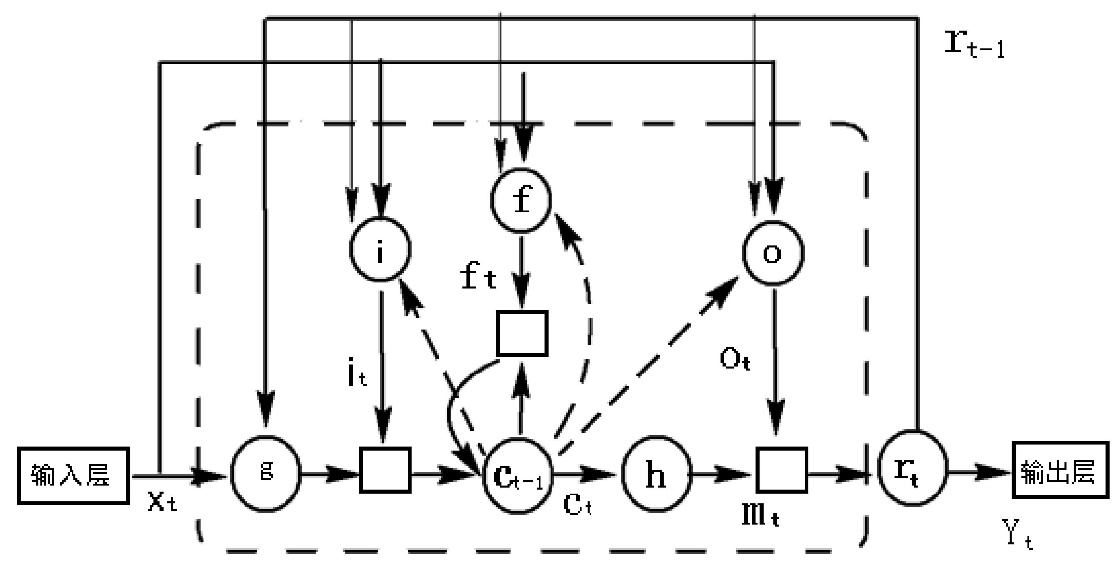
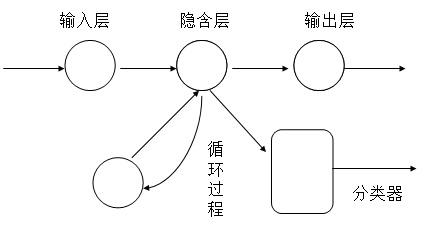
基于循环神经网络的语音识别方法设计毕业论文
2020-02-17 23:18:11
摘 要
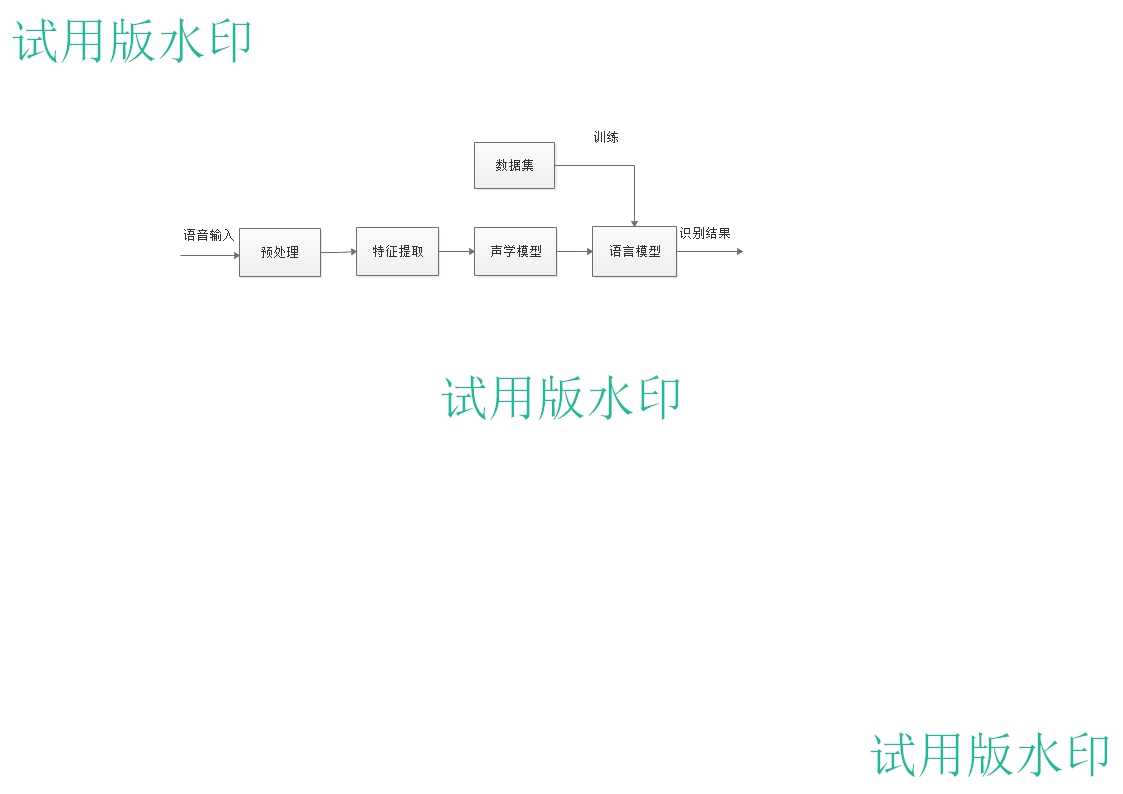
本文介绍了基于神经循环网络的语音识别系统框架及实现方法,包括语音识别的发展历史及发展现状。重点阐述了深度学习中循环神经网络的原理及相关算法,通过阅览相关学术期刊文献,借助python语言搭建框架,使用大量中文语音数据集进行训练,将声音转译为中文拼音,并通过语言模型,将拼音序列转换为中文文本。本算法模型在测试数据集上获得了75%的平均识别准确率。
本语音识别系统的声学模型基于循环神经网络,将语谱图作为输入。模型结构上,借鉴了图像识别中效果最好的网络配置VGG,在语言模型上,通过最大熵隐含马尔可夫模型,将拼音序列转换为中文文本,用已有语音数据集训练自己的神经网络模型,并在查阅期刊文献的参考下,完成对模型结构的优化,提高语音识别准确率。测试中将网络公开语音数据集和周围人语音录音进行识别测试,报告识别准确率。
关键字:神经网络,语音识别,深度学习
Abstract
This paper introduces the framework and implementation of speech recognition system based on Recurrent Neural Network, including the history and process of speech recognition. The principle and related algorithms of the Recurrent Neural Network in deep learnning are expounded. By reading the relevant academic journal literature, using the python language construction framework, using a large number of Chinese speech data sets for training, translating the sound into Chinese Pinyin, and transforming the Pinyin sequence through the language model. For Chinese text. The algorithm model achieved 80% recognition accuracy on the test data set.
The acoustic model of the speech recognition system uses a cyclic neural network with a spectrogram as input. In the model structure, the best-performing network configuration VGG in image recognition is used. On the language model, the Pinyin sequence is converted into Chinese text by the maximum entropy implicit Markov model. In the test, the network public voice data set and surrounding human voice recordings were identified and tested, and the recognition accuracy was reported.
Keyword:Recurrent Neural Network;Speech recognition;Deep learning
目录
第1章 绪论 1
1.1研究目的及意义 1
1.2国内外研究历史及现状 1
1.3语音识别存在的问题 2
第2章 语音识别基本理论 4
2.1语音特征提取 4
2.2 TensorFlow开源库 6
2.3CTC解码 7
2.4语音识别原理 8
第3章 循环神经网络概述 10
3.1循环神经网络模型结构 10
3.2循环神经元 11
3.3 RNN的反向传播及其优势劣势 12
3.4长短期记忆网络 13
第4章 神经网络优化及语音识别测试 15
4.1网络结构改进 15
4.2测试识别模型精确度 16
4.2.1基于清华大学THCHS30中文语音数据集的测试 16
4.2.2基于作者环境的语音识别测试 17
第5章 总结与展望 19
参考文献 20
致谢 21
绪论
1.1研究目的及意义
近几年“人工智能”话题持续火热,其中,让机器听懂人类说话是实现机器智能的一个重要部分,机器语音识别的发展,让机器在识别二进制数的“一维语言”和识别高级语言的“二维语言”提高至识别语音的“三维语言”,甚至能从人类语气感知情绪变化。作为人工智能的关键技术之一,人机语音交流技术一直以来备受各界科学研究人士的关注,从智能手机的出现,手机语音助手一直是智能手机智能的一大智能表现,其技术也一直得到各手机厂商的研发投入和更新,听懂人说话已经是家常便饭,还可以帮助人类完成部分手机操作,可能在部分人群中被使用频率较低,但不可否认的是,该技术已经走进人们的生活,研究人员也正在开发其在更多场合的功能,例如医院、公安局、超市等场合。
语音识别技术可以按照执行识别动作的不同分为四个方研究方向:
⑴说话者识别:主要是通过声音识别说话人的身份,由于每个人的生理特征不同,每个人的声音都不一样,而且由于每个人的说话的方言、韵律、腔调影响,可以实现说话人的识别,生活中,支付软件支付宝已经把声纹识别加入安全锁的一部分。
⑵关键词检出:在一些特定的场合,只关注包含特定关键词的句子,实现特定功能。例如在指定报警点,只要听见“报警”、“救命”等关键词,可以向公安部门发出报警信号。
⑶语言辨别:通过一些语音片段实现判断其语言所属种类。比如泰国人说话,可以对泰国人的语音判别其说的是泰国话或是其他的语言。
⑷语音识别:也是人们常说的语音识别,以人们说的话为识别对象的识别技术,可以将其转换为文本或特定操作指令。
语音识别技术可以将人类语音识别,通过建模3D图像编译手语手势,并实时进行翻译,实现正常人与聋哑人沟通交流,还可以把说中文的人说话翻译成其他语言,实现翻译功能,包括方言识别、翻译;出国旅游,语言不再是障碍,医院等特殊场合实现指路、事务咨询功能。
语音识别正因其广泛用处日益受到科学各界重视,虽语音识别技术还未完全开发,识别准确度也有待提高,但人们已经意识到其功能性及便捷性,我们完全有理由相信,它可以为人类生活带来天翻地覆的改变。
1.2国内外研究历史及现状
1982年,美国学者John Hopfield基于Little (1974) 的神经数学模型使用二元节点建立了具有结合存储(content-addressable memory)能力的神经网络,即Hopfield神经网络 。Hopfield网络是一个包含外部记忆(external memory)的循环神经网络,其内部所有节点都相互连接,并使用能量函数进行学习 。
1986年,Michael I. Jordan基于Hopfield网络的结合存储概念,在分布式并行处理(parallel distributed processing)理论下建立了新的循环神经网络,即Jordan网络 。Jordan网络的每个隐含层节点都与一个“状态单元(state units)”相连以实现延时输入,并使用logistic函数(logistic function)作为激励函数 。Jordan网络使用反向传播算法(Back-Probagation, BP)进行学习,并在测试中成功提取了给定音节的语音学特征。之后在1990年,Jeffrey Elman提出了第一个全连接的循环神经网络,Elman网络 。Jordan网络和Elman网络是最早出现的面向序列数据的循环神经网络,由于二者都从单层前馈神经网络出发构建递归连接,因此也被称为简单循环网络(Simple Recurrent Network, SRN)。
在反向传播算法的研究受到关注后,学界开始尝试在BP框架下对循环神经网络进行训练 。1989年,Ronald Williams和David Zipser提出了循环神经网络的实时循环学习(Real-Time Recurrent Learning, RTRL)。随后Paul Werbos在1990年提出了循环神经网络的随时间反向传播(BP Through Time,BPTT),RTRL和BPTT被沿用至今,是循环神经网络进行学习的主要方法 。
1991年,Sepp Hochreiter发现了循环神经网络的长期依赖问题(long-term dependencies problem),即在对序列进行学习时,循环神经网络会出现梯度消失(gradient vanishing)和梯度爆炸(gradient explosion)现象,无法掌握长时间跨度的非线性关系。为解决长期依赖问题,大量优化理论得到引入并衍生出许多改进算法,包括神经历史压缩器(Neural History Compressor, NHC)、长短期记忆网络(Long Short-Term Memory networks, LSTM)、门控循环单元网络(Gated Recurrent Unit networks, GRU)、回声状态网络(echo state network)、独立循环神经网络(Independent RNN)等。
1.3语音识别存在的问题
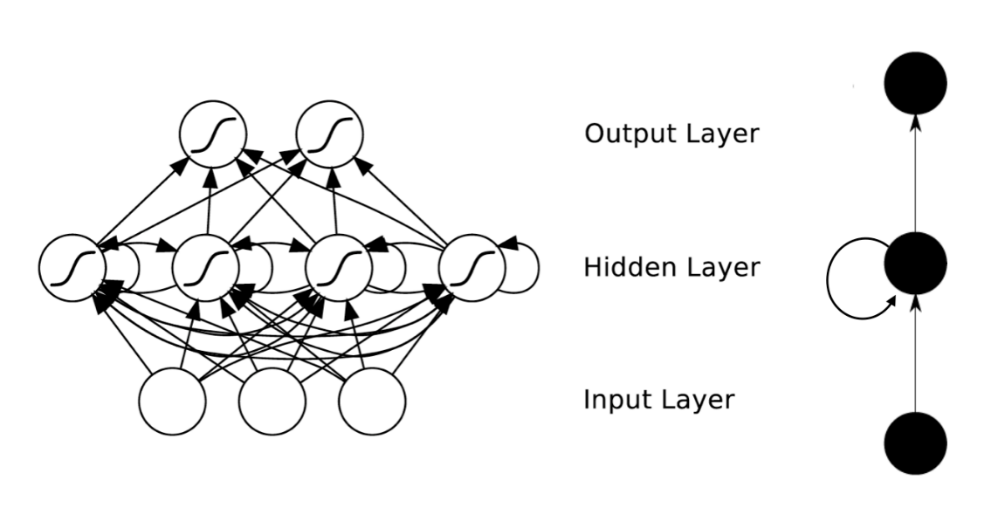
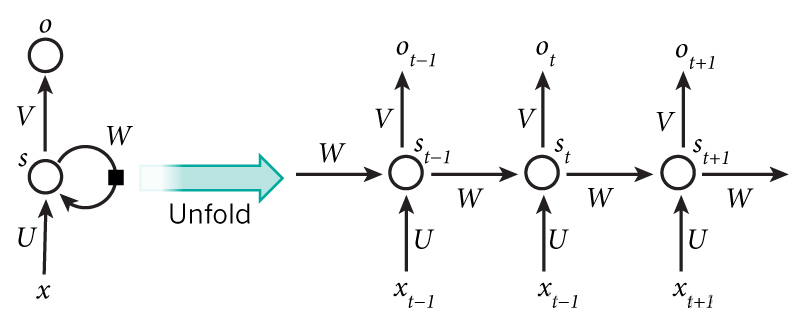
循环神经网络(Recurrent Neural Network, RNN)是利用深度神经网络建立的语言模型,是“一类人工神经网络在单位之间的连接形成一种循环,这使其可以表现出一种动态的时间行为也是目前语言模型领域的一个研究热点[1]”。众多科研人员奋斗多年的进行研究,致力于完善基于神经网络的语言识别模型,让语言识别技术更成熟、性能更优秀。但由于对语言模型的研究还不够,还有很多问题待优化:
(1)“循环神经网络的结构复杂,传递参数多,计算量通常巨大[2]”。受限与硬件计算机性能,通常需要花销大量时间。一般情况下,神经网络不仅是网络层次复杂,而且计算过程传递多。与此同时若想将一个神经网络模型训练好我们必须要有大量的训练集作为训练数据集,而且数据集必须要与研究方向一致,只训练一个数据,搭建的模型是没有“见识”的模型,必须要让模型“大开眼界”,它才是一个具有完整能力的模型。例如微软所发布的最新语音识别模型,即使在全球领先的计算机硬件环境下,为了达到实际应用的表现,训练过程仍然持续了一个多月才完成。因此,神经网络在简化模型以削减训练时间开销和降低计算机硬件依赖方面仍有研究的必要。
(2)循环神经网络模型在处理识别在嘈杂环境下的语音任务时其识别率还有待提高。在嘈杂环境下,环境噪音给模型带来识别困难,模型难以区分人的语音和环境噪音,语音识别率受影响较大,在使用手机、录音笔等移动式设备的,语音失真尤为明显。在真实环境中,基于循环神经网络的语音识别模型能否采用其他方案来削弱乃至消除环境噪音的影响,以至于在真实应用环境中能达到实验室中的高识别率水平,仍然是一个待解决的问题。
(3)用户独立性。每个人都是一个个体,没有两个完全一样的人,也没有完全一样的嗓音,每个不同的人都有自己不同打嗓音,及说活的方式,就算网络模型训练了大量的语音数据集,数据集也始终不能代表所有人,且在不同环境下生活的人,可能受方言、性格的影响,说话发育和语速都有很大差别,就拿的民族布依族来说,从小说着布依话的布依族人,受方言影响说普通话容易出现拼音中的声母“t”读成“d”等不标准发音,而在方言的识别中,由于工作量庞大,没有足够的数据集作为数据支撑,难以实现方言的语音识别。
语音识别基本理论
2.1语音特征提取
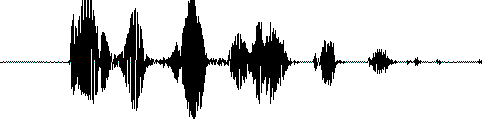 我们知道声音实际上是一种波,输入的音频文件格式为wav格式,wav格式文件存储的是文件头和一个个声音波形的点,声音波形图如图2-1。
我们知道声音实际上是一种波,输入的音频文件格式为wav格式,wav格式文件存储的是文件头和一个个声音波形的点,声音波形图如图2-1。
图2-1 声音波形图
在提取语音特征之前,首位段的静音段需要切除,避免对后续识别步骤产生不必要影响,这个静音切除操作称语音活动检测(Voice Activity Detection,VAD),需要对语音波形信号分析,涉及到信号处理的相关知识。需要对声音波形信号分帧,把语音信号分成小段,一个小段称为一帧。“通过分帧可以获取到平稳的局部音频信号[2]”。“分帧操作不是把声音信号切成动画里的帧那样不相干,帧和帧之间存在交叠[3]”,帧与帧的如图2-2:
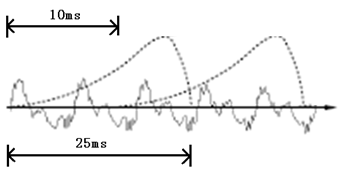 图2-2 帧与帧的交叠
图2-2 帧与帧的交叠
图2-2中,第一帧的长度为25毫秒,第一帧和第二帧之间有25-10=15毫秒的交叠。可以说成帧长25ms、帧移10ms分帧。图中,每帧的长度为25毫秒,每两帧间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
将普通的wav语音波形转换为神经网络需要的二维频谱图像信号,即语谱图如图2-3。
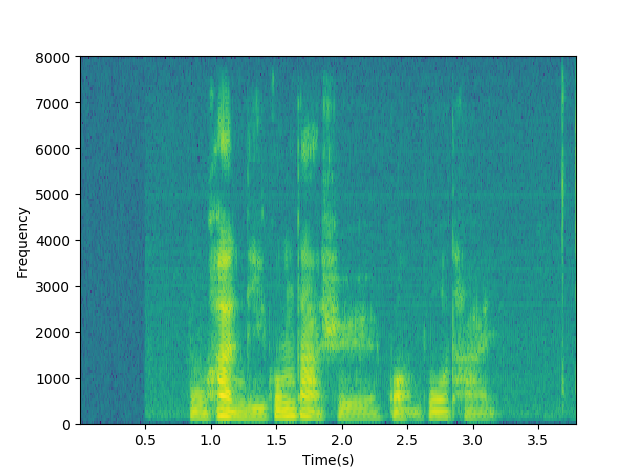 图2-3 语谱图
图2-3 语谱图
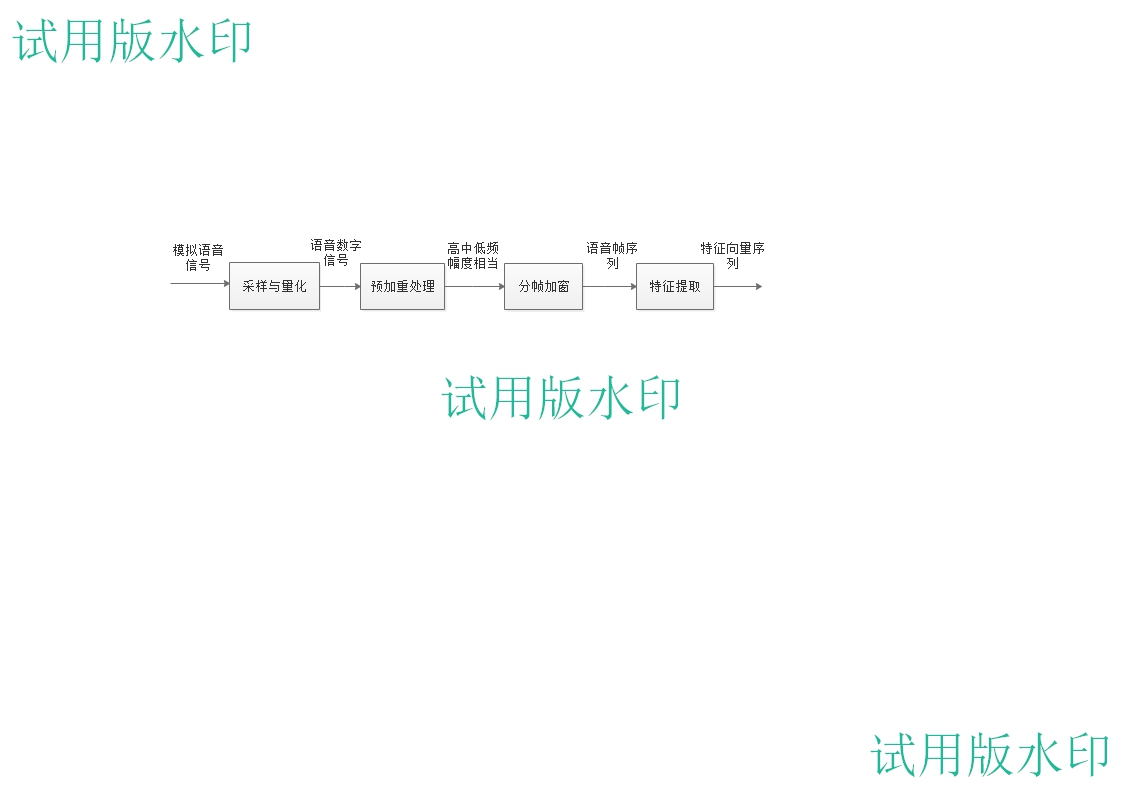 总的来说,语音特征提取流程如图2-4所示:
总的来说,语音特征提取流程如图2-4所示:
图2-4 语音特征提取流程图
输入是一个模拟的语音信号,通过设备的采样、量化,得到一个可以存于计算机的数字信号文件,经预加重处理使高中低频信号幅度相当,此举是为了方便对声音信号的提取,下一步将处理后的信号分帧加窗得到一组语音序列,再由MFCC系数倒谱提取出语音信号的特征向量序列,完成对语音信号的特征提取。
在语音特征提取中,有多种参数可以选择,常用的有梅尔频率倒谱系数 (Mel-Frequency Cepstral Coefficients,MFCC)和线性预测倒谱系数(Linear Prediction Cepstrum Coefficient,LPCC),“除了传统MFCC特征之外,目前较流行的DNN技术也可用于特征提取[3]”。本文采用了梅尔频率倒谱系数,近年来,在语音识别技术上,MFCC得到了广泛应用,“对比LPCC发现,MFCC鲁棒性更强,更加符合人耳的听觉特性[4]”。
MFCC参数和实际频率的转换关系为:
(2-1)
MFCC计算步骤如流程图2-5所示。计算流程如下:首先,确定一帧语音序列的采样点数,再通过离散FFT变换,取模的平方,并得到一个离散功率谱S(n),计算S(n)通过M个后得出的功率值,得到M个参数的自然对数,得到计算其离散余弦变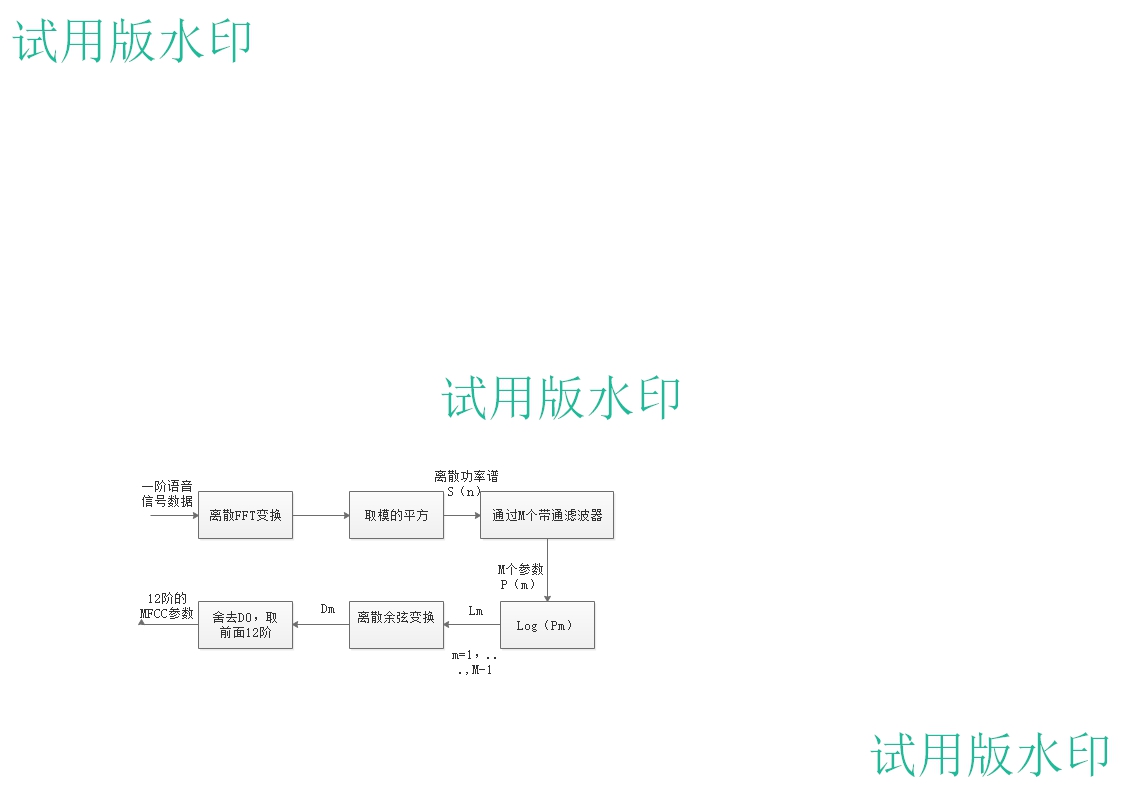 换得,取作为MFCC参数,本文中k等于1到12的整数。
换得,取作为MFCC参数,本文中k等于1到12的整数。
图2-5 MFCC计算过程
2.2 TensorFlow开源库
机器学习是一门复杂的学科。但是,由于机器学习框架(例如Google的TensorFlow)可以简化获取数据,培训模型,提供预测和改进未来结果的过程,因此实施机器学习模型远不如以前那么令人生畏。
而本文设计基于python下的Keras和TensorFlow框架,参考了VGG的深层卷积神经网络作为网络模型,TensorFlow由Google Brain团队创建,是一个用于数值计算和大规模机器学习的开源库。TensorFlow将大量机器学习和深度学习(又称神经网络)模型和算法捆绑在一起,并通过一个常见的比喻使它们变得有用。它使用Python提供方便的前端API,用于使用框架构建应用程序,同时在高性能C 中执行这些应用程序。
TensorFlow 中的数据流图有以下几个优点:
TensorFlow为机器学习开发提供的最大好处是抽象。开发人员可以专注于应用程序的整体逻辑,而不是处理实现算法的细节,或者找出将一个函数的输出与另一个函数的输出联系起来的正确方法。TensorFlow负责幕后细节。
TensorFlow为需要调试和获取TensorFlow应用程序内省的开发人员提供了额外的便利。热切的执行模式允许分别和透明地评估和修改每个图形操作,而不是将整个图形构造为单个不透明对象并一次评估所有图形TensorBoard可视化套件允许您通过基于Web的交互式仪表板检查和分析图形的运行方式。
当然,TensorFlow在谷歌的A-list商业的支持下有许多优势。Google不仅推动了该项目背后的快速发展,而且围绕TensorFlow创建了许多重要产品,使其更易于部署和使用:上述TPU芯片可加速Google云端的性能、用于共享使用框架创建的模型的在线中心、浏览器和移动设备友好的框架化身等等。
在使用Python语言编程时,一般会使用到NumPy库以便做一些计算操作,NumPy在做某些复杂的计算的时会使用其他便于计算语言(C/C )来实现同样逻辑计算操作,以保证计算效率。但是另一个问题也值得考虑,那就是如果频繁的在不同语言之间切换,其时间开销不容忽视,如果这种切换只在单机上,开销可以忽略不计,但是在庞大数据下,往往需要并行计算机来处理这些操作,数据切换可能发生在不同的CPU、不同的GPU或者不同的计算机,这样耗时就比较严重,不可以忽视。
2.3CTC解码
CTC算法全称叫:Connectionist temporal classification。一种目标函数,它允许RNN被训练用于序列转录任务,而不需要输入序列和目标序列之间的任何先前对齐。在语音识别的声学模型训练中,训练之前,每一帧数据都需要知道对应的参数,下一步才可以进行有效的训练,在训练数据集之前需要按照特征提取流程对语言数据集预处理操作。可以使用波束搜索算法执行更准确的解码,这也使得可以集成语言模型。 该算法类似于用于基于HMM的系统的解码方法,但由于网络输出的改变的解释而略有不同。在预处理阶段,语音对齐的过程需要大量迭代,从而保证语音对其准确,这个过程比较耗时。
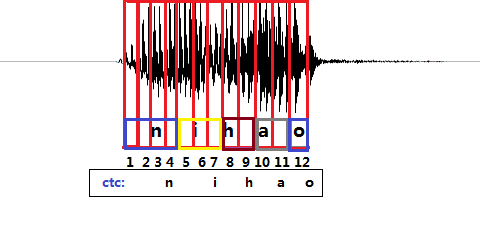
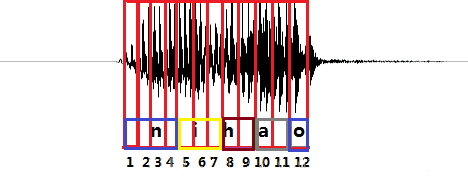 例如“你好”的拼音是“nihao”,拼音分为“n”、“i”、“h”、“a”、“o”,“你好”的普通话发音波形图如图2-6,一个竖框代表一帧,传统解码方式需要定位哪一帧对应哪一个音素。例如前4帧对应“n”音素,第5-7帧对应“i”音素(在一个字母对应一个音素的假设条件下)。但采样CTC解码的模型与传统解码方式的模型相比,使用CTC作为解码方式的声学模型不需要对数据做对齐处理,这是一种完全端到端的声学模型训练。这样对模型训练不再需要外部的后处理。也不需要一一标注预测,也不再需要将数据对齐,CTC直接把预测概率输出。
例如“你好”的拼音是“nihao”,拼音分为“n”、“i”、“h”、“a”、“o”,“你好”的普通话发音波形图如图2-6,一个竖框代表一帧,传统解码方式需要定位哪一帧对应哪一个音素。例如前4帧对应“n”音素,第5-7帧对应“i”音素(在一个字母对应一个音素的假设条件下)。但采样CTC解码的模型与传统解码方式的模型相比,使用CTC作为解码方式的声学模型不需要对数据做对齐处理,这是一种完全端到端的声学模型训练。这样对模型训练不再需要外部的后处理。也不需要一一标注预测,也不再需要将数据对齐,CTC直接把预测概率输出。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: