基于SSD的目标检测方法设计与实现毕业论文
2020-02-17 23:17:58
摘 要
在深度学习理论兴起后,计算机科学领域发生了革命性的变化,传统的算法不断被淘汰,图像识别再一次成为了热门研究领域,各种算法的出现不断将机器视觉识别的能力向前推进,完全脱离了过去人工识别的成本,技术限制。算法的检测精确速度螺旋上升,使一直处于想象的机器实时图像识别走出实验室。单发多框检测器(Single Shot multibox Detector,SSD)是目前速度实时图像识别效率最高,准确性最好对模型之一,对于该模型的研究目前依然活跃于学术界。
本文概述了深度学习算法的产生和卷积神经网络的部分发展历程。研究了SSD目标识别框架的实现方式。在Linux系统的环境中搭建Caffe-SSD框架的要求及方法。并尝试通过对SSD识别框的修改以提高对小目标的识别能力和精确度。通过PASCAL VOC2007和VOC2012训练模型,得到训练精确度和识别的效率,并运用网络图片进行目标识别实验。
关键词:深度学习;图像识别;卷积神经网络;SSD
ABSTACT
After the rise of in-depth learning, revolutionary changes have taken place in the field of computer vision, and image recognition has once again become a hot research field. The emergence of various algorithms constantly pushes forward the ability of machine vision recognition, completely breaking away from the cost and technical limitations of past manual recognition. Recent models, such as SSD, have made real-time recognition in real-time scenarios possible from theory to reality by optimizing the algorithm. Single Shot multibox Detector (SSD) is one of the most efficient and accurate models for real-time image recognition. The research on SSD is still active in academia.
This paper outlines the generation of deep learning algorithms and the development of convolutional neural networks. The implementation of SSD target recognition framework is studied. Requirements and methods of building Caffe-SSD framework in the environment of Linux system. And try to improve the recognition ability and accuracy of small targets by modifying the SSD recognition box. Through PASCAL VOC2007 and VOC2012 training models, the training accuracy and recognition efficiency are obtained, and the target recognition experiment is carried out by using network pictures.
Keywords:Deep learning; Convolutional Neural Network; Image recognition; SSD
目 录
第1章 绪章 1
1.1研究背景以及意义 1
1.2 研究现状 1
1.3 研究内容 3
第2章 基于深度学习的目标检测的原理及算法 4
2.1 深度学习的结构 4
2.1.1 生成型深度结构 4
2.1.2 判别型深度结构 5
2.1.3 混合型深度结构 7
2.2卷积神经网络特点 8
2.2.1局部感受野原理 8
2.2.2 权值共享原理 9
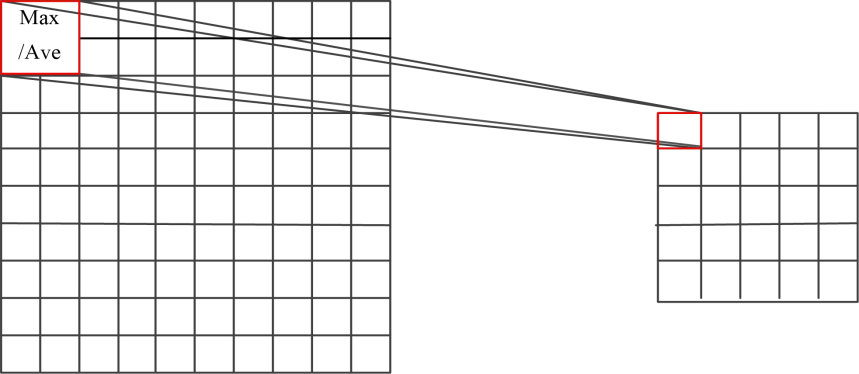
2.2.3 池化卷积 9
2.3 SSD网络算法 10
2.3.1 默认框 12
2.3.2 损失函数 13
2.4 本章小结 14
第3章 基于 Caffe 的深度学习目标识别实验平台搭建 15
3.1 Caffe学习框架概述 15
3.2 Caffe的架构特性 15
3.3 Caffe实验环境的搭建 16
第4章基于Caffe-SSD 的目标识别实验 17
4.1 Caffe-SSD的训练数据选取和设置 17
4.2 Caffe-SSD的网络训练过程 18
4.3 图片识别与结果分析 18
第5章 总结与展望 19
5.1 总结 20
5.2 展望 20
参考文献 21
致谢 22
第1章 绪章
1.1研究背景以及意义
近年来,云计算,大数据的产生,使得生活中的数据不断向云端聚集,而云端的数据也影响着每个人数据的获取与处理。在这些数据中,随着网络带宽的提升,图片取代文字在网络上成为主流信息载体。同时在安全领域,随这安全系统成本的不断下降,大量实时图片,视频信息在不断的产生。这说明,过去人们近乎点对点单一映射的,传播效率低的文字信息式已经逐渐被可跨地域,跨文化传播图像信息所取代。在全球化不断推进的今天,信息壁垒不断地被打破和摧毁。信息总量的提升和信息获取难度的降低使得每个终端,云端的信息处理方式都要朝着更高效的方法进化。因此,当今时代如何从海量的信息中获取有效的信息,已经取代了前互联网时代如何获取大量信息成为最大的难题。
在图标识别领域,如何从获取的图像中快速有效地识别目标对象类别是非常重要的。随着深度学习算法的实现变为可能,电脑取代人脑成为图片识别的主力已经慢慢成为现实。图像识别主要通过使用计算机对图片进行数字化处理后,经过卷积等操作,并提取特征信息获得的目标图像,并通过这些信息训练目标识别算法。深度学习卷积网络不同层级的连接,经过多次卷积,在每次处理中从目标图像中提取不同的特征,获得特征图象。这种方式实现了计算机在脱离人工设计特征后的自动形成特征识别,从而在保证精度与准确性的前提下取代效率低下的手工识别方式。进而引导如公共安全,工业生产,摄影领域的进化,并催生出一大批,如人脸识别,巩膜识别,自动驾驶等新兴领域。可以说是当代计算机科学领域的前进方向,具有极高的价值。
1.2 研究现状
在当前深度学习的发展中,目标识别越来越受到关注。数字图像已成为安全监控、车辆驾驶仪、传感器环境感知、智能识别、卫星遥感等领域的主要数据流量。习算法在硬件条件可以达到实现深度学习前,视觉算法通常通过人工方式进行图像处理,获得参数,处理效率低,且只在特定领域可实现较高精度。深度学习理论与手工设计算法相比更具多样性,复杂性和环境适应性通过将图片转化为文字,成为计算机可识别,可运算的特征信息。因此,它具有计算机自我学习,计算分析能力,比人工处理的识别更加准确
神经网络理论提出时间非常早,和计算机诞生几乎同步,早在七十多年前,就有关于其预言。而在三十年前,研究者再一次尝试该理论,但受限于时代,该理论并没有得到很好的发展。1986 年Rumelhart,Hinton 和Williams 在《自然》发表了著名的反向传播算法用于训练神经网络,直到今天仍被广泛应用[1]。
由于硬件计算能力的限制,神经网络并没又进入实际场景,只能在实验室中进行理论研究。由于网络复杂度的原因相对于当时算法和计算能力都过于巨大,使得算法在实验中效果不佳,产生的回归无法得到优化[2]。一方面有由于数据及训练集大小的限制,算法迭代能力有限,另一方方面计算能力不足导致训练时效率低下。此时神经网络只能作为一种理论上的算法存在,而无法进行有价值的运用。
于此同时诸如SVM、Boosting、KNN等浅层机器学习模型适应当时的硬件水平,得以发展和应用。通过一次卷积完成输出至输入的映射和特征提取,不存在多层网络带来的复杂度上升。这些算法并不具备学习进化能力,只能通过预设来完成特定的任务,现实场景应用有限。例如语音识别采用高斯混合模型和隐马尔可夫模型,物体识别采用SIFT 特征,人脸识别采用LBP 特征,行人检测采用HOG特征[3]。
由多伦多大学的Geoffrey Hinton提出了深度学习。由于其革命性的展现出对于传统弱机器学习的优势,受到广泛关注。神经网络在今日成为主流有几大基础。首先是云计算,大数据的使得信息量暴增,通过多次迭代防止过度拟合产生。计算机硬件随着摩尔定律的提升,也使大规模神经网络训练效力大大提高。一片GPU 也可以展开训练。算法的进步使神经网络训练和形成都更加高效。在各种卷积级别网络中,由非监督和独立训练组成的预训练模式可以达到局部最优解。然后通过前向传播实现全局优化。
深度学习在计算机视觉领域最具影响力的突破发生在2012 年,Hinton 的研究小组采用深度学习赢得了ImageNet 图像分类的比赛[4]。ILSVRC是最近高水平的视觉算法竞赛之一,代表了图像领域的最高水平。通过来源于网络上规模超百万的图片集进行训练。在2012 年的比赛中,排名2 到4 位的小组都采用的是传统的计算机视觉方法,手工设计的特征,他们准确率的差别不超过1%。Hinton 的研究小组是首次参加比赛,深度学习比第二名超出了10%以上[5]。展现了深度学习相较于传统方法的巨大优势,引起学界的广泛关注。
近年来,大量的更有效和精确模型如AlexNet , VGNet, YOLO,Faster R-CNN , SSD和ResNet出现,机器视觉识别的效果和精确性开始达到或超越人眼,深度学习算法在机器视觉识别领域推动作用巨大。
吉尔西克教授发明的 Fast R-CNN算法,直接将Bounding Box Regression进行训练,从而,首次提出多任务损失函数。实现了卷积层通用来降低参数数量从而极大的提升运算速律。然而Fast R-CNN由于其窗口选区的问题不能将所有有效参数提取,且效率低下。为了改进该算法待选样本匹配速度问题的,任少卿等人设计的Faster R-CNN 加入了一个全新的RPN网络与原网络通过权值共享连接,来进行训练,通过使用图像处理的方法来预测目标的位置的可能区域,然后在这些候选帧中选择准确的目标而不是将时间浪费在无效目标上。因此,FasterR-CNN的准确度明显高于Fast RCNN。 AlexNet 和 Faster R-CNN 网络所能卷积次数少,迭代能力差,网络深度不足。何恺明等人提出的 ResNet 网络克服了深层网络会出现梯度弥散(Vanishing Gradient Problem)现象。深度残差网络跨过中间层级的方法实现连接,解决了学习精度无法随网络加深提升。与这种前向传播网络不同的YOLO算法,它只进行一次CNN运算就可以获得滑动窗口所有分类运算,在每个网格中都会由预测运算。使YOLO 算法计算能力强大的硬件上进行实时计算机视觉识别成为可能。虽然 YOLO 算法的相比前代算法的识别速度产生质的飞跃,但是精确性有所下降,相较于人眼的识别精度有所不如。最后,SSD 算法在继 Faster R-CNN 和 YOLO 算法之后提出。SSD 算法的特点在于识别尺度的多样性与跨度。相比YOLO滑动窗口,多窗口工作模式可以取得更多有效特征值,因此 SSD 算法实现速度和精度提升。SSD 的出现改变视觉识别的应用边界,从此走出实验室,让现实场景实时应用从理论走向现实。
1.3 研究内容
随着深度学习算法不断演进,目标识别技术的精确度和速度也呈现螺旋上升的趋势,但是在实时场景下的物品识别与分类还存在着识别速率,识别成功率的问题有待解决。SSD算法作为当前比较先进的算法在这些场景下均有不错的表现,他的多尺度特征图识别,保证了识别的精确性此,也有效的提升了算法的效率。
主要研究内容具体分为以下几个部分:
- 研究并深度学习及卷积网络的原理,分析深度学习的生成型深度结构,判别型深度结构,混合型深度结构的组成特点。理解卷积神经网络的局部感受野原理,权值共享原理,下采样原理。
- 在Linux系统下构建可供SSD算法运行的Caffe框架,创造算法的运行环境搭建基于GPU运行的实验环境
(3) 在以搭建的平台上通过PASCAL VOC训练集和测试集对算法进行训练和测试获得算法测试数据,并通过改变选择框设置来改变SSD的识别效果。最后针对网络图片进行图片单张识别,测试系统的效率和实际的识别效果。
基于深度学习的目标检测的原理及算法
本章将对深度学习和卷积网络的原理及发展进行梳理分析,介绍了不同深度学习结构的特点及优势,介绍了卷积网络的原理与构成。通过对算法进步和对于网络具体问题分析讨论算法进步的方式的分析,以此来引出SSD算法。讨论SSD相对于前代算法的优势及改进。总结了SSD在具体选框与目标函数的实现方法
2.1 深度学习的结构
卷积神经网络、深度学习、机器学习这三个概念之间联系很紧密。深度学习是一种实现机器学习的方法,甚至可以说深度学习直接脱胎于机器学习理论;而卷积神经网络是深度学习框架下一种典型的算法。对于机器学习过程可以将其通俗的理解为在电脑上编写程序使它能实现某种功能的过程。在这里首先介绍深度学习。
对于这种网络,我们因为其卷积方向的原因可以将其分为 3 个类别:生成型深度结构、判别型深度结构和混合型深度结构。按照所提出的基础算法不同,可根据其多领域可分为5个类别:RNN;LSTM/GRU;DBN;CNN;DSN。
2.1.1 生成型深度结构
该结构通过对输入的多次卷积,获得了高次特征值,这些特征值对应着某一层局部特征,再通过对不同层的加权处理,获得输出的特征分布。与传统的神经网络不同,生成型深度结构可获得观测数据和对应类别的联合概率分布,这样可以方便进行先验概率和后验概率的估计,而传统神经网络仅能对后验概率进行估计。Hinton 教授发明的深度置信网络(Deep Belief Nets,DBN)就属于生成型深度结构。这种结构实现了对于BP的改进,在训练的程度加深后,迭代效果减弱,并开始出现拟合的问题,在总体上都有巨大的改善。DBN 由一系列受限波尔兹曼机(Restricted Boltzmann Machines,RBM)层组成。RBM 的网络结构如图 2.1 所示[6]。
图 2.1 RBM 结构
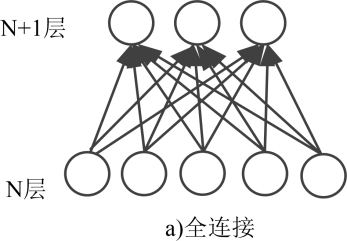
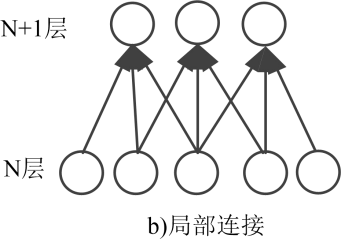
RBM拥有两个层级:输入层和特征提取层。它起源于全连接(各个神经元间都进行连接)的Holpfield网络。它的改进在于只在两层之间存在连接。限制性波尔兹曼机中,两个层级中在层级内部神经元是独立的,能否改变状态直受另一个层级影响
如图 2.1 中n所对应输入层,卷积层中所具有的神经元的数量。v = (v1,v2,v3...vn,)T表示可见层的状态向量Rw。W = wi 个神经元与可见层中第 j 个神经元之间的连接权值[7]。RBN网络的学习被看作是对不同特征的加权问题,即训练样本的最大概率分布问题。图中的W对应着输入层和卷积层间的映射,通过对不同映射进行加权运算,获得全局最优解。
DBN采用了多限制性波尔兹曼机的叠加,如图 2.2 所示为网络自我学习过程。
为了保证映射特征准确,每一个RBM网络都要进行自我学习,在这个过程中,实现获取映射能最大程度传播
然后加入BP网络进行训练,将其作为RBM网络输出的筛选,保证无效映射返回出发层级重新进行训练,实现网络优化。将系统原本的,深层训练时特征集中到各个层级的局部最优解进行返回,以实现整个DBN网络的的优化和全局参数调整,让训练可以朝向更深层次进行。
图 2.2 DBN 训练过程
2.1.2 判别型深度结构
判别型深度结构的能对输入信息进行卷积后获得的样本进行是识别和划分,描述样本相对输入的拟合度。相较于浅层网络,拥有多层次结构的CNN,可以保证对预处理数据的最小化,全局参数共享减少参数,提升学习效率,通过加权分配简化系统结构。这是一个学习算法,可以更好地训练。CNN 算法模型结构主要由卷积层、池化层及全连接层等组成,如图 2.3 所示,CNN在视觉识别方面拥有巨大的潜力,可以高效的在图像矩阵提取有效参数。
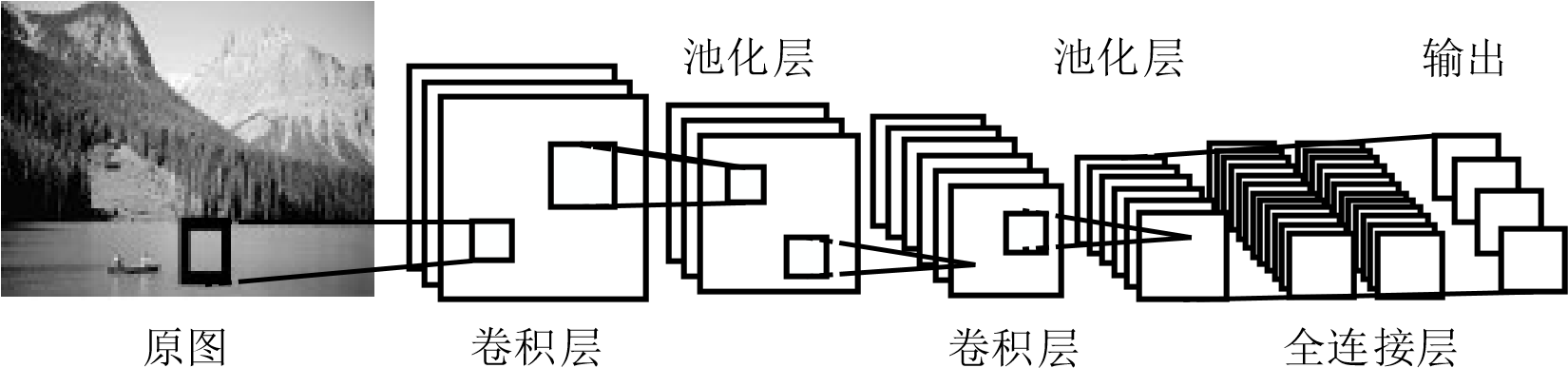
图 2.3 基于 CNN 的图像识别工作参考过程
(1)卷积层
CNN网络首先将目标进行截取,将截取后的图像进行卷积以提取特征值。某一层卷积表达为:
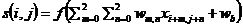 (2.1)
(2.1)
矩阵首个元素的计算方法为:
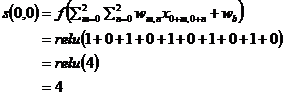 (2.2)
(2.2)
某一隐藏层在对所有图像部分进行卷积运算后即得到图像在该层的网络参数卷积后获得的信息,在每一个层级重复同样的操作,网络深度越大,提取特征越多。不同卷积层的特征矩阵位移和比重是一样的。将每一层级产生的所有矩阵叉乘,在与各个卷积层的矩阵叉乘后除以矩阵数量,如式(2.3),即可得到输出特征矩阵
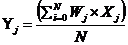 (2.3)
(2.3)
(2)池化层
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: