基于深度学习的行人检测算法研究毕业论文
2020-02-17 21:06:58
摘 要
在目标检测的领域中,行人检测有着举足轻重的地位,随着人工智能技术的迅速发展,行人检测不再局限于传统机器学习方法,取而代之的是深度学习的算法。
本文旨在研究一种在大多数情况下都能有效检测出行人的算法。全篇围绕深度学习的算法展开对行人检测方法的描述,从行人检测的基础理论出发,介绍了提取行人特征的方法和特征表示函数,列举了已有的行人检测算法并且对它们进行了优劣性对比,选择用Faster R-CNN算法完成本次设计。文章详细说明了此次设计的全过程,包括图片压缩,CNN网络对图片特征图的提取,RPN网络的分类和回归,RoI池化层中提议特征的计算和分类器的工作原理。最终通过代码的方式完成算法,证明了Faster R-CNN算法的可行性。
实验表明,基于Faster R-CNN的行人检测算法可以有效地检测出图片中的行人,在明暗程度不同的照片中都有比较好的表现,对于有遮挡情况的图片,对于遮挡程度的不同,有不同情况的表现,但总体表现良好。
关键字:深度学习;Faster R-CNN;行人检测
Abstract
In the field of target detection, pedestrian detection plays an important role. With the rapid development of artificial intelligence technology, pedestrian detection is no longer limited to traditional machine learning methods, but is instead a deep learning algorithm.
This paper aims to study an algorithm that can effectively detect pedestrians in most cases. The whole part focuses on the deep learning algorithm to describe the pedestrian detection method. Starting from the basic theory of pedestrian detection, the method of extracting pedestrian characteristics and the feature representation function are introduced. The existing pedestrian detection algorithms are listed and their advantages and disadvantages are given. Sexual comparison, choose to use the Faster R-CNN algorithm to complete this design. The article details the whole process of the design, including image compression, CNN network extraction of image feature map, classification and regression of RPN network, calculation of proposed features in RoI pooling layer and working principle of classifier. Finally, the algorithm is completed by code, which proves the feasibility of the Faster R-CNN algorithm.
Experiments show that the pedestrian detection algorithm based on Faster R-CNN can effectively detect pedestrians in the picture, and has better performance in photos with different brightness and darkness. For pictures with occlusion, the degree of occlusion is different. Performance in different situations, but overall performance is good.
Keywords: deep learning; Faster R-CNN; pedestrian detection
目录
第1章 绪论 1
1.1课题研究的目的 1
1.2国内外研究现状 2
1.3本文的主要研究内容 2
1.4本文的组织结构 3
第2章 行人检测相关技术简介 4
2.1行人检测原理 4
2.2窗口选择 5
2.2.1基于滑动窗口的预选框选择 5
2.2.2基于选择性搜索框的预选框选择 6
2.3行人的特征表示 7
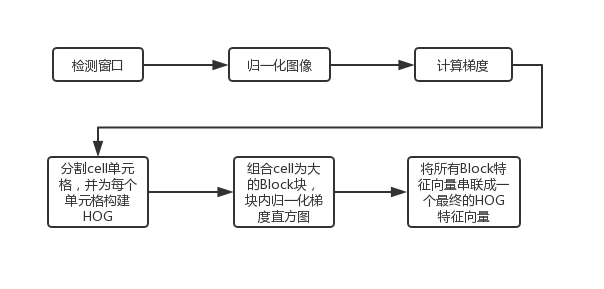
2.3.1HOG特征 7
2.3.2LBP特征 9
2.4数据集与评价标准 10
2.4.1行人检测数据库 10
2.4.2行人检测评价标准 10
2.5本章小结 11
第3章 基于深度学习的行人检测算法系统设计 12
3.1深度学习的基本思想 12
3.2典型的行人检测算法 13
3.2.1基于R-CNN的算法 13
3.2.2基于Fast R-CNN的算法 13
3.2.3基于Faster R-CNN的算法 13
3.3基于Faster R-CNN的行人检测网络设计 14
3.3.1算法的总体设计 14
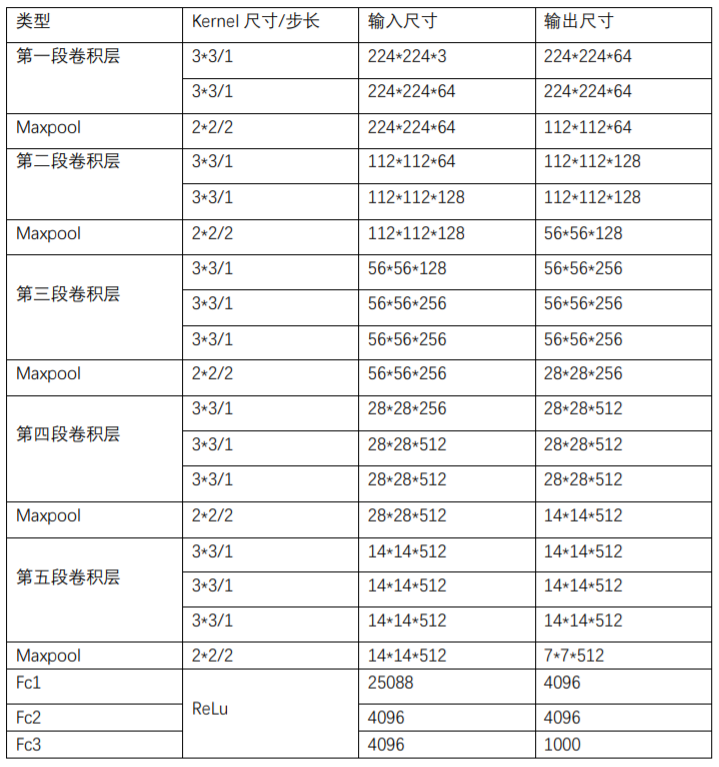
3.3.2特征提取网络结构设计 15
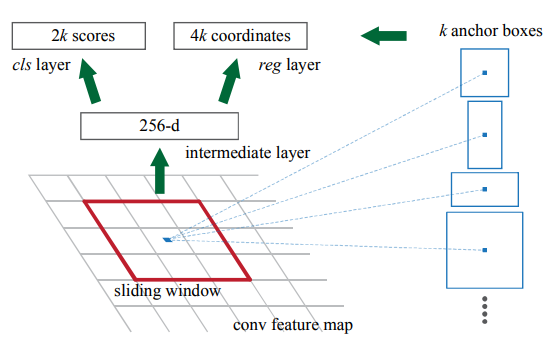
3.3.3区域建议网络结构设计 16
3.3.4感兴趣区域池化层网络结构以及分类层结构设计 20
3.4本章小结 21
第4章 基于Faster R-CNN的行人检测算法的实现与分析 22
4.1程序运行图展示 22
4.2不同情况对Faster R-CNN的影响分析 23
4.2.1明暗对于检测结果的影响 24
4.2.2遮挡程度对于检测结果的影响 24
4.2.3人数对检测结果的影响 25
4.3基于Faster R-CNN算法误差分析 26
4.4实验结果分析 27
4.5本章小结 28
第5章 总结与展望 29
参考文献 30
致谢 31
第1章 绪论
1.1课题研究的目的
行人检测作为当前图像处理和计算机视觉的研究热点,可以看成是一种独特的目标检测问题。行人既有刚性物的特点,又有柔性物的特征,行人检测相对于人脸和车辆,在姿态方面的弹性更大,因此它的检测难度也会大很多[1]。除此以外,在车辆辅助驾驶、视频监控和人体行为分析等应用领域,行人检测不仅仅是基础的一步,更是关键的一步。结合上述原因,行人检测成为计算机视觉领域中研究的热点并不奇怪。
在1982年的时候,Hoffman等人开始做行人检测方面的工作,不过那时候主要是研究人体运动分析。那时候关于行人检测的大多数研究工作的前提都是先规定需要研究的运动目标的检测工作已经完成了,所以他们把长序列运动模式的分析以及运动目标的识别、分类作为研究的重点。在随后的2000年左右,在Pfinder、和VSAM4I等视频监控系统项目中,行人检测并没有被当成一个很重要的步骤,它只是被用作预处理。由于现代社会对智能视频监控、车辆辅助驾驶、基于内容的图像或者视频检索和人体行为分析等技术的需求越来越大,技术要求也越来越智能,,除此以外,像家庭服务机器人、基于航拍图像的行人及受害者检测、Google街景图中的行人消除等新技术的出现,使得一些新的应用领域就此诞生,而这些因素也让场景中需要检测的目标(包括车辆、行人、道路、交通标志和树木等)多样化。由于场景中人体行为的复杂度加深,让分析人体的行为,不能满足于在早期实验中的那样仅仅通过简单的预处理或者人工标注出人体的位置,取而代之的是一种高效且智能的方法,使得能够通过智能设备不需要人工的帮助而自动检测出图像或者视频中的行人,并且将其标记出来。基于此,行人检测技术的发展逐渐成为一种不可逆转的趋势。
在现代社会,由于科技的进步使得新事物出现的速度越来越快,使得社会事件的复杂度增加,这就让监控显得尤为重要,所以行人检测拥有极大的市场潜力,但是仅仅有潜力是不够的,在对行人检测技术的研究过程中,研究人员发现这项技术的难度很高,甚至超过跟踪、识别这些高层的视觉分析技术。在研究行人检测的过程中,不仅模式识别、计算机视觉、图像处理等学科技术起了很重要的作用,行人衣服的改变、明暗程度的变化、体态和身材的差异、拍摄角度的变化以及不同背景的也有很大的影响,这使得虽然关于行人检测的研究很多,但是大部分都不能够满足人们的要求。因此,如何在各种环境下提高行人检测的准确率成为了本文的研究重点。
1.2国内外研究现状
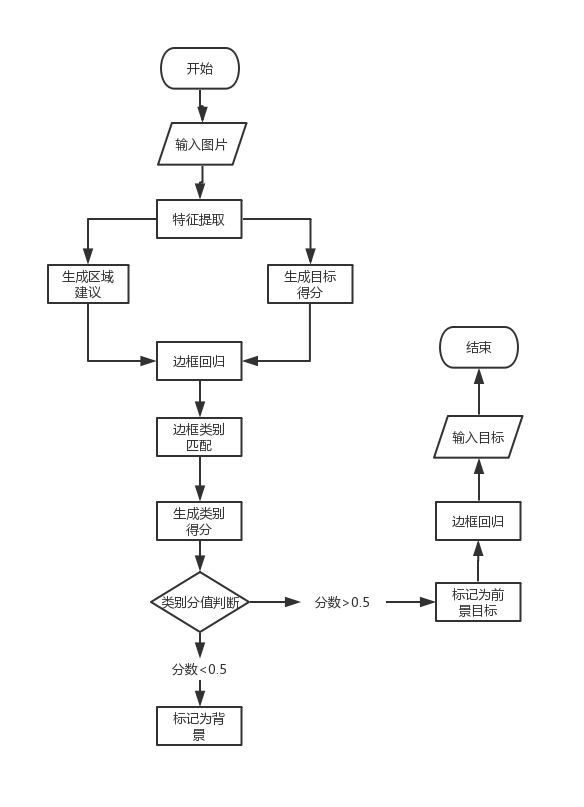
在近些年,深度学习逐渐由陌生到走进人们的视野,越来越引起人们的重视,原先采用其他方法的计算机视觉领域也转移了算法重心,在目标检测的研究上大多采用深度学习这种高效的计算方法。2013年,Sermanet等人提出一种基于CNN的Over Feat算法[2],这种算法通过滑动窗口选择行人的区域从而对画面中的行人进行位置检测。Gishick等人在2014年的时候提出了著名的R-CNN算法,也就是区域卷积神经网络算法,这一算法出自他们在CVPR上发表的论文。在这种算法中,第一步是通过SS ( Selective Search)从需要检测的画面中提取2000个有包含目标可能性的区域,随后将选择出的区域也就是现在常用的感兴趣区域(Region of Interest, Rol)进行压缩[3],让所有区域处于同一尺寸( 227x227 ),然后将压缩过的数据放入CNN中,这一步的目的是将区域的特征提取出来,最后一步为了确定候选区域的种类,用SVM分类器来处理之前得出的特征向量,完成整个的算法流程。2015年,也是在CVPR上,Gishick等人发表的论文中提出Fast R-CNN算法[4],即快速区域卷积神经网络算法,这种算法与R-CNN相似,第一步也是通过SS从原始图像中提取出2000个RoI,随后它直接对总体的待处理图像进行卷积计算,计算过后的出的结果是卷积特征图(Convolution Feature Map),最终将每个候选框特征向量从卷积特征图中提取出来,而这一步是通过感兴趣区域池化层(RoI Pooling Layer)完成的,特征向量在经过全连接层(Fully ConectedLayer)后,进入分类层和边框回归层[5]。分类层的作用是判断所得候选框内检测目标的种类,边框回归层的作用是计算出需要检测的目标在待检测的画面中的具体所在地。2015年,一种更加先进的基于Fast R-CNN算法被提出,也就是Faster R-CNN算法[6],它是由Ren等人在NIPS上发表的论文中提出的。与以往的算法不同,Faster R-CNN算法抛弃了SS,采用RPN (Region Proposal Network)来提取候选框,至此,关于行人检测过程所涉及到的所有任务都处在深度学习的理论下,也就是说它是一个完全的应用深度学习方法进行研究的算法,这种算法很好得将端到端(End-to-End)嵌入进了目标检测的研究中。除此以外,这种算法还有一个优点是它所有的计算过程都在GPU而不是CPU上完成,由于GPU的处理速度远远快于CPU,所以Faster R-CNN算法在准确度和效率上都领先于以往的算法[5]。
1.3本文的主要研究内容
行人检测这一研究话题在近几年一直是个热点,以往采用的算法虽然在理论上可以很好地实现,但是在具体环境中会受到许多因素的影响。在现实生活中背景环境多种多样,像路灯,树木等会对检测造成很大的影响,除此以外,光照强度也是个不可忽略的因素,为了增强算法的鲁棒性,本文采用基于Faster R-CNN的行人检测算法,从行人检测的原理入手,讲述了需要完成的工作,随后结合所选算法进一步论述研究的过程,包括所用特征表示、分类算法、卷积网络结构的设计,最后通过实际应用得出结果。
1.4本文的组织结构
第一章:通过绪论先将本文的写作目的以及当前国内外对这一课题研究的现状阐明,随后对文章的整体脉络结构进行说明。
第二章:对行人检测的相关技术进行阐述,包括基本原理,窗口选择方法,行人特征表示方法,此领域可用的数据集以及评价检测结果的方法。
第三章:结合所选算法进行具体阐述,列举多种算法进行对比说明,得出本文所采用算法的优势,将行人检测的过程进行分层详细说明。
第四章:讲算法的实现,包括不同干扰情况对检测结果的影响,测试算法准确率,分析导致检测不准确的原因。
第五章:总结与展望,对此次设计过程中遇到的问题、做法的不足进行总结,并且对这个领域算法未来的发展提出自己的想法和展望。
第2章 行人检测相关技术简介
2.1行人检测原理
与通常的目标检测不同,行人检测在目标检测中的地位比较特殊,因为相比于其他固定事物来说,行人不确定因素很大,这也使得行人检测成为了计算机视觉中的一个经典难题,在现阶段,想要找到一个能无视场景变换,在任何情况下都能完美得检测出行人的检测器是几乎不可能的,这种情况使得各种行人检测的方法层出不穷。
现在最受欢迎的行人检测技术是应用机器学习来检测提取到的特征[6],在此基础上,研究人员们发现了两种比较有效的方法。第一种是基于分类的行人检测算法。这种算法的工作量很大,因为它需要大量经过事先处理的样本,这些样本被标记为正负工作样本,其区别在于是否包含行人,然后通过特定的算法对这些样本集进行训练,得出一个成熟的分类器,再用这个分类器对待检图片进行检测,判断图片中是否有行人以及行人在图片中所处的位置:第二种方法是基于模板匹配的方法,这种方法直接提取待检图片中与行人有关的信息,再将这些信息与已经建立好的行人模板库中的数据加以比较,从而得出结果。
本文所选用的基于深度学习的行人检测算法采用的是上述所说的第一种算法,由于深度学习的高效、准确的优势,使得第一种算法在当前的趋势下更加占优势。这种算法的核心是通过数据集训练出行人分类器,这一分类器要尽可能包含能够描述行人特征的信息,并且要准确,在这一基础上才能通过训练好的分类器进行图像的测试,检测图像中的行人信息,整体流程包含在行人数据集基础上进行的大量行人分类器的训练和应用训练出的分类器进行的测试集的测试。这两步中分类器的训练尤为重要,工作量也很大,训练包含3个步骤,分别是数据集的选取、行人特征的获取以及分类器的训练,测试阶段的步骤与训练阶段相似,也是3步,分别是窗口选择、行人的特征提取以及分类器的训练。图2.1展示了行人检测的流程:
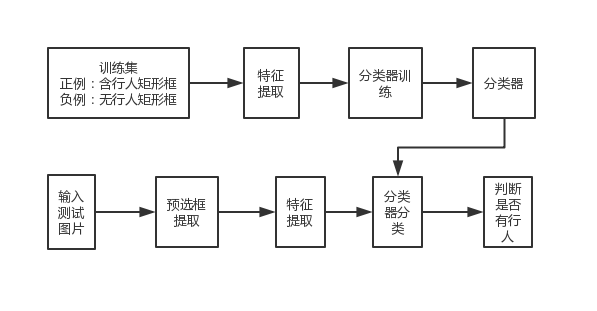 图2.1 行人检测流程图
图2.1 行人检测流程图
2.2窗口选择
经过研究者不断地探索,发现了一种很有效的区域提取法,一般称之为预选框提取法。这种方法首先判断待检测图片中可能存在行人的区域,然后将其标记并且提取出来,随后将提取到的可能存在行人的区域放入到系统中负责检测的系统中判决,在整个系统中,将这些已经提取出可能包含行人区域的矩形框叫做预选框( Region Proposal)[7]。预选框的提取对于整个系统是很重要的,它的质量对行人检测的准确性有很直接的影响。当前的预选框提取的方法多种多样,在选择上有很大的弹性,包括:基于滑动窗口的预选框选择、基于选择性搜索的预选框选择等等。不同的预选框提取法有各自的侧重点,在实际应用过程中,使用者可以根据自己的需求来选择特定的预选框提取法,这就要求每种预选框提取法不仅要在各自的侧重点上有很大的优势,也要保证所有的提取方法都能尽可能的检测出待检测图片中的目标,在此基础上才能发挥它们各自的优点。
2.2.1基于滑动窗口的预选框选择
滑动窗口法是现在一种很受欢迎的检测方法,它可以应用在目标检测的很多方面,包括行人识别、人脸检测以及车辆识别等等,它的核心思想是用二值分类的算法来解决图片或者视频中的检测问题[7]。
在现实环境中,由于行人的体态、服饰以及距离的不确定性,使得窗口的选择需要普遍适用于各种环境而非实时做出更改,于是研究人员就采用了归一化尺寸的方法。这种方法的第一步是将提取到的样本事先注明出来,然后根据注明的区域进行切割,将整个图片分为无数个小区域,这些小区域会被归一化到一个固定且统一的尺寸,当然小区域的尺寸可以根据不同的检测需求做出适当的调整,这是包含行人的样本的处理。随后再选取不包含行人的样本,在这些图像中随机选择无数个小区域块,这些小区域块的尺寸与上述统一尺寸的行人样本需要保持相同。最后一步是将包含行人样本和不包含行人样本的归一化图像块打包,形成深度学习中一个重要的工具:训练集,随后利用不同的算法经过大量的训练得出符合自己要求的二值分类器。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: