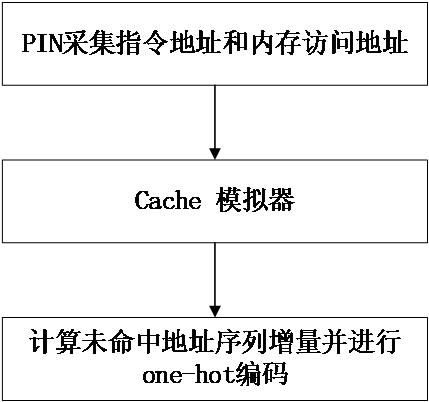基于神经网络的预取研究毕业论文
2020-02-17 23:05:00
摘 要
从20世纪80年代中期以来,计算机系统结构不断地更新和变革,制造技术的不断发展,使得计算机的性能增长达到了每年50%以上[1],但是,在2002年以后,计算机的性能的年增长率降到了20%,造成这个现象的主要原因之一就是存储器访问速度的提高变得缓慢,即内存墙问题,这是因为现代处理器的发展是飞速的,处理器的性能每年提升在50%以上,但是内存性能的提升却没有处理器那么高,只有10%左右,这样长期的发展,就造成了处理器和内存性能差距越来越大,对计算机性能的提升造成了极大的制约。
基于此我利用神经网络解决冯·诺依曼存储性能瓶颈问题,主要是通过构建有效的预取模型,通过预测机制,提升预测的准确度进而提升命中率来提升访问的速度,为了提升预测的准确度,我采用了两种方案[2],第一种是将预取策略与自然语言处理中的n-gram模型相结合构建了一个嵌入式LSTM,第二种是利用多任务学习机制,利用K-means对数据集进行预处理,再利用多任务学习机制进行预测。在这两种方案的基础上,我为了测试输入对模型的影响,构建了三种输入对模型进行预测,有指令地址,未命中地址增量,以及指令地址和未命中地址增量的结合共三种输入,找出了各自输入的特点。
经过测试,可以看到两种方案在预测性能上都有不错的表现,但是两种方案对于数据集的性能是不同的,这主要是由于数据集的特点所决定的,但是多任务学习LSTM模型相比嵌入式LSTM模型在召回率上有着更好的表现。对于输入性能的分析,可以看到未命中地址序列增量和指令地址的结合相比其中任何单独的一种都有着更好的预测性能,但是也可以通过预测结果分析得到其中未命中地址序列包含更多的信息,指令地址并非没有用,而是包含少量的信息。
关键词:预取;LSTM;多任务学习;准确率;召回率
Abstract
Since the mid-1980s, with the continuous updating and transformation of computer system structure and the continuous development of manufacturing technology, the performance of computers has increased by more than 50% per year[1]. However, after 2002, The annual growth rate of computer performance has dropped to 20%. One of the main reasons for this phenomenon is that the improvement of memory access speed has become slow, that is, the memory wall problem, because the development of modern processors is rapid. The performance of the processor is improved by more than 50% every year, but the improvement of memory performance is not as high as the processor, only about 10%. This long-term development has led to a growing gap between processor and memory performance. It greatly restricts the improvement of computer performance.
Based on this, I use neural network to solve the problem of von Neoman storage performance bottleneck, mainly by building an effective prefetching model, through the prediction mechanism, improve the accuracy of prediction and improve the hit rate to improve the speed of access. In order to improve the accuracy of prediction, I have adopted two schemes[2]. The first is to combine the prefetching strategy with the n-gram model in natural language processing to build an embedding LSTM. The second is to use the multi-task learning mechanism. K-means is used to preprocess the data set, and then the multi-task learning mechanism is used to predict the data set. On the basis of these two schemes, in order to test the impact of input on the model, I construct three inputs to predict the model, including instruction address, miss address increment, and the combination of instruction address and miss address increment. The characteristics of each input are found out.
After testing, we can see that the two schemes have good performance in predicting performance, but the performance of the two schemes is different for the data set, which is mainly due to the characteristics of the data set. However, the multi-task learning LSTM model has a better recall rate than the embedding LSTM model. For the analysis of input performance, we can see that the combination of missed address sequence increment and instruction address has better prediction performance than any of them. However, it is also possible to analyze the result of the prediction that the missed address sequence contains more information, and the instruction address is not useless, but contains a small amount of information.
Key Words:Prefetching; LSTM; multi-task learning; accuracy; recall
目 录
第1章 绪论 1
1.1 背景、研究目的及意义 1
1.2 国内外研究现状 1
1.3 本文主要内容 3
第2章 方案总体设计 4
2.1 嵌入式LSTM模型 4
2.2 多任务学习LSTM模型 5
2.3 方案对比与分析 6
第3章 方案中各模块理论介绍 7
3.1 数据预处理模块 7
3.2 Word2Vec模块理论 9
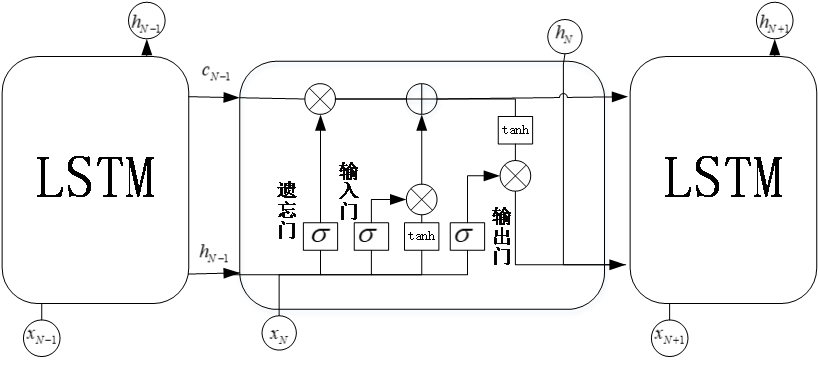
3.3 LSTM模块理论 11
3.3.1 LSTM前向计算 12
3.3.2 LSTM反向传播 13
3.4 K-means模块理论 15
3.5 多任务学习理论 16
第4章 试验结果 18
4.1 模型的分析 18
4.2 输入对模型的影响分析 20
第5章 总结与展望 23
5.1 总结 23
5.2 展望 23
参考文献 24
致谢 25
第1章 绪论
1.1 背景、研究目的及意义
现在处理器的计算速度比内存访问速度快好几个数量级,产生了内存墙问题[3],导致现在的计算机应用程序可能会花费超过50%的计算周期等待从内存到达的数据[4],为了解决这个问题,计算机存储系统采用分层存储系统,靠近中央处理器的速度快容量小,远离中央处理器的速度慢但容量大,使得处理速度接近处理器的速度,容量接近远离中央处理器的内存容量,但是真实环境中靠近处理器的缓存容量比较小,在复杂的环境中就存在着访问的数据不在靠近处理器的缓存中,此时就发生了未命中现象,则此时就会继续访问下一级缓存,这就产生了延时,为了解决这个问题,产生了预取机制,就是在程序的访问闲置等状态下将数据提前预取到缓存中去,预取会预测何时将哪些数据放入Cache中,这样就可以减少内存访问延时,可以看到一个有效的预取策略是提升计算机性能的关键。预取策略是一种猜测行为,现在的计算机会采用多种预测策略希望能够提升计算机的性能,现有的预取硬件大多是基于词汇表进行的,也就是预测提取的数据是与这个词汇表相关的,利用先验概率进行数据的提取,但是,现在是一个大数据时代,一个数据集是非常庞大的,可能会导致数据集大于词汇表。这将影响到预取的准确度。
最近的十几年神经网络得到了飞速的发展,神经网络特点是有大量的数据和大量的计算需求,而现在计算机由于硬件技术的发展导致计算能力的指数增长,这给神经网络的发展做了铺垫,神经网络比较擅长解决预测问题,在自然语言处理和与语义分析等中得到了广泛的应用,而计算机的程序会编译成汇编语言,有着指令地址和内存访问地址,计算机会按照顺序进行访问,此时就可以把程序执行看成一个序列问题,而其中的序列就是指令地址序列和内存访问地址序列,我将把内存访问的过程看成一个序列问题,利用神经网络作为预取策略,构建出一个有效的预取机制,能够实现计算机命中率的提升进而实现计算机性能的提升。
1.2 国内外研究现状
现在的计算机有着大量的应用程序,应用程序本身就是不同的,根据程序本身的特点可以设计一个合适的预取策略,可以看到预取技术是多种多样的,但是依旧是围绕着程序本身进行设计的,而程序的最大的特点就是局部性原理,包括空间局部性和时间局部性。
第一个就是利用程序的空间局部性,认为程序将要用到的数据块在当前使用的数据块的附近,原理较为简单直观,简单应用此原理的就有固定预取算法[5],假设当前程序使用的是第k块数据块,则此时会预取第k 1块到k n块的数据块,可以看到固定预取算法在数组的访问中会有一个良好的表现。但是其中n的选择是重要的,如果选择的n太小就会导致预取正确的概率很低,如果n太大会造成预取浪费,甚至可能会由于预取导致有效数据被替换而丢失,所以n的取值非常重要,即使如此也会产生很多其他问题,因为每次使用当前数据块都会进行预取n块数据块,这会造成I/O的频繁访问,可能会反而降低计算机的性能,而且在实际情况中,程序本身是很复杂的,这就会造成有很多无效的数据块被预取,反而造成了浪费,需要采用跳转长度预测机制来更好的进行预测,就是让n不固定,每次预取都会产生一个动态的n值进行预取。我们还可以结合先验概率,程序访问的记录是非常重要的,程序访问的记录会有助于我们下一次数据预取做出选择,因此我们还可以去记录每一次程序运行中的内存访问序列,对以上的数据进行统计,可以利用统计出来的直方图对未来的内存访问序列的大小进行预测。还有空间局部性侦测表,它可以对程序进行分析,可以改变程序代码的大小来提高程序的空间局部性[6]。但是这有一个弊端,需要大量的表进行维护,现在的程序中有的序列会被重复访问,所以可以记录访问次数和访问地址的关系,这样相比空间局部性侦察表会变小,可以实现一个良好的预测效果。
第二个就是时间局部性,认为我们访问了的数据会在不久的将来又要重复访问,循环流程就是体现时间局部性的最好例子,记录每个循环的序列,当判断到对应的循环体时把循环体内的序列进行直接预取,这就是利用时间局部性预取策略,实质就是去记录多条有规律的数据,当第一条数据再次使用时把剩下的数据进行预取。最简单应用时间局部性原理是MarKov模型的预测策略,MarKov模型的预测策略就是给出当前数据最有可能访问的下一条数据,这个可能性的大小就是根据时间局部性进行判断[7]。这就需要去用表进行记录,由于数据集非常庞大,导致表会很大,会造成很大的开销,所有有着一些优化策略,比如现在的Cache的命中率远远高于缺失率,那么可以只去记录未命中的序列就可以,这样可以大大的缩小表的维度,不仅如此,还可以利用相关性记录相关数据的偏移,这也可以大大减少了存储空间,而在接下来的模型的构建中就是用到了未命中的地址序列,而且是相对地址序列,就是用到了时间局部性的优化预测策略
预取技术除了利用程序的局部性原理,我们也可以利用并行处理机制,现在的CPU都是多核,其中有着非常丰富的并行资源,我们可以采用硬件技术生成预取线程,预取线程是由主线程进行精简生成的,主线程与预取线程同时运行,大多数情况下由于预取线程的精简性,预取线程的运行速度会比主线程的运行速度快,则可以将预取线程预取到的数据通过硬件进行分享,这样主线程就可以利用预取线程得到数据进行处理。由于硬件共享的速度不快,为此还可以采用核间线程迁移技术,运行一个主线程和几个预取线程,在每个核上运行预取线程,当将主线程进行迁移时,由于这个核上之前已经进行了预取运算,则此时迁移过来的主线程可以直接处理这个核上有用的数据。而核上的私有缓存的访问速度比共享缓存快,所以采用核线程迁移技术效率更高[8]。
1.3 本文主要内容
本文核心思想是设计预取模型,将神经网络与预取策略进行结合,希望能够建立一个较好的预取机制,能够提高预取准确率从而实现命中率的提升,最终希望能够提高计算机性能,在本文中设计了两种预取模型,一种是利用自然语言处理模型n-gram模型构建嵌入式LSTM模型,另一个是构建多任务学习LSTM模型,由于数据集非常庞大,对于数据集的处理我们实现了一系列的优化,包括通过Cache模拟器对数据集进行筛选,得到未命中的地址序列,降低数据量,不仅如此,还对得到的序列进行偏移计算,大大地缩小了数据的数量级。
本文的内容组织如下:
第1章绪论主要是从宏观角度分析了题目的背景、研究目的和意义,并且对主流的预取技术进行了分析。
第2章主要是介绍了本文的总体方案,介绍了两种方案并进行了阐述。
第3章第一部分介绍了预处理模块的优化流程,介绍了PIN工具对数据集的采集,以及Cache模拟器的原理。之后几部分介绍了方案中的预测模块,最后介绍了多任务学习理论知识。
第4章第一部分主要是介绍了数据集的类型和数据量的大小,以及对应的数据评价指标,第二部分主要是分析了嵌入式LSTM模型和多任务学习LSTM模型对指标性能的影响,第三部分主要是分析输入对指标性能的影响。
第5章主要是总结所做的工作以及阐述未来需要解决的一些问题。
第2章 方案总体设计
神经网络在预测方面有面有着较为广泛的应用,但是现在大多都是单任务学习模式,为了对预测模型进行性能的发掘,采用了两种方案,第一种方案是采用单任务的嵌入式LSTM模型,第二种方案是采用多任务学习的多任务学习LSTM模型[2]。
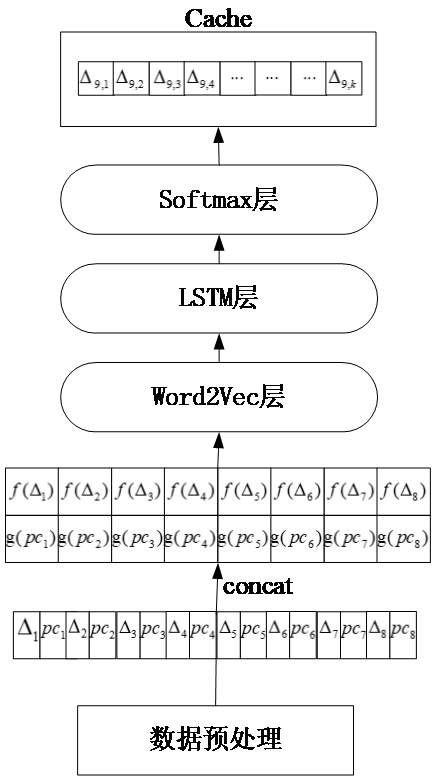 2.1 嵌入式LSTM模型
2.1 嵌入式LSTM模型
图2.1 嵌入式LSTM结构图
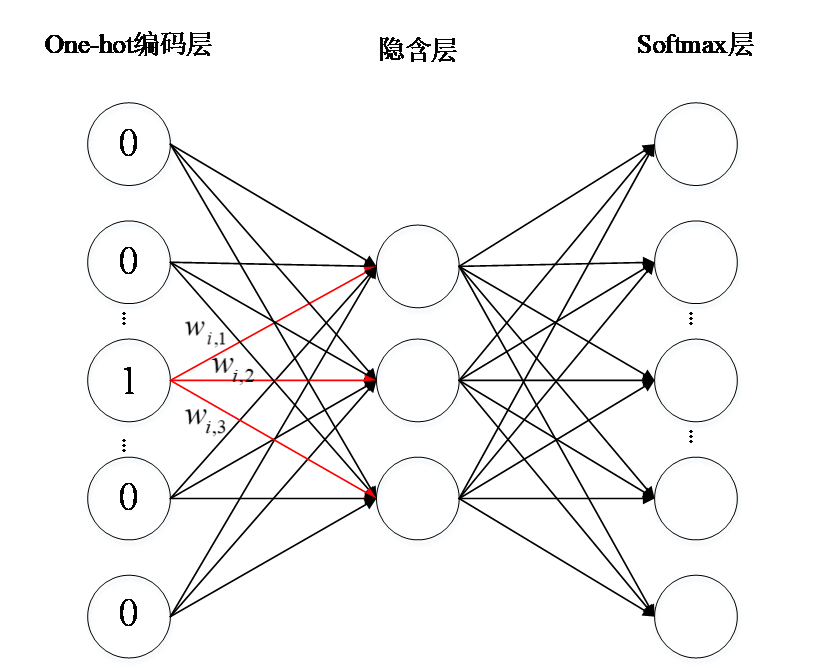
如图2.1所示为嵌入式LSTM的结构图,可以看到其中的输入为未命中地址序列增量 和指令地址pc,这些输入是由数据预处理模块采集得到的,首先对这两个输入分别建立词汇表,利用输入在词汇表的位置用one-hot进行编码 ,各自形成向量表达式,之后将未命中地址增量序列的one-hot编码结果和指令地址序列的one-hot编码结果组合成一个更长的向量。这个向量的维度是很大的,而且数据之间的关联性并不能反映出来,所以采用Word2Vec对组合成的向量进行降维并进行关联性的加入,Word2Vec的输出即是最终我们要的输入,之后才用核心模型LSTM进行学习,在这里我们采用两层LSTM,第二层的LSTM的输出必须经过softmax层,这是因为我们做的是分类,softmax层返回的是词汇表中的每一个状态对应的概率,所以在LSTM层训练完之后我们会采用softmax层进行维度匹配与概率的计算,维度的大小和输入词汇表中的是一致的,概率计算公式为式(3.1),实现就是通过一个全连接层来达到升维使得和词汇表的大小相等,我们最终会得到词汇表中的每一个的概率,在实际的预取中,我们可以预取多个结果,如果只预取最大概率对应的则会由于词汇表太大导致预测率偏低,采用预取前K个最大概率对应的有可能会造成资源的浪费,甚至由于预取的太多,而缓存的容量是一定的可能会导致缓存中删除掉了其他有用的信息,为次我采用预取前10个概率最大对应的增量。
和指令地址pc,这些输入是由数据预处理模块采集得到的,首先对这两个输入分别建立词汇表,利用输入在词汇表的位置用one-hot进行编码 ,各自形成向量表达式,之后将未命中地址增量序列的one-hot编码结果和指令地址序列的one-hot编码结果组合成一个更长的向量。这个向量的维度是很大的,而且数据之间的关联性并不能反映出来,所以采用Word2Vec对组合成的向量进行降维并进行关联性的加入,Word2Vec的输出即是最终我们要的输入,之后才用核心模型LSTM进行学习,在这里我们采用两层LSTM,第二层的LSTM的输出必须经过softmax层,这是因为我们做的是分类,softmax层返回的是词汇表中的每一个状态对应的概率,所以在LSTM层训练完之后我们会采用softmax层进行维度匹配与概率的计算,维度的大小和输入词汇表中的是一致的,概率计算公式为式(3.1),实现就是通过一个全连接层来达到升维使得和词汇表的大小相等,我们最终会得到词汇表中的每一个的概率,在实际的预取中,我们可以预取多个结果,如果只预取最大概率对应的则会由于词汇表太大导致预测率偏低,采用预取前K个最大概率对应的有可能会造成资源的浪费,甚至由于预取的太多,而缓存的容量是一定的可能会导致缓存中删除掉了其他有用的信息,为次我采用预取前10个概率最大对应的增量。
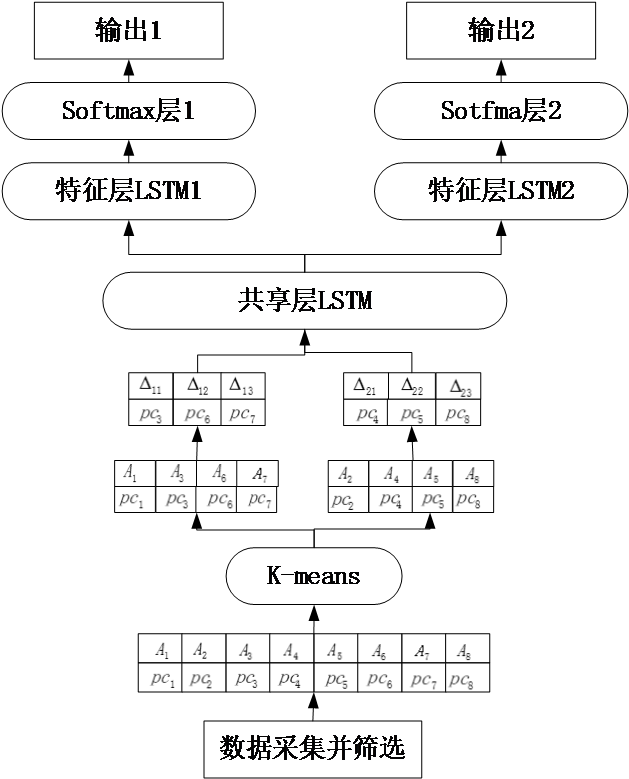 2.2 多任务学习LSTM模型
2.2 多任务学习LSTM模型
图2.2 多任务学习LSTM结构图
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: