基于深度学习的手写字符识别毕业论文
2020-02-23 18:24:00
摘 要
本文先是介绍了识别手写字符的研究背景以及目的,再介绍了卷积神经网络。本文的核心是基于TensorFlow深度学习框架设计并实现了CNN-1、CNN-2、CNN-3。其中CNN-1是利用MNIST数据集训练的手写数字识别网络,CNN-2是利用Char74k数据集训练的手写数字识别网络,CNN-3是利用Char74k数据集训练的手写小写字母识别网络。CNN-1与CNN-2的设计旨在研究在同一网络模型架构下,不同训练集对训练识别数字结果的影响。CNN-2与CNN-3的设计旨在研究在同一网络模型架构下,识别数字与识别小写字母的训练结果差异。通过对比分析CNN-1、CNN-2和CNN-3的实验结果,得到了“对于手写字符识别模型的训练,MNIST数据集优于Char74k数据集(手写数字部分)优于Char74k数据集(手写小写字母部分)”的结论,并推出“数据集数据量越丰富且平衡,训练效果越好”等推论。最后结合主观客观因素,给出了本文的不足,并且对之后的工作以及该课题方向的发展提出了展望。
关键词:卷积神经网络;TensorFlow;手写字符识别
Abstract
This paper first introduces the research background and purpose of identifying handwritten characters, and then introduces the convolutional neural network. The core of this paper is to design and implement CNN-1, CNN-2, and CNN-3 based on the TensorFlow deep learning framework. Among them, CNN-1 is a hand-written digit recognition network trained with MNIST data sets, CNN-2 is a hand-written digit recognition network trained with Char74k data sets, and CNN-3 is a handwritten lowercase letter recognition network trained with Char74k data sets. CNN-1 and CNN-2 are designed to study the effect of different training sets on training recognition digital results under the same network model architecture. The design of CNN-2 and CNN-3 aims to study the differences in the training results of recognizing digits and identifying lowercase letters under the same network model architecture. By comparing the experimental results of CNN-1, CNN-2, and CNN-3, it was found that "For the training of handwritten character recognition models, the MNIST dataset is superior to the Char74k dataset (handwritten digit part) over the Char74k dataset (handwritten lowercase). "The letter part)" and the introduction of "the more abundant and balanced data set data, the better the training effect" and other inferences. Finally, combining the subjective and objective factors, this article gives the deficiencies, and put forward the prospects for the future work and the development of the subject.
Key Words:Convolutional neural network; TensorFlow; handwritten character recognition
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 国内外研究现状 1
1.3 研究目的与意义 2
1.4 论文的主要工作 3
第2章 深度学习的相关知识 5
2.1 深度学习的发展 5
2.2 卷积神经网络 5
2.2.1 卷积层 6
2.2.2 池化层 6
2.2.3 全连接层 7
第3章 手写字符识别模型的设计与训练 8
3.1 TensorFlow介绍 8
3.2 模型设计 8
3.3 训练数据库 9
3.3.1 MNIST数据集 9
3.3.2 Chars74K数据集 10
3.3.3 数据预处理 11
3.4 模型训练 12
3.4.1 硬件设备说明 12
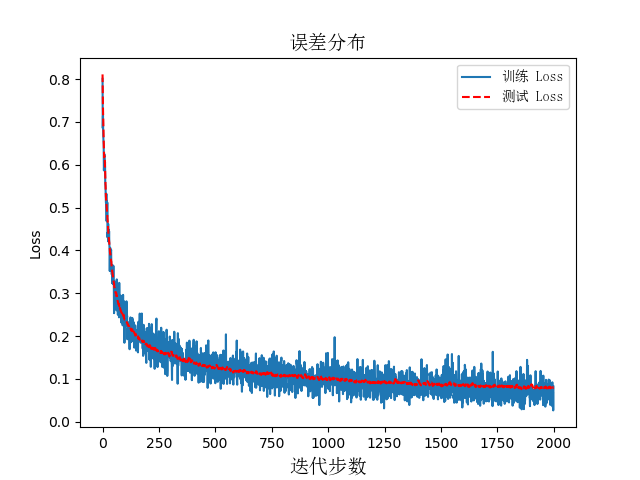
3.4.2 损失函数与优化算法 13
3.4.3 模型训练结果 14
3.4.4 模型参数保存 15
第4章 手写字符识别系统的实现 16
4.1 GUI设计与实现 16
4.2 数据采集与预处理 16
4.3 算法实现细节 17
4.4 实验结果与分析 18
4.4.1 CNN-1(数字识别)的识别结果 18
4.4.2 CNN-2(数字识别)的识别结果 18
4.4.3 CNN-3(小写字母识别)的识别结果 19
4.4.4 CNN-1 、CNN-2、 CNN-3对比分析 19
第5章 总结与展望 21
5.1 总结 21
5.2 展望 21
参考文献 23
致谢 24
- 绪论
研究背景
OCR领域(Optical Character Recognition,光学字符识别)属于图像识别领域[1],主要工作包含两部分:把手写或者打印的字符信息处理成图片信息,对图片信息进行识别把字符信息提取出来。由此可见,本课题所研究的手写字符识别是OCR领域的重要分支,也是最该领域最为核心的部分。本课题主要面临的问题是如何均衡地采集并处理数据;如何选择识别分类器以高效提取图像特征;如何对分类器进行训练等问题。
字符信息可以分为两类,文字字符信息和数据字符信息。其中,文字字符信息包含的内容较多,各个国家、各个民族的文字都属于该范畴,例如中国汉字、拉丁字母(罗马字母)等。而数据字符信息则包含的内容较少,主要是阿拉伯数字(国际通用数字)和少量特殊符号。这些手写字符已经深入人们生活的方方面面,如邮政编码、银行票据等等,这些手写字符数据量巨大,对它们进行数据处理需要大量的人力物力。对手写字符的处理引入计算机技术,可以大大提高识别、处理效率。
目前字符识别技术已经与各个领域进行了结合,它被利用到了智能计算机领域,如此智能的输入方式将提高计算机信息处理的效率[2]。这种理想的输入方式将在OA(Office Automation,办公自动化)、新闻出版、计算机输入法等领域中大放异彩。同时,字符识别技术在简化输入方式的同时,还通过将含有字符信息的文本图像转化为机器内码存储以减少大量所占用的存储空间。
手写字符识别系统主要分为两种,联机系统和脱机系统。其中,联机系统相对来说简单一些,因为联机系统的输入是一维的,连续的、可以追溯的笔划串信息,含有很多隐藏细信息,例如笔顺、笔划总数、书写速度等重要信息。脱机系统则要相对复杂些[3]。因为脱机系统的输入是二维的、静态的、无法追溯的数字点阵图像信息,且不包含其他隐藏信息,所以识别、处理这些信息相对复杂。
本文研究的是脱机手写字符识别系统,将利用卷积神经网络,基于TensorFlow深度学习框架设计并实现手写字符识别系统,完成手写数字识别与英文小写字母识别。
国内外研究现状
在字符识别领域,传统的识别方法有MRFs(Markov Random Fields, 马尔可夫随机场)、运动图像、SVM (Support Vector Machine,支持向量机)、BP神经网络、K最近邻分类算法[4]等。大量实践结果表明,以上方法中没有一种可以获得100%的识别率,都存在着一定的局限性,而且需要对图片进行统一的预处理,并且由于网络参数众多导致识别过程很复杂、费时。
近年来,应用在手写字符识别领域的方法更多是卷积神经网络,它也得到了学术界、社会范围的广泛关注。不同于传统模式识别,卷积神经网络不需要对图片进行预处理、不需要人工确定识别依据,而是直接将原始图片作为输入。随着训练过程的进行,网络将自动提取特征,依据特征对图片进行分类并且输出分类结果。实践结果表明,在同等条件下,卷积神经网络的识别准确度明显高于传统方法。
虽然构成数字字符与小写字母字符的笔划比较单一,但事实上,处理这些相似相近的字符并且在任何情况下达到较高的识别,并不十分容易,其难点主要有:
- 数字与小写字母字符集本身携带信息量少,缺少上下文信息,且相似性大,存在不规则变形;
- 手写字符的识别不可忽视个人风格。书写形变、笔画粘连的情况每个人都不一样且不存在规律性;
- 用于书写的工具、纸张以及对字符的扫描方式等现实因素都会影响字符识别。
- 在现实生活中,对单个字符的准确率要求苛刻,且对识别速度也有要求。
所以本文所要研究的脱机手写字符识别系统在如何达到高效率的问题上仍值得探究。
研究目的与意义
手写字符识别在以下领域中具有广泛的前途:
手写字符识别技术能开拓出计算机输入的新方式,在提高计算机处理信息的效率。随着计算机软件、硬件的发展,信息处理的速度越来越快,计算机输出设备除了种类繁多,输出效率也越来越高,例如激光打印的打印速度平均可达到每秒十几页A4纸。然而输入设备却一直没有什么突破,输入手段依旧是人工操作键盘,提高输入效率更多依靠个人手速与熟练度,与计算机性能无关。这使人机矛盾突出,而且不均衡的输入速度和输出速度使计算机在信息处理领域一直进步缓慢,无法进一步提高计算机系统的使用效率。而计算机自动识别字符、识别手写字符正是解决这些问题的关键所在。
计算机自动识别字符、识别手写字符是计算机智能接口的一部分。计算机智能要求计算机能像人类一样接受信息,处理信息并输出信息。视觉是人类接受信息的重要方式,所以计算机视觉应该是计算机接受信息的重要手段。目前主要是研究方向是计算机能像人类一样能识别并处理文字信息,识别并分辨图像信息等等。随着计算机智能需求的增加,越来越多领域将会用到计算机自动识别字符、识别手写字符,且应用场景将会越来越复杂。
手写字符自动识别这种输入方式一旦在OA(Office Automation,办公自动化)、新闻出版、计算机输入法等领域出现,一定会大放异彩。但目前已有的脱机手写字符识别系统达不到“又快又准确”的实用要求,另外脱机手写字符识别本质上就较联机手写字符识别更为复杂,实现起来更加困难,目前仍是一门待发展的技术。
论文的主要工作
本文旨在基于卷积神经网络,利用TensorFlow框架设计并实现手写字符识别系统,完成准确识别数字、小写字母的要求。同时,通过改变训练集,研究不同训练集对测试结果的影响,分析以得出结论。
第一章 绪论
本章介绍了本课题的研究背景等相关知识,并给出了识别手写字符的难度与应用场景,最后简要概括了各章节的主要内容。
第二章 深度学习的相关知识
本章先从概念起源、当前形式和发展方向三个角度介绍了深度学习的发展,再介绍了卷积神经网络,其中从公式概念、具体操作方面重点介绍了卷积层、池化层以及全连接层。
第三章 手写字符识别模型的设计与训练
本章说明了选用的深度学习框架,选用的数据集,给出了整个网络的架构的设计,同时描述了数据集的预处理过程、网络的训练学习过程。为了后续能得到结论,我设置并训练得到了三个对比卷积神经网络,简称为CNN-1,CNN-2,CNN-3。CNN-1是利用MNIST数据集训练的手写数字识别网络,CNN-2是利用Char74K数据集训练的手写数字识别网络,CNN-3是利用Char74k数据集训练的手写小写字母识别网络。
第四章 手写字符识别系统的实现
本章描述了手写字符识别系统的GUI设计与实现过程,以及识别算法实现细节,对收集到的原始手写字符图像在输入网络前的预处理步骤。最后得到CNN-1、CNN-2和CNN-3的实验结果,并将CNN-1与CNN-2进行对比分析,CNN-2、CNN-3进行对比分析,旨在研究同一网络模型架构下,不同训练集对训练识别数字结果的影响。
第五章 总结与展望
本章通过对比分析CNN-1、CNN-2和CNN-3的实验结果,并推出了相关的结论;然后在课题已完成的前提下,结合主观客观因素,给出了本文的不足,并且对之后的工作以及该课题方向的发展提出了展望。
深度学习的相关知识
深度学习的发展
2006年,深度学习的概念最早由G. E. Hinton 等提出。目前,越来越多的互联网公司(以Google、Microsoft、Baidu为代表)都重视起深度学习的研究[5]。经过十多年的发展,深度学习在计算机视觉、语音识别等多领域得到了广泛应用[6],但仍存在以下发展方向值得进一步研究:
深入理论研究,得到全局最优解。目前深度学习的研究大多是基于实验训练,侧重于网络架构、参数选择,得到的结果是局部最优解。要得到全局最优解,还需要更加完备深入的理论研究。
- 提高无监督学习能力。目前,卷积神经网络主要还是监督学习,需要标记数据。但在现实中大量无标记数据才是主流,添加人工标签的工作量巨大且繁杂,所以更应该发展并应用无监督学习[7]。
- 保证训练精度,同时提高训练速度。特别是在模型优化时,训练时间的长短会严重影响到调整模型规模、设置超参数、调试等问题。
- 提高记忆能力以及逻辑推理能力。目前,深度学习重视处理数据,比较忽视提高记忆能力、逻辑推理能力等。但这些能力在现实生活中,面对复杂任务时都是必要的。
深度学习仍存在无限可能,需要更加深入的研究。随着深度学习潜藏价值被挖掘出来,它将被广泛地应用于各个领域,对未来社会发展具有重大意义。
卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是第一个真正成功地采用多层层次结构网络的具有鲁棒性的深度学习方法。
相对于传统方法,将卷积神经网络应用在手写字符识别具有很大的优势。首先,对于手写字符原始图像,它所需的预处理操作非常少。这是因为卷积神经网络的网络拓扑结构与输入图像基本一致,以至于数字图像可以直接输入到网络,在训练网络的过程中进行特征的提取。另外,卷积神经网络具有局部感受域和权值共享的特性,使其网络的参数个数得到了减少,在降低网络的复杂度的同时,还缓解了网络的过拟合[8]。池化操作可以降低特征图的维数,缩小网络规模,从而大大减少计算量,节约训练网络的时间。
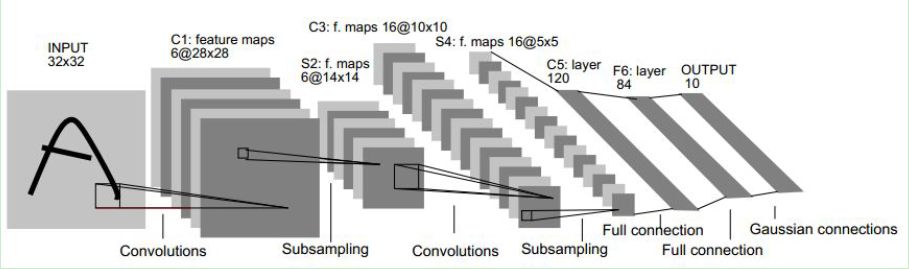 随着研究不断深入,卷积神经网络结构由简单到复杂,并且性能得到了不断的优化,应用到了越来越多其他各种领域。典型的卷积神经网络(如LeNet-5模型),主要由输入层、卷积层、池化层、全连接层以及输出层构成。
随着研究不断深入,卷积神经网络结构由简单到复杂,并且性能得到了不断的优化,应用到了越来越多其他各种领域。典型的卷积神经网络(如LeNet-5模型),主要由输入层、卷积层、池化层、全连接层以及输出层构成。
图2.1 经典的卷积神经网络——LeNet-5模型
卷积层
卷积层通过卷积操作来提取特征,低层卷积层提取的是低级特征(如边缘特征、角落特征等),卷积层层级越高,提取到的特征就越高级。
卷积操作具体是:参数可调的卷积核和输入特征图执行滑动卷积操作并加上偏置量,再整体使用一个激活函数来获得卷积结果,即为输出特征图,如式(2.1)所示。
(2.1)
其中,是第j个卷积核所覆盖的区域,是前一层(即l-1层)feature map中被所覆盖的元素;代表第l层卷积核中的元素;代表第l层经过第j个卷积核操作的输出。
池化层
池化层通过池化操作减少神经元数量,降低网络计算量,同时获得空间不变性,进行二次特征提取。
池化操作具体是:利用尺寸为n * n的池化窗口把输入特征图划分成多个不重叠的图像块,再对每个图像块采用最大池化、均值池化或者随机池化,得到缩小了n倍的图像,再加上偏置量、通过激活函数,最后得到输出特征图。最大池化如式(2.2),均值池化如式(2.3),随机池化如式(2.4)。
(2.2)
(2.3)
(2.4)
其中,是第j个n*n的池化块;是该池化块中的元素;是l层被池化后的输出,输入到l 1层feature map作为元素之一。
全连接层
经过多个卷积层和池化层之后,原始图片的高级特征基本被提取出来。全连接层通过全连接操作来连接具有不同高级特征的局部信息,并对原始图片进行分类。
全连接操作具体是:对输入特征图进行加权求和,再加上偏置量,通过激活函数,最后得到最终的输出,如式(2.5)。
(2.5)
其中,是前一层feature map中的元素(通过卷积操作、池化操作提取出的高级特征)。
手写字符识别模型的设计与训练
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: