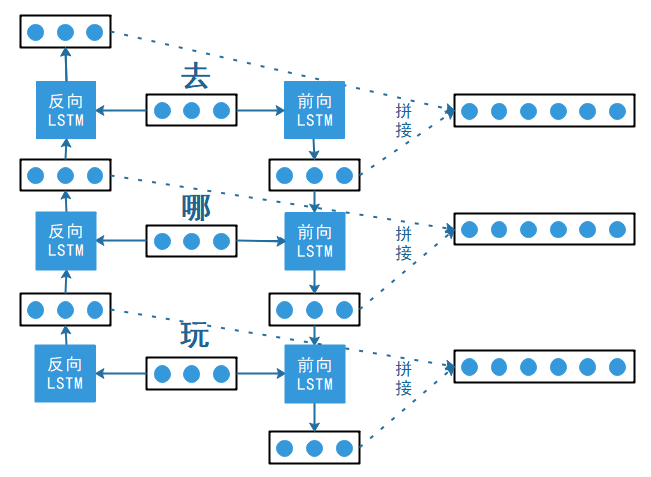
图2.3 BiLSTM示意图
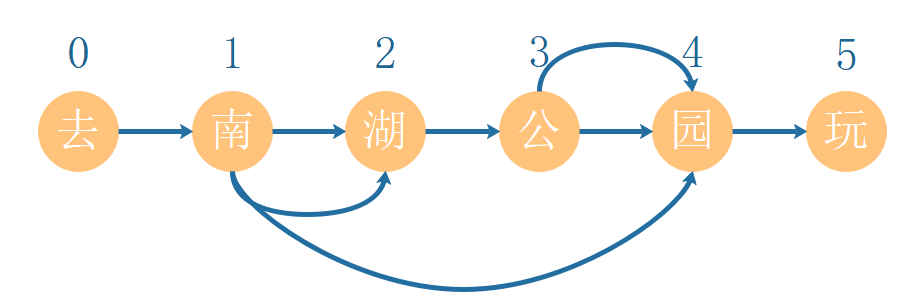
在前向LSTM输入“去”,“哪”,“玩”的词向量,反向LSTM输入“玩”,“哪”,“去”的词向量,分别得到对应向量并进行拼接得到最终的向量。
2.2 自然语言处理研究
2.2.1 中文自动分词
在英语语言中,词与词之间有空格将他们分开,这样对于机器来说以空格分隔就可以识别出相应的单词。但是在中文中却没有,这样就需要使用相应的程序在词与词之间加上空格。中文分词至少会存在如下问题:对词语的界定难以清晰定义;含有歧义的词在句子中普遍存在;词汇随时间演进剧烈,处理生词情况复杂。在中文自动分词问题被提出后,人们提出了上百种分词算法,而分词算法大致可以分为两种:
(1)基于词表的分词算法。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: