应用于大数据分析的K-means算法的实现毕业论文
2020-02-19 20:35:45
摘 要
近年来,随着大数据概念的兴起,越来越多的企业及个人将目光投向了大数据领域。相比于普通数据,大数据的特点在于其体量、种类以及速度。体量即指数据量,大数据的数据来源渠道极多,包括社交媒体、物联网等。其体量之大使得传统的数据库以及数据处理模式将变得很难应对爆炸式增长的信息量。为了更好地处理大数据,与之相应的数据存储、数据处理、数据挖掘等技术应运而生。本文将从底层存储技术和上层计算技术两个方向,以当前市面上较火热的三款大数据计算平台Hadoop、Storm以及Spark为研究对象,研究三者在存储技术上的异同,并且探究MapRdeduce分布式计算架构的特点以及局限性所在。最后比较三款分布式计算平台的异同和优缺点。之后以人工智能算法中的聚类算法为研究目标并重点研究其中的K-means算法,通过实现算法 进行仿真来探究算法存在的缺陷以及改进的可能性和方法。
关键词:大数据;聚类算法;K-means算法
Abstract
In recent years, with the rise of the concept of big data, more and more enterprises and individuals pay attention to the field of big data. Compared with ordinary data, big data is characterized by its volume, type and speed. Volume refers to the amount of index data. There are many sources and channels of big data, including social media and Internet of things. Its size makes it hard for traditional databases and data-processing models to cope with the explosion of information. In order to better deal with big data, the corresponding data storage, data processing, data mining and other technologies emerge. This article from the underlying storage technology and computing two directions at the top, with the current relatively popular on the market three big data computing platform Hadoop, Storm and Spark as the research object, research explored the similarities and differences on the storage technology, and to explore the characteristics and limitations of MapRdeduce distributed computing architecture. Finally, the similarities and differences, advantages and disadvantages of the three distributed computing platforms are compared. After that, the clustering algorithm in the artificial intelligence algorithm is taken as the research target and the k-means algorithm is emphatically studied. Through realizing the simulation of the algorithm, the defects of the algorithm and the possibility and method of improvement are explored.
Keywords: Big data; Clustering algorithm; K-means algorithm
目 录
第1章 绪 论 1
1.1 研究背景和意义 1
1.2 国内外研究发展现状 1
1.3 本文研究内容 3
第2章 大数据相关技术 4
2.1 大数据生态圈 4
2.2 分布式计算技术概况 5
2.3 Hadoop 6
2.4 Storm与Spark 8
2.5 小结 9
第3章 人工智能算法 10
3.1 大数据算法概况 10
3.2 聚类算法 10
3.2.1 K-means算法 10
3.2.2均值漂移聚类 11
3.2.3DBSCAN算法 11
3.2.4其余聚类算法简介 12
3.3 小结 13
第4章 K-means算法的实现 14
4.1 K-means关键点 14
4.2 K-means仿真 15
4.3 K-means算法的一些改进 18
4.4 小结 20
第5章 总结与展望 21
5.1 本文总结 21
5.2 展望 22
参考文献 23
致谢 24
附录 25
第1章 绪 论
1.1 研究背景和意义
随着大数据领域的飞速发展,人们的工作、学习和生活各个方面都将迎来一场巨大的变革。而传统意义上的数据处理技术对于大数据的大体量、高速度、多种类的特点显得有些难以应对。于是很自然的,人们将目光投向了另一个领域——智能算法领域。相比传统数据概念,大数据领域的处理技术将不得不面对许多难题,比如:非结构化的数据、高速流动的数据流、多渠道的数据源、价值密度低下的数据群,以及无标签无分类数据。各种各样的难点并不能通过单一的智能算法加以解决,本次研究的目的在于通过聚类算法对众多难点中“无标签”这一难点加以解决。当我们面对大量的数据时,我们首先要做的可能就是对其进行分类。而与传统数据概念不同的是,在大数据时代我们很可能并不知道这样一组大量数据能分成多少类,每个类别有什么共同的特征,因此我们需要一种无监督的只能算法来帮我们完成这项工作——即聚类算法,无需事先给出分类特征也能按照所设类别数完成分类。尝试通过Matlab平台以较为简易的算法程序完成这样的一个聚类算法分析即为本次研究的目的所在。而其意义在于给出一个易于上手易于理解的模式帮助新入门人员更好地理解何为大数据,以及智能算法在大数据领域中的应用。
1.2 国内外研究发展现状
大数据最鲜明的特征可以总结为三点:数据量极大、数据类型繁多,以及数据速度快。时至今日,全球每年的数据产量已经达到了PB量级。与此同时互联网时代中的每一个人都是数据的生产者,产生着包括但不仅限于文字、图片、影音等类型繁多的数据。而物联网、车联网,等概念的兴起则进一步推动了数据量的爆炸式增长。而速度快则指的是在大数据时代,数据产生的速度惊人地快,这一点对传统的数据采集技术及数据存储技术提出了严峻的挑战,也迫使着二者技术的进步。另一方面,数据的“快”也指代着其时效性。在大量的数据中,某些场合下的某些数据生命周期极短,这意味着如果没办法提高处理的方法和速度则到手的数据将很快变成废品,从而无法挖掘出其中的价值[1,2,3]。
除了以上三点之外,大数据技术的应用领域中有一个不得不解决的问题即是:大数据的价值密度低下。不可否认在如今的时代,数据渐渐变得越来越重要,在许多从业人员眼中:数据与各种实物资源例如土地、作物、矿物等在某种程度是有着不分上下的重要度,数据本身就是一种资源[2]。随着数据总量的几何级增长,其中蕴含的价值量也变得越来越惊人,但相对的,其价值密度比以往任何时候都要来得低下。这意味着,我们无法再用往日传统意义上的统计手段来处理这些数据,于是人们开始把目光投向人工智能领域。又或是正相反,人工智能领域的工作人员注意到了日渐膨胀的数据量级——人工智能的发展离不开大量的数据。于是人们一边利用人工智能来挖掘大数据中的隐藏价值,一边利用海量的大数据来推动人工智能的进步,使其变得更加强大。这样的一种模式使得大数据领域和人工智能领域迎来了飞速的发展,这样一场技术的变革早已方方面面地使得我们的日常学习生活发生了悄然的改变。更为重要的是,在大数据时代里,人们开始学着从另外一个角度来了解世界——即,不再关注事物之间的因果性,转而把目光投向事物之间的相关性上。海量的数据,庞大的样本,甚至使得一定程度上的预知未来成为了可能[4,5]。
随着技术的发展,数据的形式已从单纯的文字,数字扩展成了包括视频、音频、图像在内的多种复杂类型的集合。与此同时,随着计算机网络的发展,数据产生的速度之快,来源之广,形式之多样化,也远超过往。在互联网时代里,每个人都是数据的生产者——社交平台、直播平台,购物平台——你的每一次点击,你的每一句发言,甚至就连你不经意间顺手发出去的表情符号都会被作为数据保存下来并加以分析,用以确定其中蕴含的“情绪”。到今天为止,全球每年的的数据产量已经达到了惊人的ZB量级,如此海量的数据中蕴藏着巨大的“价值”。为了获得这些价值,为了应对大数据时代的到来,我们需要新的技术来管理、分析和应用这些数据[6,7]。
作为当前时代的热点词汇,大数据一次可以说重新定义了我们的学习、生活等环境。更为关键的是,它拓展了以往的决策思维模式,它使得不再依据逻辑关系而是从事物间的相关性着手来进行决策和预知成为了可能。这就致使了某些国务级别的,难以通过逻辑进行具体分析的决策可以通过数据来进行判断。比如说在随着工业化进程的发展,如今的较发达的城市地区的用电量已经达到了一个惊人的规模,而在某些人口流动性的较大的地区,局部区域的用电需求波动较大。这就导致了如今对电力的生产和管理变得愈发复杂,而通过大数据分析特定地区的电量消费变化则可更好地预测该地区未来的用电趋势,更好地对电力生产进行管理[8]。在大数据时代,人工智能得益于海量数据的支持也发展的越来越快,智能算法在各个领域逐渐取代了原本传统的分析算法。还是以电网举例,随着电网技术越发发达,工作精度也越来越高,这就导致了电网的工作负荷在较极端环境下受影响较大,需要及时根据温度和湿度调整工作状态。这就需要极高的计算精度和速度,用以往的传统方法难以解决的时候,研究人员理所当然地将目光投向了智能算法技术[9]。
大数据技术还在医学领域大放光彩,比如IBM Wston为代表的临床决策系统将海量的医疗文献以及专家决策纳入数据列表,综合病人的相关病因和病理特征给出可信度极高的建议,在减少不良反应上取得了相当良好的效果。而且在医疗过程中,临床遇见的各种疑难杂症也提供了大量的相关数据,使得相关系统通过机器学习的当时变得更为全面和强大[10]。而在商业领域中大数据的应用也愈发深入。全球范围内的企业家都开始逐渐地开展了大数据相关的应用,或许会令人感到不快的是,这种应用更倾向于收集用户不自觉的行为或反应,作为数据来加以分析,挖掘出隐藏在其中的用户趋向。以奢侈品牌prada为例,该企业会在每一件衣物上装上RFID条码,以记录该衣服在何时何地以何种频率被拿进试衣间。分析上传的数据商家就能分析出在什么地方什么时间段什么商品更加受客人青昧[11]。
从国家层面而言,全世界的有能力参与的国家都不约而同地将大数据领域的技术竞争放在了关注列表的前位。
在这样的时代背景下,大数据相关领域成为了我国的重点关注对象。这不仅仅是因为其无限的潜力,以及已经展现出来的价值。另一个更为重要的原因在于,在大数据领域中,我国极有可能领先于其他国家抢占技术先机。而之所以会这样主要有两个因素,其一是大数据领域的相关技术与传统意义上的IT技术不太一样,它对技术成本及的硬件的要求并不高,这就极大地弥补了我国在硬件技术上与国外的差距,使得我国与国外在相关技术上的竞争能够从同一起跑线上开始。另一点,则在于中国的庞大人口及由人口带来的庞大市场。由于种种因素,我国庞大人口产生的海量数据能够较为轻易地通过市场汇聚到几个点上。各种电商平台,又或是通信运营商都能够较为容易地得到这些数据,这其中不乏有足够实力和技术的企业对这海量的数据加以研究和利用。
1.3 本文研究内容
本文的研究重点在于人工智能算法在大数据中的应用,而人工智能的三个重要元素分别是算法、计算能力以及数据。其中计算能力得益于科技的进步而致使计算成本在不断地下降,而在大数据时代中,高速增长的海量数据进一步推动着人工智能的进步——这也是人工智能与大数据紧密结合的原因之一。本文重点讨论人工智能中的算符部分在大数据领域中的应用,选取的是机器学习中的聚类算法中的K-means作为研究对象。
为了探究人工智能算法在大数据中的应用即应把重点分为两项,一是研究大数据的相关技术,比如数据存储技术、数据采集技术、数据清洗技术等底层技术,例如大数据平台Hadoop。二是研究算法内容,K-means是个典型的无监督式的机器学习算法,能实现无标签的数据分类。本次研究拟采用Matlab达成算法的实现以及模型的建立,综上所述,研究内容可大体分为
(1)学习大数据相关技术,了解大数据生态圈即大数据平台的组成
(2)研究K-means算法,做到算法的实现及改进
(3)探究相关算法在大数据领域中的具体应用
第2章 大数据相关技术
2.1 大数据生态圈
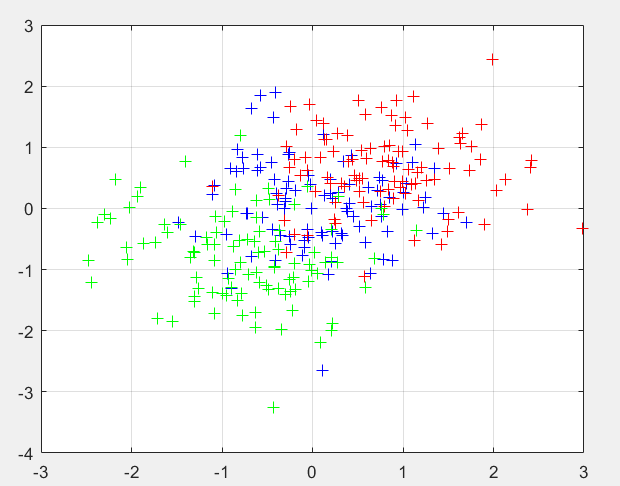
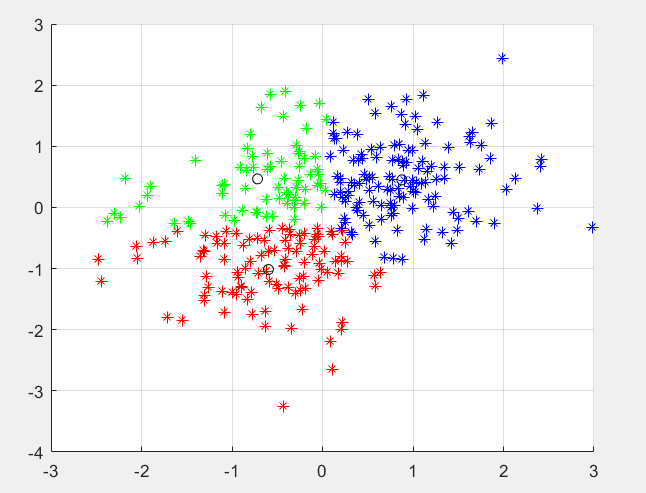
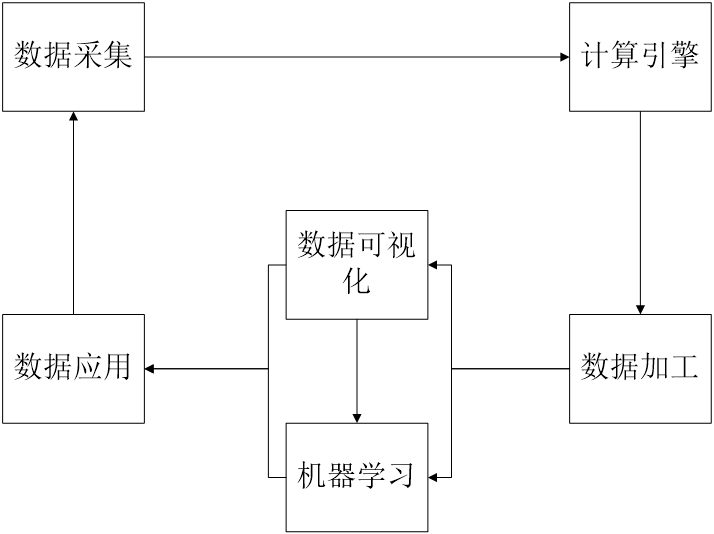 整个大数据产业可以说形成了一个相对闭合的链圈,其循环尽如图1示例所示。数据采集开始,为了对采集到数据进行计算,将数据输送到其下游节点计算引擎上。大数据的计算方式基本可分为批量计算和流式计算两种形式。这之后要进行的工作是数据加工,因为原始的大数据实际上并太适合于直接拿来进行数据挖掘,需要对数据进行清洗、去除敏感特异点等操作。完成数据加工后的工作既可实现数据可视化,以目录或地图等形式展现出来,也可用于机器学习——机器学习包括聚类、神经网络,支持向量机等。经过数据可视化的结果也可一同用于机器学习。讲过以上几个步骤之后,生产出来的“结果”便可用于实现数据应用了,其范围非常广泛。常见的,易想到的可能是精准广告、精准营销,常人不太常见到的可能是用于医疗,用于政务,或是用于预测,甚或是国务级别的未来的规划。
整个大数据产业可以说形成了一个相对闭合的链圈,其循环尽如图1示例所示。数据采集开始,为了对采集到数据进行计算,将数据输送到其下游节点计算引擎上。大数据的计算方式基本可分为批量计算和流式计算两种形式。这之后要进行的工作是数据加工,因为原始的大数据实际上并太适合于直接拿来进行数据挖掘,需要对数据进行清洗、去除敏感特异点等操作。完成数据加工后的工作既可实现数据可视化,以目录或地图等形式展现出来,也可用于机器学习——机器学习包括聚类、神经网络,支持向量机等。经过数据可视化的结果也可一同用于机器学习。讲过以上几个步骤之后,生产出来的“结果”便可用于实现数据应用了,其范围非常广泛。常见的,易想到的可能是精准广告、精准营销,常人不太常见到的可能是用于医疗,用于政务,或是用于预测,甚或是国务级别的未来的规划。
图1 大数据生态圈
如图1所示,此即为大数据的循环生态圈简易模型。本章节将较为详细地介绍大数据相关的技术,如:数据存储技术、分布式计算环境等。并将介绍包括Hadoop、Spark在内的已经较为成熟的大数据技术系统,帮助进行理解。
2.2 分布式计算技术概况
在前大数据时代,大数据刚开始爆炸式增长的时期,一些较为传统的企业用以存储核心业务数据的技术还是关系型数据库。而较新型的互联网公司,比如淘宝则建立了独立的数据仓库 Oracle RAC用以存储数据仓库。然而问题来了,当企业选择了独立的数据仓库时就会出现一个问题——数据来源顿时变得多元化。不只是平常的业务数据,包括网页的日志数据、客户的搜索记录、各商品的评分细则之类的多来源多类型的数据都将奔涌向数据库。尽管在当时,这样的数据库处理能力相当之强,能够处理10PB以下规模的数据。但在大数据时代,网络中的每个人都在时时刻刻地接受着数据,产生着数据。对这样大量繁杂的数据进行数据清洗或者数据校验等高负荷的数据加工工作,这种集中型数据库便显得有些有心无力。
然后,MPP——Massively Parallel Processing,即大规模并行式计算技术的兴起和发展使得基于MPP的专业级数据处理软件开始在市场上推广开来,代替了传统的集中型数据库。尽管如此,这些基于MPP软件的所使用的技术本质上还是一种数据库技术。随着数据的持续增长,数据的来源变得更加多元化,数据的类型数量也变得更加繁杂,更重要的是,从业人员对大数据的应用产生了更高的需求。要更好更高效地处理这样大量的数据,再使用传统的数据库技术来进行显然是行不通的,于是各种各样分布式计算系统应运而生。于是一种将数据分为多种定式的规格大小并进行分布计算的思路出现了,将这种想法实例化得到的就是各种分布式平台,其中Hadoop平台是现在最火的分布式计算平台[12,13]。
MPP的功能简单来说就是将任务分配到各个子节点上分别进行计算并最终集合到一起,即用分布的非共享数据库群集合起来作为一个整体提供数据库服务。MPP的特点在于其下多个SMP服务器通过一定的节点网络进行链接,而每个节点只访问特定的服务器,每个服务器独有自己的资源,不与其他服务器共享。这意味着这样的系统横向扩展性非常良好,可以方便地增加加点以提高性能。
与MPP相比,Hadoop能处理的数据规模级别更高一点。Hadoop能完美地处理PB级别的数据,而MPP则只能覆盖部分PB级别的数据。更关键的是,Hadoop能更好地处理非结构化和半结构化的数据,这与大数据的特征向契合。而相对的,MPP在结构化数据的处理上比Hadoop更加高效一些。因此,MPP更像是传统数据库的一个延伸,更适合处理企业的数据业务,Hadoop则能更好更搞笑地处理“外来”数据。因此许多企业采用的模式是MPP与Hadoop相结合的模式。
时至今日,大数据领域有三种最重要的分布式计算系统,分别是Hadoop、Spark以及Storm。在接下来的章节中将分别展示它们各自的技术和特点。
2.3 Hadoop
在介绍Hadoop之前先简单说一下大数据的计算模式。大数据的计算模式大体上可以分为批量计算(batch computing)和流式计算(stream computing),二者的区别在于批量计算模式的工作顺序是先进行数据存储工作,然后对存储好的大数据进行非实时的静态集中计算。而流式计算则是不进行数据的存储,当数据到来时直接进行实时计算。
Hadoop是典型的批量计算模式的分布式计算系统,适用于对实时性要求不高的场景。牺牲了实时性换来的是,批量计算模式下的计算系统数据的准确性和全面性要更好。
Hadoop是由Apache基金会研发的一个开源分布式计算系统。如今已得到广泛的使用,包括Yahoo!、Facebook以及国内的百度、搜狐等互联网公司都是Hadoop的忠实用户。
Hadoop的组成可分为两部分,一部分是HDFS——用于存储数据的分布式文件系统架构。另一部分是MapReduce——用于分布式计算的软件开发框架。HDFS是Hadoop的底层结构,其本身是一个较典型的主从结构。在一个HDFS集群中,一般而言有且仅有一个Name node,其下管理着多个Data node。其存储模式类似于,当用户想要存储摸个文件时,该文件将被分割成多个部分,每个部分都称之为Block。这些Block将分散存储在不同的Data node中,而Name node则用于存储该文件的基本信息,如目录、名字、存储路径,存储状态等等。因此显而易见的是,Name node是一个HDFS集群的核心,而该集群中的Data node则可选用一些低成本的服务器。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
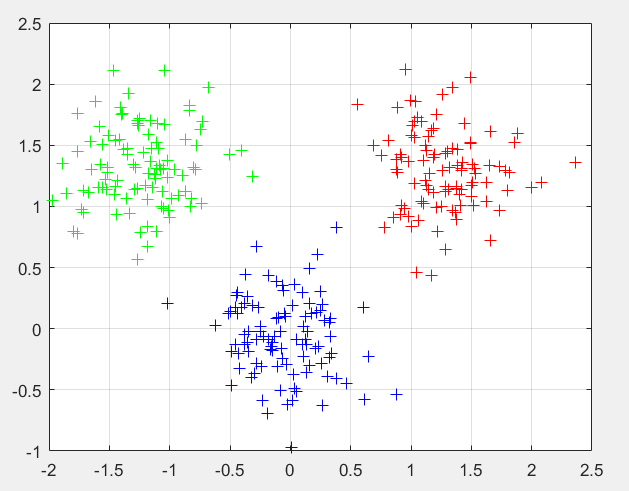
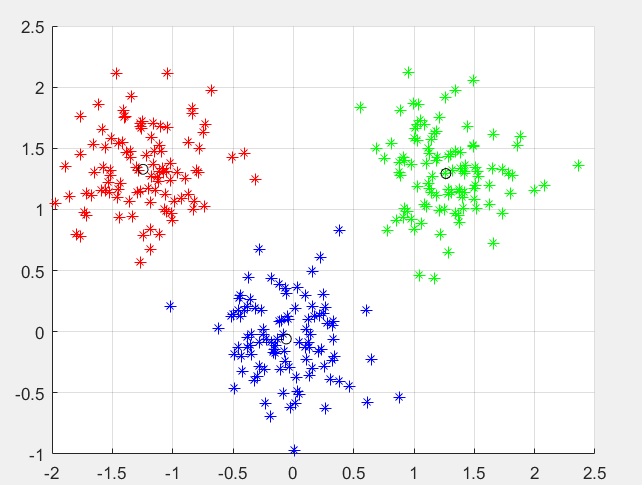
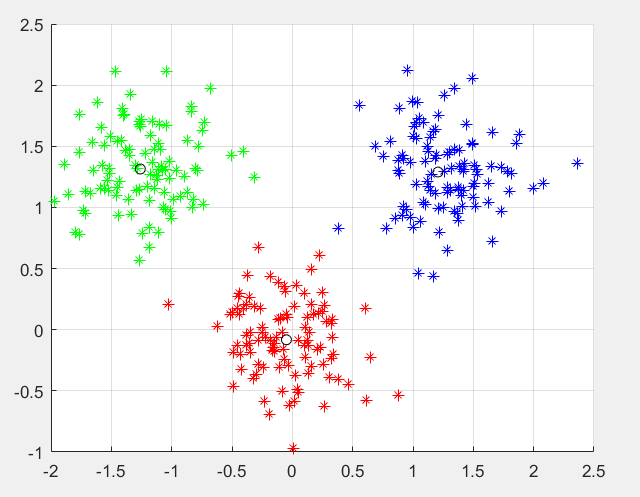
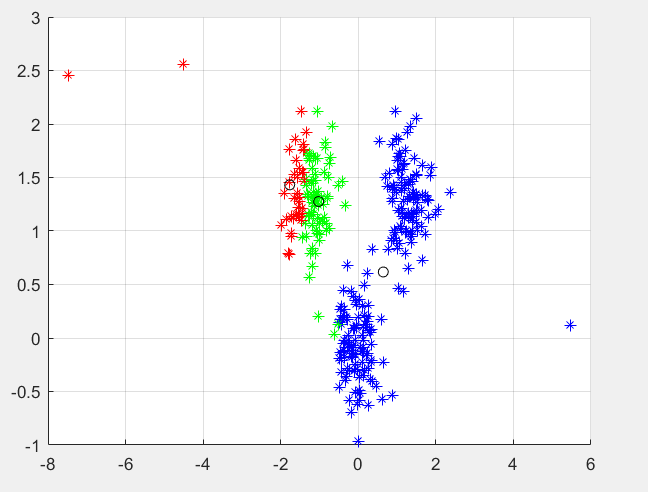
相关图片展示: