多标签瓷器图库设计与实现毕业论文
2020-02-17 23:24:48
摘 要
本次设计是利用网络爬虫软件,基于网络上主流的瓷器博物馆网站,建立不同类别瓷器的多标签数据库,包括瓷器的类别,纹饰,年代,造型。为了收集大量、可靠的瓷器图片以及信息,为后续机器学习瓷器信息提供强有力的数据支撑,将数据来源聚焦在互联网上的各大博物馆官网上,最后经过筛选,决定以故宫博物院的瓷器库作为目标网站。在深度分析了故宫博物院网站结构的基础上,基于Python语言设计了一款爬虫软件并建立了基于MySQL的数据库。
论文的结构是从设计的需求分析,方案选择,相关技术和开发工具的介绍到基于Python3.0的爬虫设计以及对多标签瓷器数据库建立的说明。详细介绍了目标网页分析,目标信息提取和处理,信息存储以及数据库建立的实现方法。
在实际测试中,设计的爬虫可以稳定运行,并可以高效无误地从目标网站上爬取下瓷器的有效信息,建立的数据库也可以完整地存储爬取的瓷器信息。
关键词:瓷器;爬虫;Python;故宫博物院;数据库
Abstract
This design uses web crawler software to build a multi-label database of different types of porcelain based on the mainstream porcelain museum website on the network, including the categories, patterns, ages and shapes of porcelain. In order to collect a large number of reliable porcelain pictures and information, provide powerful data support for subsequent machine learning porcelain information, focus the data source on the official website of the major museums on the Internet, and finally, after screening, decide to use the porcelain library of the Palace Museum as the library. Target website. Based on an in-depth analysis of the structure of the Palace Museum website, a crawler software was designed based on the Python language and a database based on MySQL was built.
The structure of this thesis is from the requirements analysis of the design, the choice of the program, the description of the relevant technology and development tools to the Python 3.0 based crawler design and the description of the multi-label porcelain database. The detailed analysis of target web page analysis, target information extraction and processing, information storage and database establishment is introduced.
In the actual test, the designed crawler can run stably, and can effectively climb the effective information of the porcelain from the target website, and the established database can also completely store the crawled porcelain information.
Key Words: porcelain; web crawler; Python; Beijing Palace Museum; database
目 录
第1章 绪论 1
1.1 毕业设计背景 1
1.2 国内外研究现状 1
1.3 论文结构和内容 2
第2章 需求分析及方案设计 3
2.1 需求分析 3
2.2 方案设计 3
2.2.1 目标网站的确定 3
2.2.2 确定爬取数据 4
2.2.3 数据本地化的方案 4
2.2.4 整体结构设计 4
2.3 相关技术 5
2.3.1 Python语言 5
2.3.2 URL与URI的比较 7
2.3.3 HTML定义及特点 8
2.3.4 MySQL语言 8
2.4 开发工具 9
2.4.1 Chrome 9
2.4.2 Spyder 9
2.4.3 MySQL-Front 10
2.5 本章小结 10
第3章 设计实现分析 11
3.1 目标网页分析 11
3.2 目标信息的爬取 12
3.2.1 设置Headers 12
3.2.2 发送HTTP的get请求 12
3.2.3 获取主页面信息 13
3.2.4 获取详细页面信息 15
3.3 目标数据的处理 15
3.3.1 图片类数据的处理 15
3.3.2 信息类数据处理 16
3.4 目标数据的本地化 16
3.4.1 图片类数据的保存 16
3.4.2 信息类数据的存储 16
3.5 异常处理及拓展部分 18
3.5.1 编码问题 18
3.5.2 SSL证书的解决办法 18
3.5.3 简单GUI页面的设计 19
3.5.4 程序流程 20
3.6 本章小结 21
第4章 系统调试及功能实现 22
4.1 网络连接测试 22
4.2 抓取过程 23
4.3 本地文件测试 24
4.3.1 图片的本地保存 24
4.3.2 信息的excel存储 25
4.3.3 信息的数据库存储 25
4.4 本章小结 26
第5章 结论 27
5.1 收获与成长 27
5.2 不足与展望 27
参考文献 28
附录 29
致谢 31
- 绪论
- 毕业设计背景
前几年,由谷歌公司创造的“最强大脑”AlphaGo以大比分打败了世界围棋冠军李在石的,此次大胜瞬间引起了全世界的轰动,也让人工智能迎来了一个史无前例的高峰期。人工智能的基础是机器学习,机器学习是通过建立代码,学习已知数据的潜在规律,目前主要用在资讯的语音识别、个性化推荐、图像识别、日程规划、智能驾驶、智能客服等地方。利用机器学习的特性,可以对大量不同形状、不同颜色、不同花纹的瓷器图片识别,做出智能化生成指定类别的瓷器样本出来以供工业设计使用。本次设计就是通过互联网获取大量的瓷器图片信息,建立一个丰富的瓷器图库供后续机器学习使用。
通过传统搜索引擎Google、Baidu搜索,获取的互联网上的瓷器信息的确很多,但是很多都是无效、重复的信息。因为这些搜索引擎是针对关键词进行搜索的,所以很难做到针对性网站的关键词搜索,并且搜索引擎为了节约搜索速度,基本使用比较的底层的高级语言,庞大复杂,并不是一个好的参考对象。
面对这种困境,使用针对性设计爬虫来获取指定网站的信息是一个很好的选择。与传统搜索引擎不同的是,网络爬虫程序可以自动获取相关的网页信息,还可以分析这些网页信息,对有效信息进行针对性的抓取,并按照设计保存到本地。Python丰富的模块和良好的兼容性使得能相对简单易完成小型项目,所以本次爬虫软件的设计选择基于Python语言。
- 国内外研究现状
伴随着网络的飞速发展,网络成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的难题。通用的搜索引擎,比如谷歌、百度、雅虎、搜狐等,可以作为人们连接互联网的通道。可是,局限性依然存在于这些通用搜索引擎之中:(1)搜索引擎相对有限,但网络资源无限增长,这种矛盾日益加大;(2)搜索的页面包括大量用户不关心的网页;(3)这些通用型的搜索引擎基本都是基于关键字的检索,并不支持语义查询;(4)同样的搜索引擎虽然可以抓取大量数据,但对于某些密集和结构化的数据的利用却不怎么擅长。种种这些原因,导致了定向抓取网页资源的爬虫的产生。
首个被运用于探测Internet发展规模的爬虫程序是World Wide Web Wanderer,它是由麻省理工学院(MIT)的学生马休 格雷开发的。设计之初的这个程序只用来统计Internet上服务器的数量,慢慢演化发展成为一款可以检索网站域名的软件。伴随着互联网的飞速发展,搜索目前最新的网页变得十分困难,爬虫程序需要做到的是及时且全面地检索所有最新的网页。因此,在这个来自麻省理工学院(MIT)的学生所设计的爬虫程序基础上,其他的一些编程者将对这种爬虫工作原理作了些调整。在1993年底,以Repository-Based Software Engineeing(RBSE)spider、JumpStation和The World Wide Worm为代表的新搜索引擎逐渐出现。
目前搜索引擎的雏体,就是现在业内大家熟知的Lycos,是Micheal Mauldin在1994年的7月把爬虫程序接入到其索引程序当中所创建的。同年4月,超级目录索引Yahoo出现了,它是由两位来自斯坦福大学的博士生David Filo和美籍华人杨致远共同设计的,直至今天,雅虎搜索也依然很受欢迎,因为Yahoo的出现,搜索引擎的概念才成功地深入人心。从此以后,搜索引擎进入了一段飞速发展时期。目前,互联网上已经有了很多有名的搜索引擎,这些搜索引擎检索的信息量跟以前已经不是一个量级的了。近年以谷歌为榜首,百度、雅虎等紧追其后的搜索引擎的出现,使得人们检索信息的方式得到了质和量提高[1]。
通用爬虫和聚焦爬虫是目前互联网爬虫的常见分类方式。通用网络爬虫也叫做全网爬虫,它主要给搜索引擎提供数据,爬行的目标是从一些种子URL到整个网络,这种爬虫爬取的范围和数量都相对较大,爬行数据较久,存在着一些缺陷,主要应用于搜索引擎中。聚焦网络爬虫只搜索与主题相关的网页,速度较快,比较节省空间,有很高的利用价值。本次设计就是通过搜索引擎搜索相关瓷器网站,然后进行选择,设计了聚焦爬虫,只抓取被确定网页的有效信息。
- 论文结构和内容
本文介绍了基于Python语言实现爬虫以及建立数据库的过程,具体内容如下:
- 正文之前包括论文题目、声明部分、中英文摘要和目录;
- 第一章绪论对本次设计的背景以及国内外研究现状和论文结构进行了阐述;
- 第二章说明了需求的分析和方案的确定以及相关技术的介绍;
- 第三章设计分析与实现主要说明了本次设计的实现过程;
- 第四章主要展示了本次设计调试过程和成果;
- 第五章总结了本次设计的收获与不足;
- 最后是参考文献,附录代码以及致谢部分。
第2章 需求分析及方案设计
2.1 需求分析
本次设计是利用网络爬虫软件,基于网络上主流的瓷器博物馆网站,建立不同类别瓷器的多标签数据库,包括瓷器的类别,纹饰,年代,造型。所以目的是设计一款爬虫软件,然后确定需要爬取的目标瓷器网站,获取相关的瓷器图片和信息,对不同的瓷器作标签化处理并建立相关数据库。
2.2 方案设计
2.2.1 目标网站的确定
 为了获取大量、全面、准确的瓷器信息,在国内几个大型博物馆进行了瓷器搜索,如中国国家博物馆,故宫博物院,南京博物馆等,只有故宫博物院的瓷器库种类和数量最多,所以最终选择了故宫博物院官网作为目标网站。
为了获取大量、全面、准确的瓷器信息,在国内几个大型博物馆进行了瓷器搜索,如中国国家博物馆,故宫博物院,南京博物馆等,只有故宫博物院的瓷器库种类和数量最多,所以最终选择了故宫博物院官网作为目标网站。
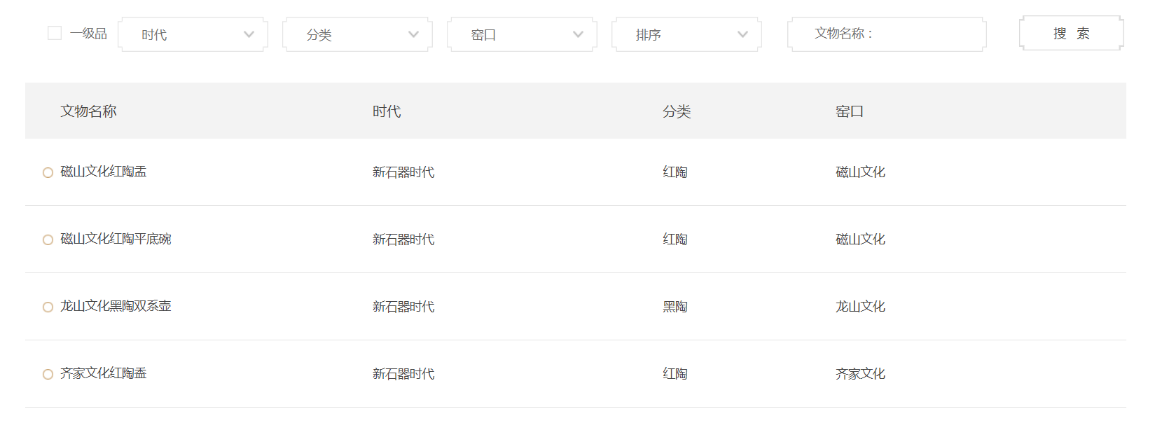
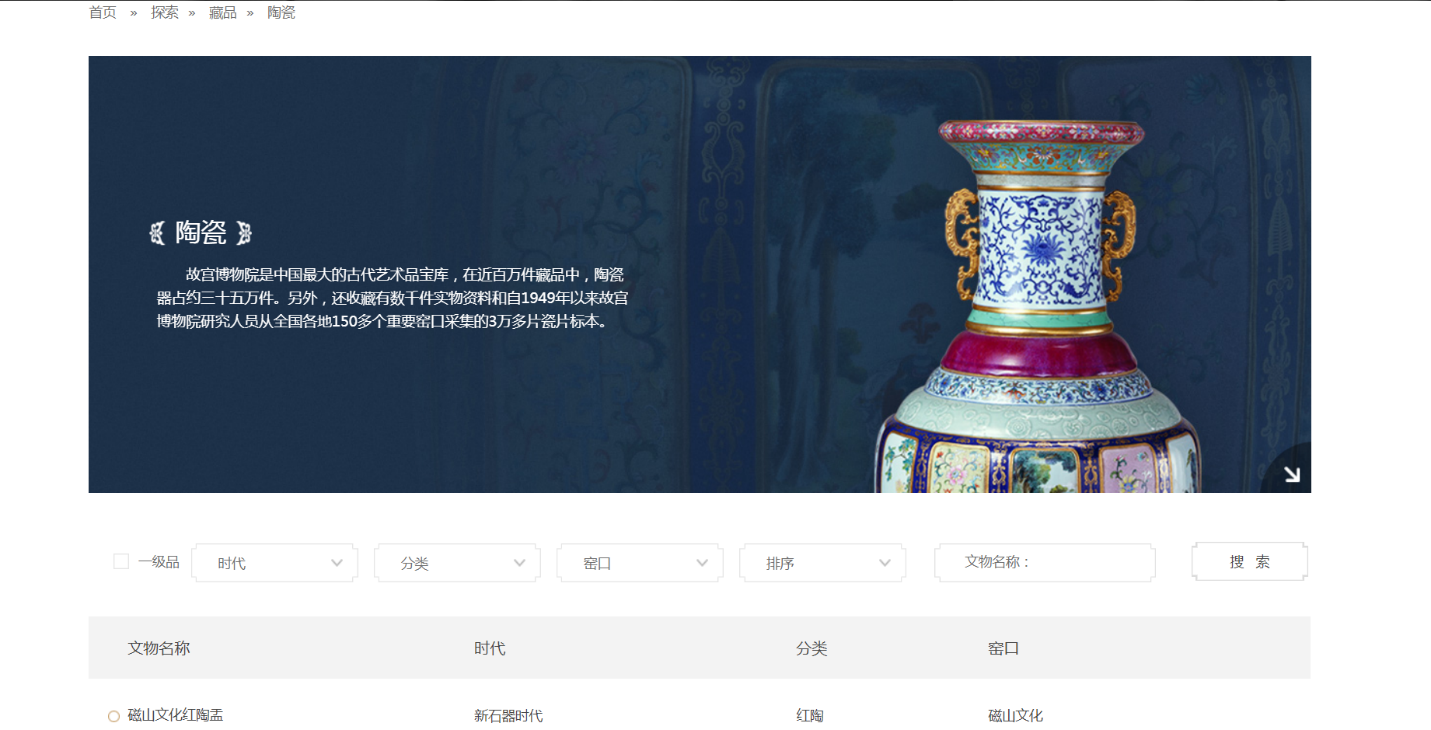
图2.1 故宫博物院馆藏瓷器图录首页
如图2.1所示,故宫博物院是中国最大的古代艺术品宝库,在近百万件藏品中,陶瓷器占约三十五万件。另外,还收藏有数千件实物资料和自1949年以来故宫博物院研究人员从全国各地150多个重要窑口采集的3万多片瓷片标本。故宫博物院的瓷器馆藏量非常丰富,可以作为本次建库的信息来源[12][16][17]。
2.2.2 确定爬取数据
在确定了目标网站之后,下一步就是其URL对应的网页内容进行爬取。在此之前,需要了解中国瓷器的一些分类方式,如表2.1所示:
表2.1 中国瓷器常见的分类方式
分类方式 | 种类1 | 种类2 | 种类3 | 种类4 | 种类5 | … |
年代 | 唐 | 宋 | 元 | 明 | 清 | 等 |
产地 | 景德镇 | 唐山 | 德化 | 龙泉 | 潮州 | 等 |
材质 | 白瓷 | 高白瓷 | 高白玉瓷 | 玉瓷 | 骨瓷 | 等 |
制造工艺 | 釉下彩 | 釉上彩 | 金彩 | 粉彩 | 唐三彩 | 等 |
特征 | 原始瓷器 | 青花瓷 | 玲珑瓷 | 素瓷 | 黑瓷 | 等 |
窑口 | 官窑 | 民窑 | 龙泉窑 | 耀州窑 | 德化窑 | 等 |
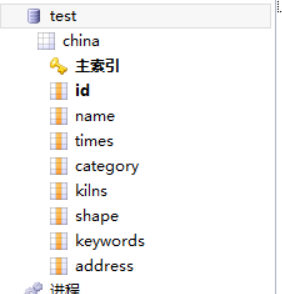
对网页内容爬取之后,首先需要遍历整个网页的HTML代码,确定需要抓取的内容,找出其中的有效信息,包括文物名称、时代、分类、窑口以及瓷器图片。根据网站的瓷器对瓷器按不同分类方式进行分类,建立不同类别的瓷器库。
2.2.3 数据本地化的方案
完成了对有效信息的抓取之后,要把这些信息进行处理,然后就要把这些信息保存到本地,包括信息和图片。图片直接保存到本地,信息类数据可以通过程序传到excel中或者数据库里。这些爬取的数据是什么编码格式,什么类型的,如何将这些图片保存到本地,两种不同的方式如何进行保存,这些都将在下一章进行详细讲解。
2.2.4 整体结构设计
图2.2 设计结构图
如图2.2的结构图所示,本次毕业设计先是确定爬取的目标网址,然后获取相关数据,最后再保存到本地和数据库中。下面将对项目涉及的技术和工作做些说明。
2.3 相关技术
2.3.1 Python语言
本次设计的程序,基本是建立于Python3.0的基础上的。下面通过Python的发展、原理、特点三个方面来介绍Python语言:
发展:
 1989年的圣诞节,荷兰数学家、计算机学家Guido von Rossum为了打发无聊的假期,着手设计了一门新的脚本解释型编程语言。他希望这门语言能够像Shell语言一样方便,同时又能像C语言一样可以调用众多系统接口。Guido将这种介于C与Shell之间的语言命名为Python,据说起这个名字是因为他喜欢的有部电视剧的名字叫这个。1991年,第一个公开发行版的Python问世。Python的后续版本不断发行,其中最重大的升级出现在2000年10月发行的Python2.0和2008年12月发行的Python3.0版本中。在Python2.0中增加了许多新特性,包括垃圾回收机制和Unicode的支持;在Python3.0中去掉了2.x系列版本中冗余的关键字,使Python更加规范、简洁,并进一步完善了对Unicode的支持。与其它语言升级不同的是,升级后的python3.x系列版本并不支持向下兼容。此前的Python2.x系列的最新版本为2010年7月发行的2.7版本,官方将在2020年停止对该版本的支持[5]。自1991年至今,Python经过了大大小小多次变革,发展成为简洁、人气颇高的编程语言,在编程人员中很受欢迎,这与Python社区的支持和贡献是分不开的。社区人员贡献的大量模块能够支持Python方便地完成包括机器学习、图像处理、科学计算等在内的多种多样的人物,这也吸引了越来越多的编程人员成为Python社区的一员。
1989年的圣诞节,荷兰数学家、计算机学家Guido von Rossum为了打发无聊的假期,着手设计了一门新的脚本解释型编程语言。他希望这门语言能够像Shell语言一样方便,同时又能像C语言一样可以调用众多系统接口。Guido将这种介于C与Shell之间的语言命名为Python,据说起这个名字是因为他喜欢的有部电视剧的名字叫这个。1991年,第一个公开发行版的Python问世。Python的后续版本不断发行,其中最重大的升级出现在2000年10月发行的Python2.0和2008年12月发行的Python3.0版本中。在Python2.0中增加了许多新特性,包括垃圾回收机制和Unicode的支持;在Python3.0中去掉了2.x系列版本中冗余的关键字,使Python更加规范、简洁,并进一步完善了对Unicode的支持。与其它语言升级不同的是,升级后的python3.x系列版本并不支持向下兼容。此前的Python2.x系列的最新版本为2010年7月发行的2.7版本,官方将在2020年停止对该版本的支持[5]。自1991年至今,Python经过了大大小小多次变革,发展成为简洁、人气颇高的编程语言,在编程人员中很受欢迎,这与Python社区的支持和贡献是分不开的。社区人员贡献的大量模块能够支持Python方便地完成包括机器学习、图像处理、科学计算等在内的多种多样的人物,这也吸引了越来越多的编程人员成为Python社区的一员。
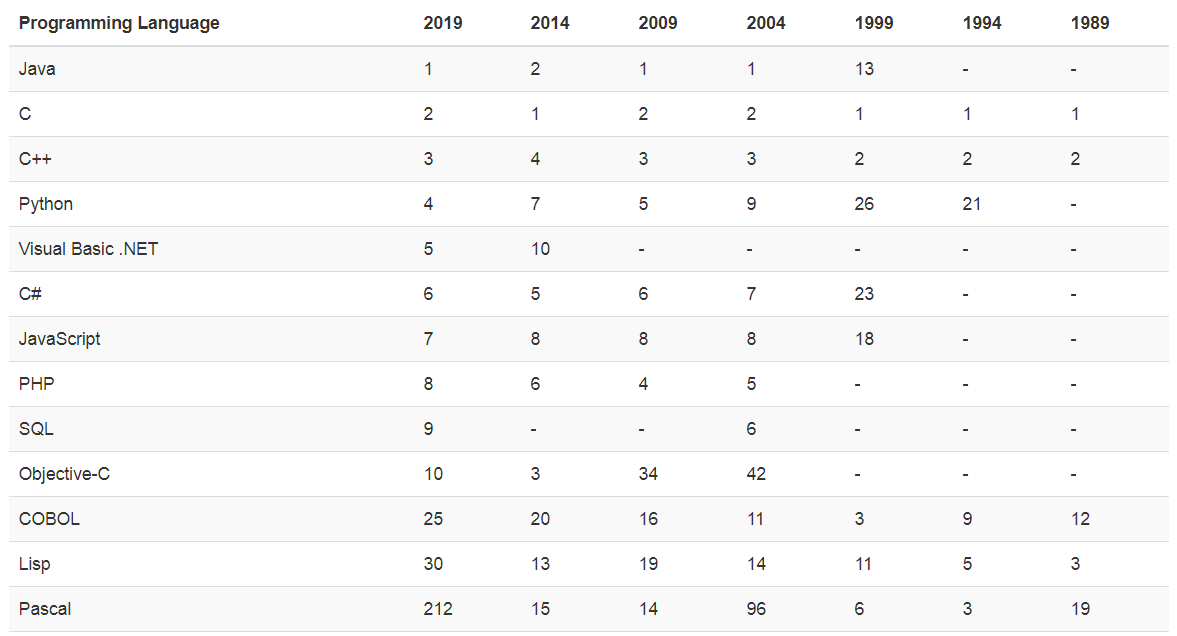
图2.3 各种热门编程语言近年排名
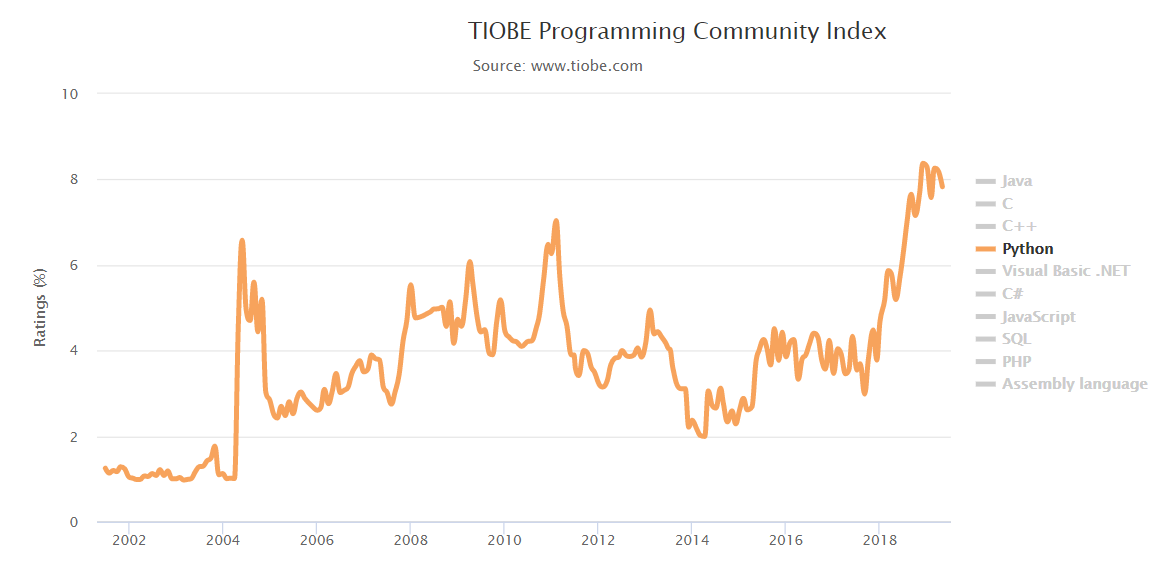 图2.4 Python语言使用率走势
图2.4 Python语言使用率走势
如图2.3,2.4所示(数据来源TIOBE指数),自2004年以后,Python的使用频率正在飞速增长,尤其近几年,人工智能、机器学习和大数据的兴起,更使得Python的使用率大大提高。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: