基于Scrapy框架的爬虫系统的设计与实现毕业论文
2020-02-17 23:21:27
摘 要
随着互联网的普及,信息通信技术迅猛发展,网页数量和网络上的信息量都呈指数倍的增加。巨量的数据,帮助社会进步的同时也给用户带来了新的挑战。目前几个大型的搜索引擎只能提供模糊的搜索结果,且结果信息分散在各处,不便于用户进行高效的查找与分析。
针对上述问题,本文利用Python设计了一种小型简单的网络爬虫系统,实现了制造信息的高效的爬取,并对爬取的信息进行了处理与分析。本文的主要工作包括:
(1)详细介绍了Scrapy框架的工作原理,网页的结构组成以及网络爬虫的相关知识。
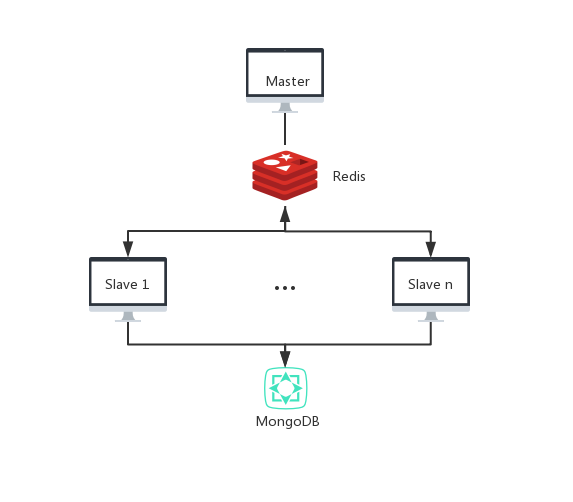
(2)在Scrapy框架基础上设计并实现了一种基于Scrapy-Redis框架的主从分布式网络爬虫系统。对网站源代码的分析,设计编写相应的模块,将Linux服务器作为主节点,实现了制造信息的高效抓取,并将信息经过清洗处理后,存储至数据库中。
(3)对储存在数据库中的制造信息,通过数据分析可视化软件Tableau,以图表形式更直观的展示制造信息,并对结果进行了简单分析。
关键词:Scrapy框架;网络爬虫;数据可视化
Abstract
With the popularity of the Internet, information and communication technologies have developed rapidly, and the number of web pages and the amount of information on the Internet have increased exponentially. A large amount of data brings new challenges to users and helps society advance.
In response to the above problems, this paper uses Python to design a small and simple web crawler system, which realizes efficient crawling of manufacturing information and processes and analyzes the crawled information. The main work of this paper includes:
- We've covered in detail how the Scrapy framework works, the structure of the web page, and the knowledge of web crawlers.
(2) This paper designs and implements a master-slave distributed web crawler system based on Scrapy-Redis framework. Analyze the source code of the website, design and write the corresponding module, take the Linux server as the master node, realize the efficient capture of the manufacturing information, and store the information in the database after cleaning the information.
(3) For the manufacturing information stored in the database, we use the data visualization software Tableau to display the manufacturing information in a graphical form and analyze the results.
Key words: Scrapy Framework; Web Crawler; data visualization
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.3 主要研究工作 2
1.4 论文的组织架构 2
第2章 网络爬虫相关原理概述 4
2.1 网页的基本原理 4
2.2 网络爬虫 4
2.2.1 网络爬虫的主要类型 4
2.2.2 网络爬虫的爬取策略 5
2.2.3 单机网络爬虫的工作流程 5
2.3各类爬虫框架分析 6
2.4 基于Scrapy框架的网络爬虫 7
2.4.1 Scrapy框架的组成 7
2.4.2 Scrapy框架工作原理 8
2.5 网络代理 8
2.6 网络爬虫的开发环境 9
2.6.1 Python语言 9
2.6.2 相关第三方库 9
2.6.3 Redis数据库 9
2.6.4 MongoDB数据库 10
第3章 基于Scrapy-Redis的分布式爬虫 11
3.1 分布式网络爬虫设计 11
3.1.1 爬虫架构的选择 11
3.1.2 方案总体设计 12
3.2 爬虫系统的详细设计 14
3.2.1 系统爬取方法设计 14
3.2.2 系统稳定性设计 17
3.2.3 数据存储设计 17
3.2.4 分布式部署的实现 19
3.3 爬虫系统的测试 19
3.3.1 测试环境 19
3.3.2 爬虫性能分析 20
第4章 爬取数据的处理与分析 21
4.1 数据的处理 21
4.2 数据的分析 22
第5章 总结与展望 24
5.1 总结 24
5.2 展望 24
参考文献 25
附 录 27
致 谢 30
第1章 绪论
1.1 研究背景及意义
互联网信息通信技术的快速发展和广泛普及、互联网数据信息的爆炸将人们带入了大数据时代,特别是这几年,互联网技术推动制造业产业更新,各种智能制造等也开始迅猛高速发展。制造业从各种维度将工业数据进行处理上传,变为可供消费者选择的定制化服务,同时消费者的决策也会及时反馈给制造业,反过来帮助制造业的产品线升级。制造业与消费者间形成一个以数据信息为载体的闭环,提高了资源利用率,同时也帮助了制造业的升级。
但是互联网上出现各种制造信息,散落在各处,或是和其他无用信息混在一起,截至2018年年底,在中国注册的网站域名超过2816亿个,相比于去年同期有大幅增长[1],目前通过一些大型搜索引擎,只能搜索出模糊的信息,需要花费大量的时间去辨别、整理。因此,本课题设计一种基于Scrapy框架的分布式小型爬虫系统,对数据信息进行初步的筛选和整理,以实现对制造信息的高效收集。
1.2 国内外研究现状
爬虫技术发展到今天,技术已经十分完善,同时也产生了很多优秀的开源的爬虫框架,如Nutch、Scrapy,这些开源框架的实现语言与侧重的功能各不相同。用Python语言开发的Scrapy框架,由于它设计简单易用,可扩展性高,广泛受到编程开发者的欢迎[2]。
国内学者针对Srapy框架扩展性强的特点,对其进行优化设计,研究出了一系列高性能的爬虫。
在爬虫架构优化与创新方面,樊海英通过将无界面浏览器PhantomJS与Scrapy框架相结合,实现了Scrapy框架的动态数据的抓取[3],从而能成功爬取一些采用数据异步加载的网站信息。樊宇豪通过将Scrapy框架与高性能数据库配合使用,设计出了一种扩展性强,使用方便的分布式的网络爬虫[4]。张树涛等人针对现有分布式爬虫系统中的节点负载不均衡,限制系统效率的现象,提出一种负载均衡策略[5]。
李远龙从采集数据的处理角度出发,设计开发了一种招聘信息检索系统,将在多个招聘信息网站爬取的有效信息进行数据整合,为应聘者提供了有效的指导作用[6]。丁忠祥等人设计了一种面向搜索影视信息和其评论的网络爬虫程序,制作了一个围绕影视信息及其评论的分析的工具[7]。
曾武序在去年提出了一种将Python与BP神经网络相结合的方法,利用多层BP神经网络对股票各项指数的权值进行计算,进而对走势进行预测,为投资者提供投资参考[8]。北京交通大学的周靖洋设计了一种基于NLP与分布式爬虫框架阅读类APP[9],该APP程序将NLP与分布式爬虫框架相结合,使用NLP对内容进行分析,并根据字典进行翻译,解决了外文阅读APP使用者的痛点。国防科学与技术大学的李逸鸣从网络安全出发,通过研究一般主题网络爬虫模型总结出网络中敏感信息的分布特点后,提出了面向网页的敏感信息提取模型[10]。
国外对网络爬虫的研究侧重方向也各有不同,Schäfer R提出了一种基于监督式机器学习的样板去除信息提取的方法[11],该方法采用多层感知器(MLPs)对爬虫爬取的信息进行分类,准确度可达95%以上。Kristoffersen K B则通过不断地训练优化,开发出了一种超大型的英语语料库[12],能帮助爬虫更快地进行语义分析和信息查重。J. Wang等人则通过爬取淘宝网上的用户使用痕迹,进行用户特征分析[13],对各类商户的策略决定有一定的帮助。
1.3 主要研究工作
本文基于Scrapy框架,针对单机爬虫爬取速度慢的问题,设计了一个分布式爬虫系统,实现了制造企业消费者产品的价格信息的抓取,主要完成了如下研究工作:
(1)对不同种类爬虫的优缺点进行了对比,阐述了爬虫主要采用的几种网页爬取方法,以及单机网络爬虫的工作流程。
(2)详细介绍了Scrapy框架整体与各个组件的功能,以及整个框架的数据处理流程。对两种不同类型的分布式爬虫架构进行了分析对比。
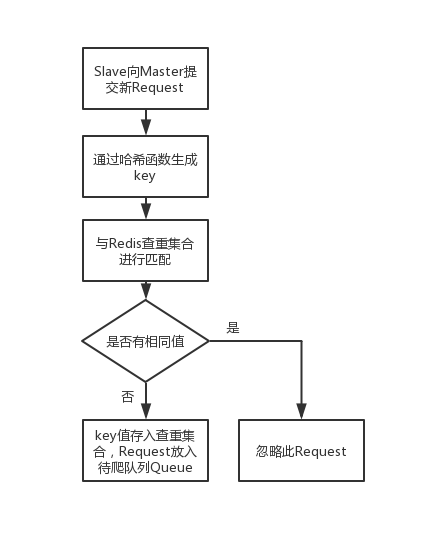
(3)基于Scrapy-Redis框架设计了一种主从分布式爬虫系统。利用基于内存存储的数据库Redis实现了URL的去重,提升了爬虫的工作效率。
(4)结合目标网站说明了分布式爬虫系统的的实现过程。针对于购物比价网站慢慢买,分析了其网站商品信息的存储结构,提出Spider爬取信息的具体方法,同时在服务器上设置了可供从节点公网访问的数据库,对Scrapy框架的各组件进行相关设置,完成了Scrapy-Redis框架与分布式的对接。
(5)测试了分布式爬虫的性能,对抓取到的数据进行了去重处理,分析,以及可视化展示。
1.4 论文的组织架构
论文后续章节具体内容如下:
第2章具体介绍了分布式爬虫系统需要涉及的相关系统。介绍了网页的基本构成,爬虫的历史发展和基本的工作原理。介绍了需要用到的非关系型数据库Redis和MongoDB的原理和基本概念。
第3章重点介绍了分布式网络爬虫的设计和实现,首先详细说明了分布式以及去重的实现方法。然后从目标网站的特点着手,运用Scrapy框架、Redis数据库、MongoDB数据库,进行了爬取方法的设置,实现了该系统。并在一定的环境下,对爬虫的性能进行了测试,通过记录各个从机爬取时间和爬去数量,计算出其平均爬取数据的速率,与单机爬虫进行性能的对比。并且在章节最后,根据其系统的结构特点,分析了此架构的不足之处。
第4章主要对采集到的数据进行数据清洗以及分析。首先对存储的数据进行了数据的清洗,主要包括空值数据的查找和替换,以及重复数据的查询删除,保证了分析用数据的可靠性、准确性。利用清洗后的数据,对面向消费者端的企业制造商品信息,从制造企业产品布局,产品定位等几个方面,进行了简单的分析。通过数据分析软件Tableau对数据结果进行了可视化的展示。
第5章先对本次选题研究内容进行总结,再对继续深度研究进行展望。
第2章 网络爬虫相关原理概述
2.1 网页的基本原理
每一个网页在互联网上都有一个独有的URL地址,用于进行网页服务器位置的确定。如果知道了网页的URL地址,人们就可以直接对网页进行访问[14]。我们在访问一个网址时,浏览器会生成一个包含各种信息的请求,通过DNS服务器对地址的查找,发给相应的网站服务器。网页服务器接收到请求后会进行简单判定响应,然后给浏览器返回网页信息,浏览器再将网站的内容呈现给使用者。
网页主要由以下几个部分组成:
HTML(Hyper Text Markup Language)是一种专门用于规定网页基本架构和内容的语言。其通过不同的标签来对文字、按钮、图片和视频进行分类。各种标签间的不同排列和嵌套形成了一个完整的网页[15]。
层叠样式表CSS,在网页中数个样式文件发生冲突时,其可以按照其规则顺序对其进行层叠显示。同时,通过CSS还能对网页中的文字的大小、颜色、间距、排列等进行设定。
JavaScript能使网页变得更加美观智能。HTML与CSS的搭配使用,只能展现出静态的网页,而JavaScript的使用可以增加用户和网页间的交互体验。通过JavaScript我们可以看见网页中一些交互和动画效果,如下载进度条和提示框等,能够更加准确地向访问者传递所想表达的内容。
2.2 网络爬虫
网络爬虫,又称为网络蜘蛛,是一种对网页信息进行自动爬取和分析的程序,可以按照一定需求对其进行编写。从实现过程来说,就是编写程序模拟浏览器发送网页访问请求,把返回的代码信息或者数据爬取至本地,进而进行解析,提取和储存,从而达到高效收集有用信息的目的。
2.2.1 网络爬虫的主要类型
网络爬虫按照爬取方式和爬取对象,可以简单的分为以下四类:通用性网络爬虫能对全网数据进行爬取,目前大型的搜索引擎使用的爬虫都是通用型网络爬虫。将互联网上的信息按一定周期进行爬取存储,供搜索者使用,但其只能提供和文本相关的内容,不能针对不同领域有不同需求的人提供不同的搜索结果。聚焦型网络爬虫则指的是针对某一方面特定需求进行专门爬取的爬虫,爬取具有目标性、针对性,因而极大地节省了硬件和网络资源,提升了爬取的效率。增量式网络爬虫则通常用于信息的维护,其按照一定规则一定周期获取网页的更新内容,而对于存储系统中已爬取过的网页不会重新爬取下载。深层网络爬虫则是用来爬取那些内容不能通过搜索引擎直接搜索到的、需要用户进行登陆或者其他操作才能获得的Web页面。
2.2.2 网络爬虫的爬取策略
爬虫的网页抓取策略主要为以下几类:
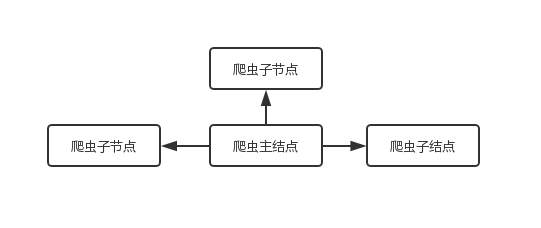
广度优先策略以爬取网站范围最大为目标,即针对图2.1所示的结构图,其搜索次序为F-C-E-A-D-H-G-B-M。当一个主网页中的所有子链接被遍历完后,爬虫才会开始开始访问子网页中的更深层链接。通过这种方法,能保证爬虫对一个域名下的所有链接进行遍历,同时广度优先算法相对来说比较容易实现,但是其缺点在于,随着抓取的网页增加,大量的与主题无关的内容也会被一起下载,而影响到爬取的效率。
最佳优先搜索策略,是指爬虫对当前待爬网页与目标爬取网页的地址相关性进行计算比对,选取最接近的几个网页进行抓取。因为算法本身存在的缺陷,可能导致许多相关的网页直接被忽略而未被抓取,但同时也大大降低了无关网页的数量。
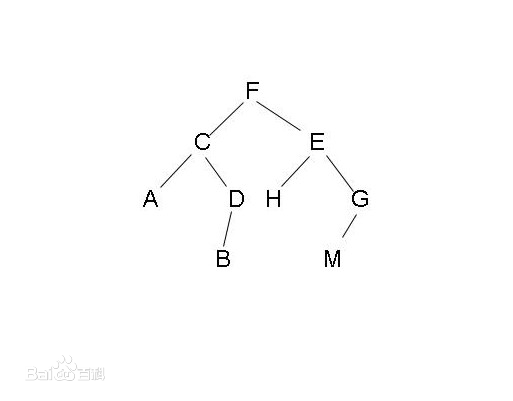 深度优先搜索策略则是以深度为最高优先级,如图2.1的结构图,其抓取顺序为:F-C-A-D-B-E-H-G-M。从起始节点选择一个子节点网页进入,再在此节点网页中选择更深层的节点。按照此方法一直向下抓取,直到最底层的页面,然后再选择下一条路线进行处理。
深度优先搜索策略则是以深度为最高优先级,如图2.1的结构图,其抓取顺序为:F-C-A-D-B-E-H-G-M。从起始节点选择一个子节点网页进入,再在此节点网页中选择更深层的节点。按照此方法一直向下抓取,直到最底层的页面,然后再选择下一条路线进行处理。
图2.1 网页结构图
2.2.3 单机网络爬虫的工作流程
网络爬虫从功能上来讲一般需要实现对数据的抓取,按照一定规则清洗数据,以及将数据进行存储这几个功能[16]。如图2.2展示了传统单机爬虫的工作流程。
根据给定初始的URL,爬虫对网页进行下载抓取,通过对网页的解析,提取相应的数据和新的URL,新的URL会放到待爬取队列中,整个过程直到爬虫爬取完所有URL才会停止。爬取的数据则可以通过不同方式进行存储,例如存储在数据库中、生成文本文档或者文件夹中。
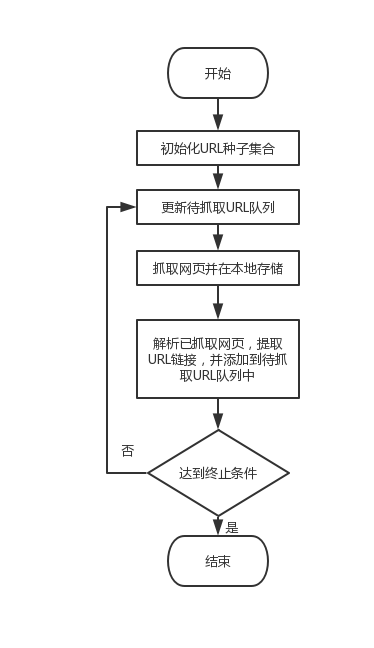
图2.2 单机爬虫工作流程图
2.3各类爬虫框架分析
目前国内外有各种开源的爬虫框架,其实现语言和侧重的方向各有不同,接下来对几种主流的技术进行介绍和分析。Nucth是在Java语言下运行的通用型网络爬虫框架,通过Nutch我们可以实现自己的搜索引擎,相较于大型搜索引擎,得出来的结果是真实的。同时,其还可以很好地对接Hadoop平台,实现分布式爬取。对于特定信息的精确抓取,Nutch框架也可以实现,但是效率会特别低。
Scrapy是一个用 Python 开发的一个高效的网页抓取框架,用于抓取指定域名范围内的所有子网页站点,并从页面中提取所需要的结构化的数据信息。Scrapy框架特点是结构简单且具有很强的可扩展性[17],每个模块都能根据不同的需求进行灵活的调整。其框架本身不支持分布式,一定程度上限制了爬取的效率。但是根据其结构特点,可以与高性能数据库对接,完成分布式爬虫的实现。
2.4 基于Scrapy框架的网络爬虫
Scrapy的整体框架结构图如图2.3所示。
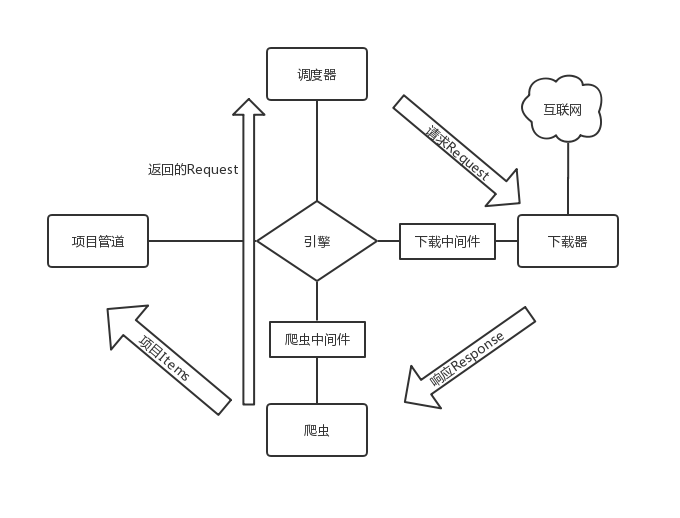 图2.3 Scrapy框架结构图
图2.3 Scrapy框架结构图
2.4.1 Scrapy框架的组成
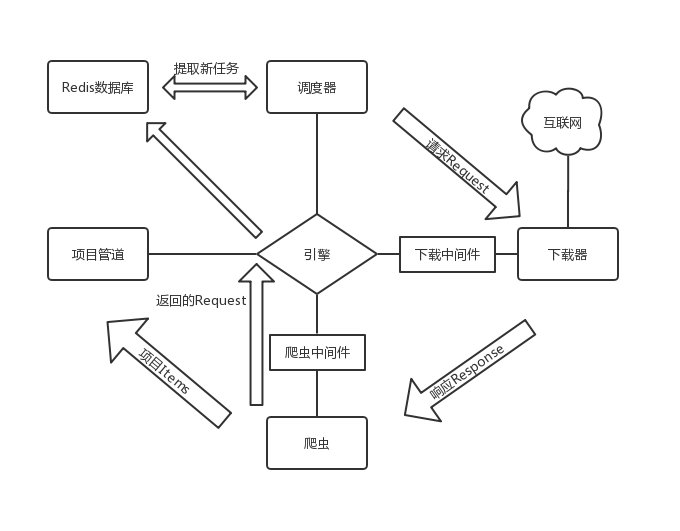
Scrapy框架主要分为以下几个部分:引擎、调度器、下载器、爬虫、项目管道、下载中间件、爬虫中间件 [18]。
中心引擎是Scrapy的核心,主要起信息中转的桥梁作用,框架中其他组件间的数据信息传递都需要经过引擎。调度器负责维护任务队列,对接收到的请求Request,即网页的URL,按照一定规则生成任务队列。下载器通过接取任务后对相应的网页进行下载。爬虫,负责解析网页源代码,提取项目所需要的信息以及新的URL链接。项目管道负责对提取到的项目数据进行存储。下载中间件和爬虫中间件都是在组件与引擎中,通过中间件可以对请求的各个参数进行自定义设定。
为了避免爬虫重复抓取网页情况的发生,Scrapy框架中有内置的dupefilter去重模块,使用set数据类型,生成的request会经过去重模块的判断后再存入queue队列。Scrapy框对响应内容进行选择,同时支持CSS选择器以及正则表达式的嵌套使用,灵活且功能强大,能快速解析目标信息。
2.4.2 Scrapy框架工作原理
整个Scrapy框架的工作以引擎为中心。首先,引擎通过初始URL打开网页,将网页内容交给爬虫进行处理,爬虫会将爬取到的第一个URL交还给引擎;然后,引擎获取URL后,将其转发给调度器进行调度,调度器经过查重等处理,生成新的Request队列;引擎从调度器中提取Request请求,通过下载中间件转发给下载器;下载器进行网页的下载操作,下载的页面信息Response经由下载中间件反馈给引擎;引擎将响应Response通过爬虫中间件分发给爬虫,爬虫按照一定方法解析页面中的目标信息以及新的URL链接,这两类信息会通过爬虫中间件返还给引擎;引擎接收到这两类信息后,将目标数据信息交给项目管道进行后续存储处理,将URL交给调度器进行新Request的生成。整个框架会一直重复上述流程,直到调度器中的Request队列为空才会停止[19]。
2.5 网络代理
许多网站都设置了一定的反爬规则,以此来拒绝爬虫的访问,保证服务器负载在正常范围内。比如,服务器会根据访问记录计算出各IP访问该网站的频率,若在一定时间内的访问次数过多,系统则判定为爬虫,进而直接拒绝服务。为了高效爬取相应网站,我们可以通过IP伪装的方式,绕过服务器系统的判定规则,避免出现访问失败的情况,这种方法就是设置代理服务器。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: