基于Hadoop的工业大数据分布式存储系统的设计与实现开题报告
2020-02-18 18:26:17
1. 研究目的与意义(文献综述)
1.1研究目的意义
| 大数据时代的出现,是信息化高度发展的必然结果。因为世界信息技术的不断飞速发展,电子信息化设备在人类生活中广泛应用,使得信息数据的产生、获取、传输都达到了前所未有的新高度,同时存储技术的快速发展为海量数据的存储提供了技术保障,使得对于大数据的分析应用成为了可能。我们目前已经进入了数据技术时代,现如今数据驱动创新的局面已经逐渐在全世界范围内显现出来。世界各大互联网巨头公司也都加入其中,诸如国外的谷歌、苹果、微软、雅虎等,国内的阿里、百度、腾讯、华为、网易等。他们纷纷加入到大数据研究行列中,亦都是察觉到了大数据的发展前景。如此多巨头公司的一致认可也从更加证实了,大数据在行业来来发展中所要扮演的重要角色。 目前,大数据技术已经在医疗、制造、交通、金融、互联网等行业中广泛应用,并且取得了卓越的成就。在工业领域随着信息化建设和工业物联网技术的不断深入发展,以及近些年电子信息科技的不断发展,所带来的电子采集设备的多元化及廉价化,使得工业物联网得到了快速的发展。同时国家对工业科技信息化建设不断投入,以及对智慧工业、精细化工业、工业物联网科技等项目的大力开展,使得我国目前的工业科技水平实现了快速的发展。工业领域已经成为大数据应用的又一个重点领城。工业物联网中的数据已经显现出了大数据的5V特点,海量数据(Volume),处理速度快(Velocity),数据类型多样性(Variety),价值大 (Value),精确性高(Veracity)。相信大数据技术应用于工业领域之后,一定可以给工业的发展带来新的活力和机遇[10]。 但是,由于工业领域本身就属于一个多学科交叉应用的领城,众多学科、行业的技术都在工业领域有相应的应用,并且工业具有地域性分布明显,受季节、位置影响明显等特征。因此它所产生的数据具有明显的异构性,很难用现有的常规方法来处理分析其数据集。在整个工业的生产、加工、销售流通、质量溯源、工业管理等等过程中会产生多种多样的数据类型,包括文本、图像、视频、声音、文档、GIS坐标信息等,这些数据由结构化、半结构化及非结构化组成。面对如此庞大且种类繁多的工业数据,首先第一步需要解决的是对数据的采集,其次是对数据的存储,最后才是对数据的分析挖据。 1.2国内外研究现状 在国外,很多国家目前已经建立起了自己国家的工业大数据中心,大数据中心存储有全国的工业数据,在数据中心通过大数据技术对这些数据库中的数据进行挖掘处理分析,这些分析结果能够很好为本国工业生产提供指导和帮助。例如美国通用电气,传感器已经被嵌入到通用电气公司制造的250,000台“智能机"上,包括喷气发动机、动力涡轮机、医疗器械设备等等。这些传感器收集和分析的数据在优化产业经营方面拥有巨大的潜力:“在未来的15年间,工业互联网有望为全球经济带来15万亿美元的提高”。通过工业系统中的海量数据对工业系统的运行和管理进行建模和优化,让整个工业系统优化运行,使产量尽可能高,质量尽可能好,成本尽可能低,消耗尽可能低,环境污染尽可能小。工业大数据应用技术可将这一愿景变为现实。2013年6月,通用电气宣布联手亚马进等公司打造“工业云”产品,利用亚马逊的云技术,准备将全球在运营的并已经联入网络的机器和设备,以“大数据”的概念和方式来处理原始数据。并在同一年,通用电气在其白皮书中介绍了其工业大数据分析处理平台[8]。 |
2. 研究的基本内容与方案
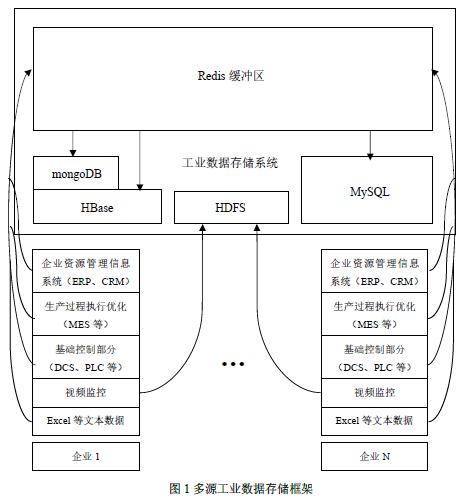
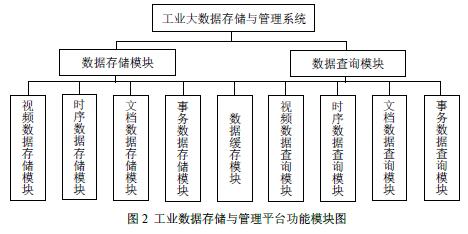
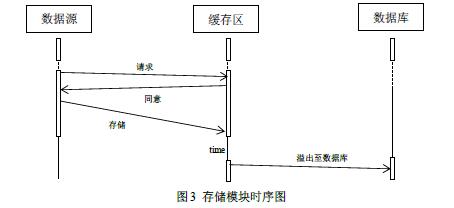
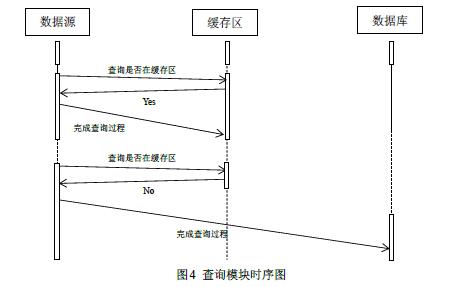
| 2.1研究内容 对工业海量数据分析其复杂的行为特征,是解决传统方法难以解决复杂问题的新方法。本文设计并实现面向工业大数据分布式存储系统,通过搭建Linux集群和部署安装Hadoop相关组件实现一个面向工业大数据的分布式存储和管理系统。 主要的研究内容有: 1.对工业大数据研究的现状分析,对工业大数据分析的支持技术进行研究; 2.研究工业大数据的特点和研究难点,设计实现不同种类工业大数据存储系统框架并搭建数据存储与管理的平台; 3.基于Hadoop分布式数据存储原理,根据数据存储与管理平台,完成对工业大数据的存储与管理系统的设计与实现。 2.2研究目标 工业企业的数据有多种来源,且分布于多个独立的系统,各数据源的数据彼此孤立。对于企业基于数据的决策分析来说,难以利用企业拥有的全部数据资源实现企业的生产优化、经营管理优化等;对于整个行业的决策分析来说,也难以利用全面的数据资源来实现行业发展指导。因此,本次研究的目标是构建一个支持多源的、多层次的数据存储和管理的平台。 2.3技术路线 对于面向工业大数据的分布式存储和管理系统,主要从以下几个方面来实现: 1.分析工业大数据的数据结构,其由结构化、非结构化和半结构化的数据并存组成。结构化数据指的是具有固定的结构、规范的数据,通常被称为关系型数据。非结构化数据与结构化数据相比,不方便使用关系型数据的二维关系描述,一般在数据格式方面没有明确的规范,比如文本文档、图片、Excel表格或者视频等。而半结构化数据则是介于结构化数据和非结构化数据之间的,不能以结构化数据的二维关系描述,却又能附带一些描述性数据,形式和结构都比较灵活。 2.设计如下图1所示的多源工业数据存储框架。
|
3. 研究计划与安排
| 第1周—第3周 搜集资料,撰写开题报告; 第4周—第5周 论文开题; 第6周—第12周 撰写论文初稿; 第12周—第15周 修改论文; 第16周 论文答辩。 |
4. 参考文献(12篇以上)
| [1]万轶,向广利.基于Hadoop和HBase的分布式索引集群研究[J],信息技术与信息化,2015(01):102-103 [2]AlexanderThomasian,Yujie Tang. Performance, reliability, and performability of ahybrid RAID array and a comparison with traditional RAID1 arrays[J]. ClusterComputing,2012,15(3). [3]Blomer J. ASurvey on Distributed File System Technology[J]. Journal of Physics: Conference Series,2015,608(1). [4]Kaur R,Chadha R. Comparative analysis of various file formats in HIVE[J]. Int. J.Technol. Comput, 2017, 3(6): 135-139. [5]景晗,郑建生,陈鲤文,许朝威.基于Map Reduce和HBase的海量网络数据处理[J].科学技术与工程,2015,15(34):182-191. [6]陈兴振.基于Hadoop的数据作业管理平台设计与实现[D].中国科学院大学,2015. [7]邹立民.基于Hadoop的分布式数据存储系统应用的研究[D].沈阳工业大学,2018. [8]王淑芬.基于大数据的制造运行监测与分析平台研究[D].广东工业大学,2014. [9]谢青松.面向工业大数据的数据采集系统[D].华中科技大学,2016. [10]张强.面向大数据的农业物联网数据采集与存储研究[D].北方民族大学,2017. [11]王建军.基于Hadoop的钻井工程实时数据分析研究[D].西安石油大学,2016. [12]王建军,王震,战非,赵侃.基于Hadoop的高校社团信息资源存储研究[J].产业创新研究. [13]陈中,范开勇,饶宏博.基于Hadoop分布式交通大数据存储分析平台设计与实现[J].数据库与信息管理,2018. [14]张国栋.基于Hadoop技术的电信大数据分析平台的设计与实现[D].上海交通大学,2014. [15]张华.基于Hadoop的电信大数据平台应用探究[J].长春大学学报,2018. [16]欧建林.基于Hadoop的商业银行大数据平台研究与实现[J].中国金融电脑,2019. |



