语音信号降噪方法研究及其MATLAB实现毕业论文
2020-04-10 16:55:24
摘 要
论文主要研究了语音降噪方法和LMS降噪算法及其变种NLMS算法MATLAB的实现,也就是语音增强中语音降噪的实现。在语音降噪技术中,自适应滤波器是一个重要方法,它可以于不基于任何语音模型,损失的语音特征又比较小,达到良好的消噪效果,因而被广泛应用。在自适应信号处理中,自适应滤波算法应是最常被研究的方向的一种。而在自适应算法中,最常用到的LMS算法,本文针对其及其变种NLMS算法,并在实验中验证变种算法是否具有更快的收敛速度以及增强效果。
为了验证语音降噪算法的性能,本文借助仿真软件MATLAB对自适应算法中的LMS算法和NLMS算法进行性能仿真,比较不用步长对算法的影响。然后对多个语音增强算法对一段标准且加噪后的语音进行降噪,根据所得语音波形图以及分段信噪比和PESQ得分进行对比分析。
仿真结果表明:NLMS算法、LMS算法、NLMS和子空间降噪组合算法具有较好增强效果。可懂度也有较大提高,达到了增强有用语音的目的。实际听音表明NLMS算法得到的语音很清晰,LMS算法得到语音则有些失真。
本文的特色:比较完整和个地介绍了语音增强技术的发展现状,由浅入深地介绍语音增强技术的实现,具体到LMS和NLMS算法简略推导和实现步骤,通过仿真实验验证算法增强效果。
关键词:MATLAB;语音降噪;语音增强;LMS;NLMS;
Abstract
The dissertation mainly studies the speech denoising method, LMS denoising algorithm and its variant NLMS algorithm MATLAB, which is the realization of speech denoising in speech enhancement. In the speech noise reduction technology, the adaptive filter is an important method, it can be based on not any speech model, the loss of speech features is relatively small, to achieve a good denoising effect, and thus is widely used. In adaptive signal processing, an adaptive filter algorithm should be one of the most commonly studied directions. In the adaptive algorithm, the most commonly used LMS algorithm, this article for its and its variant NLMS algorithm, and verify in the experiment whether the variant algorithm has a faster convergence speed and enhance the effect.
In order to verify the performance of the speech denoising algorithm, the simulation software MATLAB is used to simulate the performance of the LMS algorithm and the NLMS algorithm in the adaptive algorithm, and the influence of the step size on the algorithm is not compared. Then, a plurality of speech enhancement algorithms are used to denoise a standard and noise-added speech, and a comparison analysis is performed based on the obtained speech waveform and the segmented signal-to-noise ratio and the PESQ score.
The simulation results show that the NLMS algorithm, LMS algorithm, NLMS and subspace denoising combined algorithm have better enhancement effect. The intelligibility has also been greatly improved, achieving the purpose of enhancing useful speech. The actual listening shows that the speech obtained by the NLMS algorithm is very clear, and the speech obtained by the LMS algorithm is somewhat distorted.
The characteristics of this article: The development status of speech enhancement technology is introduced in a complete and comprehensive way. The implementation of speech enhancement technology is introduced from the beginning to the end. Specific deductions and implementation steps of LMS and NLMS algorithms are specifically introduced. The simulation results are used to verify the enhancement effect of the algorithm.
Key Words:MATLAB;speech enhancemen algorithmt;speech denoise;LMS;NLMS
目录
第1章 绪论 1
1.1 课题背景和意义 1
1.2 语音降噪国内外的研究现状分析 1
1.3 研究的基本内容、目标 3
1.4 本文研究内容及论文结构 4
第2章 语音增强技术的基础理论 5
2.1 引言 5
2.2 语音信号和噪声的特性 5
2.2.1 语音信号的产生及特性 5
2.2.2 噪声的特性及其影响 6
2.3 语音降噪算法评估标准 7
2.4 本章小结 8
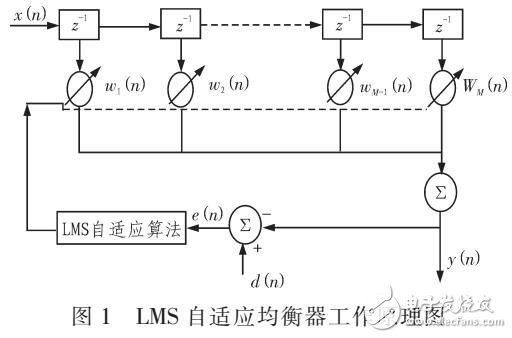
第3章 自适应滤波器原理及LMS算法 9
3.1 滤波器结构 9
3.2 自适应滤波器 9
3.3 最速下降算法 10
3.4 LMS(最小均方)算法分析 11
3.5 本章小结 12
第4章 NLMS变步长算法与子空间降噪算法组合 13
4.1 归一化LMS算法 13
4.2 子空间降噪算法 14
4.3 组合算法 14
4.4 本章小结 15
第5章 降噪算法的仿真与实现 16
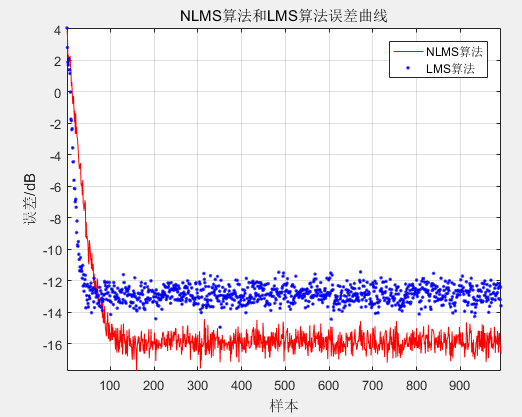
5.1 LMS和NLMS性能仿真 16
5.2 多种语音增强算法效果对比 17
5.3 本章小结 19
第6章 总结和展望 20
参考文献 22
致 谢 23
第1章 绪论
语音是人们相互交流信息中最自然、最快捷的手段,人们为此创造世界各地的方言,其重要性可想而知。语音信号在声电转换时不可避免地要受到周围环境的影响,比如说麦克风。人们在用麦克风说话时,如果高背景噪声将会严重影响语音信号质量。
因此,语音通信系统中的一项重要任务是提取纯粹的原始语音并尽可能地从有噪声的语音信号中抑制背景噪声。提高识别率,这就是语音增强的工作。语音增强是一种当语音通信系统的输入或输出信号受到噪声干扰时提高系统性能的技术[1]。种种语音降噪算法也是因为这个原因而得到了普遍的研究和应用。
1.1 课题背景和意义
语音与说话人的地理和文化水平密切相关,因此它可以传送各种有用的信息。与文字和图片相比,有时通过语音获取信息可能更加直接和有效。
在日常生活中,人们的长途通信基本上是电话的使用达成的,例如安装在街道,机场和手机上的公共电话。然而,当我们享受这个长途电话时,我们将不可避免地受到各种背景噪音的影响。例如,当您在拥挤的街道上听手机时,您会听到噪音,而对方也会因为你的噪声导致收听不清晰。因此通过估计接收端的噪声干扰模型可以滤除噪声,从而实现语音增强,保证通话质量。
随着DSP技术和语音增强算法的不断发展,它是汽车互动,LiteHD呼叫,人机对话语音识别,诸如人工耳蜗,智能家居,战场通信和军事窃听等语音增强技术正被越来越广泛地使用[2]。
由于言语的特殊作用,人们不仅需要相互沟通,还要让各种机械“理解”人们在说什么。即使人们与各种机器,机器和机器的语音通信也是人们梦寐以求的很长一段时间。在这种情况下,这些机器理解人们的言语并与人进行智能沟通是一个非常有意义和具有挑战性的研究课题。因此,语音识别研究的目的是不言而喻的。
1.2 语音降噪国内外的研究现状分析
实际的语音通常是一个嘈杂的信号。尽管完全消除噪声并不现实,但语音增强的目标是减少听众的疲劳,改善语音质量并改善语音识别。对于语音处理系统(识别器,收音机,手机)来说就是提高系统的识别率和抗干扰能力。但是,这两个目标通常是不可用的,所以通常根据生活应用中的具体情况来确定。
语音增强主要包括三个方面:语音降噪(主要方面),语音分离和语音混响(可以包括回声消除)问题。根据接收信号的信道数量不同,分为单信道和多信道(特别强调两麦的情况,因为它对应于人耳)。在混合信号和干净信号建立的接收信号模型基础上形成了基本算法。考虑空间,时间和光谱特性方面的信息和信号处理的三个维度。这里讨论的一般都是语音降噪问题。
历史上,最原始的降噪算法是通过平滑信号和消除信号中的奇点来降低噪声。然而,实质上,这样的降噪算法仅仅对在噪声信号中混合的噪声进行平滑处理,没有对信号本质进行降噪处理。傅立叶变换(FFT)是在19世纪20年代提出了非周期信号分解的概念后,被界内称为信号分析中最广泛的分析方法。传统的降噪算法是基于傅里叶变换的,因为噪声能量多半集中在高频部分(突变),而有用信号的频谱主要在局部范围内。使用低通滤波器来保留频域中的低频信号,从而让高频噪声信号消失。傅里叶变换完全是频域分析方法,与时域完全不沾边,即根本不能对应相应时间段的频率信息。使用这样的算法对于周期性平稳信号的降噪效果(即有用信号频带和噪声信号的噪声频带被分离)相对较好。对于非周期性信号(即有用信号频带和有噪信号的噪声频带是混叠的),它相对而言效果很差。在实际工程应用中,绝大部分信号通常是非周期性的,并且信号的频域特性随时间动态变化。这个时候,基于傅立叶变换的传统降噪方法使得难以实现良好的降噪效果[3-4]。
在参考了一定文献以后,大致把语音降噪算法分为以下几类。
表1.1 语音降噪算法的分类
方法 | 内容及特点 |
噪声消除法 | 噪音消除方法从时域或频域中的带噪语音中直接减去噪音分量。该方法最重要的特点是需要使用背景信号作为参考信号,其性能取决于参考信号的精度。自适应滤波技术广泛运用在采集背景噪声的场景中,在采集背景噪声中使用自自适应滤波可以使参考信号尽可能接近噪声语音中的噪声成分[5]。 |
谐波增强法 | 谐波增强是一种基于周期性的方法,在频域中的它的周期性反射可以分别与对应于基频(基频)及其谐波的一系列峰值分量挂钩,大部分语音的能量集中于这些频率上,语音增强正是根据这种周期性来进行的,另外如果采用梳状滤波器来提取目标语音的基音及其谐波分量,其他周期性噪声和非周期的宽带噪声都能被有效抑制[6]。 |
基于语音生成模型的增强算法 | 基于语音生成模型的增强算法将语音话语过程等同于线性时变滤波器。动机的不同来源用于不同类型的言语。全极点模型经常用于语音生成模型。在建立语音生成模型之后可以获得各种语音增强算法,并且时变参数维纳滤波和卡尔曼滤波方法是其代表。但是此类降噪算法的运算普遍偏大,系统性能往往需要优化才能正常使用[7]。 |
基于短时谱估计的增强算法 | 基于短期频谱估计的增强算法基于语音短期频谱估计的降噪算法是各种各样的,并且通常需要对语音进行预处理。谱减法,维纳滤波,最小均方误差(表示LMS算法)是其中的代表。适应大信噪比,操作简单,易于实时处理等优点[8]。 |
基于小波分解的增强算法 | 先是小波分解这一新的数学分析工具有了良好的发展进而带动了语音处理方面的小波分解法,这种算法往往需要与谱象减法相结合[9]。 |
基于听觉屏蔽的增强算法 | 针对人耳听觉特性建模而成的语音增强算法。即使周围有强噪声干扰,人耳可以分辨出需要聆听的声音[10],听觉屏蔽法正是利用了这一听觉特性。 |
在上面所述的六类算法中,基于短期谱估计增强算法的谱减法及其改进形式具有计算复杂度低,实时性容易,增强效果好的优点。最常为人们所使用。本文主要是讨论这一类的增强算法。基于短时频谱估计的算法主要基于短时频谱幅度的估计(语音分帧处理),这是由于人耳对语音相位不敏感造成的。因此,估计的对象被放置在短期频谱幅度上。
最小均方(LMS)算法已成功应用于许多过滤应用程序,包括信号建模,均衡控制,细胞化、生物医学或波束、成型的噪声消除方案。麦克风需要这种应用来捕捉噪音的性质和语音的同步确认附加噪音之间的相关性等等。
1.3 研究的基本内容、目标
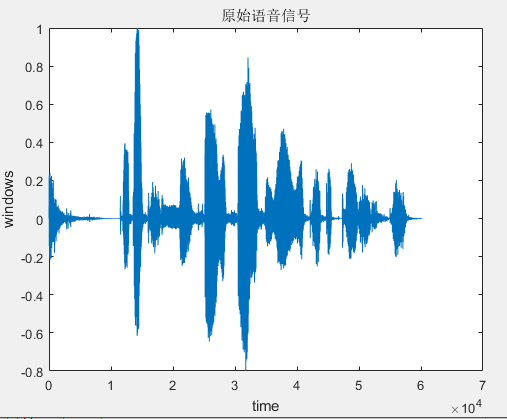
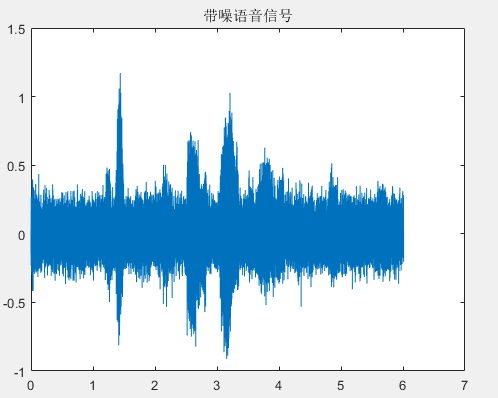
选择TIMIT语音库中的标准男声作为原始纯语音并向语音添加高斯白噪声,然后使用多种算法,主要是LMS和NLMS,以减少噪声增加的语音的噪声。比较各个算法不足。为了让各个算法对语音的降噪效果有一个客观的评判标准,可计算降噪后语音的分段信噪比和语音质量感知评估得分作为评判的依据。验证了组合算法的降噪效果与传统算法相比是否能有效消除背景噪声干扰。在更快的收敛和更小的稳态误差情况下,验证它是否能够取得显著的滤波效果。
在实际应用过程中,LMS算法存在很多缺陷:第一,它的收敛速度很慢,当它需要快速收敛时,它不再适用;输入信号的特性在很大程度上决定了它的滤波性能,即输入语音信号的自相关矩阵的特征值的分布。当然,滤波性能会因为背景噪声很强而出现急剧下降。在此,有一个思路是:为了提高优化后的LMS算法效果,首先通过其他算法(例如子空间滤波)改善输入信号特性,然后使用优化的LMS滤波器。
一种组合算法:带噪信号首先由由子空间进行。过滤掉一部分噪声,再将过滤后的信号作为NLMS算法输入进一步滤波获得比单个算法更好的效果。
根据上述分析完成组合算法后,使用MATLAB评估组合算法的降噪效果。为检测LMS、NLMS算法性能,以5种算法分别进行仿真对比。
1.4 本文研究内容及论文结构
本文主要包括三方面内容:一是对语音降噪的现状进行了分析,系统论述最基本的语音降噪知识;二是LMS算法及其改进NLMS算法的理论研究;三是语音增强改进算法在MATLAB上的实现以及对比。本文的结构和主要内容安排如下:
第1章,绪论。描述了本研究主要内容的背景和意义,以及当前声音去噪算法的发展以及该技术在各个领域尤其是生活中的应用。
第2章,介绍语音增强技术的基础理论为下面做铺垫。对语音信号及噪声的产生和特性、带噪语音简单模型、语音质量评价方法进行简述。
第3章,在论述了自适应滤波器技术原理和最速下降算法的基本原理后,以此为基础对LMS推导,最后对LMS算法进行了详细分析。
第4章,在LMS算法基础上对NLMS变步长算法做了性能分析,对比不同参数对NLMS算法的影响。将NLMS算法与子空间降噪算法组合。
第5章,算法的仿真与实现。主要阐述了MATLAB中各种语音去噪算法的实现过程,并介绍了去噪结果的分段信噪比和语音质量感知评估。
第6章,总结和展望。
第2章 语音增强技术的基础理论
2.1 引言
语音增强通常是指语音降噪。这改善了语音信号输出信噪比达到了提取有用的语音的目的。消除信号中不需要的噪音的一般方法是:安排一个抑制噪音并保持信号相对恒定的过滤器,使污染的信号通过。然后对输入进行滤波以滤除原始噪声,从而提高信噪比。通过分析语音信号的基本参数,我们可以处理多个语音信号,增强和传输语音信号。因此,语音信号分析在数字语音信号处理和增强中起着非常重要的作用。
2.2 语音信号和噪声的特性
2.2.1 语音信号的产生及特性
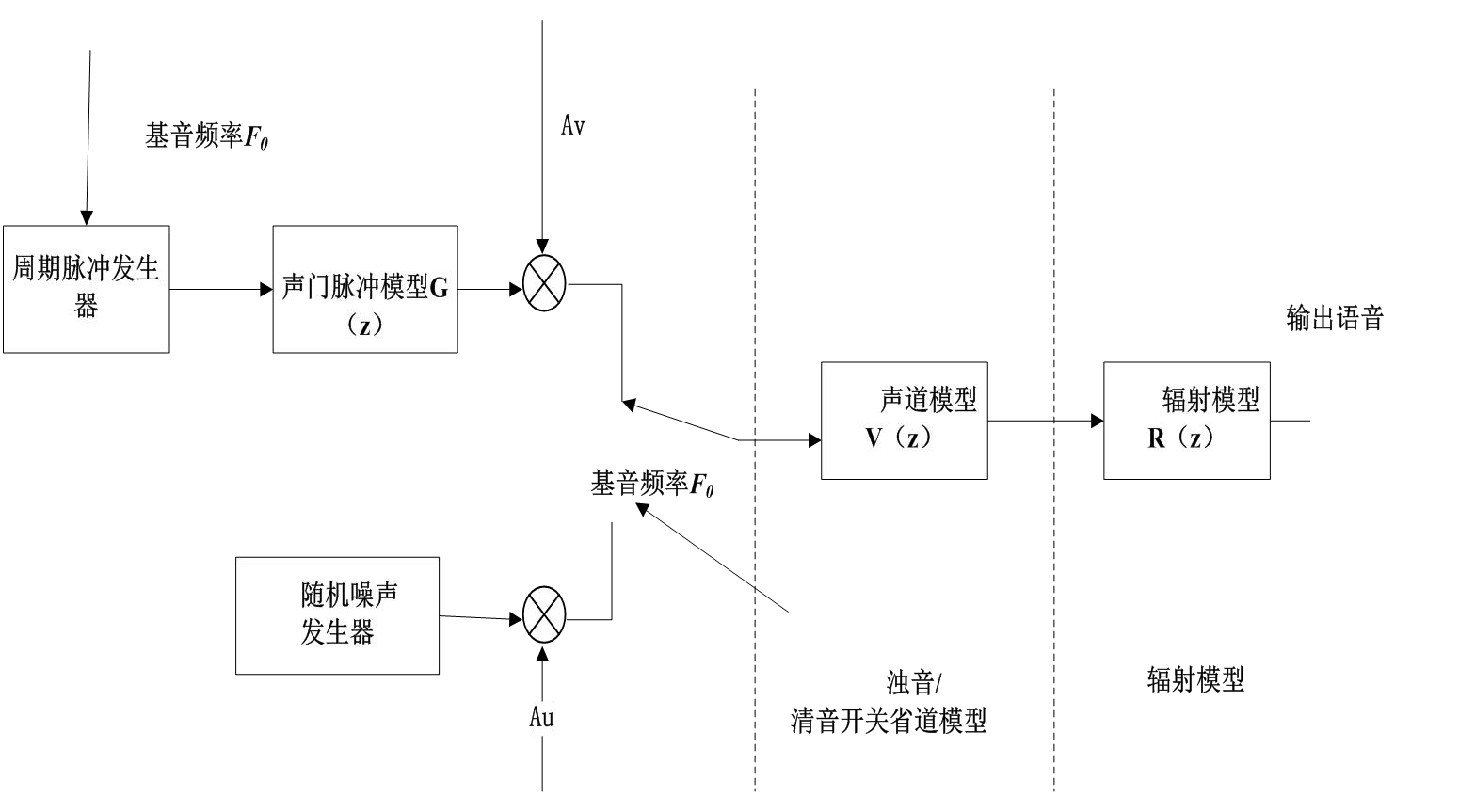 从声学角度来看,不同的声音是由声音激发源和发声器官中的声道的差异引起的。根据信道源和信道模型,语音可以大致分为浊音和清音。为了进一步建立时域离散语音信号生成模型,该模型如图2.1所示。
从声学角度来看,不同的声音是由声音激发源和发声器官中的声道的差异引起的。根据信道源和信道模型,语音可以大致分为浊音和清音。为了进一步建立时域离散语音信号生成模型,该模型如图2.1所示。
图2.1 离散的语音信号产生模型
语音是一个随时间变化的非平稳随机信号。在较短时间内(例如在30ms内),人类发声系统的生理结构相对而言变化更快。假设在这段时间内短期语音频谱相对稳定,可以使用短期频谱的平滑性来处理语音信号。使用短期频谱的这种平滑性来进行语音分析,提取语音特征用于语音增强。
由上述可知,语音的短时谱幅度的统计特性是时变的,是非平稳且非遍历的, 短时谱的数学统计特性也是随时间的推移不断变化的,因此,只能使用逐帧处理。高斯分布模型基于中心极限定理,我们经常把高斯分布模型对有限帧长度的应用,尽管这仅仅是近似描述,不过也是语音增强的前提。
2.2.2 噪声的特性及其影响
语音系统的应用环境是信号的噪声主要来源,应用环境是千变万化的,所以噪声的特性也是多种多样的。不过噪声大体上可以分为加性噪声和卷积噪声。噪声与信号在时域上相加是指加性噪声,噪声与信号在时域上相互卷积是指卷积噪声。一般情况下,经过同态变换,卷积噪声能够变换为前者,而加性噪声模型较卷积噪声容易建立,因此本文主要研究加性噪声的特性以及其对语音降噪的影
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: