基于商品评论的用户分类方法毕业论文
2020-02-22 20:36:54
摘 要
通过数据挖掘的方法对购物平台商品消费评论进行用户分析,挖掘高价值用户以此便利于企业针对用户需求对商品的制造和营销作出改进。构建用户分类的指标体系,利用k-means聚类将用户分为四类,利用关联规则挖掘类的内部特征,结合用户价值和用户评论价值,构成商品评论二维分类模型并通过京东旗舰店铺商品评论的数据进行实验。将商品消费用户分为(1)沉默实际型用户(2)果断周到型用户(3)冲动怀疑型用户(4)稳健经济型用户,共4类,重点挖掘沉默实际型用户以及稳健经济型用户的特征并提出具有针对性的措施。由于匿名评论者的信息大都无法获取,因此未将匿名评论考虑在内。该模型是一种简易有效的商品评论效用用户分类模型。
关键词:商品评论、用户分类、k-means聚类分析、关联规则
Abstract
The method of data mining is used to analyze the consumer comments on the shopping platform commodity consumption, and the high value users can be excavated to improve the manufacturing and marketing of the goods for the enterprise. The user classification index system is constructed. Users are divided into 4 categories by using k-means clustering. Using association rules to excavate the characteristics within class, combine user value and user comment value to form a two-dimensional classification model of commodity reviews and experiment through the data of the Jingdong store commodity reviews. The consumer is divided into (1) silent actual users (2) assertive and thoughtful users (3) impulsive skeptical users (4) robust economic users, including 4 categories, focusing on the characteristics of silent actual users and robust economic users and putting forward targeted measures. Anonymous reviews were not taken into account because the information of anonymous commentators could not be obtained. The model is a simple and effective user classification model for commodity reviews.
Key word:Product reviews, user classification, K-means clustering analysis, association rules
目录
1引言 1
1.1选题背景 1
1.2国内外研究动态 2
1.2.1 国内用户评论研究 3
1.2.2 国外用户评论研究 5
1.3 研究内容 6
1.4技术方案 6
1.4.1 数据取样 6
1.4.2 数据预处理 7
1.4.3 k-means聚类分析 8
1.4.4 Apriori算法 8
2分类模型构建过程 9
2.1数据抓取 9
2.2自然语言处理 10
2.3指标选择 11
2.3.1评论价值 11
2.3.2评论者价值 11
2.4模型构建 12
2.4.1聚类分析 13
2.4.2关联规则分析 14
4实验结果分析 15
5结语 17
1引言
1.1选题背景
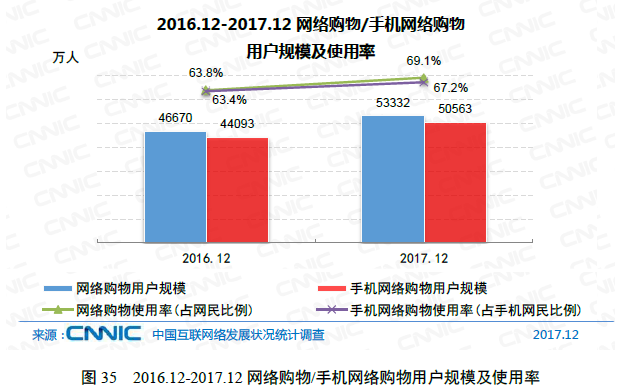
在电子商务蓬勃发展的网络环境下,互联网已融入了人们的生活,深刻而广泛地影响了人们的生活状态和思维方式。根据《2018年第41次中国互联网络发展状况统计报告》显示,截至到2017年12月,我国网络购物用户规模达到5.33亿,较2016年增长14.3%,占网民总体的69.1%。手机网络购物用户规模达到5.06亿,同比增长14.7%,使用手机网络购物的比例由63.4%增至67.2%。在此期间,网络零售则继续保持高速的增长,全年交易额总计达到71751亿元,同比增长32.2%,增速较2016年提高6个百分点。如图1.1所示。
图1.1 2017网络购物/手机网络购物用户规模及使用率
网络购物的蓬勃发展也使得用户逐渐开始愿意在网络平台上分享自己的消费和使用体验,商品评论的数量飞速增长。在电子商务快速发展的今天,用户评价已经成为很多商城非常重要的一个展示内容,其所占篇幅甚至超过商品本身的描述。一方面,商家为了提高用户满意度并获得商品意向反馈鼓励用户在购买商品后进行评论,从而使商品评论数量增多;另一方面,由于网购自身的局限性,很多用户在购买商品前也会针对其他用户对商品的评论来确认商品品质是否符合个人预期。根据CNNIC《2015年中国网络购物市场研究报告》显示,2015年网络购物用户购买商品时主要考虑的因素如图1.2:
图1.2 2015年网络购物用户购买商品时主要考虑因素
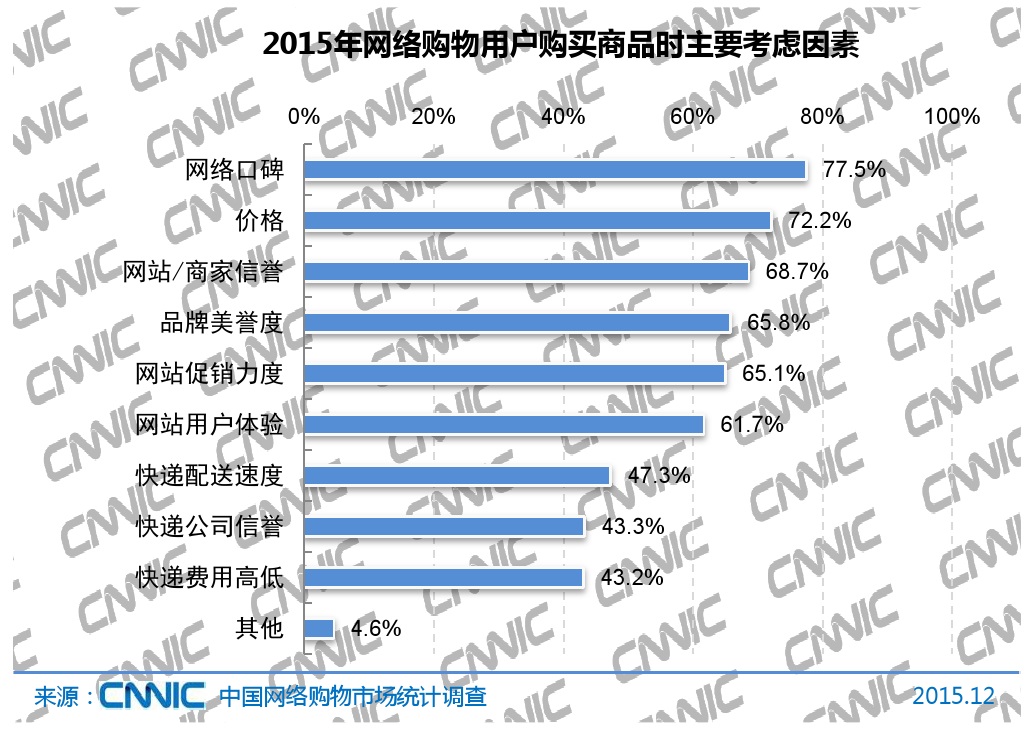
以上数据表明,中国有数量巨大的网络购物用户群体,并且网络口碑是最能影响用户购物行为时的重要因素。网络口碑的大部分是由商品评价组成,这些商品评论文本包含了用户对商品的情感、满意度、购买意向、整体评价等重要信息。而现如今,主流用户分析方法主要是基于用户的搜索记录、浏览记录等来源,对于用户评论的价值挖掘不够重视。用户评论包含了用户最直接主观的个人意向等信息,对商品推荐优化具有十分重大的意义。通过对这些信息进行挖掘分析,可以从中获取用户个人相关的用户画像,商家也可以通过数据反馈改善商品质量并优化商品推荐体系,从而提高买卖双方的成交率,降低商业成本。
1.2国内外研究动态
在线评论的效用是指对用户制定购买决策有帮助的商品评论。近年来,国内外的学者主要研究不同领域在线评论效用评级的前置变量与后置变量。前置变量指的是影响在线评论效用的各种因素,如SusanM和 David站在以搜寻品和经验品的角度来对商品分类进行研究,包括该因素对评论有用性产生的影响,更多的学者从评论内容质量或评论内容质量结合评论者的特征角度进行指标选择 。
1.2.1 国内用户评论研究
国内的购物网站产品评论是消费者通过在各购物平台上进行购买行为并对产品使用后自身对产品满意度的表达和交流。以淘宝网为例,利用语义分析来研究淘宝网所显示评论的主要方法。第一个特征是根据类的特征画出该类别的注释,执行分词,计算词频;将包括普通LDA的词聚类,以对单词进行分类和分类,并基于本体库建立语料库。(分类是最重要的一步,如大学风、淑女、美洲豹、休闲等类别的服装类别将被归类为风格);属性情感搭配,建立属性词与情感词之间的联系,判断情感。对属性词、情感词、属性类情感、句子的位置标记、属性情感和位置标签结果生成进行搜索,以便于标签对内容的检索。在情感词典构建方面,国内的情感词典使用《知网》较多,知网主要以汉语和英语表示的概念为基础,揭露不同概念之间以及属于不同概念的属性之间的关系;在判断意见持有者的领域,针对商品评论来识别和判断意见持有者是总结评论者对商品观点的关键,例如“我朋友看了我买了这个东西一直在跟我吐槽”中的“我朋友”是评论意见的持有者。因此让人们联想到保留意见的人大多是命名实体(如自我称呼或商品名称)是很容易的。有些学者通过使用命名实体识别技术将不同类型的意见持有者筛选判别出来,还有通过标记不同的角色标注来进行选择。但是这些识别方法有一个共同点,那就是都需要以自然语言处理技术为基础。
还有部分人运用划分类别的思想来选择到底谁是意见的持有者,这种方式主要根据特征判别技术和分类技术。CRF(Conditional Random Field)模型,通过将判断出的意见持有者等价于序列标注问题,以此来完成对持有者的选取。
首先是在评论文本识别研究方面,伊芳(2012)研究表明,场景图像中包含丰富的文本信息,它们很大程度上能够帮助人们捕获和认知场景图像的内容及含义,因此场景图像中的文本对所在图像视觉信息的获取具有十分重要的作用。针对场景文本因为文本载体本身倾斜或获取过程中的相机视角倾斜所引起的倾斜和透视变形,提出了一种基于数学形态学的变形校正方法[2]。郑立洲(2016)用新闻学中事件的语义元素5W1 H(When, Where, Who, What, Whom和How)对抽取出的文本事件进行表达[3]。提出了文本事件类型提取算法、基于事件类型的文本事件抽取方法、文本事件5W1H语义元素提取算法、多维度的商品评论情感分析方法等多种构成新系列的设计,并且在真实的文本集合上实验证明了所有算法的有效性,为今后使用信息提取技术在较短的文本上应用提供了重要的参考。
在情感分析方面,张卫(2016)研究显示,经典的商品评论情感分析是专门有针对性的评论文本集合的情感分类正负极性来进行的,并不考虑每一则评论中详细的商品属性评价问题,归类于粗粒度的情感分析,然而在真实的商品评论文本中,很多用户将商品两极差异的评论掺杂在一起,利用语言模糊的逻辑反转使得机器很难准确的将评论文本划分为正向或者负向[4]。其主要研究针对商品评论的细粒度的情感分析,提出一种基于商品属性的商品细粒度情感分析方法。该方法让用户对商品的不同方面功能属性的满意度得到更显著的表示,便利消费者更清晰的了解商品各属性的综合评价,从而作出最合适的购买决策,同时也使得厂商更清除用户喜好,改善服务。主要研究方法为爬取文本预处理后,对数据源首先进行人工筛选,筛选过滤掉噪音数据,而后进行相应处理,同时使用基于组合神经网络的商品属性聚类算法。该文提出了新的特征表示方法,将文本表示为一个四维向量,随后用支持向量机算法验证文本表示方法的准确性和有效性,最后提出建立商品评论情感词典的方案,同时使用词典对文本实施了情感分析。
杨思源(2014)研究详细描述了面向商品评价情感倾向的特征选择方法,即矩阵投影方法思想和过程,以及描述预测商品评价情感倾向的归一化向量算法思想和分类过程,并对其时间复杂度进行了分析。为了实现对文本的特点筛选和挖掘分析,需要将自然语言文本表示成计算机可处理的语言格式,也就是依照一定的方法把文本转化为数学模型。历经长时间的研究和探索,目前使用较多的文本表示模型大致可以分为:向量空间模型(Vector Space Model,VSM)、布尔模型(Boolean Model)和概率检索模型(Probabilistic Model)[5]。
谷斌和徐菁(2015)研究指出在线评论的效用研究是电子商务领域的研究热点,但焦点更多地集中在其影响因素上[6]。根据已有研究基础,从商品评论内容质量和评价者价值两个不同的维度构建在线评论效用指标体系。选择评论深度、语气强度、一致性作为衡量内容质量的二级标准,选择频度、近度、值度来作为衡量评价者价值的二级指标。在分析每一个分类评价特征之后提出相应措施:重点在于维系高效评论及评论者;甄选可疑评论并且对评论者进行限制;促进潜力和无效评论者的转化。由于匿名消费者留下的用户信息无法准确获取,因此对匿名评论的情况不适用。
张圣声(2015)利用层次分析法将影响产品评价的因素进行重要性的排序,计算出相关因素的权重,结合产品属性认可度,衡量产品的总体口碑情况[7]。刘云(2017)基于建模后的用户特征维度庞杂,碎片化数据蕴含价值低等问题,根据信息增益计量特征重要程度,提出两种具有代表性概率特点提取算法的优化策略:概率包裹式特征选择算法和启发式概率特征搜索算法[8]。李志宇(2013)从研究在线评论效用的影响因素入手,建立评论效用指标体系。采用模糊层次分析法确定指标的相对权重,通过语义挖掘对评论内容的各项指标进行量化处理,最后统计每条评论的效用总分[9]。余文喆(2015)提出基于属性重要程度的代表性评论集生成方案,令生成的结果集质量高且观点丰富[10]。周咏梅等人(2014)研究得出直接利用文本情感词典的分类效果好于朴素贝叶斯分类器,并具有分类过程简单、快速等优势[11]。
魏慧玲(2014)通过钻研该领域设计并实现了一个产品评论分析系统。该系统可以抓取特定的页面评论数据,做到基于词性模板和句法关系筛选产品特征词和情感词对,完成根据情感词典来对产品评论的特征进行情感分类,最终提供可视化的结果展示[12]。
1.2.2 国外用户评论研究
国外很早便开始针对用户评论分析进行了多项研究工作,2002年起,Peter首次提出通过将语义倾向性作为工具使用在非监督的用户评论分类工作中,并设计简便的算法,主要目标是将评论分为推荐(recommended)和不推荐(not recommended)。NEC公司的研究者Satoshi Morinaga,Kenji Yamanishi等人也在几乎相同的时间点提出通过网络上分析挖掘产品声誉度的概念,并设计出一种新的自动经由网页上手机使用过程中人们频繁关注的产品建议和意见然后通过文本的挖掘分析来获取产品声誉度的新框架。同时国外也有部分研究机构把针对商品评论的不同观点的分析挖掘做成系统:微软美国研究院Gamon等人所开发的Pulse系统实现了自身主动学习挖掘网上用户所上传的评论文本中与汽车评论相关的正向和负向信息以及这些信息的强弱程度。
目前,国外情感分析研究的常用基础资源包括WordNet、SentiwordNet和General Inquirer(GI)词典。WordNet是普林斯顿大学的研究者参与设计和实现的词典,该词典不但可以实现通过字母顺序来排列单词,而且还可以根据词语词性(如动词、名词、形容词)和词语的释义将单个词汇用来构成“单词的网络”。基础的语义概念使用一个同义词相关的集合来表示,此外这些集合间也有各种关联。SentiwordNet使用WordNet中的同义词集合来把三种数值联系在一起,即对每个同义词集合进行三种不同的情感标注:正面、负面、客观。General Inquirer在1996年设计开发,内部含有11788个英语词语和182个词语分类,部分词语通过人工手动标注分为了正面或负面的情感倾向。针对出现的单个词语多个释义的现象,词典将使用不同类别来划分。
在叶强(2009)等人研究中,情感分类技术被纳入到采矿评论领域的旅游博客。具体而言,我们比较了三种监督学习算法的朴素贝叶斯,SVM和基于字符的N-gram模型的情感分类的评论旅游博客的七个流行的旅游目的地在美国和欧洲。实证结果表明,SVM和N-gram方法优于Navier-Vayes方法,并且当训练数据集有大量评论时,所有三种方法都达到至少80%的准确度[13]。劳伦斯(2003)等人也针对意见提取和产品分类的语义分类进行了深入研究[14]。Kobayashi N(2006)等人通过提取主题方面的评价关系,在Web上进行意见挖掘[15]。
通过对已有的文献进行总结发现,研究内容更多的是挖掘评论有用性的影响因素,较少从评论效用本身用户分类方面进行研究,且在具体指标选择上更侧重评论内容,较少能深入地从评论者的角度进行研究,或较少将评论者与评论内容两者清晰地划分。鉴于此,本文根据在线评论有用性的影响因素建立效用指标,利用数据挖掘中的聚类以及关联规则技术构建在线评论用户分类模型。
1.3 研究内容
本文将主要根据用户评论中的各项情感性词汇对用户评论进行分类和汇总,从而挖掘出高效用评论和无效或低效评论,将评论效用进行数字评级,利用python等数据处理软件对评论效用等级进行排列分析。将评论的效用价值与用户购物信息合并进行二维分类。其基本目标为通过对评论数据的分析挖掘对用户消费潜力及消费倾向进行细致分类,从而获取更加具有商业价值的用户特征画像。
在陈述的选择方面,陈述是将意见与情感融合在一起的主观表述。在情感分析中,如果语句里混杂的客观信息会给实验的分析结果带来不可知的不利影响,在情感分析前有必要把主观信息与客观信息分隔开来。由于文本内容的格式表现大多十分随意,主、客观文本信息经常让机器难以区分,因此在多数情况下,判定文本的主观和客观信息比单纯对主观性质的文本进行分类更加难以实现。
本文将针对文本语句内部包含的情感知识来进行主、客观文本信息分类,同时针对不同程度的情感语气词对文本信息的有效性进行评判。
1.4技术方案
1.4.1 数据取样
首先明确需要进行数据挖掘的目标后,必须将与研究目标相关的样本数据子集从各类商品评论中抽取出来。抽取数据的标准主要有三个方面,第一是相关性,二是可靠性,三是有效性,不需要对全体数据进行分析,以此来减少数据处理工作的量,节约系统资源,同时一并凸显我们想要寻找的内在价值规律性。
衡量取样数据质量的标准为:(1)资料全面详细,各类指标项完善;(2)数据准确无误,反应的都是正常状态下的水平。对所获取的数据,可从中再进行抽样操作。抽样的常见方式为随机抽样、等距抽样、分层抽样、从起始顺序抽样、分类抽样。
基于上述目标,我们需要通过网络爬虫技术对商品评价进行获取。本文采用的商品评论数据是使用网络爬虫软件从web页面上爬取下来的真实评论文本数据。在此对网络爬虫技术进行简单介绍。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。网络爬虫根据系统框架和实现方式,大致可以分为以下几个类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的[1]。
1.4.2 数据预处理
数据质量分析是数据筹备环节中十分重要的步骤,是数据预处理的前置条件,也是数据挖掘分析准确性和有效性的基础,没有可靠的数据,构建的数据模型将是空中楼阁。其主要任务是检查原始数据中是否存在脏数据,脏数据指不符合数据研究需求,以及不能直接进行相应分析的数据,通常包括缺失值、异常值、不一致的值、数据重复及含有特殊符号的数据等。



