基于Hadoop的大数据存储策略研究毕业论文
2020-02-17 23:03:40
摘 要
现阶段,我们处在了大数据时代,然而随着网络通信和信息技术的不断发展与普及,全球数据量呈现出爆炸式增长。面对前所未有的数据存储压力,分布式存储系统应用而生,有效地整合和利用分布在不同地理位置并通过网络相连的存储资源。利用廉价商用机器取代传统高昂硬件组已经成为了趋势必然。然而,其实对于分布式存储系统的研究在近些年从未停止,Hadoop自2004年发行以来,不断发展,其内部化结构不断完善,Hive子项目开发,淘宝云梯的建立,其对大量数据处理速度不断提升,多家大型企业包括雅虎,戴尔等推出Hadoop解决方案,其版本不断开发完善,使其在我们生活和实践中获得了更高的地位。目前,分布式存储在国内外发展的越来越好,因此Hadoop作为其一个主要的开源开发平台,对其存储策略进行研究有着重要的意义。
然而,虽然分布式存储这个概念其实已经深入人心,但是我们对于Hadoop的认知,对于大数据的存储方式了解还不够深入,因此,本论文旨在分析目前的存储现状,搭建合理的结构化Hadoop平台,基于Hadoop平台对大数据存储策略进行分析模拟。
本文首先分析了分布式存储方式的产生以及其国内外研究现状。紧接着介绍了存储系统的历史、发展,讨论了传统存储方式、市面上常见分布式存储例如GFS等、与基于Hadoop的分布式存储方式的共同性和差异性,随后搭建了Hadoop的运载环境,引入了Hadoop分布式存储系统的原理和技术、强调其一式三份的特色,随后分析了Hadoop分布式文件系统中的文件存取方式,异常修复的方式,并且探索了在分布式存储之后面临着数据分析、数据处理甚至涉及之后的云计算问题的情况,因此引入了MapReduce的编程模型,并利用基础的wordcount对其进行了测试,最终利用其实现了单词统计的功能,本研究对了解大数据存储方式有着较大的帮助,对了解并且使用Hadoop进行云存储乃至云计算的学习和理解具有重要的意义。
关键词:Hadoop;分布式存储; HDFS;云存储;大数据
Abstract
At this stage, we are in the era of big data. However, with the continuous development and popularization of network communication and information technology, the amount of global data has exploded. Faced with unprecedented data storage pressures, distributed storage systems are being used to effectively integrate and utilize storage resources that are geographically connected and connected across the network. Replacing traditional high-end hardware groups with cheap commercial machines has become a trend. However, in fact, the research on distributed storage systems has never stopped in recent years. Since it’s first established in 2004, Hadoop has been continuously developed, its internalization structure has been continuously improved, Hive subproject development, Taobao ladder construction, and its massive data processing. The speed continues to increase, and many large enterprises, including Yahoo and Dell, have launched Hadoop solutions, and their versions have been continuously developed to achieve a higher status in our lives and practices. Recently, distributed storage is getting better and better at home and abroad. Therefore, Hadoop considered as one of its main open source developing platforms, has important significance in researching its storage strategy.
However, although the concept of distributed storage is already deeply rooted in people's minds, our understanding of Hadoop and the understanding of how big data is stored is not deep enough. Therefore, this paper aims to analyze the current storage status and build a reasonable structured Hadoop. Platform, based on the Hadoop platform to analyze and simulate big data storage strategies.
This paper first analyzes the generation of distributed storage methods and their research status at home and abroad. Then, the history and development of the storage system are introduced. The common storage and storage methods, such as GFS and other distributed storage methods based on Hadoop are discussed. Then the Hadoop carrier environment is built. Introduced the principle and technology of Hadoop distributed storage system, emphasizing its features in three copies, then analyzed the file access methods in Hadoop distributed file system, the way of abnormal repair, and explored the face of distributed storage. Data analysis, data processing and even the subsequent cloud computing problems, so introduced the MapReduce programming model, and used the basic wordcount to test it, and finally use it to achieve the function of word statistics, this study is to understand big data The storage method is of great help, and it is of great significance to understand and use Hadoop for the learning and understanding of cloud storage and even cloud computing.
Key Words:Hadoop;Distributed Storage System;HDFS;Cloud Storage;Big Data
目 录
第1章 绪论 1
1.1 目的及意义 1
1.2 国内外研究现状分析 2
1.3 研究(设计)的基本内容、目标 2
第2章 存储策略研究 4
2.1 传统存储方式 4
2.2 分布式存储系统 5
2.2.1 分布式存储系统简介 5
2.2.2 Hadoop分布式存储系统 6
2.3 Hadoop版本选择 6
2.4 Hadoop完全分布式搭建 7
第3章 HDFS技术 9
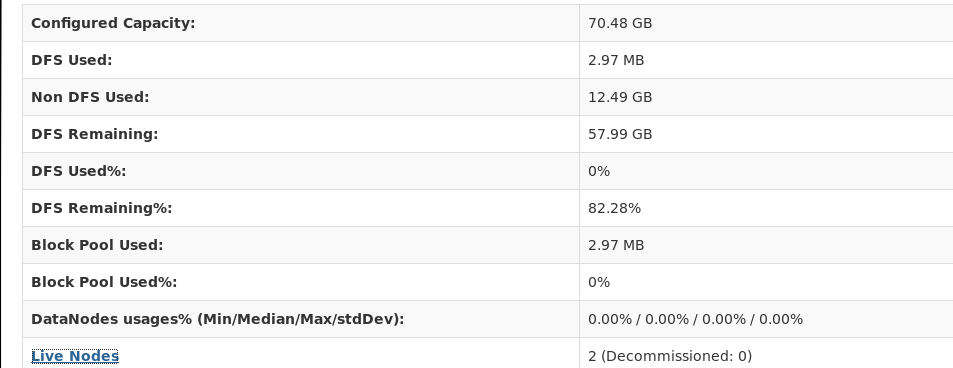
3.1 HDFS整体架构 9
3.2 HDFS基本概念 10
3.2.1 数据块 10
3.2.2 主节点 10
3.2.3 数据节点 10
3.3 HDFS特点 11
3.4 HDFS通信协议 11
3.4.1 RPC通信协议调用 11
3.4.2 Client Protocol 12
3.4.3 DataNode Protocol 12
3.5 HDFS文件操作 12
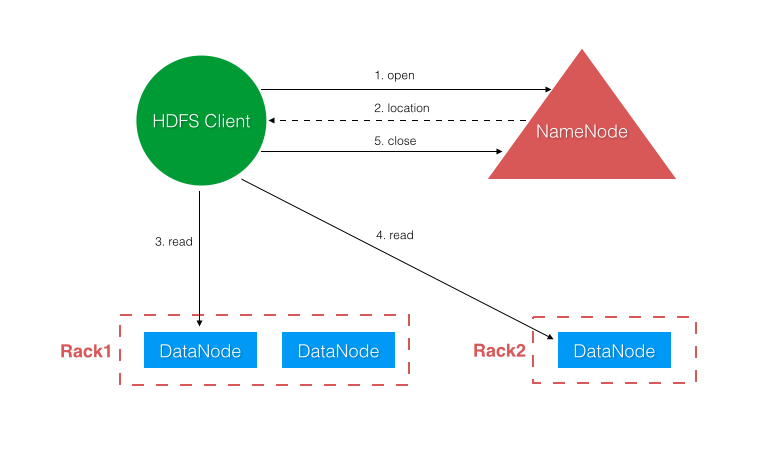
3.5.1 文件写入 12
3.5.2 文件读取 13
3.5.3 心跳检测 13
3.6 文件读取异常与恢复 14
3.6.1 读取文件异常 14
3.6.2 写入文件异常 14
3.7 HDFS的扩展 15
第4章 Mapreduce介绍 16
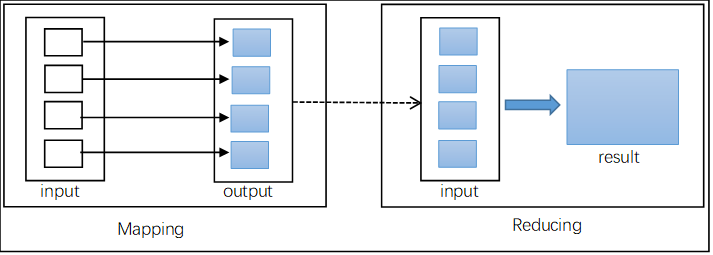
4.1 MapReduce编程模型 16
4.2 MapReduce流程分析 17
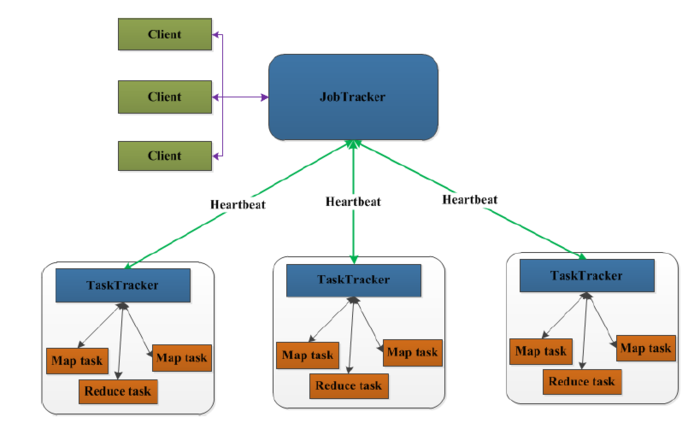
4.3 MapReduce的Task运行 17
第五章 Wordcount实例测试 19
5.1 运行流程图 19
5.2 本地文件创建 19
5.4 测试运行 20
5.5 结果展示 21
5.6 结果分析 21
第6章 总结 23
参考文献 24
致谢 26
第1章 绪论
1.1 目的及意义
现如今,网络与信息技术的深入发展与广泛应用,各行各业都在以匪夷所思的速度迅猛地产生各类数据。人们利用微信、QQ等进行聊天,利用微博、贴吧等进行交流互动,利用淘宝、京东进行网络采购,利用顺丰、三通进行物品传递,利用网络进行通信,随时随地产生着交流、评论、购物等多种数据,而移动终端与互联网的迅速普及更是加快了数据的产生[1]。在业界分析调研机构IDC发布的研究报告中指出:在今后的10年里,全世界的信息量将从2009年的0.8ZB增长到2020年的35ZB,这意味着10年将增长44倍,年均增长40%[2]。而由多种方位,无处不在的数据所呈出的爆炸性增长,标志着我们步入了大数据时代。
海量数据的产生已不再适合用传统的方法对数据进行存储,与此同时数据处理手段也是复杂多样,再加上数据结构不像传统数据那样统一,那么我们应该怎么合理地存储海量数据呢?为了解决传统存储模式容量有限难以满足大量数据存储需求的问题,我们考虑改进技术手段,更新存储系统,采用分布式构建,即把单一的存储空间转化为多个存储节点从而实现了大数据的分化。这样不仅可以应对数据量越来越大的难题,而且将之前数据只能通过单一线路进行提取存储转化可以通过多节点进行提取,不仅加快了数据处理速度,而且扩展了系统容量。
当然,此时也将会面临着数据结构不同的问题,我们也可以采用设置多个类型的存储引擎的方式,为不同的种数据结构提供合适的存储方案。
分布式存储系统,顾名思义,分布式意味着分散,即数据分散。分布式存储系统将意味着将大量的数据信息分散至不同地区的多台独立的存储设备中进行存储。传统的存储系统一直采用着集中的存储的思想,即由一台或者几台稳定的大型服务器集中存放所有数据,因此,大型存储服务器的存储能力成为了系统性能的瓶颈,而集中化的存放,使得人们对大型存储服务器的可靠性和安全性要求更高,随着量的增大,传统的存储系统慢慢地无法满足大规模存储的需要。而分布式存储系统的特点之一便是可扩展性,其对于单个存储设备的存储能力并没有特别高的要求,因此,分布在不同地理位置的多台存储服务器可以共同分担存储负荷,共同分担的方式也提升了其系统的稳定性和可靠性。与此同时,这也降低了其开销成本,廉价的设备也可以作为存储点。
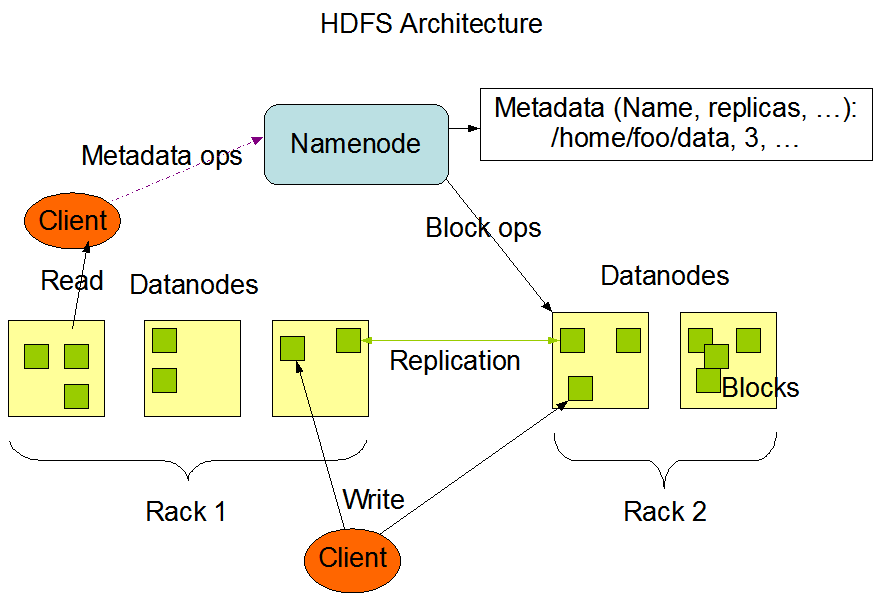
Hadoop采用Java语言开发,是对Google的MapReduce、GFS(Google File System)和Bigtable等核心技术的开源实现,由Apache软件基金会支持,是以Hadoop分布式文件系统(Hadoop Distributed Storage System,HDFS)和MapReduce(Google MapReduce)为核心,以及一些支持Hadoop的其他子项目的通用工具组成的分布式计算机系统。主要用于海量数据(大于1TB)高效的存储、管理和分析[3]。HDFS作为Hadoop生态系统中不可缺少的部分,文件分布式存储不仅满足了整个系统对于大量数据的存储需求,同时这些数据后续的提取和分析都需要依赖文件分布式存储技术。由此可见,Hadoop系统之所以如此高效、可靠,与HDFS技术密不可分。
HDFS相较于传统模式优势便在于能够在多个数据节点间快速实现数据的传输,而这一切都归功于MapReduce框架,这一编程框架能得以应用在于其支持大量数据集的并行运算,从而提高了数据传输效率。为了适应MapReduce框架模型,HDFS特意在数据传输之前将需要传输的数据分成单独的数据块,并把他们分配到不同的工作节点,从而满足了了分布式文件处理对高效的要求。
此外,HDFS具有高容错性。由于存储成本低廉,导致单点存储不稳定,HDFS通常会多次复制数据片段,并将数据副本分发给多个节点,其保证了至少存在一个副本被存放至其他服务器机架上。因此,哪怕在任何一处数据节点出现问题,也能在其他地方获得所需的数据,从而保证数据的完整性。HDFS使用主/从架构。在HDFS技术运用之初,每个Hadoop系统都是由两部分组成。一部分负责文件系统日常的运维,称为NameNode;另一部分负责各个数据节点上信息的使用和存储,称为DataNode。
由于存储方式的变革以及Hadoop在大数据中的广泛使用,本研究利用Hadoop的分布式文件系统HDFS来进行分布式存储系统的搭建与性能测试,从而掌握Hadoop的基本使用、更深入地了解目前大数据的存储策略以及对所设计的存储方案进行测试。
1.2 国内外研究现状分析
随着分布式存储技术的不断更新,数据分布式存储的方式也越来越多,为了满足多种类型的业务需求,许多国外公司都各自研发了适合本公司发展的分布式文件存储系统:
Sun Microsystem公司开发了网络文件系统NFS(Network File System)[4]由;IBM公司开发了并行文件系统GPFS(General Pallel File System)[5];IBM公司还与美国的卡内基梅隆大学(Carnegie-Mello University)联合研制了分布式文件系统AFS[6];HP、Intel和Cluster File System等公司与美国能源部一起研制了Lustre[7]。除了大型公司对其投入研究意外,国外的许多高校与开源社区也对此做了深入的研究,研发了能运行在Linux系统上的分布式文件系统;卡内基梅隆大学研制了Coda[10];Clifford Neuman在VSM基础上研发了Prospero[11];Sage Weil研发了可扩展性的分布式文件系统Ceph[12]Apache Hadoop[13]社区也结合自身需求研发了HDFS[14]。在国际发展的同时,国内的发展也不甘落后,许多也根据自身的应用需求,研发出了一些分布式文件系统,例如阿里巴巴也开发了支持大规模的非结构化数据的分布式文件系统TFS[15],中国科学院计算机研究所研发了蓝鲸集群文件系统BWFS[16]。
近几年,Hadoop技术在分布式系统领域也得到了深入地研究。许文龙利用HBase分布式数据库进行了交通数据的存储模型的设计,对海量车联网数据进行分布式存储与分析[17]。胡辉利用Hadoop技术对现有的大规模动车组运行状态数据进行分布式存储与分析,结合数据挖掘的原理设计了动车组故障数据关联规则挖掘系统[18]。郭凯振利用Hadoop框架实现了基于Hadoop的分布式计算系统[19]。武桂云根据所研究的深度学习,针对现有的数据挖掘任务,设计并实现了基于 Hadoop平台的分布式数据挖掘系统[20]。王铮也将Hadoop技术运用了到了现有的金融保险业之中[21]。
1.3 研究(设计)的基本内容、目标
本课题拟基于Hadoop分布式文件系统为大数据设计高效的存储方案,并对所设计方案的性能,例如安全性、可靠性、存储开销、读写开销等,进行多维度的软件仿真测试和理论分析。
第2章 存储策略研究
大型主机的诞生激起了所有与计算机领域有关的各行各业的发展浪潮,即自20世纪60年代开始,无论是计算机行业还是与计算机有关的商业,大型主机都凭借其高效在其中占有着一席之地。
科学家们开始投入大量的人力财力不断对大型主机进行开发,优化其计算的能力、让其运行更加稳定,让抗干扰能力更强。而之后System/360系列大型主机的研发,其表现出来的强大能力,无疑奠定了大型主机的主导地位。这也就意味着IT界开始步入由大型主机主导的新时代。
2.1 传统存储方式
凭借在单机处理上的高效性、稳定性和安全性,大型主机相较于其他计算机具有极大的优势。由于大型主机采用的是集中式的架构,这一系统架构也迅速成为IT系统的主流。随着计算机系统都采用了集中式系统,IT系统也进入了集中式处理阶段。
目前市面上主流的集中式存储的方式为NAS和SAN
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: