基于强化机制设计的云资源分配算法研究毕业论文
2020-02-23 18:23:49
摘 要
云计算[1-2](cloud computing)是继并行计算、分布式计 算和网格计算的一种新的计算模式[3-4],正逐渐成为信息产业的最新发展趋势。而云计算资源分配正是云计算面临的核心问题之一,高效的资源分配方案不仅能提高资源的利用率,还能提高用户的满意度。在今天的云资源市场中,云资源供应商通过分配给不同的用户云资源来获取利润,而为了获得更长期的利益,有必要对云资源的分配方案进行优化,云供应商应该如何分配资源才能使自己的利润最大化是我们研究的主要问题。
本文采用强化学习算法来对云计算资源分配问题展开研究,研究的工作内容如下:
(1)为了简单起见,我们考虑市场上只有一个主动供应商提供资源的情况,若干用户向该供应商请求资源,供应商针对不同用户请求给出对应的资源分配方案来获取最大利润。
(2)我们考虑市场上多个用户的情况,除了简单的资源分配问题,还考虑了资源的回收问题,用户请求完资源后将资源归还给供应商。
(3)在上面的设置中,我们使用强化学习中的一个比较经典的算法Q-learning算法来给供应商提出分配方案,同时我们还另使用了贪心算法对该问题进行研究,将两个算法进行比较,比较得到的分配方案以及最大利润。
关键词:云资源分配;强化学习;Q-learning算法;贪心算法
Abstract
Cloud computing [1-2] is a new computing mode following parallel computing, distributed computing and grid computing [3-4], which is gradually becoming the latest development trend of the information industry.The resource allocation of cloud computing is one of the core problems faced by cloud computing. The efficient resource allocation scheme can not only improve the utilization rate of resources, but also improve users' satisfaction.In today's cloud resources market, the cloud resource suppliers through cloud resources are assigned to different users to gain profits, and in order to get more long-term interests, it is necessary to optimize the cloud resource allocation scheme, cloud providers should be how to allocate resources to make their own profit maximization is the main problem of our research.
In this paper, the enhanced learning algorithm is adopted to study the allocation of cloud computing resources. The research content is as follows:
(1) for the sake of simplicity, we think the market is only one active suppliers provide resources, number of users request to the supplier resources, suppliers according to different user requests corresponding resource allocation scheme is given to obtain the biggest profit.
(2) we consider the situation of multiple users in the market. In addition to simple resource allocation, we also consider the problem of resource recovery. After the user requests the resource, he will return it to the supplier.
(3) in the above Settings, we use reinforcement learning a more classic algorithms of Q - learning algorithm to put forward allotment project to the supplier, at the same time we also use the greedy algorithm to study of the problem, we compare two algorithms, and compare with the scheme and maximum profit.
Keywords: cloud resource allocation; intensive learning; q-learning algorithm,; greedy algorithm
目录
第1章 绪论 1
1.1 引言 1
1.2 相关工作与研究现状 1
1.3 研究内容 2
1.4 论文的结构安排 3
第2章 基于强化学习及贪心算法的资源分配 4
2.1 强化学习理论研究 4
2.2 Q-learning理论研究 5
2.3 贪心算法理论研究 7
2.4 云资源分配算法模型 7
2.4.1 用户的需求模型 8
2.4.2 供应商的利润模型 8
2.5 本章小结 8
第3章 云资源分配算法研究 10
3.1 Q-learning算法设计 10
3.1.1 设计思路 10
3.1.2 算法描述 11
3.2 贪心算法设计 12
3.2.1 设计思路 12
3.2.2 算法描述 12
3.3 本章小结 13
第4章 数值实验 14
4.1 实验参数设置 14
4.2 实验结果统计 15
4.3 实验数据分析 16
4.4 本章小结 17
第5章 总结与展望 18
参考文献 19
致谢 22
第1章 绪论
1.1 引言
科技的进步推动了新兴产业的发展,“云”也逐步进入人们的生活,其发展在业界取得了巨大的成功,其原因在于它可以提供经济、可伸缩和弹性的计算资源,从而将人们从安装、配置、保护和更新各种硬件和软件中解放出来。目前,亚马逊、salesforce.com、3Tera等许多公司都提供云服务。
资源分配问题是大规模分布式云计算环境中的一个重要挑战。如何合理有效地分配资源是近年来的一个关键问题。云计算是从网格计算发展而来的。然而,网格计算中的现有资源分配方法不能直接在云环境中使用,因为云中的用户需求更大、更动态、更多样[5]。因此,云资源利用率低的问题,尤其是云基础设施的数据中心,一直是学术界和业界关注的焦点[6]。
云资源分配问题可分为两类。一种是资源利用的最大化。根据用户的特定需求(例如,CPU、带宽和INs的存储硬件资源被分配尽可能多的资源[7])。另一类是利润的最大化,这可能是公司的整体利润或利益[8]。
而本文考虑的云资源分配问题是利润的最大化,研究基于强化学习算法的云资源分配算法和贪心算法对云资源的分配,而本文使用的强化学习的一个比较经典的算法Q-learning算法来解决供应商的云资源分配问题,来使供应商的利润最大化。
1.2 相关工作与研究现状
随着科技的发展,云资源市场正在日益繁盛,而如何合理的分配和调度云资源正是当下国内外学者研究的热点。云资源的分配问题可以分成资源利用的最大化以及利润最大化两个方向[9],而利润的最大化又可分为两个方面进行研究,分别是使整体的收益最大化和使云资源供应商的利益最大化。张胜、吴杰等人[10]从最大化云资源利用率出发,提出了一个新颖的虚拟网络模型,并同时满足了空间上和时间上的动态需求;冯国富等人[11]研究了使云资源供应商获利最大化问题,同时使用了形式化的方法详细地描述了云资源的分配问题,并通过拉格朗日方法求得了能使供应商利润最大化的最优解,同时证明了该方法在云资源供应商的资源短缺的情况下具有很大的优势。
Prodan[12]站在博弈论的角度考虑问题,他采用了一种非合作博弈的模型,提出了一种主要解决云资源环境下的资源分配以及负载均衡问题的分配算法。Mihailescu[13]考虑到了动态定价问题,同时站在云用户的角度考虑,提出了一种在云资源分配过程中能提高云用户收益的动态定价方案,并通过实验证明了该种定价方案能够使云用户获得的收益更大。
Trinh等[14]提出了一种博弈论策略来解决考虑带宽分配的资源分配问题,但不考虑INs提供的有限资源。[15]提出了一种博弈论的方法,即在设备与设备之间的通信中进行能源效率的资源配置。
同时,目前也完成了许多基于拍卖的云资源分配的研究。在[16]中,为了从不同的供应商中分配一种云资源,提出了一些基于反向拍卖模型的资源分配。在[17]中,为了从不同的提供者分配各种类型的云资源,提出了一种反向批量匹配拍卖的方法。在[18]中,设计了一个连续的双向拍卖机制,使消费者和提供者能够竞标并提供一种云资源。在[19]中,为了交易一种模型,提出了一种基于知识的连续双拍卖模型。
文献[20]提出了一种资源分配算法,这种算法是基于云计算Hadoop平台的,同时在该资源分配算法中还引入了延迟调度Delay机制。文献[21]中,为了实现云资源环境下的资源分配,提出了一种基于蚁群优化算法和遗传算法的混合模型。
1.3 研究内容
云计算作为一种新型的计算模式,彻底改变了传统 IT 商业模式,越来越多的企业、事业单位和个人用户将其业务逻辑转移到云平台中,学术界也对云计算相关技术进行了广泛研究,当前研究工作重点关注云计算基础设施、资源分配、安全等方面。在互联网环境中,云平台一般由自利的 IT 公司运营,这些公司向使用云资源的用户收费来获得利润。云平台收到用户请求之后需要向用户分配资源,由于云平台的资源是有限的,所以在用户的需求数量很大的情况下,云平台不能将资源分配给每一个用户。本研究基于此背景使用强化学习方法来设计一种云资源分配的算法,给云资源供应商提供分配方案,来保证云供应商的收益最大化。
而在本文采用强化学习中一个较经典的算法Q-learning算法来对云计算资源分配问题展开了研究,首先,我们考虑市场上只有一个主动供应商提供资源的情况,若干用户向该供应商请求资源,供应商针对不同的用户请求给出对应的资源分配方案来获取最大利润。该云供应商接收不同用户的资源请求,然后经过Q-learning算法来得到分配方案确定是否分配资源,然后在用户使用完资源后将资源回收。其次,我们考虑了多个用户的情况,云资源供应商按照请求先后顺序接收到用户的请求任务,若云供应商分配给该用户云资源,则在云资源使用结束后会将资源归还给云供应商,即云供应商对云资源进行回收,然后可以将云资源分配给其他用户,以获取更多利润。
同时除了使用强化学习的Q-learning算法来解决该云资源分配问题以外,本文还使用了贪心算法来对该云资源分配问题进行研究,同时将两种算法得到的分配方案进行比较,判断那种分配方案更好,获取的利润更大,能使云供应商获取更多的利润。
1.4 论文的结构安排
本文主要研究基于强化学习算法的云资源算法研究,主要考虑了如何让云资源供应商给用户分配资源才能使供应商的利润最大化,全文共分为五章,各部分的内容安排如下:
第一章,介绍本课题的研究背景和意义,以及国内外对于本课题的研究现状以及本文的研究内容等。
第二章,介绍了强化学习以及本课题中用到的强化学习的一些基础知识以及Q-learning算法的一些基础知识,同时介绍了基于强化学习算法的云资源分配模型。
第三章,详细介绍了Q-learning算法在本课题中的应用,同时也介绍了一下比较传统的云资源分配算法,贪心算法,来比较两个算法能给云供应商带来的利润大小。
第四章,介绍了本课题中的实验,实验参数的设置,数据的统计以及分析Q-learning算法的贪心算法的实验结果,分析得到结论。
第五章,对本文的研究工作进行总结分析,并指出研究中发现的不足之处,对下一步的研究进行展望。
第2章 基于强化学习及贪心算法的资源分配
云平台资源分配问题简化其模型如下:
1、用户提交自己的资源请求给云资源供应商
2、供应商根据自己的资源剩余量来为用户分配资源,而应该如何分配才能使云资源供应商的利润最大化就是我们需要考虑的问题。
而基于强化学习的资源分配指用强化学习的方法来解决云资源分配问题,云供应商通过不断的学习,从学习中获得经验,然后根据以往经验来确定新的分配方案,以最大化供应商的利润。
2.1 强化学习理论研究
很多人工智能软件,如AlphaGo、AlphaGo Zero等,都采用强化学习作为自己的核心技术,强化学习又称增强学习或者再励学习(Reinforcement learning),属于机器学习中的一个重要分支。随着近几年深度学习、大数据和深度学习技术的飞速发展,研究者对强化学习算法以及应用有了更加广泛和深刻的关注,由此强化学习也有了更为快速的发展[22]。
强化学习解决的是一种只关心当前输入下我们应该采用什么动作才能够达到我们的目的,而不关心此时的输入长什么样的序列决策问题。换句话说就是为了使我们的任务序列达到最优,我们当前应该采用什么样的动作。而应该怎样做才能使我们到达最优任务序列呢,这就需要我们的智能体不断地与周围的环境进行交互,不断地尝试了,因为在刚开始,我们的智能体并不知道在当前状态下我们采用什么动作才能更有利于我们的目的。我们用图2.1来表示强化学习解决问题时的框架。智能体利用通过动作与环境进行交互返还的回报评估所采取的动作,一是保留有利于实现目标的动作,衰减了不利于实现目标的动作。
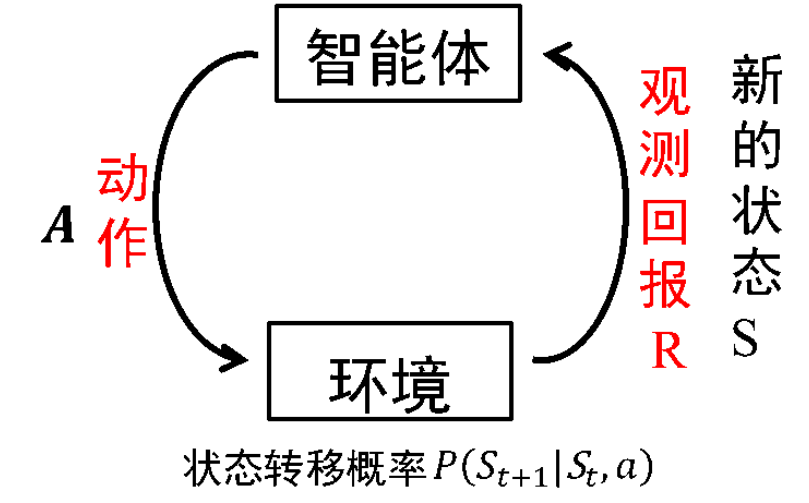
图2.1 强化学习解决问题的框架
智能体首先通过动作A与环境发生交互,在环境和动作A两者共同的作用下,智能体会发生状态转移进入一个新的状态,此时环境会根据智能体选择的动作A产生一个立即回报。然后一直循环,在环境与智能体两者的交互过程中就会产生很多的数据。强化学习算法再利用刚产生的数据更改自己的动作策略,再与环境发生交互,然后再产生新的数据,再利用刚刚产生的新数据改良自己的行为,经过不断的迭代学习,智能体最终会学到最优的动作来完成相应的任务。
强化学习是一个不断交互、动态的的学习过程,该学习过程需要的是与环境不断地发生交互产生的数据。而几十年来,无数学者们经过不断地探索和努力,提出了马尔科夫决策过程框架,这是一套能够解决大部分强化学习问题的框架
马尔科夫性指的是下一个状态与以前的状态无关,只与当前的状态有关。而马尔科夫过程是由一个二元组(S,P)组成,且这个二元组(S,P)满足:S表示有限状态集合,P表示状态转移概率。状态转移概率矩阵为:
(2.1)
而马尔科夫决策过程就是将动作和回报都考虑在内的马尔科夫过程。
下面研究一种典型的、应用极其广泛的强化学习算法—Q-learning算法
2.2 Q-learning理论研究
强化学习研究进展中一个重要里程碑就是Q-learning算法,Q-learning算法是Watkins学者于1989年提出来的[23],它是一种无模型(model free)强化学习算法。Watkins认为Q-learning也可以看成是异步动态规划过程,而Sutton则认为Q-learning学习过程可以看成是一种瞬时差分算法,并将其称为离策瞬时差分算法(off-policy TD),Q-learning通过各种“假设”动作估计最优动作,并不是根据实际策略选择的行动[24]。
Q-learning算法,一种无模型的学习算法,是强化学习诸多算法中比较重要的一种算法。而Q-learning算法是基于一个能够将智能体和环境之间的交互过程看作是一个马尔科夫决策过程(MDP)的假设,换句话说就是智能体的一个固定的转移概率分布以及下一个新的状态是由他当前所选取的动作以及所处的状态决定的,同时还会获得一个立即回报。而能够找到可以最大化将来获得的报酬正是Q-learning算法的目标,刚好云资源分配解决的主要问题也是使供应商的利益最大化,所以我利用该算法来解决问题。
Q-table,一个用来存放Q-value的表,就是Q-learning算法的核心。Q-table的行和列分别表示的是state(当前智能体的若干个状态)和action(当前智能体所能采取的动作)的值,而在当前状态下采用那个动作的好坏动作我们用Q-table的值来衡量,即当前状态下,选取更大的那个动作会更好,会使得最终获得的总收益更大。
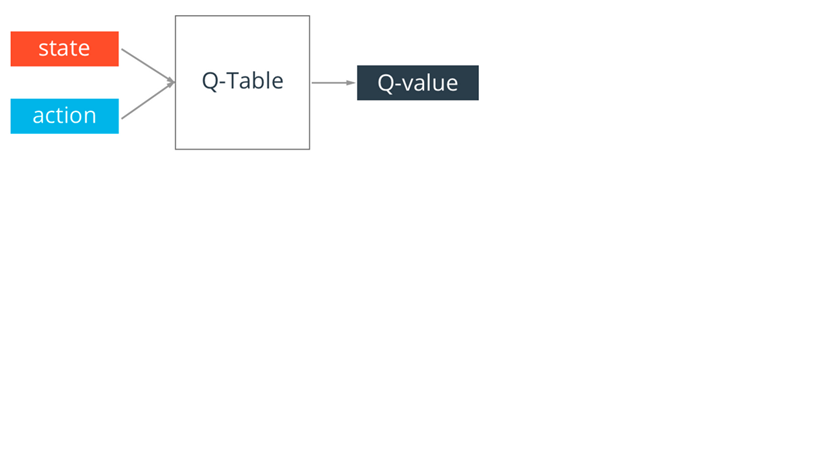
图2.2 Q-table
Q-learning算法中,每个对应的是当前状态s的选取动作a的Q值,然后智能体在不断的学习过程中,根据动作选择策略以及Q值的大小来选择更有利于最终收益的动作。
在Q-table的每次更新时,我们都会用到Q现实和Q估计,Q现实是根据当前Q表得出的Q值,Q估计是假设下一动作后计算得到的Q值,该状态下的Q的估计值,即根据选择策略选择较优动作后的下一状态的最大Q值乘以衰减值γ加上选取该较优动作后得到的立即回报。Q估计的值为:



