“看图猜对联”--基于图像内容的对联检索毕业论文
2020-02-23 18:17:48
摘 要
文本摘要自动生成技术和图片处理技术均是目前充满挑战性但又非常具有前景的技术。而神经网络在这两大技术上的应用均已得到了良好的反馈,而卷积神经网络更是当下超级火爆的研究课题。为了能够对这方面的研究有所了解,我们设计了一个基于图像识别的对联生成系统。
本文主要采用的是MSCOCO数据集,利用VGG16模型对给定的图像进行识别分类后生成图片描述,随后通过机器翻译的方法将得到的英文描述翻译成中文,最后根据encoder-decoder框架处理生成的中文摘要,最终生成上联。
本文的特色在于对给定的图片,可以自动识别图片内容并生成相应的描述,然后反复使用encoder-decoder框架处理文本,最终生成对联上联,并对其结果进行分析。虽然最终生成的对联上联在准确性上还有待提高,但是相对于简单的检索提取结果来看,还是有很大的优势。对未来根据图片内容生成对联的技术有一定的参考价值和借鉴意义。
关键词:卷积神经网络;机器翻译;文本摘要自动生成;encoder-decoder框架;对联
Abstract
The automatic text generation technology and image processing technology are currently challenging but very promising technologies. The application of neural networks in both two technologies has been responded to good results. Convolutional neural networks are currently the subject of intense research. To be able to understand this research, we designed a couplet generation system based on image recognition.
In this paper, we apply the VGG-16 model to identify and classify the given images which are from the MSCOCO Dataset, and then translates the English description into Chinese by using the method of machine translation. Finally, the left roll of a couplet is generated based on the Encoder-decoder framework processing and match the most suitable couplet.
The feature of this paper is that for a given picture, the content of the picture can be automatically recognized and the corresponding description generated, and using the encoder-decoder framework to process texts repeatedly, then generating the left roll of a couplet in the end, then analyzing the results. Although the accuracy of the left roll of the couplet is still to be improved, it still has a great advantage compared to the simple retrieval results from the database of couplet. It has certain reference value and reference value for the technology of generating the couplet based on the image content in the future.
Key Words:Convolution neural network; machine translation; Text summary generation; Encoder-decoder; couplet
目 录
第1章 绪论 1
1.1研究背景 1
1.2 国内外研究现状 2
1.3 研究目的及意义 3
1.4 课题工作内容和结构安排 4
第2章 基本知识 5
2.1 卷积神经网络 5
2.1.1 CNN简介 5
2.1.2 结构组成 6
2.2 机器翻译 7
2.2.1 简介 7
2.2.2 方法 7
2.3 文本摘要生成 9
第3章 设计与实现 10
3.1 环境搭建 10
3.1.1 系统平台 10
3.1.2 系统设计 10
3.2 图片识别 10
3.2.1 基本原理 11
3.2.2 算法模块拆分 12
3.3 机器翻译 13
3.3.1 基本原理 13
3.3.2 模块实现 14
3.4 文本摘要自动生成 15
3.4.1 基本原理 15
3.4.2 分词模块 16
3.4.3 匹配对联上联 17
第4章 结论 21
4.1总结 21
4.2展望 21
绪论
本章主要从研究背景、研究目的、研究意义、国内外研究现状、课题研究内容及预期目标几个方面进行相关的阐述。
1.1研究背景
互联网自从被提出和发展到现在普及到全世界的短短几十年的时间里,使用互联网的人数近乎是成指数增长,同时伴随有越来越多的图像、音频、视频等非文本的信息出现在网络中。虽然人类自己处理这些非文本信息的时候几乎没有任何难度,但是随着时代的逐渐发展,当下的技术已经越来越无法满足人们对技术的追求。而近些年,人工智能热度的爆炸性传播,也导致人们迫切需要一种更高效、更可靠的方法使计算机来识别这些非文本内容,使其具有类似人类的视觉并进行相应的处理后能够得到相应的信息。为了使计算机能拥有类似人类的视觉和认知系统,处于科学前沿的研究人员们一直在进行不断的研究与测试。
相关人员创建了一个十分宏大而又非常精确的图像数据库ImageNet,而且,每年都会举行以这个数据库为平台的视觉挑战赛ImageNet Large Scale Visual Recognition Challenge (简称 ILSVRC[1]),用来测试图像识别算法的准确率和性能。卷积神经网络就是在ILSVRC-2012的角逐中脱颖而出的,人们发现,使用卷积神经网络的算法在图像识别领域中可以得到非常理想的效果,相对于其他算法,卷积神经网络效率更高、容错能力更强、而且可以快速处理较大规模的数据。从此之后,图像分类识别领域中的主流算法便换成了卷积神经网络,并且一直延续到现在。
机器翻译主要是把一种自然语言经过一系列处理后翻译转换成另一种自然语言,翻译的过程主要是用要翻译的目标语言的单个词语来取代对应待翻译的自然语言的单词,然后再通过处理将所有的单词整理成顺畅的一句话。它属于计算机语言学的范畴,与计算机技术和信息论关系非常密切。从最开始的字典匹配,到后来的词典与语言专家知识相结合的规则翻译的出现,最后是现在基于语料库统计的机器翻译。通过借助计算机的多语种信息和计算能力,机器翻译技术正在愈发的成熟,广大普通用户也终将可以享受到方便快捷的自动翻译服务。
信息检索是指用户们通过查询来获得有关信息的主要手段,即用来查找信息的方法。广义的信息检索只是指信息通过某种方式处理后收集起来,再依据用户给出的特定信息通过搜索后,最终将相对来说最匹配的结果反馈出来的过程。但是伴随信息检索技术的不断发展和成熟,传统的统计检索方式已经逐渐难以适应现在人们对于快速、准确的检索需求,同时基于词向量的检索技术正逐渐成熟并广泛应用于各个领域中。
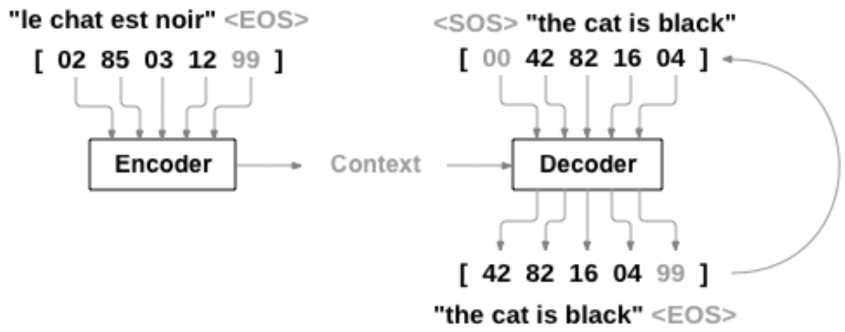
1.2 国内外研究现状
图像分类与识别至今依然是图像处理领域中最火的方向之一。其发展经历了图片中文字的识别、数字图像的识别与处理以及物体识别三个阶段。但是因为图像的特征很难准确的提取和描述出来,相似度的计算和人眼的感知也存在一定的差异,所以往往得不到准确的描述。20世纪90年代兴起的基于内容的图像检索技术——CBIR就已经允许直接根据图像的底层视觉特征进行检索,如颜色、纹理、形状等。伴随着数据挖掘和机器学习的兴起,图片分类技术也应运而生。经典的图片分类主要使用图片的颜色直方图、图片的纹理信息、图片的形状特征,结合常用的贝叶斯分类器、SVM分类器、KNN进行分类。然而这些方法无法有效的打破搜索引擎所返回的对于结果数量的限制。而且随着机器学习的应用,视觉领域进入一个新天地。Encoder-decoder框架结构最开始是基于循环神经网络的,即编码器和解码器均由RNN模型构成,现在框架结构已经发展成了编码器(CNN)-解码器(RNN),也就是先利用CNN预训练一个图片分类任务后得到编码器对图片解码的处理结果,然后再用最后一个hidden layer作为解码器的输入来产生相应的图片描述[2],在此基础上分别又出现了原有技术上嵌入soft和hard注意力机制来对前面的技术进行一定程度上的优化,使内容描述更为准确[3];CNN将前面所有的单词描述作为输入,并且对生成过的单词的依赖性进行建模,再进行对图片整体内容的文字描述[4];图片利用CNN模型处理图片,利用双向[5]RNN模型生成sentence,通过一个多模[6]编码来使两种模式的输入对齐最后给出一个多模的RNN架构来学习生成对图片区域的描述[7]。
伴随着互联网技术的逐渐发展和接触人数的不断增加,机器翻译也开始受到人们的关注,一方面因素是随着基于大规模语料库统计翻译技术的发展,机器翻译模型在提出后不久就逐渐受到了研究人员们的关注;另一方面的因素就是人们对机器翻译的性能需求随着计算机技术的日渐发展壮大也愈发提高 。
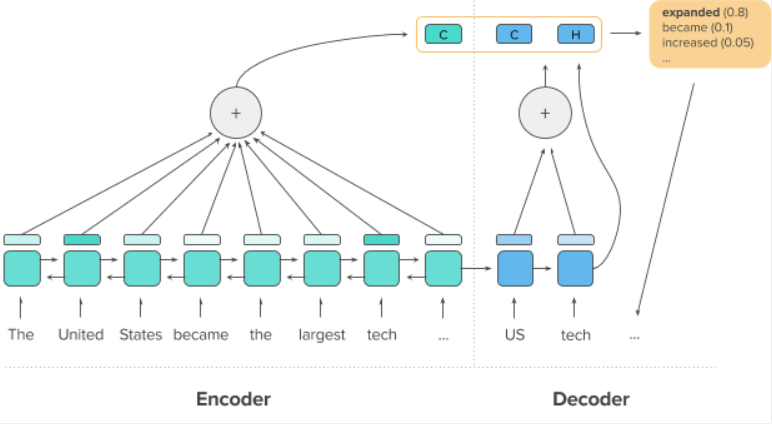
互联网自上世纪出现以后便不断的蓬勃发展。到现在互联网上的文本文献数量几乎是指数爆炸性的增多,其文本的结构变化也很大:数量大幅度增加、结构逐渐半结构化[8]。目前的文本摘要自动生成技术主要有抽取式和生成式两种。抽取式是指根据一定的权重,从给定的原文中找出和文章主旨最接近的一个或几个词汇。而生成式则是计算机在浏览全文并了解了文章意思后按自己的理解生成相应的简要概括。尽管抽取式摘要自动生成技术现在已经发展的比较成熟了,然而描述的顺畅度及准确性却无法令人满意。而依靠深度神经网络结构来实现的生成式摘要文本生成技术,其流畅度和准确性伴随着深度学习的逐渐被开发也都有显著的提升,但它也有一定的不足,如抽取内容不佳、处理过长的文本时缺乏准确度等。Sequence to Sequence序列(Seq2Seq)又称为编码器-解码器架构是由GoogleBrain团队在2014年提出的。该序列中的编码器、解码器均由数层RNN/LSTM构成,编码器负责把输入的原文处理成一个向量;解码器再从这个向量中抽取重要信息来获取其语义后在生成相应的文本摘要。然而因为“长距离依赖”的问题不可忽略,RNN在最后一个时间点输入的描述中已遗失信息的数量是不可忽视的。这也导致后面生成的语义向量同样也遗失了更多的信息,造成最终生成的文本摘要准确性不高这种不足的产生。基于RNN的文本生成技术目前为止做的相对较好的是由Salesforce推出的基于循环神经网络的Sequence to Sequence生成式文本摘要模型,他在原有模型架构上添加了注意力机制和强化学习。而由Facebook推出的ConvS2S模型是基于CNN的文本自动摘要自动生成模型中最典型的代表,该模型的编码器和译码器不仅是通过卷积神经网络实现而且加入了注意力机制。可见,伴随深度学习的进一步发展的同时神经网络也将覆盖更多的内容,而基于神经网络的生成式文本摘要自动生成技术也终会将变得更加成熟完善。
1.3 研究目的及意义
文本摘要自动生成技术和图片处理技术一直很受欢迎。随着互联网发展,网络上将会出现越来越多图像这类非文本的信息, 为了更有效率的处理图片内容信息,这就需要我们用一种更为高效、可靠的方法让计算机去识别这些内容,并且得到相应的内容描述。由于近期开始受到广泛关注的深度学习中的卷积神经网络(CNN)效率高,容错能力强,可以快速处理大规模的数据,被认为是进行图像内容检索很好的选择。而文本生成技术目前大多还是以检索的方式生成最相近的结果,目前来看不管是抽取式还是生成式,都有各自的不足。本次研究目的在于,熟悉tensorflow框架后通过卷积神经网络来完成图像的识别操作,并在Google翻译的基础上,利用接口将英文描述翻译成中文,最后通过编码器解码器框架来实现上联的生成。
我们都知道对联作为中文语言的独特的艺术形式是中国的优秀传统文化之一,上联和下联之间对仗工整,有着相同的字数和结构,平仄协调,言简意深。 本研究意义在于,尝试通过tensorflow框架应用卷积神经网络来完成对图像的处理操作,再把生成的文字描述转化成中文描述,最后根据描述去匹配上联。因研究涉及的卷积神经网络和文本摘要生成技术均是目前非常受关注的技术。因此本研究一方面可以进一步扩充和丰富中华传统对联文化的内容,另一方面也可以验证两大技术的运行性能,为之后可能对这些技术的研究提供新的参考。
1.4 课题工作内容和结构安排
本研究主要是根据给出的任意图片,通过系统分析,应用CNN的方法把原始图像的像素作为输入来生成相应的描述,根据该标签再通过RNN做一个训练来进行对联生成。涉及内容包括了卷积神经网络、文本自动生成、机器翻译等。课题研究的主要内容如下:
- 利用哈工大的LTP分词算法对从各网站爬取的对联数据进行分词处理;
(2) 通过深度学习的tensorflow框架利用卷积神经网络来完成对图像的处理操作,利用MSCOCO数据集进行图像分类;
(3) 利用Google翻译的 API接口将英文描述翻译成中文;
(4) 学习并利用Encoder-decoder框架根据中文描述去生成上联。
本文结构安排:
第一部分:绪论,介绍本研究所涉及的主要技术的国内外发展和研究现状。
第二部分:基本知识,介绍有关卷积神经网络、机器翻译和文本摘要自动生成等技术的相关知识。
第三部分:介绍本次项目中主要使用的一些方法和技术,并基于这些方法和技术所进行的相关工作。
第四部分:分析实验结果,总结结论。
第2章 基本知识
本章首先对所涉及的知识内容进行基本介绍,包括卷积神经、机器翻译和文本摘要生成技术等内容的基础介绍。
2.1 卷积神经网络
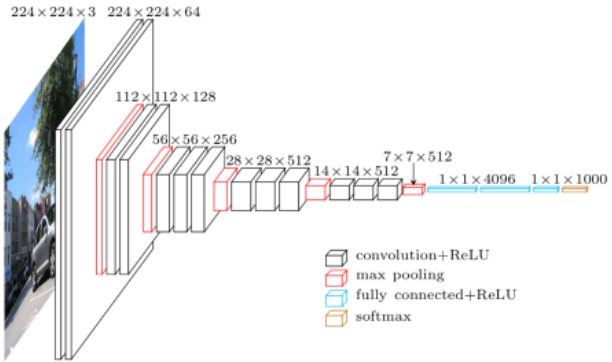
卷积神经网络是一种主要由输入层、输出层和隐藏层组成的带有卷积结构的深度神经网络。隐藏层一般由卷积层、池化层、全连接层和最后的输出层组成[9]。目前已经成功应用于视觉图像的分析领域中。
2.1.1 CNN简介
卷积神经网络(Convolutional Neural Networks)在1998年由纽约大学的Yann LeCun提出,由于备受关注的深度学习在近几年中发展迅速,作为高效的识别方法的卷积神经网络也受到更多的关注。卷积神经网络可以不需要在前期对图像进行繁杂的预处理而是输入最初的图像而被广泛是应用到各个领域之中[10]。它的概念可以追溯到19世纪60年代,Hubel的团队在对猫的视觉皮层细胞进行研究时观察到一种可以有效降低反馈神经网络复杂性的独特的神经网络结构[11],进而第一次提出了名为“感受野”的概念。而后Fukushima在上世纪80年代在这个发现上又提出了能够被当作卷积神经网络的第一个实现网络的新概念神经认知机。在这些人的研究基础上,纽约大学的Yann LeCun于1998年正式提出了Convolutional Neural Networks(CNN)即卷积神经网络这个概念。卷积神经网络实际上和多层感知机有些相似,它联合局部感受野、权重共享以及时间或者空间上的子采样这三种结构来确保平移和变形上的稳定性[12]。
CNN是一种非全连接的神经网络结构,卷积神经一般由两层基本结构组成,即特征提取层和特征映射层。每个特征提取层的相对位置是由位于其中连接了其上层局部感受野的神经元通过提取出该感受野的特征信息来确定的。特征映射因小核sigmoid函数的存在而拥有位移不变性。同时,网络上参数的数量因为位于相同映射面的神经元的权值相同而相对的变少。在CNN中的每个卷积层都会有着一个对应的由多个特征映射层组成的计算层跟随计算二次提取和局部平均,特征分辨率得到降低的原因正是得益于卷积神经网络独特的多次特征提取的结构。一个典型的CNN如图2.1所示。
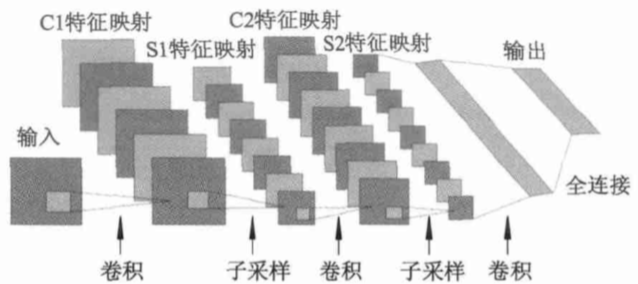
图2.1 CNN的基本结构
2.1.2 结构组成
由卷积层和次抽样层组成的经典卷积神经网络是非全连接且多层的神经网络。卷积层由多个分别由许多共享连接权重的神经元构成的特征平面组成,它的任务是抽取平面特征,其中每个神经元均定义了相应的感受野,即该层的输入连接了前一层的局部感受野并提取出相应的特征信息。卷积层的表达公式如下:
(2.1)
次抽样层的每个特征平面上面的神经元也是通过共享连接权重和从其感受野中接受数据来对其感受野中的数据进行抽样处理,所以其特征平面上的神经元的个数通常会减半。卷积层的每个平面都提取了前一层某一方面的特征。而且每个位于卷积层上的结点都会被看作是一个探测器来共同探测并提取输入的图像的某些特征。经过一层卷积后的图片就从原始空间被映射到了特征空间中去完成图像的重构。在特征空间中图像被重新构建的坐标在用作卷积层的输出的同时还会作为下一层即次抽样层的输入。
局部感受野:在图2.1中的第一个隐藏层中有6个特征图,其中每一个对应于输入层中的那个小方框就是一个局部感受野,也可被称为滑动窗口。
权值共享:上面的公式表示为卷积层l中第j个特征映射的激活值。其中代表的是一个非线性函数,通常是指tanh函数或sigmoid函数,表示为第l层的第j个单元的偏置值,表示为l – 1层中特征映射i的索引向量,在第l层中的特征映射j是需要累加的,*指的是一个二维卷积操作,表示为作用在第l – 1层中的特征映射i上的卷积核心,然后生成第 l 层中的特征映射 j 累加的输入部分。每个卷积层通常由几个不一样的特征图构成,而在这里表示为权重,它在同一个特征图中是相同的,以确保可以减少自由参数的数量。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: