基于K-means的聚类分析及改进毕业论文
2020-04-10 16:14:41
摘 要
随着大数据时代的到来,数据挖掘在未来呈现出强劲的发展态势。聚类分析作为其一个重要分支,其应用也逐渐呈多领域方向发展,这要求算法种类必须与时俱进,满足时代要求。聚类分析指的是,在没有预知的条件下,将数据集划分为几个不同的簇;簇内具有相似性,簇间具有差异性。K-means算法是一种简单实用的聚类分析算法。以下是本文的主要工作内容:
1. 详细讨论了k-means算法的原理,并对算法的收敛性进行了分析。对该算法进行了实现。通过对实验的结果进行分析,发现该算法有良好的聚类效果,但仍存在些许不足:一、初始质心的选取;二、k值的选取;三、有噪数据对聚类结果的影响。
2. 针对初始质心的选取问题,介绍了k-means 和二分k均值两种算法。详细讨论了这两种算法的原理;并对两种算法进行了实现。通过对两种算法的实验结果进行对比,发现k-means 算法的效果稍微好一些,而二分k均值算法对克服局部最优解效果更好。
3. 针对k值的选取问题,介绍了ISODATA算法。详细介绍了该算法的原理;并对该算法进行了实现。通过对实验结果进行分析,可知该算法中k值的选取是通过不断地合并与分裂来选取的,其中k值是不断变化的。该算法通过选取合适的k值来减少类别数对聚类的影响。
4. 在实际当中,数据当中往往存在许多孤立点。这些孤立点会对聚类造成影响,可通过PCA降噪对数据进行处理。可以先通过PCA去除孤立点,然后再对这些数据进行k-means算法聚类,来取得良好的聚类效果。
关键字:数据挖掘、聚类算法、k-means算法、k-means 算法、二分k-means算法、PCA
Abstract
With the coming of the big data era, data mining will show a strong development trend in the future. As an important branch of clustering analysis, the application of clustering analysis has been developing in many fields. This requires that the type of algorithm must keep pace with the times and meet the requirements of the times. Clustering analysis means that the data set is divided into several clusters without prior knowledge, and the clusters are similar and have different clusters. K-means algorithm is a simple and practical clustering analysis algorithm. The following is the main work of this article:
1. the principle of K-means algorithm is discussed in detail, and the convergence of the algorithm is analyzed. The algorithm is implemented. Through the analysis of the results of the experiment, it is found that the algorithm has a good clustering effect, but there are still some shortcomings: first, the selection of initial centroid, the selection of two, K value, and three, the influence of noisy data on the clustering results.
2. for the selection of initial centroid, two algorithms of k-means and two points K mean are introduced. The principles of the two algorithms are discussed in detail, and the two algorithms are implemented. By comparing the experimental results of the two algorithms, it is found that the effect of the k-means algorithm is slightly better, while the two - point K mean algorithm is better for overcoming the local optimal solution.
3. for the selection of K value, ISODATA algorithm is introduced. The principle of the algorithm is introduced in detail, and the algorithm is implemented. Through the analysis of the experimental results, we can see that the selection of K value in the algorithm is selected through continuous merging and splitting, and the K value is constantly changing. This algorithm reduces the influence of class number on clustering by selecting the appropriate K value.
4. in practice, there are often many outliers in data. These outliers will affect clustering, and data can be processed through PCA noise reduction. We can first remove the outliers by PCA, and then cluster these data with k-means algorithm to achieve good clustering results.
Keywords: data mining, clustering algorithm, K-means algorithm, k-means algorithm, two point k-means algorithm, PCA denoising
目录
第一章 绪论 1
1.1研究背景和意义 1
1.2国内外研究概况 1
1.2.1数据挖掘研究现状 1
1.2.2聚类分析研究现状 2
1.2.3 算法改进研究现状 3
1.3本文结构 3
第二章 k-means算法的原理及实现 5
2.1 k-means算法的原理 5
2.2 算法的收敛性 5
2.2.1 EM算法的收敛性 5
2.2.2 k-means的收敛性 7
2.3 k-means算法的实现 7
2.4 实验结果及分析 9
2.5 本章小结 10
第三章 针对k-means算法初始质心的改进与实现 11
3.1 k-means 算法的原理及实现 11
3.1.1 k-means 算法的原理 11
3.1.2 k-means 算法的实现 11
3.1.3 实验结果及分析 12
3.2 二分k均值算法的原理及实现 14
3.2.1 二分k均值算法的原理 14
3.2.2 二分k均值算法的实现 14
3.2.3 实验结果及分析 16
3.3 本章小结 17
第四章 针对k-means算法k值的改进及实现 18
4.1 ISODATA算法的原理 18
4.2 ISODATA算法的实现 18
4.3 实验结果及分析 21
4.4 本章小结 22
第五章 针对有噪数据的k-means算法实现 23
5.1 噪声对聚类结果的影响 23
5.2 PCA数据降噪的原理 24
5.3 针对有噪数据的PCA与k-means相结合的聚类算法实现 26
5.4 本章小结 27
第六章 结论与展望 28
6.1 结论 28
6.2 展望 28
参考文献 30
致谢 32
第一章 绪论
1.1研究背景和意义
随着大数据时代的到来,以及数据库技术的飞速发展,当今社会拥有的数据越来越多。人们每天都会产生海量的数据,信息急剧膨胀是当今社会的主要特点。与此同时,我们也面临着一个严峻的问题,如何才能更好的利用这数以亿计的数据。随着数据积累的越来越多,人们对更好的利用这海量数据的需求也变得越来越迫切,如何挖掘到这海量信息背后的隐藏信息,并且发挥出其最大价值变得日益重要。但是,我们会发现很难获得在这大量数据背后隐藏的有用信息和知识。这就导致“数据爆炸但知识匮乏”现象的出现,以及Data Mining技术的产生。
数据挖掘(DM)是指从大量不规则数据中选择具有较高利用价值的信息的过程。这一技术引起了人们的广泛关注,同时也推动了信息技术的进步,加快了将隐藏数据向有用信息转化的过程。数据挖掘是一门交叉学科,覆盖了很多方面。这其中涉及统计学、计算机程序设计、数学与算法、数据库、机器学习、市场营销、数据可视化等领域的理论和实践成果。
聚类是一种无监督学习算法,在发现大数据背后隐藏的有用信息方面扮演越来越重要的位置。根据“物以类聚”的基本思想,按照一定标准对数据进行分类。分类原则是,同一簇间的数据具有相似性,不同簇间的数据具有差异性。聚类分析有着广泛的应用,涉及到天文学、地理学、生物学、信息检索、文本挖掘、客户关系管理和图像处理等。同时,在数据挖掘领域,随着当今社会数据越来越多,聚类分析也变得越来越重要。
k-means算法是一种无监督学习算法[1]。其优点是简单高效、易于实现,所以应用也很广泛,能够处理大数据。另外该算法也存在很大的局限性,首先,k值需要人为事先设定;其次,初始质心的选取也是随机的,该过程会对聚类结果造成很大影响[2]。针对部分缺点,本文做了些许改进。
1.2国内外研究概况
1.2.1数据挖掘研究现状
数据挖掘(KDD)一词,是在一九八九年八月被提出来的,该领域的出现顺应了时代的发展潮流,符合未来信息领域的发展趋势—大数据时代。该领域的研究规模也由最初的几十人发展到今天上亿人,研究重点也随着时代的不同发生了改变,毕竟随着时代发展,数据越来越多,数据的种类越来越广泛,需要我们处理的信息量也变大,这对我们的处理能力提出了更高的要求。
自1998年在纽约召开第四次知识发现和数据挖掘国际会议以来,许多软件公司已经引入了许多数据挖掘应用系统。在1989年提出KDD一词后的十多年里,多家公司推出了很多相应软件。许多西方国家便引进了这些数据挖掘软件,并进行了深入推广,尤其是北美、欧洲地区的国家。
我国的数据挖掘技术研究起步很晚,直到1993年,才得到国家自然科学基金的支持。在之前,我国的研究领域也比较广,主要集中在学校、企业和研究所。九三年之后,学术界、商业界等领域才逐渐重视数据挖掘的研究和应用。
此外,国际上在许多领域也开辟了KDD专题。1993出版KDD技术期刊。发表的五篇论文代表了当时KDD研究的最新成果和趋势。对知识发现系统的设计方法、发现结果的评价以及知识发现系统设计的逻辑方法进行了全面的论述。针对KDD系统存在的动态冗余、高噪声和不确定性、数据库零值等问题,讨论了KDD系统与其他传统机器学习、专家系统、人工神经网络、数理统计分析系统的关系和区别,以及相应的基本对策。本文总结了KDD在分子建模、设计和制造等方面的具体应用。
1.2.2聚类分析研究现状
聚类分析,是指从一个样本集中,找出合适的样本的一种算法,和分类类似,但又有着很大的不同。聚类是一种无监督学习算法。按照某一种标准,对数据对象进行划分,分成若干的类。目标是同一组中的数据相似,而不同组之间的数据相差很大。同一组中的相似度越大,不同组之间的差异越大,这意味着聚类效果越好[3]。
与传统的聚类分析对比,数据挖掘技术有着很大不同。当今的时代是大数据时代,我们每天要处理数百万个由几百甚至上千种特征组成的数据,传统的聚类分析算法很多已经不再适应。然而,现在存在的一个需要大家解决的问题是,大数据中有许多既包含数值特征又包含类属特征的数据。许多聚类算法可以同时处理这两种类型的数据[4],但不能同时处理很多数据。或者,有一些聚类算法可以处理大量数据,但它们不能同时处理这两个数据。因此,其高效性逐渐得到越来越多人的重视。
聚类分析的主要研究方向有以下。聚类算法有很强的可伸缩性,聚类算法处理的数据类型应该多样化,聚类算法的输入参数问题,聚类算法的簇形状,聚类算法的输入顺序,聚类算法的高维性,聚类算法的约束性,聚类算法中噪声数据问题[5],聚类算法的可解释和可用性等等。聚类分析具有广阔的发展前景,其应用必定也会越来越广泛、越深入。
聚类在许多领域都有着应用。其中,商业领域,生物学领域,地理行业,金融业,保险行业,医疗领域,因特网领域,电子商务领域等等,占的比重比较大。例如,在地理领域,聚类可以使地球上观察到的数据库供应商趋于相似。在internet领域,聚类分析用于对internet上的文档进行分类以修复信息。
1.2.3 算法改进研究现状
k-means算法有很多优点,但也存在着某些缺陷,最主要的是必须预先知道初始质心才能使用该算法。该算法作为一种非常简单的算法[6],在得到广泛应用的同时,也有很多地方需要改进,以下是该算法存在的一些缺陷。一、具有局部最优解,而非全局最优解[7];二、初始值k需要事先设定;三,初始质心的选择较难。针对这些缺点,做了很多针对性的改进。针对局部最优解问题,可用二分k均值算法来改进;针对初始值k的设定问题,可用模糊聚类算法来进行改进;针对初始质心的选择较难,可用k-means 算法来进行改进。K均值算法存在很多优点,但也或多或少的存在一些缺点,这些缺点很难用一种算法同时克服,故本文针对其中的某一两个缺点进行单独的改进。
通过研究发现,上述方法有一个共同的缺陷,那就是这些聚类算法在聚类过程中无法自主确定簇的个数,都需要靠人工主观给定最终聚类结果的数目。这种靠人工主观来确定聚类数目在大多数情况下是不合理的。这就迫切需要有一种技术能自适应的的确定文本聚类的数目,进而发现文本潜在的主题数。以上算法只能把每一个聚类对象划分到一个聚类簇中。属于硬聚类算法。然而,有些时候,按照某一规则对聚类对象进行划分并不能很好的反映客观事实,为解决这一问题,FCM应运而生。
1.3本文结构
对于k-means算法的实现以及其改进,本文共用六章对其讨论:
第一章,绪论。详细介绍本文的研究背景、研究目的、KDD技术和聚类的国内外发展现状,以及文章的结构。阐述数据挖掘技术和聚类分析的基本概念、技术的实现原理以及在当今社会的应用等。在这些基础上,我们对KDD的国内外发展现状,以及其过程、任务、对象做了简单的了解,对聚类分析的国内外发展现状,以及其优缺点,尤其是k-means算法做了更加详细的介绍[8]。
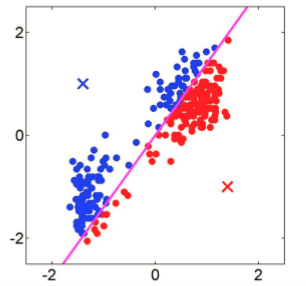
第二章,k-means算法的原理、收敛性及实现[9]。本章会详细讲解该算法的原理,存在的优缺点以及相关的距离公式;画出该算法的实现框图、伪代码;画出该算法代码运行后的实际效果图,并对实际效果做出对比和说明。
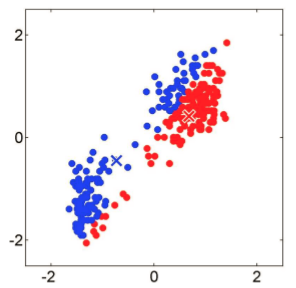
第三章,针对k均值算法初始质心的选取做出的改进。主要介绍了k-means 算法、二分k均值算法的原理及实现[10]。本章会详细讲解这两种算法的原理,并与k-means算法原理做出对比;画出该算法的实现流程图、伪代码,并作一定说明;画出该算法代码运行后的实际效果图,选取不同k值,并对实际效果做出对比和说明,与k-means算法的实际效果图做出对比,观察改进效果。
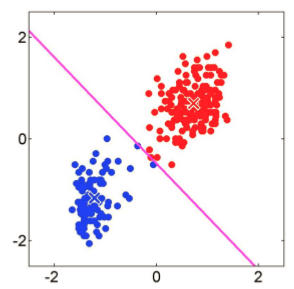
第四章,针对k值的选取,采用ISODATA算法来改进。本章会详细讲解该算法的原理,实现的步骤;对算法进行实现,通过与k-means、k-means 、二分k均值算法实验结果的对比,来观察该算法的优点。
第五章,本章主要讲解有噪数据对聚类的影响,PCA降维的原理、步骤,以及针对有噪数据的PCA与k-means算法结合的聚类实现。详细介绍了PCA降维对聚类的重要性以及必要性,通过PCA可以对数据进行预处理。讲解了簇的合并与分裂的具体操作步骤。
第六章,总结全文,客观分析本论文研究的意义,比较k均值算法及其三种改进方法,掌握编写论文的整体思路,为接下来的学习打下基础。
第二章 k-means算法的原理及实现
2.1 k-means算法的原理
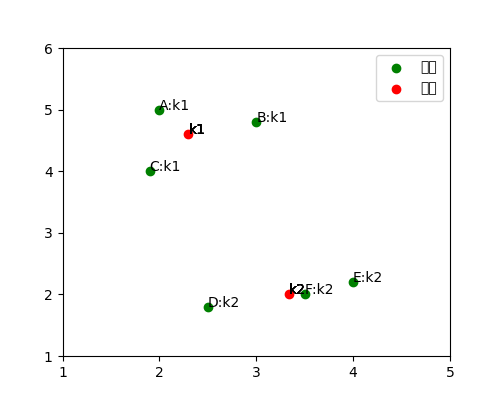
k-means算法的原理很简单,对于整个数据集,按照样本间距离远近随机分为k个类。要求是同一个类内的数据距离较近,类与类之间的距离较远。
表达式如下,其中k为要将数据集分成的类的个数,E为聚类的最小化平方误差:
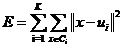 (2.1)
(2.1)
在公式2.1中,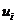 是数据均值,即聚类中心。表达式为:
是数据均值,即聚类中心。表达式为:
 (2.2)
(2.2)
2.2 算法的收敛性
2.2.1 EM算法的收敛性
通过极大似然估计建立目标函数:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: