基于生成对抗网络的多源医学影像融合算法研究毕业论文
2020-02-17 23:22:39
摘 要
医学图像融合技术是当今图像融合技术的一大重要应用,其在许多生物医学研究和临床应用例如医学诊断、检测和治疗中扮演着举足轻重的角色,为医用的后续处理和决策执行提供了关键的信息,尤其是异分辨率医学图像的融合也为医学应用场景的多样性及复杂性提供了更多的支持和保障。现有的医学图像融合方法需要手动设计复杂的活动水平测量和融合规则,这受到了实施难度和计算成本的限制。此外,由于升级硬件设备和算法的难度,提高其中一张源图像的分辨率或降低另一张源图像的分辨率以融合异分辨率源图像的策略必然导致源图像部分信息的含糊或丢失,还可能产生一些冗余信息。而且,源图像的信息在融合图像的比例也难以调节。因此,对异分辨率医学图像的融合研究具有重要意义。
本文提出了一种新型的基于wasserstein生成对抗网络(WGAN)的端到端模型,用于融合异分辨率磁共振成像(MRI)医学图像和正电子发射断层扫描(PET)医学图像,该算法称为MWGAN,比基于生成对抗网络的算法更加稳定,此算法通过在生成器和两个判决器之间建立两个对抗性竞争,旨在使融合图像同时具有来自高分辨率MRI图像中器官软组织结构细节(纹理细节信息)以及来自低分辨率的PET图像中功能和代谢信息(像素强度信息)。
为实现深度学习覆盖整个融合过程,本文使用反卷积操作,通过训练自动获得参数,以融合异分辨率源图像,避免源图像信息丢失及冗余信息产生。并且本文也提出了一种新的损失函数设置策略来有效地调整融合图像中源图像中的信息。
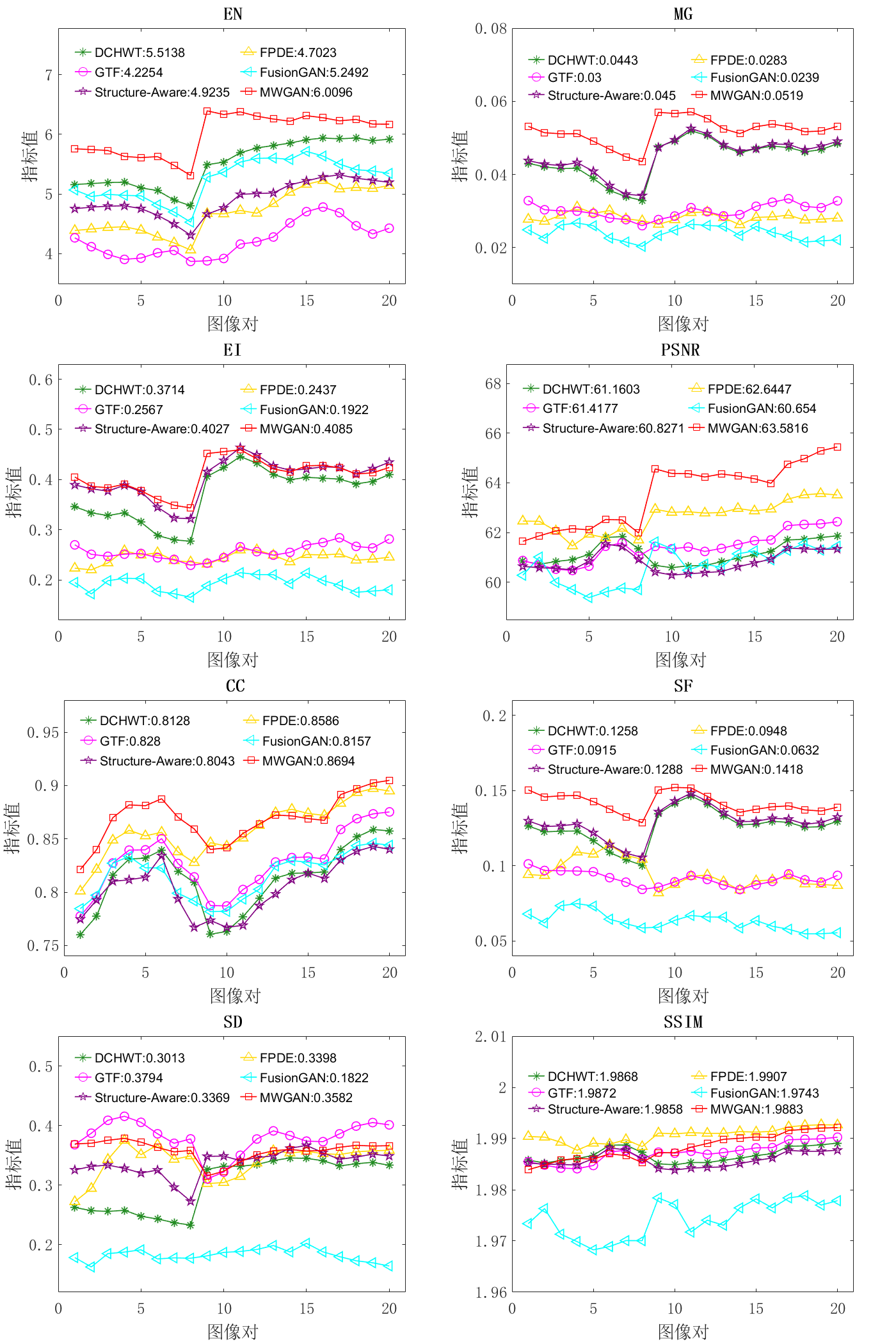
在公开数据集与其它五种算法的直观定性比较证明了本文提出的MWGAN算法优于现有融合算法;在定量8项指标比较中,EN、MG、EI、PSNR、CC和SF这6种指标分别达到了6.0096、0.0519、0.4085、63.5816、0.8694及0.1418,在这六种算法中均排第一,其余两项指标SD和SSIM也分别达到了0.3582及1.9883,在这六种算法中均排第二。此外,MWGAN也适用于异分辨率的MRI医学图像和CT医学图像的融合,与现有技术相比,它也达到了很好的融合效果。
关键字:医学图像;WGAN;端对端;异分辨率
Abstract
Medical image fusion technology is an important application of today's image fusion technology. It plays a pivotal role in many biomedical research and clinical applications such as medical diagnosis, detection and treatment, providing key information for medical subsequent processing and decision-making. In particular, the fusion of different-resolution medical images also provides more support and guarantee for the diversity and complexity of medical application scenarios. Existing medical image fusion methods require manual design of complex activity level measurement and fusion rules, which is limited by implementation difficulty and computational cost. In addition, due to the difficulty of upgrading hardware devices and algorithms, the strategy of increasing the resolution of one source image or reducing the resolution of the other source image to fuse the source images of different resolutions will inevitably lead to the loss of partial information of the source image, and possibly generate some redundant information. The ratio of source images information in the fused image is also difficult to adjust. Therefore,it is of great significance to study the fusion of medical images of different resolutions.
In this thesis, we proposed a novel end-to-end model based on wasserstein generative adversarial networks which is more stable than generative adversarial networks, termed as MWGAN, for fusing magnetic resonance imaging (MRI) medical image and positron emission tomography (PET) medical image of different resolutions. Our method establishes two adversarial games between a Generator and two Discriminators, aiming to generate a fused image with the details of soft tissue structures in organs (texture details information) from high-resolution MRI image and the functional and metabolic information (pixel intensity information) from low-resolution PET image.
This thesis also uses the deconvolution operation to automatically obtain parameters through training to fuse the source images of different resolutions to avoid information loss without redundant information generated, getting rid of the constraints of traditional methods. And the information from the source images can be effectively adjusted with a new loss function setting strategy provided.
The qualitative comparison with other five algorithms on publicly available datasets demonstrates the superiority of our MWGAN over the state-of-the-arts; Among the quantitative metrics, the six metrics of EN, MG, EI, PSNR, CC and SF reach 6.096, 0.0519, 0.4085, 63.5816, 0.8694 and 0.1418, respectively, ranking first among the six algorithms. The other two metrics SD and SSIM also reach 0.3582 and 1.9883, respectively, ranking second among the six algorithms. Furthermore, our MWGAN is applied to the fusion of MRI image and CT image from different resolutions, which also achieves an better performance compared with the state-of-the-arts.
Key words: medical image; WGAN; end-to-end; different resolutions
目 录
第1章 绪论 1
1.1 课题研究背景 1
1.2 基于深度学习的图像融合方法国内外研究现状 2
1.3 课题重要工作贡献与论文结构 3
1.4 本章小结 4
第2章 神经网络 4
2.1 神经网络简介 5
2.1.1 神经网络 5
2.1.2 卷积神经网络(CNN) 5
2.2 GAN 6
2.3 WGAN 7
2.4 本章小结 7
第3章 MWGAN算法 8
3.1 图像全局融合过程设计 8
3.2 MWGAN训练过程设计 9
3.3 损失函数设计 10
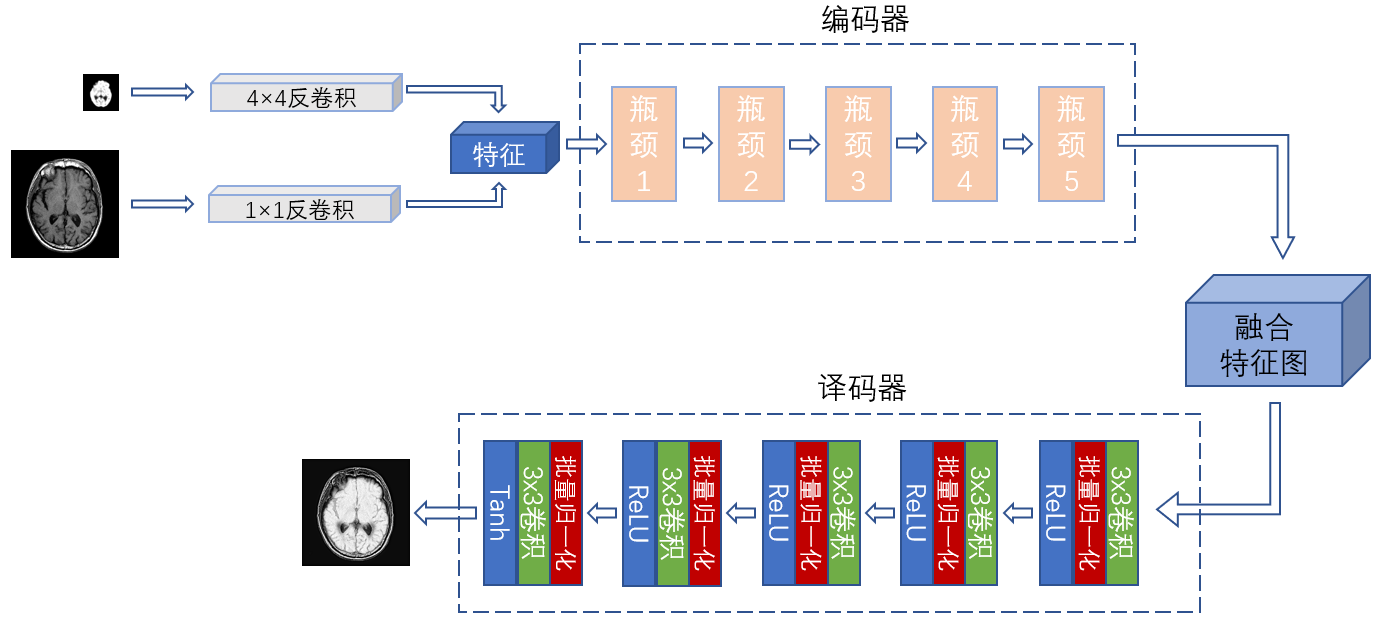
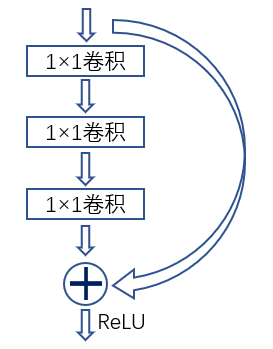
3.4 网络结构设计 11
3.4.1 生成器网络结构 12
3.4.2 判决器网络结构 13
3.5 本章小结 13
第4章 实验设计与结果分析 14
4.1 数据集的选取与处理 14
4.2 训练细节处理 14
4.3 MWGAN算法针对MRI与PET图像的融合结果 15
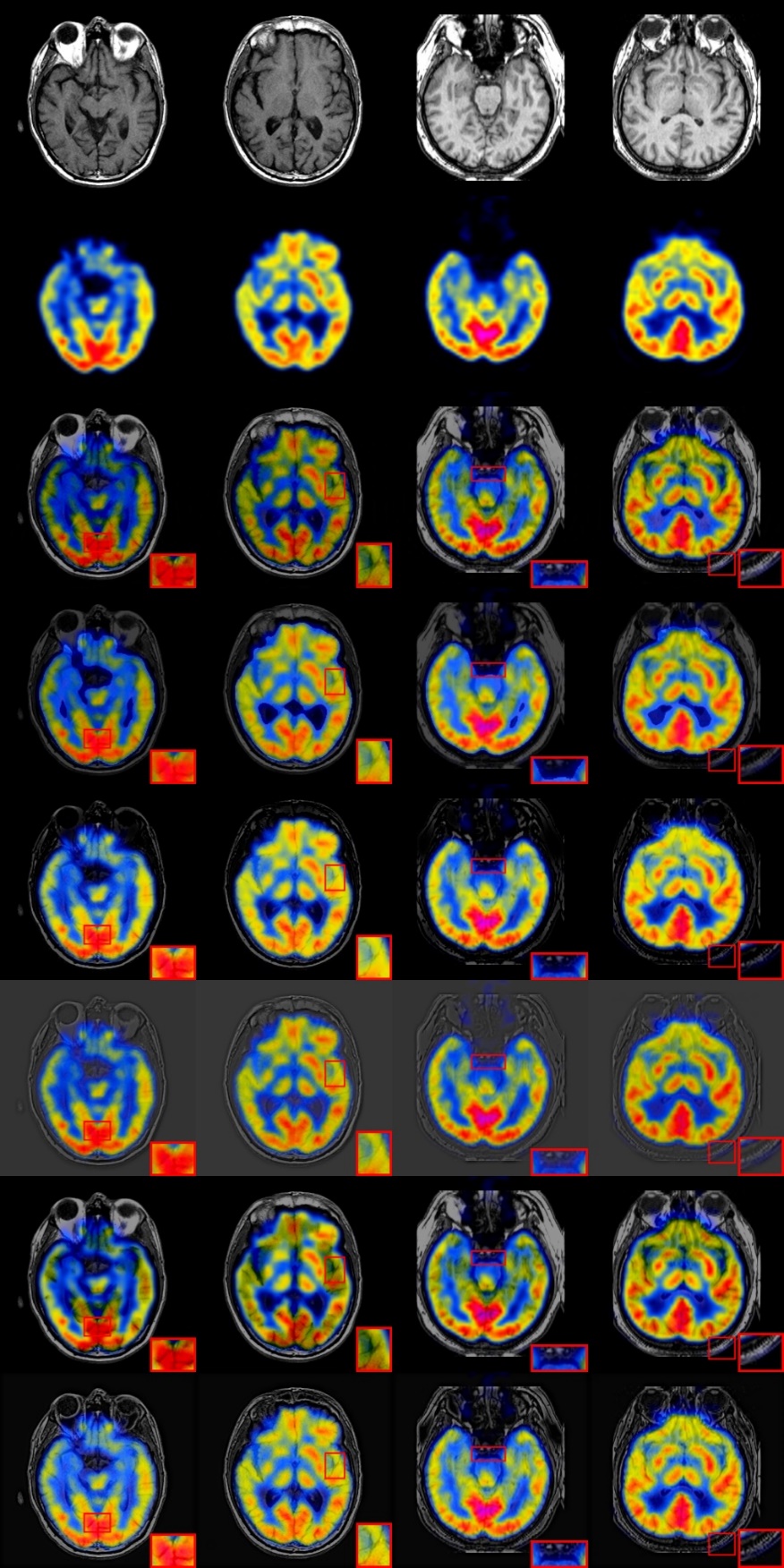
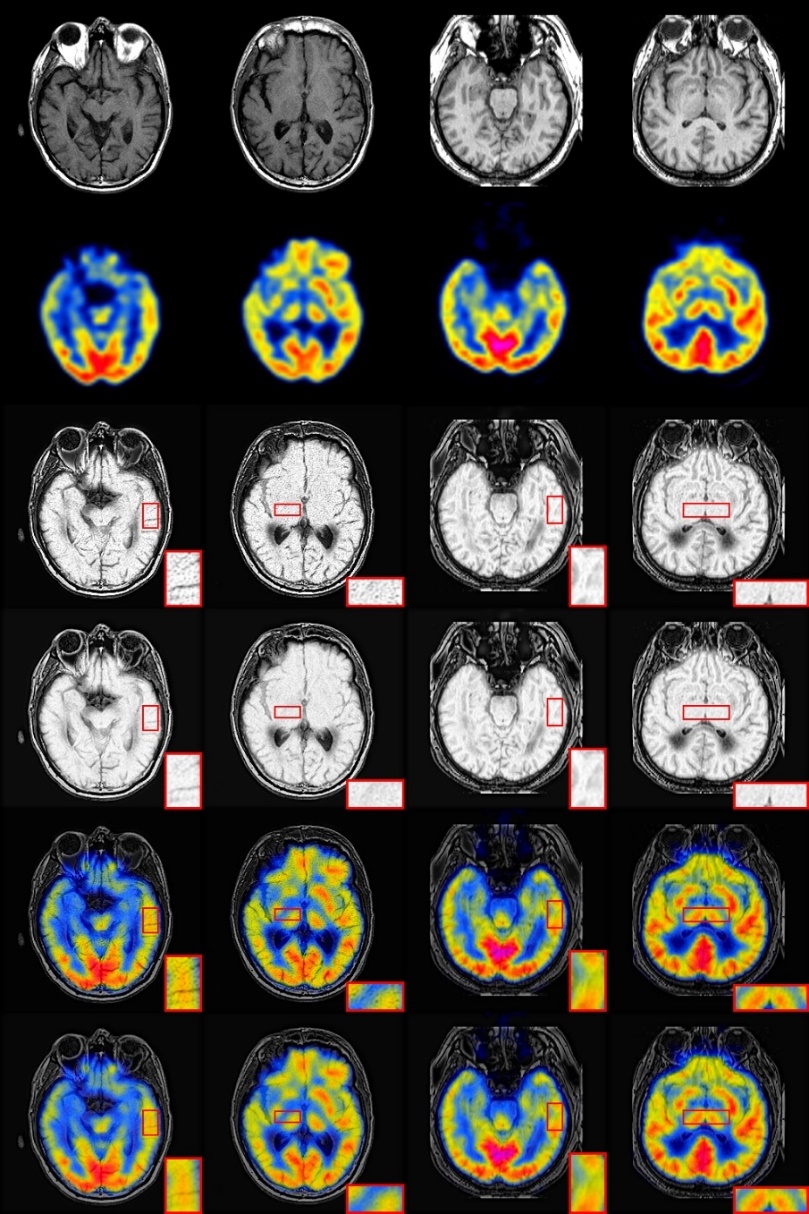
4.3.1 实验结果定性比较 16
4.3.2 实验结果定量比较 18
4.3.3 生成器参数的剪切分析 22
4.4 MWGAN算法针对MRI与CT图像的融合结果 23
4.5 本章小结 25
第5章 总结与展望 26
5.1 本文工作总结 26
5.2 展望 26
参考文献 28
致 谢 30
第1章 绪论
1.1 课题研究背景
图像融合是指使用特定算法将来自不同类型传感器的图像融合到新图像中。融合结果可以利用两个(或多个)图像在时间和空间上的相关性和信息互补性,使融合后得到的图像对场景有更全面,更清晰的描述,更有利于人类视觉感知和机器自动检测。图像融合技术通常用于红外和可见图像的融合,以在突出目标的同时在单个图像上显示各种信息[1]。受此启发,在医学成像领域,医学图像可以主要分为表征结构系统的图像和表征功能系统的图像[2]。磁共振图像(Magnetic resonance image,MRI)可以捕获器官中软组织结构的细节。正电子发射断层扫描(Positron emission tomography,PET)图像可以提供功能和代谢信息,因此融合图像将具有MRI图像的软组织细节和PET图像的功能和代谢信息。对于来自不同传感器的源图像,图像融合的关键是将源图像的最重要信息提取到新的单个图像而不生成冗余信息。在过去的几十年中,图像融合问题已经开发出不同的方案,包括基于子空间的方法,混合方法[3][4],基于多尺度变换的方法,基于显著性方法,基于稀疏表示[5][6]的方法和其他融合方法[7]。然而,这些方法需要手动设计复杂的活动水平测量和融合规则,这受到了实施难度和计算成本的限制[8]。
生成对抗网络(Generative Adversarial Networks,GAN)作为深度学习的一大革命性进展,也被应用到了图像融合领域,其通过在融合图像与源图像之间建立一种对抗性机制,不断拉近源图像与融合图像之间的距离,使融合图像具备更多源图像的信息。但是由于其自身的测量距离的不合理以及真实分布与生成分布之间的难以重合的问题,造成GAN难以稳定地训练。
由于传统融合方法的缺点,深度学习的出现为图像融合提供了新的解决方案。虽然这些基于深度学习的方法在一定程度上解决了传统融合方法的缺陷并显示出良好的融合结果,但仍存在不足之处:(1)在目前基于GAN的融合方法中,很难平衡生成器和判决器的训练程度,导致GAN训练的困难。(2)传统的基于GAN的损失函数设定策略使得来自源图像的信息比例的调整无效。(3)活动水平测量的设计和特征的处理仍然受到传统方法的干扰,因此无法实现融合过程中深度学习的全面覆盖。
此外,由于场景要求的多样性和复杂性的增加,对来自不同分辨率的图像的融合的需求不断增长。然而,受当今硬件设备和算法的限制,低分辨率PET图像具有比相应MRI图像更低的分辨率和更模糊的细节。由于升级硬件设备和算法的难度,提高PET分辨率或降低MRI分辨率的策略必然导致PET图像或MRI图像部分信息的含糊或丢失,还可能产生一些冗余信息。因此,从两个不同分辨率的源图像获得的融合图像必须具有以下特征:(1)尽可能完全地获得PET图像的强度信息和MRI图像的纹理细节信息。(2)不产生冗余信息。
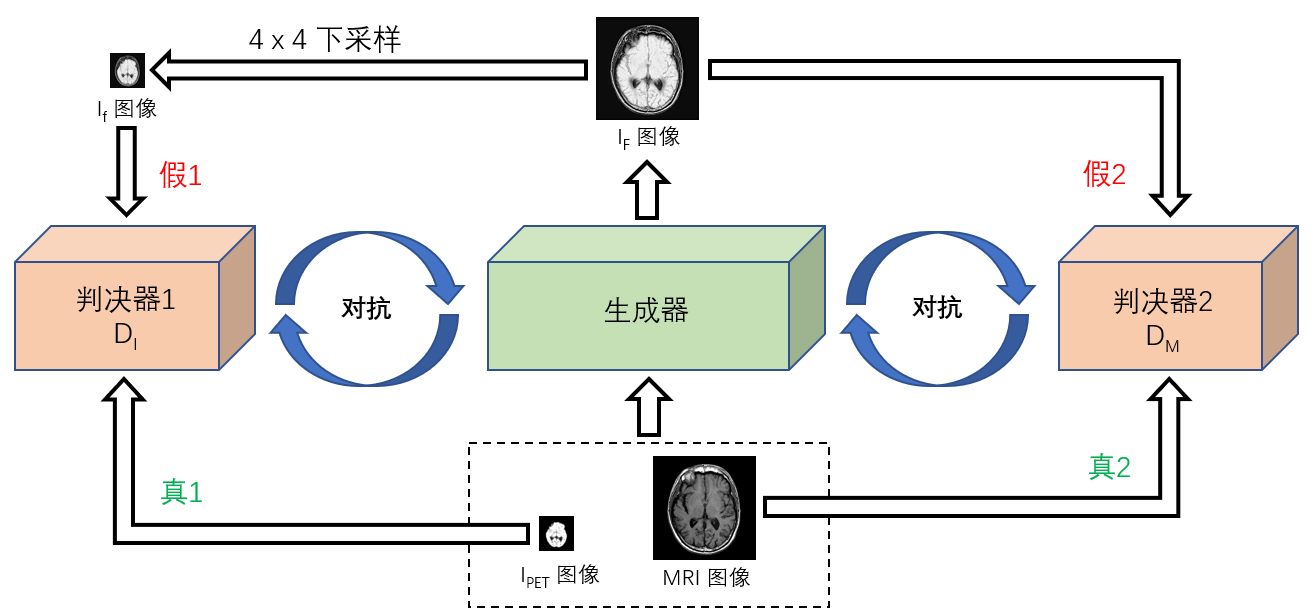
为了克服上述困难并实现融合图像要求,本文提出了基于Wasserstein生成对抗网络(WGAN)的MWGAN,用于异分辨率MRI和PET医学图像的融合。MWGAN可以看作是一种三人对抗。MWGAN中包括两种类型的模型,一种是生成器模型Generator(G),另一种是判决器模型Discriminator(D),判决器模型包含两个判决器,即判决器1(DI)和判决器2(DM)。生成模型G:不断预测训练集中实际真实数据(源图像)的概率分布,以便两个源图像生成的融合图像无法与源图像区分(生成的图像与训练集中的图像越相似越好)。判决器模型DI、DM:判断生成的融合图像是否真实,目的是将生成器G生成的“假”图像与训练集中的“真实”图像区分开。本文的MWGAN算法不仅将DI和G进行竞争对抗,还将DM和G进行竞争对抗。在训练过程中,这两个模型通过相互竞争对抗同时得到增强。由于DM和DI的存在,生成模型G可以在具有先验知识和先验分布(源图像)的前提下更好地学习以逼近实际数据,最后由生成器模型生成的数据(融合图像)不能与真实数据(源图像)区分开来。即DI和DM无法区分G生成的图像与真实图像。(DI和DM不能区分G生成的图像和真实图像,因此DI和DM分别与G达到一定的Nash均衡。)
1.2 基于深度学习的图像融合方法国内外研究现状
在本节中,简要介绍了一些基于深度学习的国内及国外现有图像融合方法。并从成像领域及基于深度模型种类等方面进行陈述探讨。
1.2.1 基于深度学习的图像融合方法国外研究现状
在数字成像领域,Prabhakar等人[9]通过提出一种无监督的深度学习框架来解决多重暴露融合的问题,其提出了一种无监督的MEF深度学习框架,利用无参考质量度量作为损失函数。所提出的方法使用训练的新型CNN架构来学习融合操作而无需ground truth实况图像。该模型融合了从每个图像中提取的一组常见低级特征,以生成无伪影感知的良好的结果。在遥感图像融合领域,Masi等人[10]提出了一种新的三层结构来解决基于CNN的pansharping问题,其采用了最新提出的一种简单有效的三层架构,用于超分辨率问题并有效地提升了融合效果,而不增加结构的复杂性。
1.2.2 基于深度学习的图像融合方法国内研究现状
自深度学习问世以来,其在特征学习和重建方面的突出表现得到了广泛的关注,并已成功应用于许多图像融合领域。在数字成像领域,Tang等人[11]提出了一种用于多焦点图像融合的方法,其从源邻域信息中识别源图像中的聚焦和散焦像素。在多模态图像融合中,Ma等人[1]将生成对抗网络应用于红外和可见图像的融合,并且因为判决器的存在,所生成的融合图像能够从可见光图像中获得更多细节。Liu等人[12]提出了一种基于卷积稀疏表示(CSR)的图像融合框架,解决了细节保留能力有限和对重合失调敏感性高的问题,其中每个源图像被分解为基础层和细节层,用于融合多聚焦图像和多模态图像。近年来,卷积神经网络(CNN)是基于深度学习的图像融合技术最依赖的模型。
上述基于深度学习的图像融合方法在实现具有良好的融合效果的同时也具有很强的借鉴意义。但是,仍存在一些不足之处:(1)现有的基于GAN的图像融合方法面临着训练不稳定的问题,容易出现梯度消失/爆炸。(2)在基于GAN的图像融合方法中,源图像的信息在融合图像的比重受限制,并且难以调节。(3)传统融合方法的局限性仍然存在。例如,融合规则仍然需要手动设计[13],深度学习不能被应用于整个融合过程中。
本文的MWGAN有效地解决了上述问题。本文引入WGAN来解决GAN训练过程中的不稳定问题。在此基础上,本文提供了一种新的损失函数设置策略,以便更好地去调整源图像信息在融合图像中的权重比。此外,本文提出的方法不需要手动设计融合规则,整个过程不受传统方法的限制。
1.3 课题主要工作内容与论文结构
本文研究的是基于生成对抗网络的多源医学影像融合算法,先从国内外基于深度学习的图像融合算法现状分析其中的不足,再由此提出解决这些不足的新算法,通过实验得出此算法与其他算法的对比表现,并由此扩展到MRI与CT图像的融合[14][15],最后进行总结。
本文的主要工作内容体现在以下三个方面:首先,针对医学图像的融合提出一种基于WGAN[16]的更加稳定的融合算法MWGAN,并提供一种新的损失函数设定策略。第二,实现MWGAN端到端的模型设计,并在整个融合过程中实现深度学习的全覆盖,通过与现有先进融合方法的定性和定量比较,得出本文提出的MWGAN与其他算法相比针对异分辨率MRI和PET医学图像融合表现。最后,通过实验验证本文的MWGAN在MRI和CT医学图像的融合表现。
由此,本文分为五部分来阐述,具体安排如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: