基于DTW算法实现对英文字母的语音识别开题报告
2020-04-12 14:07:48
1. 研究目的与意义(文献综述)
随着人类科学技术的不断发展,人和设备的之间的关系相比以前发生了很大的变化,这体现在人们希望利用某些信号控制机器设备。语音是一种非常常见的信号。语言的声学表现形式包含人类的语音,我们希望通过语音信号来控制机器即要使机器听懂人的语言,就需要做很多工作。这就是研究了几十年的语音识别和语音合成技术[1]。基于语音处理技术发展迅速,并且在各个方面应用广泛,本次毕业设计对语音处理中有重要作用的dtw算法进行研究。本次毕业设计题目为基于dtw算法实现对英文字母的语音识别,目的是利用dtw算法实现对引英文字母的识别,语言是人类最重要的交流工具,因为它自然方便、准确高效。
1.1研究目的
本次毕业设计的研究目的是详细研究dtw的基本原理,同时基于dtw算法实现对英文字母的识别,并对语音处理的各个部分进行研究,包括语音录入、预处理、训练、识别及结果输出等进行分析。
2. 研究的基本内容与方案
2.1研究目标
本次毕业设计的研究目标是实现基于DTW算法实现对英文字母的识别。语音识别并显示识别结果是语音识别中的一个重要方向。利用该技术可以实现对机器的控制,具有较强的实际意义。
2.2基本内容
研究语音识别中各个模块的处理方法,包括语音输入、预处理、特征提取、参考模式库、模式匹配、后处理灯各个模块的研究和分析[6]。拟采用MATLAB等软件以及C语言实现各部分的功能。
2.3拟采用的技术方案及措施
本次毕业设计采用对各个模块进行分析。
整体框图如图2.3.1所示:
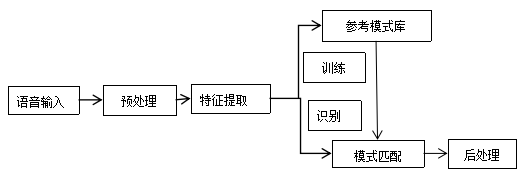
图2.3.1
首先是语音录入模块,这部分要完成语音的端点检测。在许多语音信号处理任务中需要判断一段输入信号中哪些是语音段,哪些是无声段。在孤立词语音识别系统中,需要正确判断每个输入语音的起点和终点,利用短时平均幅度参数M和短时平均过零率Z可以做到这一点。其基本原理是,首先,根据浊音情况下的短时平均幅度参数的概率密度函数P(M|V)确定一个阈值参数MH,MH值一般定的较高。当一帧输入信号的短时平均幅度参数超过MH时,可以判定为有声。根据MH可判定输入语音的前后两个点A1和A2。但是语音的精确起点、终点还要在A1之前和A2之后查找。为此可以再设定一个较低的阈值参数ML,由A1点向前找,当短时平均幅度由大到小减至ML时,可以确定点B1,类似地,可以由A2点向后找,确定B2点。然后在B1和B2之间利用短时过零率进行搜索,根据无声情况下的短时短时过零率,设置一个参数ZS,如果由B1向前搜索,例如短时平均过零率大于ZS的三倍时,则认为这些信号仍属于语音段,知道直到短时平均过零率下降到低于3倍的ZS,这时的C1就是精确的起点。同理也可以确定精确的终点C2[7]。
在计算过零率时拟采用公式2.3.1
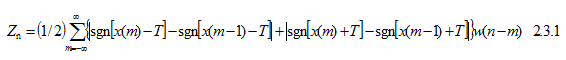
第二个部分是预处理,这部分包括滤波和量化。作用主要是有两个:一个是我们在使用低通滤波器的时候可以滤除掉频率高的部分,保证信号不会被混叠干扰;其次是使用高通滤波器来阻止电源干扰。从整体作用来看:预滤波可以等效成为一个带通滤波器对语音信号进行处理[8]。语音信号是连续信号,连续指的是在时间和幅度上都是不断变化的。由于计算机的独特性,它不能够识别出连续的语音信号,所以我们在把信号送入到计算机前就要对语音信号进行采样和量化[9]。把时间和幅度都是连续的转化成为都是离散的值。
第三个部分是特征提取,特征参数的提取对于语音识别系统尤为重要,特征参数的好坏对于语音别系统的精度和识别时间都有很大的影响,根据各种研究表明,倒谱特征参数中含的信息量比其他特征参数含的多,能较好的表现语音信号[10]。所以拟利用倒谱参数作为特征参数。因为Mel倒谱参数能充分反应人耳的特性,所以选用Mel倒谱参数[11]。具体计算方法如下:
1)根据式将实际频率尺度转换为Mel频率尺度[12]。
2)在Mel频率轴上配置L个三角形的滤波器组,L的个数由信号的截止频率决定。
3)根据语音信号幅度谱求每一个三角形滤波器的输出。
4)对所有滤波器输出做对数运算,再进行离散余弦变换即得到MFCC[13]。
第四个部分是语音识别部分,这是整个语音识别系统中最关键的部分。此部分拟采用DTW算法。DTW即动态规划技术(DP)[14],将一个复杂的全局最优化问题转化为许多局部最优化问题,一步一步地进行决策[7]。DTW的目标是求出最小总累计距离,所以关键是要找到输入矢量和参考矢量之间的关系,从而计算出这两个模板匹配时,累计距离最小值,从而可以得到归正函数。同时这个函数要满足一定的条件[15]。
边界条件:
连续条件:
最小累计距离可以由式2.3.4得到。
| |
DTW算法流程图可由图2.3.2表示:
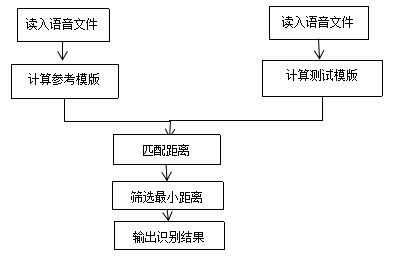
图2.3.2
第五部分,训练部分采用预先录入一定量的语音,然后通过算法对语音进行处理。将语音同文本对应起来,形成语音模板库,然后录入语音,系统能识别出语音文本内容,最后将结果输出[16]。
3. 研究计划与安排
第1-2周:查阅文献,确定毕业设计思路。
第3-4周:根据前一部分查阅的资料完成开题报告。
第5-6周:查阅外文文献,完成翻译的任务。
4. 参考文献(12篇以上)
[1] 廖振东.基于dtw的孤立词语音识别系统研究[d].云南大学,2015.
[2] 陈淑珍,张晨光.基于改进的语音参数提取的线性预测[j].武汉大学学报:理学版,2003,49(1):91-94.
[3] alexander seward. a fast hmm match algorithm for very large vocabulary speech recognition[j]. speech communication, 2003, 42(2). 193-206.



