视频图像语义标注方法研究毕业论文
2020-02-23 18:22:15
摘 要
随着互联网、多媒体技术、存储技术等的飞速发展,以及各种数字设备普及,使得海量的多媒体数据得以快速的增长和传播。如今数字图像已经与我们紧密的联系在一起,比如新闻媒体、医疗行业、娱乐行业、工业制造业等,在被如此广泛应用的背景下,图像数据的数量在以指数的形式增长,然而面对如此庞大的图像数据,如何进行有效的分类和检索已经成为迫切需要解决的难题。
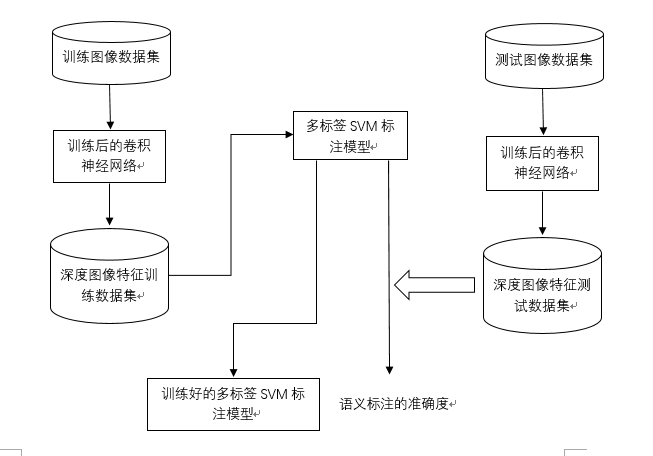
本文主要从生成式的图像特征提取和判别式的图像语义学习两个方面来展开研究的,通过结合卷积神经网络和SVM构建了一个基于生成式特征提取和判别式语义学习的图像语义标注框架。首先用标注好的图像数据集训练卷积神经网络,将训练好的网络作为图像的高层特征提取器,再利用图像提取到的高层特征对SVM进行训练,从而将图像的标注问题转化为多标签分类问题,进而完成图像的语义标注。对比一些传统的图像语义标注方法,该方法取得了较好的标注效果,所得结果对于图像自动语义标注具有重要的指导意义。
关键词:深度学习;SVM;图像语义;语义标注
Abstract
With the rapid development of the Internet, multimedia technologies, and storage technologies, as well as the popularity of various digital devices, the rapid growth and spread of massive multimedia data has been achieved. Nowadays, digital images have been closely linked with us, such as news media, medical industry, entertainment industry, industrial manufacturing, etc. Under the background of such a wide range of applications, the number of image data has grown exponentially, but With such huge image data, how to effectively classify and retrieve has become an urgent problem to be solved.
This dissertation mainly focuses on two aspects: the generation of image feature extraction and the discriminative image semantics learning. An image semantic annotation framework based on generated feature extraction and discriminative semantic learning is constructed by combining convolutional neural network and SVM. . Firstly, the convolutional neural network is trained with the labeled image dataset. The trained network is used as the high-level feature extractor of the image, and then the SVM is trained by using the high-level features extracted from the image, so that the labeling problem of the image is converted into multiple labels. Classification problem, and then complete the semantic annotation of the image. Compared with some traditional image semantic annotation methods, this method has achieved better annotation results. The results obtained have important guiding significance for automatic semantic annotation of images.
Key Words:Deep learning;SVM;Image semantics; Semantic annotation
目录
摘 要 I
Abstract II
第1章 绪论 2
1.1 研究背景及意义 2
1.2 国内外研究现状 3
1.2.1图像标注模型的研究 3
1.2.2 解决语义鸿沟的现有方法 4
1.2.3 传统的图像特征提取 4
1.3 主要研究内容和章节安排 4
第2章 图像语义标注方法介绍 6
2.1 基于传统算法的图像语义标注 6
2.1.1 基于分类的图像语义标注方法 6
2.1.2 基于概率统计模型的图像语义标注方法 7
2.1.3 基于关联文本的图像语义标注方法 8
2.2 基于深度学习的图像语义标注 8
2.3 本章小结 9
第3章 融合深度学习和SVM的图像语义标注 11
3.1 图像的语义标注 11
3.2 基于卷积神经网络的图像特征学习 11
3.3 基于SVM的图像语义学习 13
3.4 本章小结 14
第4章 图像语义标注算法实现 16
4.1 数据集与实验设置 16
4.2 实验结果与分析 17
4.3 本章小结 18
第5章 总结与展望 19
5.1 论文工作总结 19
5.2 研究工作展望 19
参考文献 21
致 谢 23
第1章 绪论
1.1 研究背景及意义
随着互联网、多媒体技术、存储技术等的飞速发展,以及各种数字设备普及,使得海量的多媒体数据得以快速的增长和传播。如今数字图像已经与我们紧密的联系在一起,比如新闻媒体、医疗行业、娱乐行业、工业制造业等,在被如此广泛应用的背景下,图像数据的数量在以指数的形式增长,也促进了很多图像数据的存储技术的发展。然而面对如此庞大的图像数据,如何进行有效的分类和检索已经成为迫切需要解决的难题。这就需要一种能够快速、方便、准确的查找到用户所需图片的技术,也就是图像检索技术。
图像检索方法主要是基于文本的图像检索(TBIR)和基于内容的图像检索(CBIR)。自20世纪70年代始,就已经出现了关于图像检索方面的研究,当时主要的研究方向就是基于文本的图像检索技术(Text-based Image Retrieval,简称TBIR),通过运用文本描述的方法来描述图像的特征,是一种被人们广泛认可的图像检索方式。它通过人工的方式对图像进行文本的标注,使图像和文本之间建立联系,然后利用文本检索技术对图像进行检索这种方式能够取得很好的效果,但是随着图像数据的增长,人工标注图像的工作量加大,这显然是种不现实的方式。而且每个人对图像的理解都是不一样的,不同的人之间容易产生歧义,这也使得人工的标注容易产生很大的问题。
从90年代开始,基于内容的图像检索技术(Content-based Image Retrieval,简称CBIR)成为了新的研究方向,就是通过分析图像的内容语义,比如图像的颜色、纹理、布局等来进行图像检索。它将从图像信息中提取低层的视觉特征以向量的形式存入到数据库中,然后通过比较图像视觉特征向量之间的相似度来检索图像。但是提供实例图像并不是一件容易的事,并且低层的图像视觉特征和高层的语义之间存在“语义鸿沟”[1],所以想要通过低层的图像特征来表达高层的语义是不太充分的。
为了解决图像语义标注中的“语义鸿沟”问题,人们又提出了基于语义的图像检索(Semantic-based Image Retrieval,简称SBIR),该方法的关键就在于对图像进行自动的语义标注。图像的自动语义标注是利用已经标注好的图像样本进行训练,再根据训练的结果创建语义标注模型,建立图像视觉特征和高层语义之间的映射关系,然后运用这个模型来对图像进行语义标注。该方法的本质就是通过对图像的低层视觉特征进行分析来提取用于表示图像含义的高层语义,从而有效缓解低层图像特征和高层语义之间的“语义鸿沟”问题。
1.2 国内外研究现状
1.2.1图像标注模型的研究
在研究图像语义标注的建模方法过程中,可以将现有的语义标注模型大致分为以下三种:判别式图像标注模型、生成式图像标注模型以及基于深度学习的混合式图像标注模型。
在判别式图像标注模型中,图像的自动标注被理解成为一个有监督分类问题,这种图像标注模型中主要是通过机器学习算法构建低层视觉特征和预标注的标签之间的关联性。在机器学习中常用的分类算法有逻辑回归(Logistic Regression)、支持向量机(Support Vector Machine,简称SVM)、传统神经网络(Traditional Neural Networks)、线性回归(Linear Regression,简称LR)等,此种模型通过运用分类算法计算图像视觉特征之间的相似度,然后结合对应的类别标签来对图像的类别进行预测,进而转换成图像的语义标注标签。这几年,多示例多标签学习也被广泛的应用到 图像的语义标注中,如Zhou[2]等人在2007年提出的MIML_SVM学习框架,用于解决多示例多标签问题,在MIML_SVM方法中是主要就是先对所有的示例进行聚类,然后以每个包到得到的N个聚类中心的距离为每个包的特征,从而将多示例多标签问题转变成了单示例多标签问题,而后再将单示例多标签问题转换成一系列的单示例单标签问题加以解决。Zha[3]在2009年提出的Joint Multi-label Multi-instance Learning方法,根据隐变量随机场对多示例多语义标签学习进行建模。
生成式图像语义标注模型就是通过学习图像和标注文本两者的数据来确定图像语义标签和图像视觉特征之间的联系,其主要思路是通过学习图像视语义标签和图像的视觉特征获得两者的联合分布概率,而后再利用贝叶斯公式计算出图像中的每个语义关键词的概率,概率越高就表明该语义标注词越能体现图中的图像特征,最后根据每个语义标注词的概率对图像进行语义标注。如Monay[4]等人在2007年提出的PLSA_WORDS模型方法,不仅考虑到了图像视觉特征与语义标签之间的语义关联性,还考虑到了对视觉特征之间联系的分析,为图像的标注提供了一种新的方法。
基于深度学习的混合式图像标注模型如今是计算机视觉领域里的研究热点,作为机器学习方法的一种,近年来成为机器学习领域发展的领跑者,深度学习之所以能够再次掀起学者的研究热潮要得益于其在计算机视觉领域取得的巨大成功,从Hinton研究小组的AlexNet[5]对图像的分类效果便可以看出。现在卷积神经网络(Convolutional Neural Network,简称CNN)已经被大量的运用在计算机的的很多领域,比如在模式分类领域,和传统的图像视觉特征提取方式相比,卷积神经网络能够将未处理的原始图片直接传入神经网络中,而不需要在之前对图像进行复杂的预处理,而且卷积神经网络能学习到高级的图像视觉特征,在视觉表达能力方面更出色。
1.2.2 解决语义鸿沟的现有方法
为了缓解低层视觉特征和高层语义之间的“语义鸿沟”问题,研究人员们尝试着从不同的角度来解决图像语义标注任务中的“语义鸿沟”问题。如Jin[6]等人在2005年提出的使用WordNet中词语的属分关系对Web图像标注方法所得到的标注结果进行优化,是从优化标注结果的角度来缩小“语义鸿沟”的。而Itti[7]等人在2001年提出的方法是从人对图像的视觉感知方面来缩小“语义鸿沟”的,他们的研究指出当人们在浏览一副图像时,图像的各个区域在人的视觉中占的比例是不一样的,由此形成了一种新的图像标注理论,即基于视觉权重的图像标注方法。
1.2.3 传统的图像特征提取
图像视觉特征提取是进行图像语义标注的基础。图像的底层视觉特征一般可
分为颜色、纹理、形状和空间位置等
颜色特征。颜色是每个物体都特有的一种特征,是一种物体表面的视觉特征。相比于其他的图像视觉特征,图像的颜色特征具有更好的鲁棒性,因为它对图像自身的旋转、缩放和其他形变的依赖很低。描述颜色特征的方法有很多,比如颜色矩法、颜色相关图法、颜色直方图法等。
纹理特征。纹理特征是用来反应图形图像中同质现象的一种视觉特征,这种视觉特征并不依赖于图像的颜色、亮度等,它广泛的存在于物体的表面,是图像中重要的底层物理表征。比如石头、树叶等等它们的纹理表征就各不相同。现在用来描述物体纹理特征的方法有频谱分析、统计分析和结构分析。
形状特征。形状特征是图像检索方面中一种非常重要的视觉特征,它具有良好的可区分性。但是不同于颜色和纹理等特征,形状特征的提取必须建立在对图像中物体或区域的边缘提取和分割基础上。形状特征在含义上是指一块有边界的封闭区域,所以在描述图像的形状特征时,可以描述这块封闭的区域或者这块封闭区域的轮廓曲线。
1.3 主要研究内容和章节安排
本文总共分为四个章节,每个章节安排如下:
第一章:绪论,首先简单的介绍本篇论文研究的背景和意义,而后对现阶段图像语义标注方法的研究现状展开分析,包括语义标注模型的介绍、语义鸿沟的解决办法和传统的图像特征提取等。
第二章:图像语义标注方法介绍,主要介绍几个现有的图像语义标注模型和方法,简要的介绍了一个基于深度学习的图像语义标注方法。
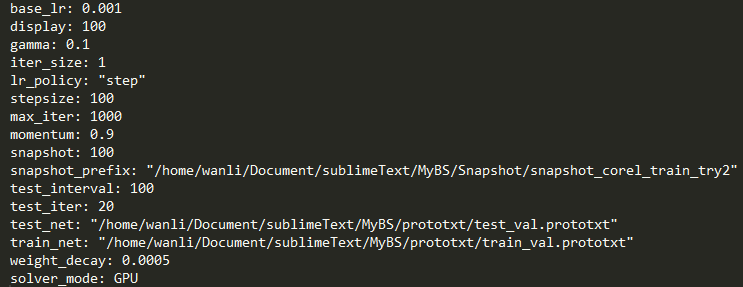
第三章:融合深度学习和SVM的图像语义标注方法,这一章中介绍了生成式的卷积神经网络的特征提取和判别式的SVM图像语义学习。本章确定了图像语义标注的框架以及网络的参数配置,同时也确定了SVM分类器的核函数。
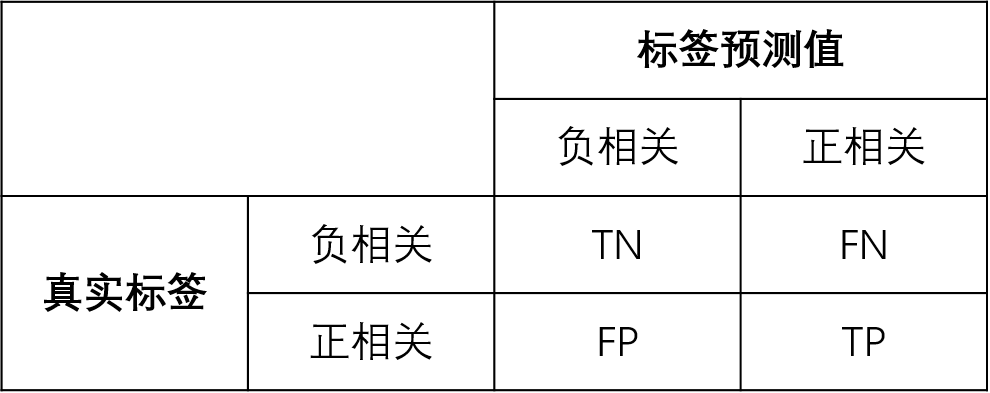
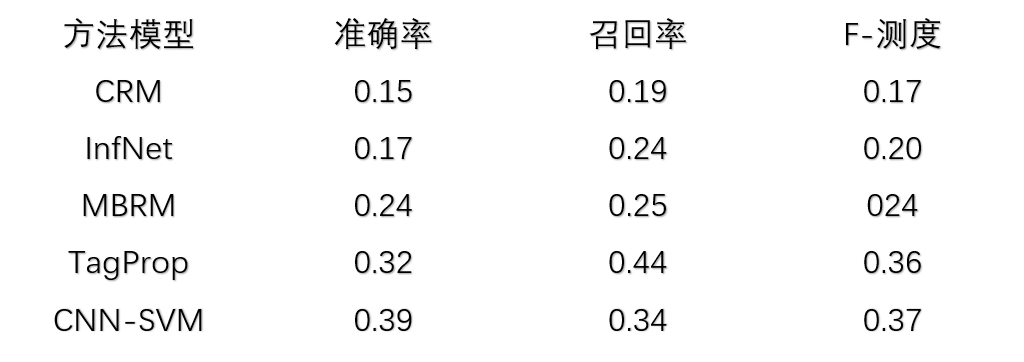
第四章:实验结果和分析,这一章实现了上一章所提出的图像语义标注框架,并通过同CRM模型、InfNet模型、MBRM模型以及TagProp模型等进行对比,证明了该方法的可行性和具有较好的准确率。
第五章:总结与展望,这一章回顾之前主要的工作并对其进行总结,同时分析了本文所提出的方法中需要改进的地方,对之后的工作和研究做了一个简单的展望。
第2章 图像语义标注方法介绍
2.1 基于传统算法的图像语义标注
现在已经出现了很多的图像语义标注方法,在这里将传统的语义标注方法大致分类三类,分别是基于分类的图像语义标注方法、基于概率统计的图像语义标注方法和基于关联文本的图像语义标注方法。
2.1.1 基于分类的图像语义标注方法
基于分类的图像语义标注方法就是将原始的图像标注问题看成是图像的分类问题,是一种比较容易理解的图像语义标注思路,多标记学习和多示例学习是基于分类的图像标注方法中两种不同的角度,现在大多数此类算法都是单一的从其中的一个角度来对图像标注问题进行分析和解决。基于分类的图像标注算法的基本流程大致如图2.1.1所示。
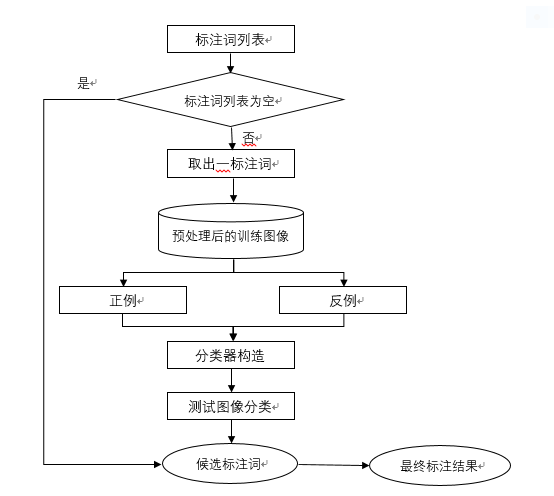
图2.1 基于分类的图像语义标注方法流程
在多标记学习中,每一个标注词看成是一个类别,从而达到解决图像标注问题的目的,但是和传统的图像分类算法相比又存在很大的区别,比如在图像的语义标注问题中,一幅图像可以同时存在好几个语义标注词,也就是说可以标注多个语义关键词,但是在传统的图像分类算法中,一幅图像只会被归为一类。如Cusano C[8]等人在2004年提出的基于支持向量机的图像语义标注算法,这个算法的思路是首先为每一个语义标注词构造一个二分类器,再根据二分类的思想将正例样本定义为所有被这个语义标签所标注的训练图像,同理可得反例样本为所有没有被这个语义标签所标注的训练图像。而后根据提取的正例和反例的的图像视觉特征为每个语义标签设置一个SVM分类器。在对图像进行语义分类时,需要将图像的视觉特征输入到每一个之前训练好的分类器中进行分类,每个语义标签按照对应的分类结果值大小由高到低排列,最后选择排序中的前几个语义标注词作为待标注图像的标注结果。但是因为用于训练的图像中没有标注出图像中的区域和语义标签之间的联系,只给出了整幅图像的视觉特征和语义标签之间的联系,可以理解为图像中的所有区域并不是都和这个标签的语义有关系,所以这也直接影响了该方法语义标注水平。
在多示例学习中,每幅图像给定的标签是标注在整幅图像上的,并没有给出标注的关键词与多个示例之间的关系,如果将一个图像当作是一个包,这个包是由多个示例组成的并且每个包都会有正包和反包之分,正包就是这个包中有两个或者多个正示例,同理,反包就是这个包中全部都是反示例。如Yang C[9]等人在2005年提出的解决图像语义标注问题的方法,使用的是多样性密度算法。他们使用的方法大致思路是,首先按照如上所说将训练的图像集分为正包和反包,然后假设在图像特征空间中存在一个点,这个点表示的是某一个语义标签的语义,那么在正例图像中至少有一块区域是和这个点对应的,换句话说,正包的所有示例中最少也有一个示例同这个点接近;同时在反例图像中并不存在某个区域和这个点对应,也就是说在反包的所有示例中没有一个和这个点接近。由此可以看出正包中的示例应该紧密的散布在这个点的附近,所以如果在特征空间中假设有一点的周围分布的正包的示例越多,那么这个点表示某一语义标签的语义的概率就越大。 在Yang C等人的方法中选择的是通过多样性密度来计算这个概率值,最后寻找的点就是计算出来的概率最大的点。但是这个方法也有不足的地方,一是很难用单一的特征来表示具有丰富语义的标注标签,二是在使用多样性密度算法计算概率时为了求得最优解还要进行多次的梯度下降搜索, 所以需要相当大的时间开支。
2.1.2 基于概率统计的图像语义标注方法
基于概率统计的图像语义标注方法, 就是通过概率统计模型来计算图像的语义标签和图像视觉特征之间的概率, 从而为需要标注的图像标注语义关键词。 简单的来说就是如果两幅图像之间视觉特征相似度比较高, 那么这两幅图像标注相似的语义关键词的概率就越高。这种图像语义标注方法不需要经过图像特征学习来建立语义标注词和低层图像视觉特征之间的关系,也就是说, 语义关键词和低层图像视觉特征之间不存在一一对应的关系。
Duy gulu P[10]等人在2002年提出通过机器翻译模型来对图像进行语义标注。他们提出的方法是将自然语言处理中的双语翻译模型应用在图像的语义标注问题中,将图像的视觉特征和图像的文本标签语义看作是表述一副图像的两种语言,从而将图像的标注问题转化为翻译问题,即将图像从视觉特征语言翻译到文本标签语言。 在视觉特征语言中,视觉特征词汇是由一个个blob组成,每一个blob是由每个图像区域经过聚类得到的;在文本标签语言中,语义词汇就是由标注在图像上的语义标签组成。最后根据自然语言处理中的机器翻译模型来确定语义词汇和视觉特征词汇之间的关系,从而解决图像语义标注问题。但是在这个方法标注的结果中,那些在训练的图像中出现的次数很多的语义标签对标注结果有很大的影响,所以为了解决这个问题, Kang 等人在2004年和2005年提出了两种基于该算法的改进方法,第一个方法是结合由语义词汇到视觉特征词汇的翻译结果和由视觉特征词汇到语义词汇的翻译结果来对图像进行语义标注[11],第二个方法则是通过规则化机器翻译模型的概率来解决这个问题[12]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
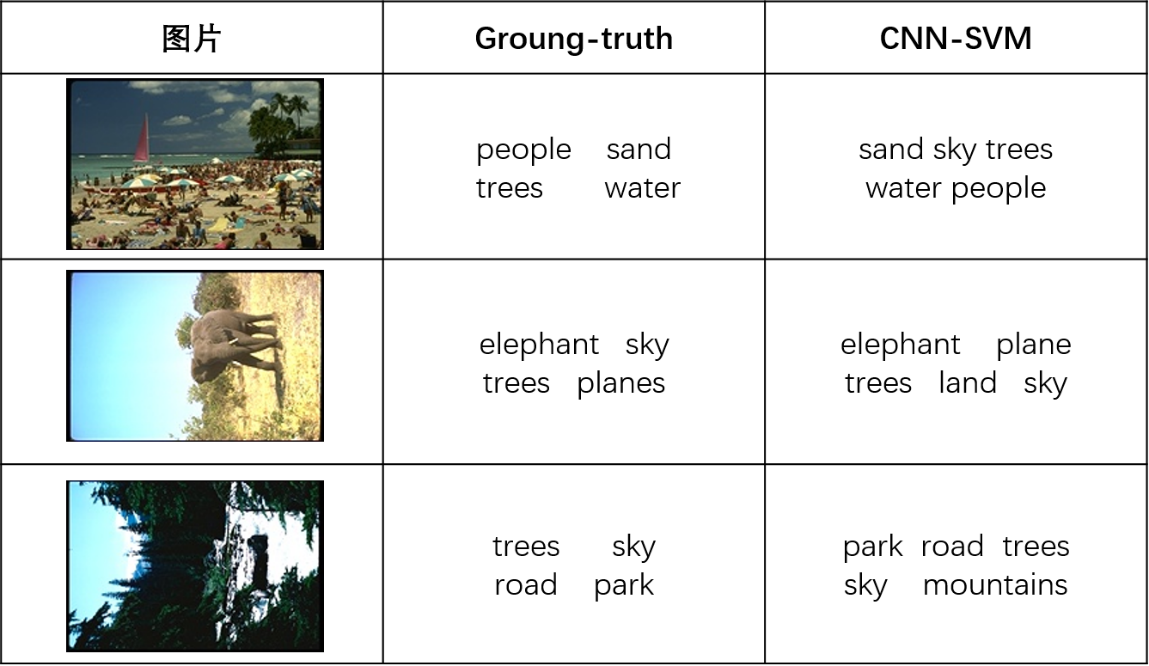
相关图片展示: