主题网络爬虫的研究与实现毕业论文
2020-04-11 18:02:43
摘 要
随着时代的进步,互联网深入们的生活,其承载着的丰富讯息正不断的影响人们,然而,随着信息时代的飞速发展,互联网上的信息量正在高速膨胀,如何通过网页便捷地查询到真正所需要的信息成为了困扰大家的难题。传统的通用搜索引擎在很大程度上为人们在因特网上查找信息提供了很多方便,但也暴露出查准率不高等不足。因此,新的研究方向:主题搜索引擎被提出。
主题搜索引擎也称为主题爬虫,主题爬虫专门对特定主题或领域有特定要求的用户提供搜索服务,并负责将用户感兴趣的某一主题相关的网页、内容进行抓取下载。
本文前半部分通过对通用爬虫与主题爬虫的结构进行介绍与对比,详细介绍了主题爬虫的实现方式与关键技术,并且根据对内容评价搜索策略与对链接结构评价的搜索策略的研究对比选取。后半部分详细介绍了主题爬虫的体系结构,对其组成模块进行分析,并以Python作为编程语言,在Windows操作平台上实现了以豆瓣读书为初始页面,运用基于内容评价的搜素策略,对书籍信息进行抓取筛选的主题爬虫,并达到了预期的效果。
关键词:主题爬虫,网页抓取,搜索引擎
Abstract
With the progress of the times, the Internet enters people's life, which carries a rich message that is constantly affecting people's life. However, with the rapid development of the information age, the amount of information on the Internet is expanding rapidly. It is difficult to find the information that is really needed through the web page conveniently. Question. The traditional general search engine provides a lot of convenience for people to find information on the Internet, but it also reveals that the accuracy rate is not high enough. Therefore, topic search engine technology has become a new research direction.
Themed search engines, also known as themed crawlers, provide targeted search services for specific directions, specific users, and capture web pages and contents related to a particular topic of interest to the user.
The first part of this paper introduces and compares the structure of common crawler and theme crawler, and introduces the implementation and key technology of the subject crawler in detail, and improves the search strategy of content evaluation and the search strategy for the link structure evaluation. In the second half, the architecture of the subject crawler is introduced in detail, and Python is used as a programming language. On the Windows operation platform, the subject crawler is carried out to screen the book information as the initial page, and the desired effect is achieved.
Key words: Topical Crawler, Web capture,Search Engines
目录
摘要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.3 本文主要内容与结构 2
第2章 编程语言与爬虫框架概述 3
2.1 各类编程语言对比 3
2.2 python语言简介 3
2.3 通用爬虫系统结构 4
2.4 通用爬虫的爬行策略 5
2.5 主题爬虫的的体系结构 6
2.6 主题爬虫的搜索策略 7
2.6.1 基于内容评价的搜索策略 7
2.6.2 基于链接结构评价的搜索策略 7
第3章 主题爬虫模块介绍 9
3.1 初选种子与URL队列 9
3.2 网页解析 9
3.3 网页信息的提取 10
3.4 中文分词 12
3.4.1 基于字符串匹配的分词方法 12
3.4.2 基于统计的分词方法 13
3.4.3 结巴分词 13
3.5 主题相关性计算 14
第4章 主题爬虫的设计与运行 15
4.1 系统平台 15
4.2 系统界面与操作流程 15
4.3 结果分析 17
第5章 总结与展望 20
5.1 全文总结 20
5.2 问题与展望 20
参考文献 21
致谢 22
第1章 绪论
1.1 研究背景与意义
随着信息时代的来临与发展,互联网与人们的日常生活联系越来越紧密切且难以分割,随着“互联网 ”概念的提起,“互联网思维”被大家所接受并推广,从而促进了互联网的迅速发展,因此,互联网上的信息量正在不断的膨胀[1]。如何在如此巨大的信息空间里准确查找并获取人们所需要的信息成为了困扰大家的问题。现在主流的捜索引擎很多,常用引擎就有 google、百度等等,虽然他们能返回大量的网页信息,但是在结果中常常也会包含大量不准确的内容,针对这个问题,垂直搜索引擎应运而生,垂直搜索引擎的设计用意主要就是为了满足特定领域与特定人群的特定需求,为这些用户提供专业方向的查询与信息服务[2]。
垂直搜索引擎也可称之为主题网络爬虫,主题网络爬虫负责抓取数据并且将数据保存以提供索引。主题爬虫的工作原理是基于一定的算法,预设一个主题,在抓取网页页面时根据算法计算页面与信息的主题相关度,将得到的相关度不够的页面与信息丢弃,将符合要求的内容留下,并不断的循环上述的过程,直到满足结束抓取的条件结束抓取。本文通过对基于内容和链接两种搜索策略的研究与对比,运用基于内容的爬行策略,实现了一个以书籍选取为主题,对书名、简介等内容抓取的主题网络爬虫系统。
1.2 国内外研究现状
主题爬虫的任务是根据预设定主题,从起始网页开始,按照一定的方式,在网页上尽可能多的获取与主题相关的数据资源。所以爬行的策略就显得尤为重要,也致使众多的国内外学者在这方面付出努力,目前比较成熟的爬行策略主要有以下两类:
基于文字内容评价的爬行方法,就是通过对网页的文字内容进行提取分析,进而计算、判断候选链接所指向的网页的主题相关性[3]。基于文字内容评价的算法有三种1.Fish-Search算法,顾名思义,该方法将主题爬虫比喻成海里的鱼群,当这群鱼发现食物(即相关信息)时,就继续繁殖并寻找新的食物;当没有发现食物(即无相关信息)或水被污染(即带宽不够)时,它们就会死掉(即停止爬取)。在判断主题相关性时,该算法运用的是一个二元值,在判断值上比较单一,所以不能比较好的区分链接的优先级,在使用上不够准确。2.为弥补Fish-Search算法的不足,M.Hersovici等人使用了相似度算法,将页面的相关性值计算成为0~1中的连续值,还综合考虑了网页文本信息等带来的影响,这就是Shark-Search算法。3. Best- First算法,该算法是用空间向量模型来表示网页的关键词,然后根据向量来计算网页的相关性,再根据计算的值来判断链接的优先级别[4]。基于文字内容的评价方法并没有考虑到链接结构对爬虫的影响,会导致爬虫错过一些比较权威的网页。
基于链接结构评价的方法,其核心为以不同的网页间相互指向的链接结构来判断网页重要性,从而指导主题爬行过程,该方法的实现主要有两种算法:PageRank算法与HITS算法[3]。
PageRank算法是由Google的两位创始人S.Brin和L.Page于1998年提出的,这种算法与网页之间的相互指向有关,其核心思想为:当一个网页被其他网页所指向时,就增加该网页的价值,被指向的次数越多,则价值越高,当被价值高的网页指向时,也说明该网页价值高。根据这个思想,该算法根据连接它的网页链接的重要性与数量来判断此网页的重要性。
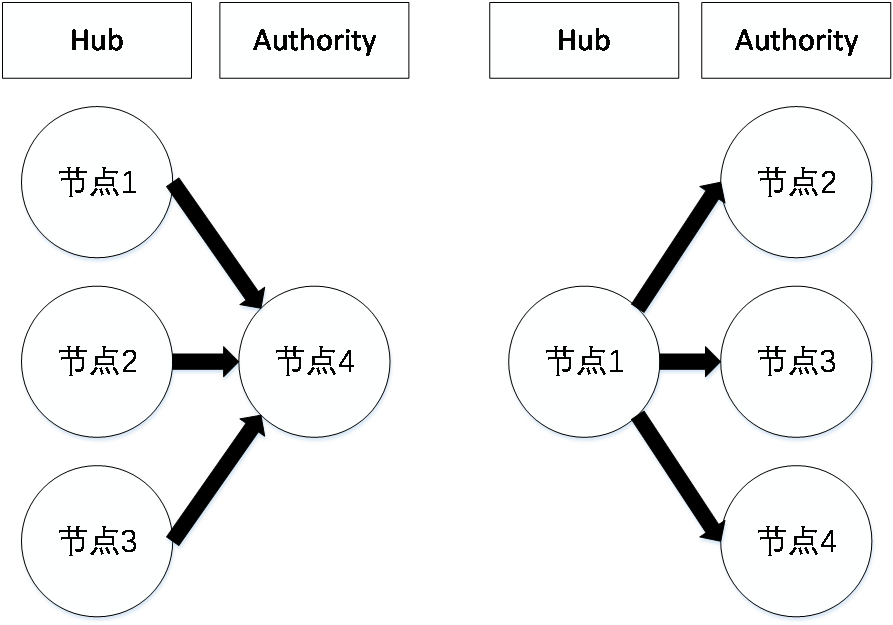
HITS(Hyperlink Induced Topic Search)是另一典型的基于链接结构评价的算法,由Kleinberg在90年代末提出。该算法的核心思想是页面的重要性与用户的查询条件有关,每个页面的重要性都由两个指标来衡量:页面的入度(即指向此网页的链接,也称Authority值)和页面的出度(即此网页指向别的网页的链接,也称Hub值)[5][6]。
1.3 本文主要内容与结构
本文主要设计和实现了一个主题爬虫系统,对设计过程中涉及的各个关键技术进行了的分析和讨论,主要的模块为爬行策略,URL的选取与维护,网页解析,信息提取,中文分词,主题相关度判断。本文的结构如下:
第一章主要阐述了主题网络爬虫的作用,课题的研究意义意义与国内外的研究现状。
第二章主要对比了可以实现爬虫的编程语言以及对所选语言进行介绍,阐述了通用爬虫与主题爬虫的体系结构,介绍了相关的搜索策略并加以分析。
第三章主要讲解了主题爬虫的各个组成模块,详细讲解了每个模块的工作原理。
第四章主要是对以书籍为主的主题爬虫的设计与实现,并对爬取结果进行分析。
第五章为对前面章节内容进行总结,反思发现设计的不足并提出改进的学习方向。
编程语言与爬虫框架概述
网络爬虫作为作为一种搜索引擎,其实现有多种方式,只需选取最适合的语言即可;在编写一段程序之前,需要先明确所需实现的功能,搭建其工作框架;本章即对编写爬虫的语言进行简单对比,并对爬虫框架做介绍。
2.1 各类编程语言对比
常用的编程语言例如C、python、Java都可以用来进行网络爬虫的编写。但是不同的语言有不同的特性,在不同的运用场合有各自的优缺,以下是对上述三种语言的简单对比。
(1)Java:Java是一种开发者用来创造计算机应用的程序语言,语言严谨、逻辑性强,主要用于商业逻辑很强的领域,例如可以用于商城系统的建立,且Java对商业数据库有较好的支持,也可以用于金融、保险等传统数据库的事务领域;Java语言有很好的软件工程理念,很适合多人共同进行工程开发,但对于初学者而言相对困难一些。
(2)C:C语言是一种高级语言,很多优点,例如运算符丰富、表达方式灵活,特点是C语言可以直接访问物理地址,进而访问硬件,所以C语音更多的被应用于底层开发;但是C也有一些缺点,比如C语言的语法限制不太严格,对变量的类型没有严格的约束等等,对程序的严谨性有一定的影响、也可能影响到程序的稳定性。从应用的角度来看,相对其他语言,C更复杂更难掌握一些,也对工程师的要求更高一些。
(3)Python:Python也是一种开源语言,虽然与Java一样都是面向对象,但同时还有一些面向过程的部分,并且其有很强的灵活性,可以调取多种库,并且可以跨平台调用C语言的库,灵活方便。再者,Python有很多解释器,如CPython,PyPy,Jython,IronPython等等,很适合用于业务语言、插件语言,更适合用来做脚本语言;Python的作者有意的设计限制性很强的语法,使得不好的编程习惯都不能通过编译,也更有助于编程者养成良好习惯。
通过对比,Python在实际运用中入门简单,有代码简洁优美,可读性强等优点,使得初学者更容易学习,更容易实现,且更有助于培养良好的编程习惯,所以在此次设计中,选择Python作为编程语言。
2.2 Python语言简介
Python是一种面向对象的解释型计算机程序设计语言,自1991年首次公开发行至今更新至3.7版本,常用版本有2.7与3.x,由荷兰工程师发明[7],其源代码和解释器CPython遵循GPL(GNU General Public License)协议。其语法简洁清晰,具有丰富且强大的库。并且Python还可以用于封装其他语言,可以把其他语言所描述的模块打包起来并组合使用,所以它常被称为“胶水语言”。有一种常见的应用情形:使用 Python搭建程序的框架,对特殊的部分,用更合适的语言改写,再封装为Python可以调用的扩展类库;不仅可以扩展库,在标准库方面,Python的标准库提供了包括系统管理、网络通信、文本处理等额外的功能[8]。Python标准库命名接口清晰、文档良好,很容易学习和使用,为了让Python使用方便,其在被设计时就尽量使用其他语言所使用的英文与符号,所以其有良好的可阅读性,并且相对于C等静态语言而言,Python不需要重复写声明,特殊情况的出现也更少。
值得一提的是,Python将缩进纳入了语法的一部分,以缩进表示语句块的开始,以回退表示语句块的退出,如果违反了缩进规则,则代码就不能够被编译,这有助于帮助工程师养成良好的习惯[9]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: