主题网络爬虫的研究与实现开题报告
2020-04-12 14:14:53
1. 研究目的与意义(文献综述)
1.1 研究目的及意义
随着当前"互联网 "概念的兴起,各个行业都在积极的拥抱"互联网思维",从而促进了互联网的迅速发展,web信息量也呈爆炸式增长,网络对每个人的影响越来越大。然而正因为当今网络信息的种类繁多、覆盖面广,还充斥着大量内容相近或低质量的网页信息,导致人们很难在复杂的web信息中快速准确地找到想要的资源,搜索引擎正是在这样的需求下而产生的,并在网络信息搜索中起到了至关重要的作用,它可根据用户的输入内容在浩翰的信息海洋中寻找人们想要获得的相关信息。现在主流的捜索引擎有google、百度、搜狗等,虽然他们能返回大量的网页信息,但是在结果中通常也会包含大量的“不准确”内容,为用户増加了额外的负担。除此之外,通用搜索引擎还存在着覆盖率低、更新不及时等缺点,针对以上问题,用户急需一种智能的专业化搜索引擎,能够帮助用户在web这个巨大的信息空间中快速准确的查找特定信息。
垂直搜索引擎是针对某一特定主题的专业搜索引擎,它能在特定的捜索范围内取得比传统搜索引擎更好的查询效果,是传统搜索引擎的细化和延伸,所以更适合在某一特定领域或某一特定人群中使用,可以较好的为使用者提供个性化、专业化的查询服务,是针对传统搜索引擎查询准确度低、信息兀余且覆盖率低等缺点提出的全新搜索模式。垂直搜索引擎能够根据用户需求返回专业化的定向信息,其返回内容均针对某一特定领域,对与领域主题不相关的内容有较强的屏蔽功能,能够去除大量的无效信息,并且有搜索周期短、更新及时等优点。相对通用搜索引擎返回信息的海量无序化,垂直搜索引擎专业、全面、深入的性能特点使其成为当下的研究热点之一。
2. 研究的基本内容与方案
爬虫的实现方法很多,java、c、python等语句都可以完成网络爬虫的实现,经过对比与考虑,此次设计使用python语句进行编写,python有良好的可扩展性和可嵌入性,并且便于移植,有极佳的可读性,也更适合初学者学习。将逐步解决三个问题,1.爬哪里,确定要抓取的页面。2.爬什么,分析上述页面,确定从页面中爬取的数据。3.怎么爬,可使用 python 强大丰富的标准库及第三方库来完成。这是爬虫的核心部分。
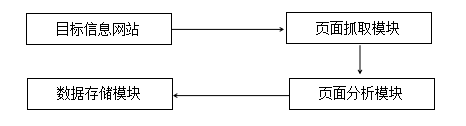
该爬虫系统主要由三个模块:页面抓取模块、页面分析模块、数据存储模块,三个模块之间相互协作,共同完成网页数据的抓取。爬虫实现流程图如图一所示。
3. 研究计划与安排
(1) 第1-3周:查阅相关文献资料,明确研究内容,学习毕业设计研究内容所需理论的基础。确定毕业设计方案,完成开题报告。
(2) 第4-5周:掌握主题网络爬虫的实现原理,完成英文资料的翻译,熟悉开发环境。
(3) 第6-9周:完成整个系统的设计。
4. 参考文献(12篇以上)
[1]于娟,刘强.主题网络爬虫研究综述[j]. 计算机工程与科学,2015,37(02):231-237.
[2] filippo menczer, gautam pant, padminisrinivasan. topical web crawlers[j] . acm transactions on internet technology(toit), 2004, vol.4 (4), pp.378-419



