基于深度学习的情感分类研究毕业论文
2020-04-09 15:21:08
摘 要
随着移动互联网的快速发展,网购已经成为了现代人日常生活中不可缺少的一部分。网购平台上存在着大量的用户评论信息。挖掘这些评论的情感倾向,不仅可以为消费者提供有用的参考,同时也能为商家提供各种信息,方便商家做出相应的调整和决策。然而面对海量的文本评论信息,仅靠人工判断是非常的费时费力的,如何利用人工智能领域的相关技术对文本倾向进行自动化的判断成为一个非常重要且非常有意义的研究课题。
现有的文本情感分类方法主要有三种:基于规则的方法、基于机器学习的方法以及基于深度神经网络的方法。随着语言形式的多元化,深度神经网络技术逐渐成为人工智能在自然语言处理方向的主流方法,同时该方法在情感分析领域也取得了很大的突破,本文的研究重点主要为基于深度神经网络的情感分析方法。
主要工作如下:
对已有的评论文本,通过使用Python语言进行数据的预处理工作,包括文本分词,词频统计,词语引索的建立以及文本的数字化表示等。同时为了解决表示词语时向量维度过高和语义间不相关的问题,实验中采用了word embedding机制,使用该方法之后的每一个词向量都会在模型训练时不断调整和优化。
在实验阶段本文选取了多种算法和模型在性能上进行对比,其中包括支持向量机和朴素贝叶斯分类器两种常见的机器学习算法,以及全连接神经网络,长短时记忆网络和注意力机制等深度学习方法。在对比的过程中本文不断的变化输入句子的长度,为句子引入了噪声信息,通过在不同的情况下的模型表现,最终总结出针对不同情形下的网络选择方案。
为了将训练的模型用于实际服务,实验中,在Flask框架下嵌入了训练好的模型,并制作出了简单的网页以供使用。
本文的主要创新在于:
(1)刻意为文本句子加入了噪声信息,以此提高文本的信息冗余度,从而增加网络的判别难度,并研究了各网络在此情况下的表现性能。
(2)对已有注意力机制网络进行了改进,提出了运用全时刻信息的注意力判别模型,希望以此提升模型在长文本时的判别精度。
关键词:Python;机器学习;深度学习;Flask框架
Abstract
With the rapid development of the mobile Internet, online shopping has become an indispensable part of the daily life of modern people. There are a large number of user reviews on the online shopping platform. Exploring the emotional tendencies of these comments can not only provide consumers with useful references, but also provide businesses with a variety of information to facilitate merchants to make corresponding adjustments and decisions. However, in the face of massive textual commentary information, manual judgment alone is very time-consuming and laborious. How to use the related technology in the field of artificial intelligence to automatically judge text tendencies becomes a very important and significant research topic.
There are mainly three existing text sentiment classification methods: rule-based methods, machine learning-based methods, and methods based on deep neural networks. With the diversification of language forms, deep neural network technology has gradually become the main method of artificial intelligence in the direction of natural language processing. At the same time, this method has also made great breakthroughs in the field of sentiment analysis. The research focus of this paper is mainly based on deep neural networks.
The main work of this article is as follows:
- For prescriptive texts with some comments, the use of Python language for preprocessing data, including text segmentation, word frequency statistics, the establishment of words and the digital representation of the text. At the same time, in order to solve the problem that the word dimension is too high and the semantics are not related, we adopt the word embedding mechanism. After using this method, each word vector will be adjusted and optimized continuously during the training of the model.
- At the experimental stage, we compared the performance of several algorithms and models, including two common machine learning algorithms, support vector machine and naive Bayes classifier, and fully connected neural networks, long and short-term memory. Deep learning methods such as networking and attention mechanisms. In the process of comparison, we continuously change the length of the input sentence, introduce noise information for some sentences, and finally summarize the network selection scheme for different situations through model performance in different situations.
- In order to use the trained model for the actual service, we embedded the trained model in the Flask framework and created a simple web page for use.
The main innovation of this article is:
(1) Noise information was deliberately added to the text sentence to improve the information redundancy of the text, thereby increasing the difficulty of discriminating, and studying the performance of each network in this case.
(2) Improvements have been made to the existing attention-mechanism network, and an attention-discriminating model using full-time information has been proposed in the hope of improving the accuracy of the model in determining long texts.
Keywords:Python; Machine Learning; Deep Learning; Flask Framework
目 录
1 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.2.1 基于规则的文本情感分类方法 1
1.2.2 基于机器学习的文本情感分类方法 2
1.2.3 基于深度神经网络的文本情感分类方法 3
1.3 研究内容介绍 3
2 数据集选择与数据预处理 5
2.1 数据集选择 5
2.2 数据预处理 6
2.2.1 文本分词 6
2.2.2 建立词典 7
2.2.3 词汇转化 7
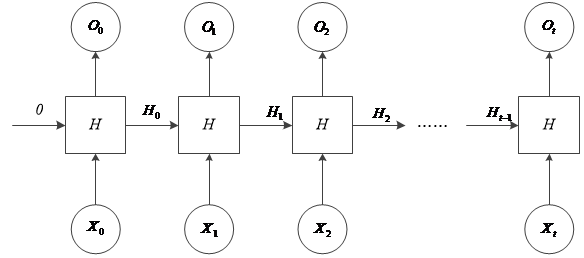
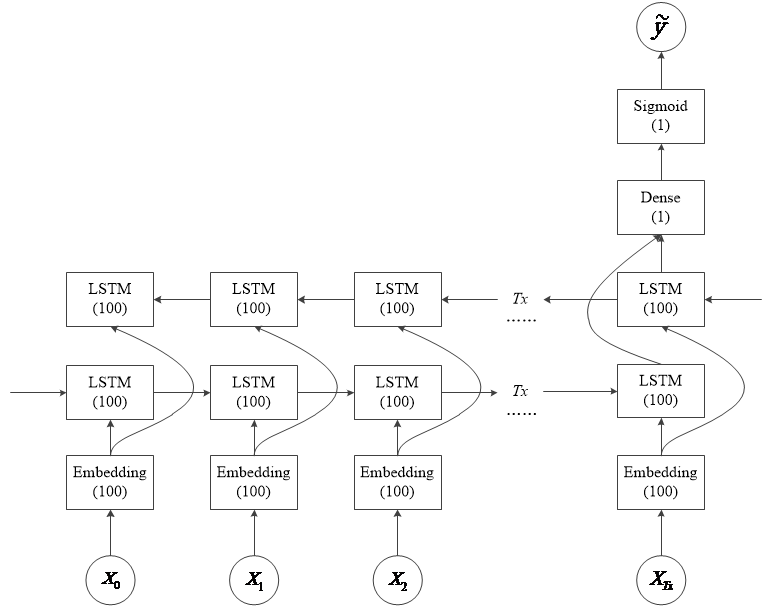
3 基于LSTM的情感分类研究 9
3.1 词嵌入层的介绍及使用 9
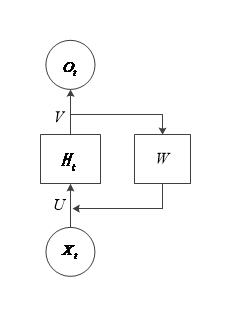
3.2 循环神经网络原理 10
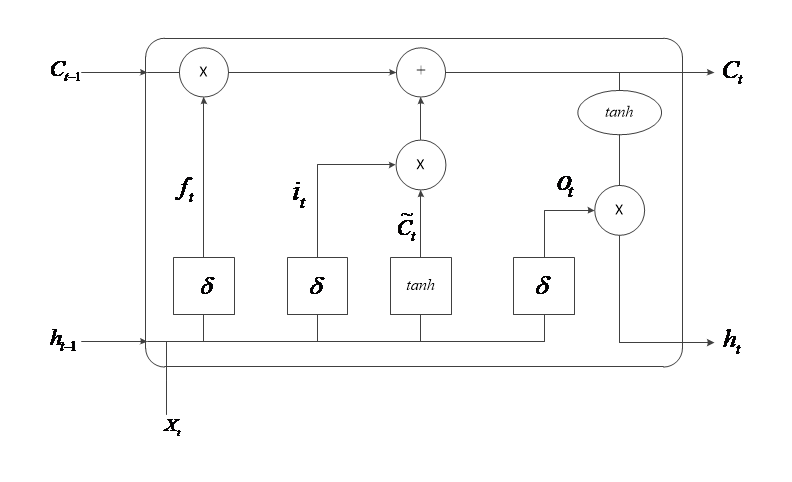
3.3 长短时记忆网络原理 11
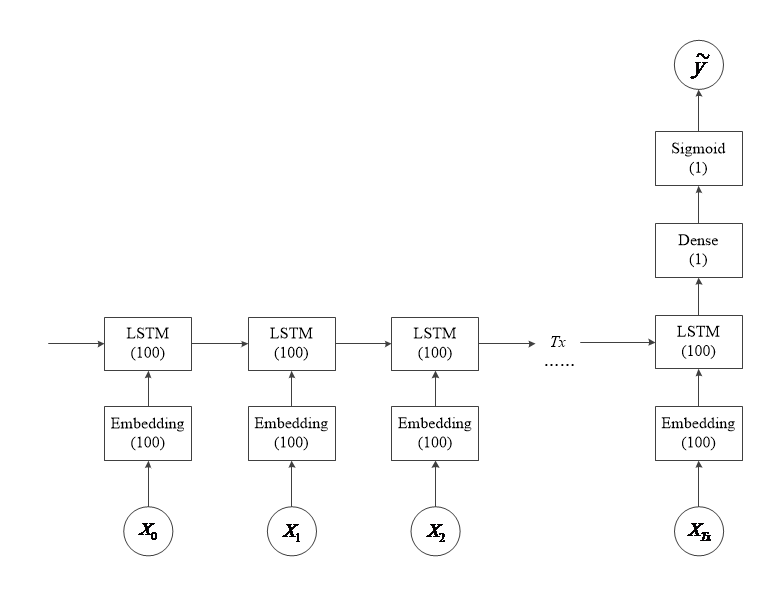
3.4 实验网络结构 13
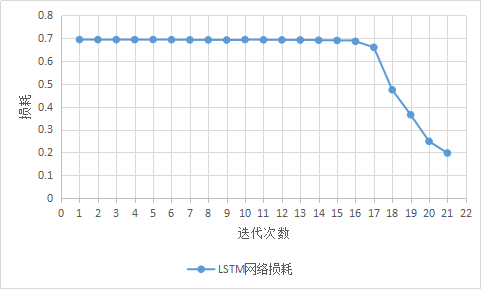
3.5 实验结果及结果分析 16
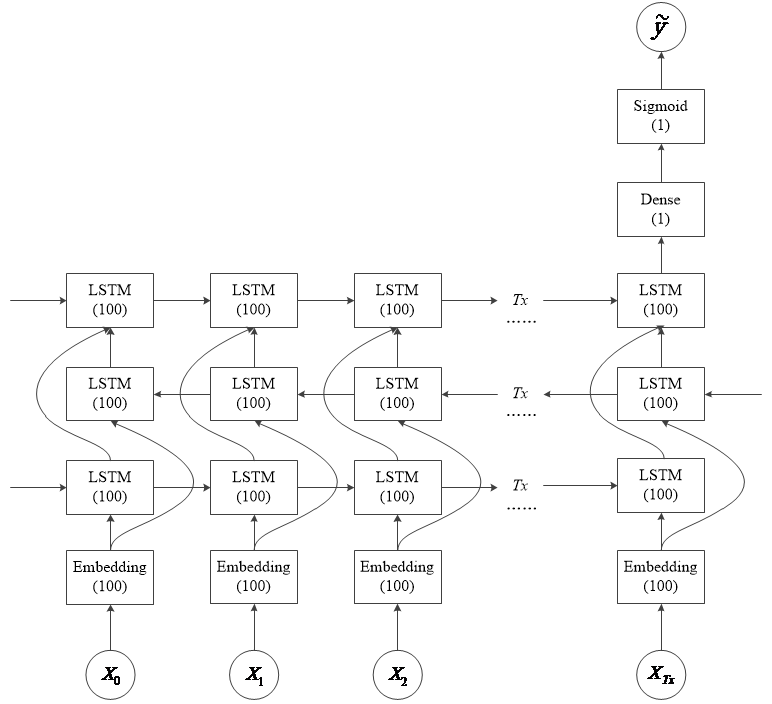
4 基于注意力模型的情感分类研究 21
4.1 在双向LSTM中引入注意力机制 21
4.2 Attention模块内部结构 23
4.3 实验结果与结果分析 24
4.4 运用全时刻信息的注意力判别模型 25
4.6 各模型总结 28
5 系统的设计 30
5.1 Flask框架简介 30
5.2 采用Flask框架制作情感分析网页 30
6 总结与展望 32
参考文献 33
致 谢 35
1 绪论
1.1 研究背景及意义
随着信息技术的不断进步以及移动互联网的广泛普及,互联网已经成为现代人生活中不可缺失的一部分。同时,互联网也给人们的生活方式带来了巨大的改变。如出去旅游时,人们会在美团软件上提前预定好酒店;想买一些商品时,人们最先想到的是上淘宝、京东等电商平台进行筛选。现如今,消费的方式已经逐渐的从传统的线下实体消费转变为线上购物。截止到2016年12月,我国网民的数量达到了7.31亿人,其中,网购的用户规模已经达到了4.67亿,占总网民数的63.8%之多,相比2015年底增长了12.9%[1]。
人们在网上消费的同时,喜欢对购买的商品进行评论,由于日益普遍的网购行为,导致电商网站中充斥着大量的褒贬不一的评论。在网购的过程中人们看不到实际的商品,无法对实物的质量做出直接的判断,比起商家在网页和软件上的主观描述,消费者更愿意通过查看买家的评论来获取商品的详细信息,同时卖家也可以通过评论来了解人们对某款商品的看法,从而得知该商品存在的问题,重新制定合理的营销政策。但是,面对网络上海量的文本评论数据,通过人工的方法标注评论的情感倾向是一件成本非常高的事情,因此,如何利用自然语言处理领域的相关技术对评论文本的情感倾向进行自动地挖掘与分析是当今热门且非常有实用价值的研究课题。
当今主流的文本情感分类方法主要有三种:基于规则的方法、基于机器学习的方法和基于深度学习的方法[2]。伴随着大数据技术的不断发展,以及语言表达日益自由化和多元化,深度神经网络技术的优势逐渐凸显,成为了自然语言处理方向的主流技术,相比于其他的两种方法,深度神经网络技术由于其模型和函数的复杂性,可以区分更为复杂的非线性数据分布,在面对复杂多变的语言现象时,可以捕捉到更为深层的文本特征,对文本能有更好的理解,从而能在文本情感分类上达到更好的效果,故本文的主要研究方向为基于深度神经网络的情感分类。
1.2 国内外研究现状
1.2.1 基于规则的文本情感分类方法
通常在使用基于规则的文本情感分类方法时,需要构建情感词典或情感搭配模板,之后再通过文本中所包含的词典中的情感词或者固定搭配来计算此文本的情感倾向。
在国外,Turney[3]就通过使用点互信息(Pointwise Mutual Information,PMI)方法扩展了基础的褒贬词汇表,并在此基础上挖掘出表达文本倾向性的词,最后使用极性语义算法(ISA)对文本情感进行判别。
在对文本情感进行分类时,Kim[4]对情感词典中的词进行了打分,以此来表明每个词的情感强度,最后把文本中包含的情感词的分数相加得出最终的文本情感倾向,这种方法在实验中取得了不错的效果。
在国内,Tsou和Yuen[5]利用情感词典分析完文本的情感倾向性之后,会进一步的去分析情感词在该文本中的密度、广度以及情感词本身的强度对情感极性的影响,接着综合这些指标来计算文本情感倾向的程度。徐琳宏和林鸿飞[6]从句子的角度出发,首先分析句子中的词汇以及语句结构,再利用情感词典捕捉九个可以体现出情感倾向性的特征,并融合文本本体识别后的情感特征,进一步的去判断文本的情感极性。在另一方面,Hu和Liu[7]认为判断文本倾向性的关键在于对文本中形容词的提取和分析,他们提取出文本中的形容词作为情感倾向性的判别依据,之后计算文本中的词与提取出的形容词之间的相似程度来判断文本倾向。
基于规则的文本情感分类方法的主要有优点在于其灵活性,可以人为的去加入多种词典和搭配规则,但是随着语言现象的日益增多,这种方法所适用的范围也不断的变窄,很难去建立一个比较完备的情感词典和关系的搭配规则,这也是其瓶颈所在。
1.2.2 基于机器学习的文本情感分类方法
基于机器学习的文本情感分类方法主要将有标签的训练语料进行特征提取和句子建模,然后使用机器学习的常见方法自动化地实现情感倾向性判断。机器学习方法主要有支持向量机(Support Vector Machine)、朴素贝叶斯分类器(Naive Bayesian)和决策树(Decision Tree)等。
在国外,Pang[8]分别使用支持向量机、朴素贝叶斯分类器和最大熵这三种机器学习方法对电影影评进行了情感倾向性的判断,并将实验的结果与手工分类结果做比较,最后发现支持向量机表现出最好的效果。Moens[9]则在多种语言的文本上使用机器学习的方法做情感分类,结果显示出三种语言的分类准确率分别为68%、70%、83%。由此可见在外文的情感分类中机器学习方法取得了一定的效果。
在国内,对于中文的情感分类,唐慧丰[10]通过抽取文本中的名词、副词、形容词、动词等词汇作为特征,通过文档频率、信息增益、互信息和CHI统计量作为特征选择的方法,分别选择了K最近邻和支持向量机、贝叶斯分类器、中心向量法三种不同的机器学习方法做对比,获得了最优的特征选择方法和机器学习方法的组合。万源[11]提出了一种基于模式匹配的情感判别方法,他通过对大量的评论文本分析总结出了10种常见的模型,通过这些模型对特征进行了规范和改进,在实验中获得了81.8%的判别精度。
机器学习算法虽然可以自动的判断文本的情感倾向性,但是算法判别的好坏依赖于输入特征的选择,而人工选择存在着很大的不确定性,且不能选择出文本较深层的特征,整个模型的判别能力和泛化能力都有很大的局限性。
1.2.3 基于深度神经网络的文本情感分类方法
深度神经网络采用多层非线性的网络结构对输入的数据进行建模,其具有的层级结构能够学习到文本中深层语义特征,从而可以弥补机器学习的局限性。
深度学习在文本情感分类领域的应用主要分为两个部分。
第一个部分是构建神经网络语言模型,1986年,Hinton[12]提出了词的分布式表示(distributed representation)方法,它的主要思想是将词映射成一个向量表示,通过计算词向量之间的余弦相似度或者欧氏距离来判断他们之间的语义相似度。2003年,Bengio[13]将基于分布式表示的词向量通过神经网络训练出来,并给出了相应的公式。2013年,Mikolov[14]公布了word2vec词向量转化工具包,该工具包中包含了几种新的模型和方法用来构造词嵌入向量。神经网络语言模型将文本映射成为一个低维的向量,该向量中包含了词语的语义信息,通过使用这种方法解决了传统的文本表示方法中词向量高维、稀疏且不带语义信息的缺点。
第二个部分是通过神经网络模型来挖掘文本深层次的特征,从而使得模型对文本有更好的理解。Kim[15]使用卷积神经网络(Convolutional Neural Network)对词向量表示的文本进行情感分类,在多个数据集上都表现出不错的结果。Socher[16]引用了递归神经网络(Recurrent Neural Network)对影评进行了情感分析,使用该模型后较传统方法取得了明显的成效。在国内,梁军、柴玉梅等人[17]在进行文本情感分类时,引入了长短时记忆网络(Long Short-Term Memory),该网络能保存文本的历史信息,最终该模型在斯坦福大学提供的影评数据集上达到了88.1%的分类正确率。
1.3 研究内容介绍
本文主要对基于深度神经网络的情感分类方法进行了研究和改进,全文总共分为六章,每一章的内容简述如下:
第一章为绪论部分,主要介绍文本情感分类的研究背景和意义、国内外的研究现状以及本文的主要研究内容。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: