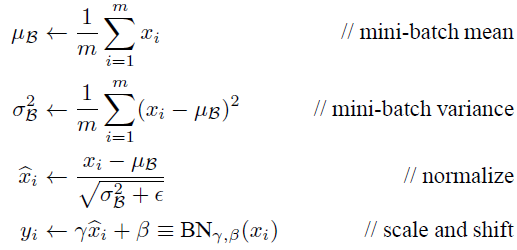基于深度学习的图像识别的研究与应用毕业论文
2020-02-23 18:24:45
摘 要
目前深度学习正在对我们的生活产生着深远的影响,它在工业生产中也发挥着重要的作用。深度学习和计算机视觉的结合是其中不可缺少的一部分。人脸识别、图片搜索、视频监控和医疗影像分析等都是图像识别的应用场景。在这样的环境下,提高图像识别技术的表现,促进进一步的规模应用,技术的不断推进是至关重要,也是我们需要做的。
本论文主要工作如下:
- 学习了卷积神经网络的原理。研究了图像分类方法和其他常用CNN模型。对于卷积层,采样层,ReLU层的使用配置方法,以及如何有机地组成了一个完整的网络。本文研究了深度模型中存在的过拟合问题和dropout解决方法,初始化方法对于训练和收敛的影响以及不同的优化方法存在的问题和改进。
- 使用MSRA初始化方法改进VGG19模型。研究了现行Xavier方法存在的问题,和MSRA做出的相应改进。通过对比实验,证明MSRA收敛较好,更加稳定和适合ReLU激励方法。
- 在VGG19中加入批量归一化层。研究了一般神经网络中出现的协方差转移问题,提出在每一层后加入归一化层,用于规范它的输出的解决方法。并通过对比实验发现加入这一层之后,训练速度大幅度加快,正确率提高了非常多。
- 在VGG19训练中引入迁移学习。学习研究了迁移学习出现是为了提高模型的泛化性能。并且可以通过迁移学习将分了问题下不同数据集的模型,相互应用。弥补数据集的过小和训练时间较短的不足,进一步提高正确率。通过对比实验证明,使用已有模型,利用他们的图像理解力,可以改进我们的模型正确率。
本论文理解并且研究了图像分类相关技术,进行基本的图像分类实验,改进了原有的VGG19模型。
关键字:卷积神经网络,VGG,batch normalization,MSRA
Abstract
At present, deep learning is having a profound impact on our lives. It also plays an important role in industrial production. The combination of deep learning and computer vision is an indispensable part of it. In such an environment, improving the performance of image recognition technology and promoting further application of scale will continue to be the key to the advancement of technology, and it is also what we need to do.Main work of this paper is as follows:
1) Learned the principles of convolutional neural networks. Image classification methods and other common CNN models were studied. For the convolutional layer, the sampling car, how to use the ReLU layer configuration method, and how to organically form a complete network. This paper studies the overfitting problems and dropout solutions that exist in the depth model, the effects of initialization methods on training and convergence, and the problems and improvements in different optimization methods.
2) Use the MSRA initialization method to improve the VGG19 model. The problems existing in the current Xavier method were studied, and the corresponding improvements made by MSRA. Through comparison experiments, it is proved that MSRA has good convergence, is more stable, and is suitable for ReLU incentive method.
3) Add BN layers in VGG19. The problem of covariance transfer in general neural networks is studied, and a solution for normalizing its output is proposed by adding a normalized layer after each layer. And through comparison experiments, it was found that after this layer was added, the training speed was greatly accelerated, and the accuracy rate was greatly increased.
4) Introduce migration learning in VGG19 training. Learning to study the emergence of migration learning is to improve the generalization performance of the model. And through migration learning, the models of different data sets under the problem can be divided and applied to each other. Make up for the shortcomings of too small data sets and shorter training time, and further improve the accuracy rate. The comparison experiments show that using existing models and using their image understanding can improve the accuracy of our model.
This paper understands and studies the techniques of image classification, performs basic image classification experiments, and improves the original VGG model.
Keyword: CNN, batch normalization, MSRA, VGG
目 录
第1章 绪论 1
1.1研究背景及意义 1
1.1.1 研究背景 1
1.1.2 研究意义 2
1.2国内外发展概况 2
1.3 数据集介绍 3
1.4论文研究内容 4
第2章 相关技术介绍 6
2.1 卷积神经网络 6
2.2 图像分类研究 6
2.2.1过拟合 6
2.2.2 Adam优化算法 7
2.2.3 Xavier初始化 7
第3章 图像分类模型与调整 9
3.1 图像分类模型 9
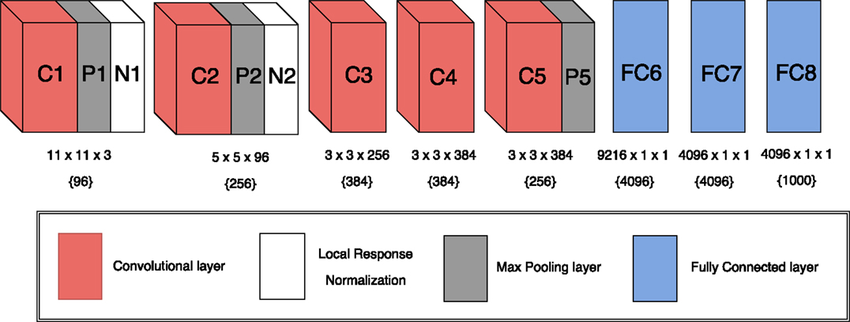
3.1.1 AlexNet 模型 9
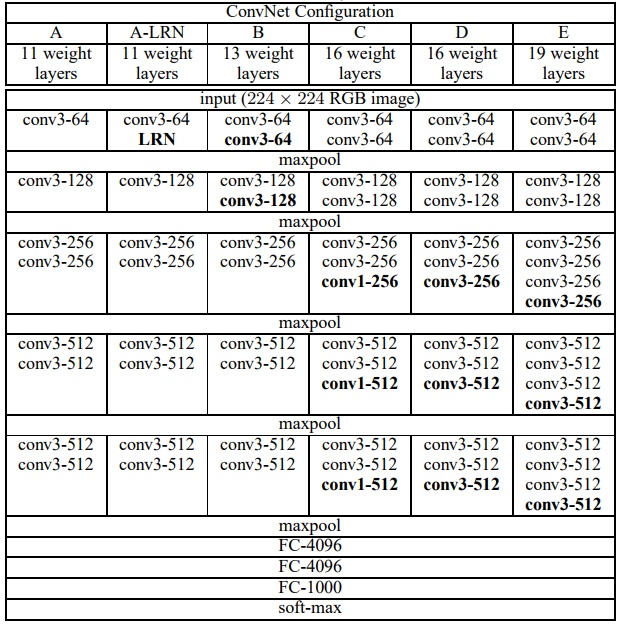
3.1.2 VGG模型 9
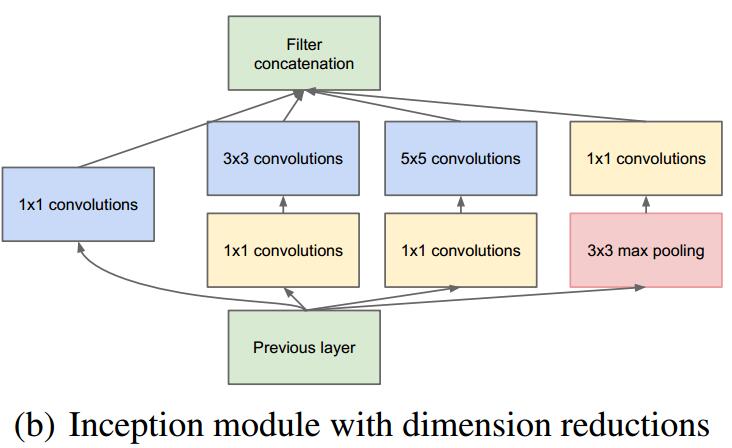
3.1.3 GoogLeNet 模型 10
3.2 VGG模型及调整 11
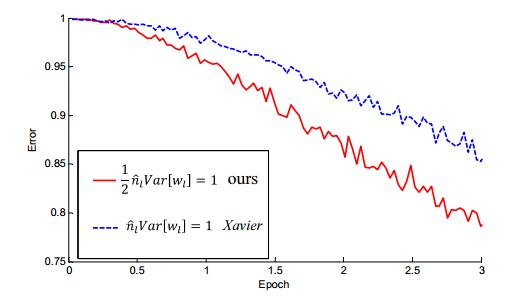
3.2.1 MSRA初始化 11
3.2.2批量归一化 13
3.2.3迁移学习 15
第4章 实验及结果分析 16
4.1 实验基本设置 16
4.1.1环境配置 16
4.1.3 DIGITS 创建训练数据 17
4.1.4 DIGITS 模型配置 18
4.2 MSRA实验及分析 19
4.3批量归一化实验及分析 21
4.4迁移学习实验及分析 23
4.5总实验结果分析 24
第5章 总结与展望 27
致谢 28
参考文献 29
第1章 绪论
1.1研究背景及意义
1.1.1 研究背景
神经网络的历史可以追溯到1943年,沃伦麦卡洛克和沃尔特皮茨创造的基于数学和阈值逻辑的ANN模型。后人这个基础上逐渐研究,相继制造出第一个多层感知机,深度神经网络,研究出反向传播max-pooling算法,循环神经网络等等,我们稍后会提到。但是相对来说,机器学习知识结构简单,所需要的计算资源较少,可行性较高,所以神经网络在发展过程中有一些停滞期。然而在近来几年随着各方面条件不断成熟,神经网络知识体系继续壮大,神经网络再次变得热门。
GPU是必须的硬件条件。GPU非常适合用于机器学习的矩阵/矢量数学,GPU可以将训练算法加速几个数量级,从而将运行时间从几周缩短到几天,可以使用专门的硬件和算法优化进行高效处理。Google Brain使用Nvidia GPU来创建功能强大的DNN。 在那里,吴恩达证明GPU可以将神经网络的训练速度成倍进步。
精确的标记数据集满足了精确数据的要求。李飞飞教授意识到,仅仅像学界那样埋头研究算法而不关心数据是否合格是有局限的。但是她认为数据同样重要。她在亚马逊相应平台进行众筹,用了两年半形成最后的ImageNet。ImageNet数据集一共有230万张标记图片,共分为5246种类别。许多研究人员发现通过ImageNet,他们的算法性能得到了提升,也有很多著名的算法在ImageNet竞赛中产生。
相关技术在本世纪继续发展也是非常重要的条件。网络架构不断得到改进,例如在卷积神经网络范围内,从最初的LeNet,到12年的AlexNet,以后的GoogleNet, VGG, ResNet,以及在这些架构上的不断改良。ReLU激励函数出现之前,一直使用的是类似于神经元的Sigmoid激励函数,而后是ReLU的各种变式。Dropout, batch normalization相继出现。优化方法不断改进。新的理论不断产生。
软件开发平台的不断发展,降低了个人学习神经网络的门槛,满足了人各种各样的需求。越来越多的开发工具出现在人们的眼前,有可视化开发工具如NVIDIA DIGITS,较为简单的keras,和功能比较齐全,性能比较好的一般框架如tensorflow。这些工具的出现对底层进行了一定抽象和实现,提高了人们的开发效率。
深度学习网络不断取得新的成就激励着人们学习,语音助手深入我们的日常生活,自动驾驶汽车不断前进,AlphaGo与人类的史诗级对局等等。人们对于深度学习的有了越来越多的热情,工业界对于神经网络投入增加,并且在不断竞争夺取人工智能的制高点。
1.1.2 研究意义
当前计算机视觉被规模化使用。人脸识别以图像识别技术为基础,广泛应用于公共安全,金融,教育和IT产业,可以用来进行考勤门禁,进行身份认证,活体检测,人脸搜索,人脸关键点定位。监控分析技术用于物体、商品智能识别定位,道路车辆行为分析。在大量人群流动的交通枢纽,该技术也被广泛用于人群分析、防控预警等。静态图片识别分析可以用于以图搜图,物体场景分析,鉴定黄色暴力图片等。汽车是人工智能技术的非常大的应用投放方向,也就是说自动驾驶技术。当前自动驾驶汽车还有很多技术需要攻克,深入研究图像识别会有所帮助。在医院等地方,医疗图片有大量病人信息。医疗影像领域拥有孕育深度学习的海量数据,医疗影像诊断可以辅助医生,提升医生的诊断的效率[1]。文字识别基于OCR技术,将图片转化为文字,很多软件都用到了这一功能,且准确率非常高,增加图片利用效率。因此计算机视觉有很大的应用可能性,充分应用可能会改变我们信息运用方式进而影响生活。
1.2国内外发展概况
上文提到神经网络始于1943年,之后在1965年Alexey Ivaknenko 和 Lapa将理论付诸实践创造出第一个前馈深度多层感知机,1971年他们做出一个8层的使用数据处理算法的组方法训练的深度网络。
1975年Goff Hinton提出了反向传播算法,对于以后研究有很大影响。通过链式求导得出所有权重对于损失函数的梯度,并将该梯度反馈给优化方法,用来更新权值[2]。
1989年,Yann LeCun 做邮政编码识别的时候,提出了LeNet模型,它拥有卷积层、池化层、全连接层这些现代卷积神经网络组件,为以后的卷积神经网络打下了基础。
max-pooling技术于1992年被引入以帮助最小的移位不变性和对变形的容忍度,以帮助3D物体识别,在2010年,被证实在GPU加速的反向传播训练中优于其他的池化方法。
循环神经网络(RNN)诞生于1980s,并且 1997年 Hochreiter 和 Schmidhuber创作出广泛使用的RNN模型 - LSTM模型,它比其他类似网络改进了长短时依赖。
2006年Geoffrey Hinton的A fast learning algorithm for deep belief nets提出了深度置信网络(DBF).它是一种生成模型,由受限玻尔兹曼机(RBM)组成,通过训练其神经元间的权重,我们可以让整个神经网络按照最大概率来生成训练数据。
AlexNet应用的dropout,ReLU具有指导意义。相继2014年Google 的 Going Deeper with Convolutions提出GoogleNet模型,它使用模块的结构,更多的卷积,更深的层次得到ILSVRC2014图像分类的冠军,同样来自英国的发表very deep convolutional networks for large-scale image recognition,提出VGG模型探讨深度与精确程度的关系取得了当年分类任务的亚军。2015年微软亚洲研究院获得当年的冠军,他们的模型是深度残差网络(ResNet),最深的有152层,它的特殊在于设计了瓶颈形式的模块。
2015年Google工程师提出batch normalization的概念。它简化了我们调参的过程,不再需要可以地慢慢调整参数,可以让你使用较大的初始学习率,不再使用dropout等正则层。它在网络的每一层输入的时候,插入归一化层,使网络每层输入固定下来,解决了内部协变量变化的问题。
1.3 数据集介绍
本论文中采用的是Cifar10图片标记数据集,它是由多伦多大学的Alex Krizhevsky, Vinod Nair, 和Geoffrey Hinton收集创建的。Cifar10一共包括6万张图片,共有5万张用于训练,1万张用于测试。(图)每张图片的像素为32×32的RGB图像,一共分为10个类别,每个类别由6000张图片。
图1.1显示的数据集中图片的类别,一共十个,后续图片是每个类别中的随机10张图片:
图1.2是训练数据的train.txt,可以看见它包含两列文字。第一列是图片的绝对路径,从路径中我们可以得到每个图片为PNG格式,不同类别的图片放在不同的文件夹。第二列是一个数字,它的意思是图片的类别,范围为0-9,和图1.1中类别相呼应,例如airplane为类别0,truck为类别9。

 1.4论文研究内容
1.4论文研究内容
图1.2 数据集标记文件
图1.1 cifar10的十个类别和样例图片
本次论文是在VGG19模型的基础下,对于Cifar10图像数据集进行图像分类任务。在实现图像分类任务的同时,为了尽可能地提高图像分类的正确率,对于原有模型VGG19和它的训练方式进行一些改进和扩展。
本论文研究的内容如下:
- 说明基本的卷积神经网络和VGG模型结构,介绍各部分的功能。
- 研究初始化方法对于网络收敛的作用,介绍常见的初始化方法,进行初始化方法Xavier、MSRA的相应实验。
- 对于批量归一化的实现的研究,介绍它的优点和可能对于网络的改进,并进行相关实验。
- 在他人训练成功的相同模型上,使用他们的模型权重,进行实验,检测它对于实验结果和过程的改进。
第2章 相关技术介绍
2.1 卷积神经网络
一般神经网络上的每一层都是由神经元组成,每一层之间神经元相互连接,他们可以通过训练进行学习。和一般函数模型相同,他们有输入,输出,可以简化为公式,其中W,b是需要学习的参数权重和偏置。
卷积神经网络由卷积层,池化层和全连接层组成[3]。卷积神经网络的特殊在于通过卷积层权值共享,大幅度降低了参数数量[4]。一个卷积神经网络通常有许多卷积层,而且卷积神经网络越深,网络表现越好。卷积层通过对输入图像进行卷积运算获取图像关键信息,而卷积层就是卷积运算中的卷积核[5,6,7]。在convolution层中,设定的参数有:1) 步长 2)卷积核大小 3)0填充的大小。通过控制参数,确定输出图像大小。池化层对于卷积层的输出进行下采样,获取图片的关键信息,对于输入规模进行压缩和简化网络。Max-pooling应用最广泛。通常池化层进行运算的单元都比较小,例如2×2或3×3.全连接层是一般的神经网络组成,主要对于卷积层的信特征进行整合,并且将数据交给损失函数或者线性回归预测函数。
2.2 图像分类研究
2.2.1过拟合
因为参数过多,过拟合是大型网络中存在的很大问题。尤其是当我们数据有限的时候,网络会花费时间学习噪声数据,导致在测试时,表现很差。
当我们有无限的计算资源时,以“正规化”固定大小的模型中的最好的方法是平均所有可能预测的参数,加权给出训练数据及其后验概率的每个设置。然而训练神经网络开销过大,不适合重复运算。而且,数据可能不足以训练。即使能够训练许多不同的大型网络,在测试,要求快速响应时使用它们都是不可行的。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: