基于深度强化学习的交通灯控制研究毕业论文
2020-02-17 21:07:35
摘 要
近年来,交通拥堵是城市交通中的普遍现象,这种现象严重影响了我们的日常生活和工作效率。传统的手动命令流量耗时且效率低。固定时间交通灯控制不能根据不同的交通状况调整交通灯,上述两种方法不能实时协调多个交叉口的交通状况。为了解决上述问题,我们提出了一种更有效的多智能体深度强化学习方法。对于多个交叉口的拥堵问题,多个交叉口的拥堵可用于实时动态控制交通信号灯。在当今的大数据时代,访问各种交通信息并不困难。物联网作为新一代信息技术的重要组成部分,在我们的生活中发挥着重要作用,因此我们可以充分分析和利用这些信息,结合他的多智能体深度强化学习方法来构建多元化具有动态学习能力的交叉口交通灯控制模型。在本文中,我们提出了一种基于确定性策略梯度算法的基于记忆的多智能体深度强化学习方法。我们不仅考虑了车辆,还考虑了行人穿过交叉路口的情况,为公交车和普通车辆设定了不同的优先级。仿真结果表明,该方法能够在多个交叉口稳定运行,协调多个交叉口的交通灯控制,并且取得了较好的实验结果。
关键词:交通灯控制;深度强化学习;深度确定策略梯度算法;马尔可夫决策过程
Abstract
In recent years, traffic congestion is a common phenomenon in urban transportation, and this phenomenon has seriously affected our daily life and work efficiency. The traditional manual command traffic is time-consuming and inefficient. The fixed-time traffic light control cannot adjust the traffic lights according to different traffic conditions, and the above two methods cannot coordinate the traffic conditions of multiple intersections in real time. In order to solve the above problems, we propose a more effective method of using multi-agent deep reinforcement learning. For the congestion problem of multiple intersections, the congestion of multiple intersections can be used to dynamically control the traffic lights in real time. In today's big data era, access to a variety of traffic information is not a difficult thing. The Internet of Things, as a key component of a new generation of information technology, plays an important role in our lives, therefore we can fully analyze and utilize these Information, combined with his multi-agent deep reinforcement learning method to construct a multi-intersection traffic light control model with dynamic learning ability. Ln this paper, we proposed a memory-based, multi-agent deep reinforcement learning approach based on Deterministic Policy Gradient Algorithm. We have not only considered the vehicle but also considered the situation where pedestrians pass through the intersection, setting different priorities for buses and ordinary vehicles. The simulation results show that our method can stably run at multiple intersections and coordinate the traffic light control of multiple intersections, and the algorithm achieved good experimental results.
Key Words:Traffic Light Control, Deep Reinforcement Learning, Deep Deterministic Policy Gradient Algorithm, Markov decision process.
目 录
第1章 绪论1
1.1 背景、目的和意义1
1.2 国内外研究现状3
1.3 本文的工作4
第2章 系统模型与问题描述5
第3章 深度强化学习模型8
3.1 交叉路口状态8
3.2 智能体的动作9
3.3 环境的奖励10
第4章 交通灯控制的深度强化学习算法12
4.1 深度Q学习算法(DQN)12
4.2 深度确定策略梯度算法(DDPG)13
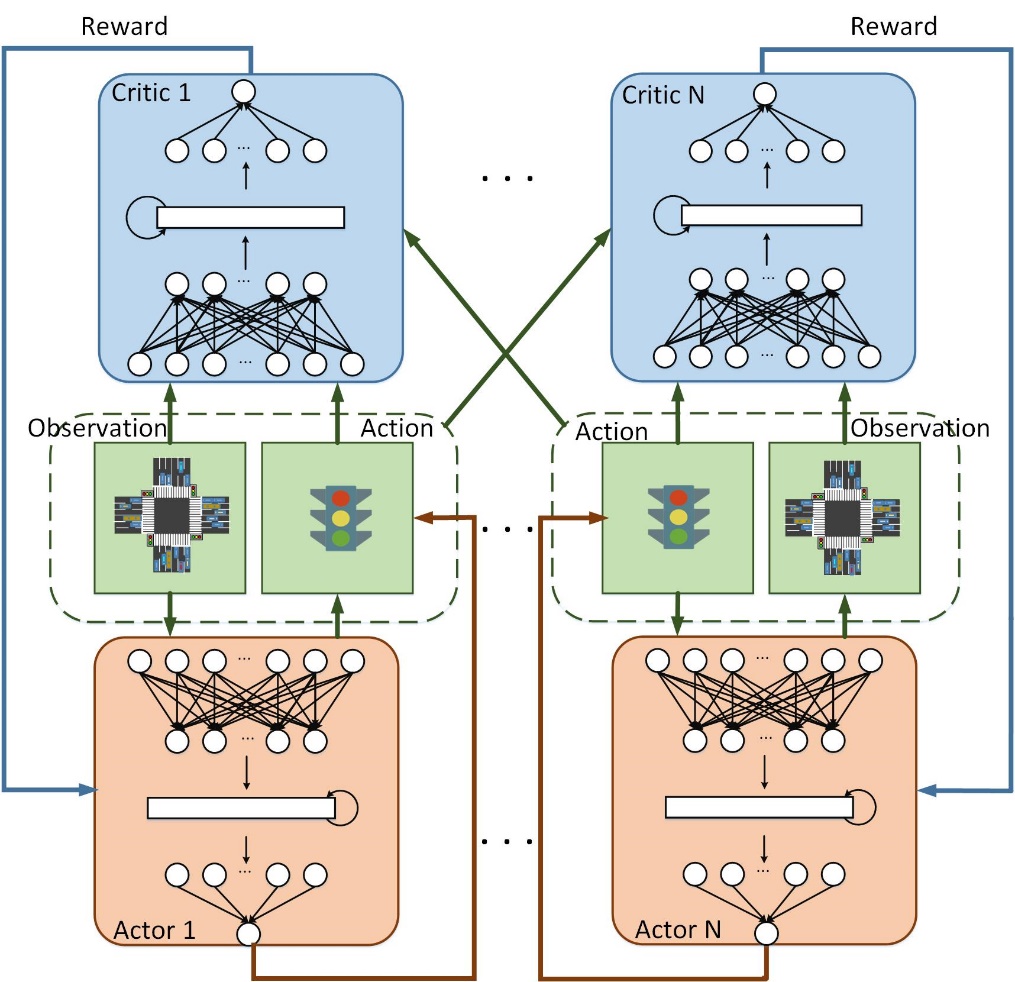
4.3 MARDDPG算法13
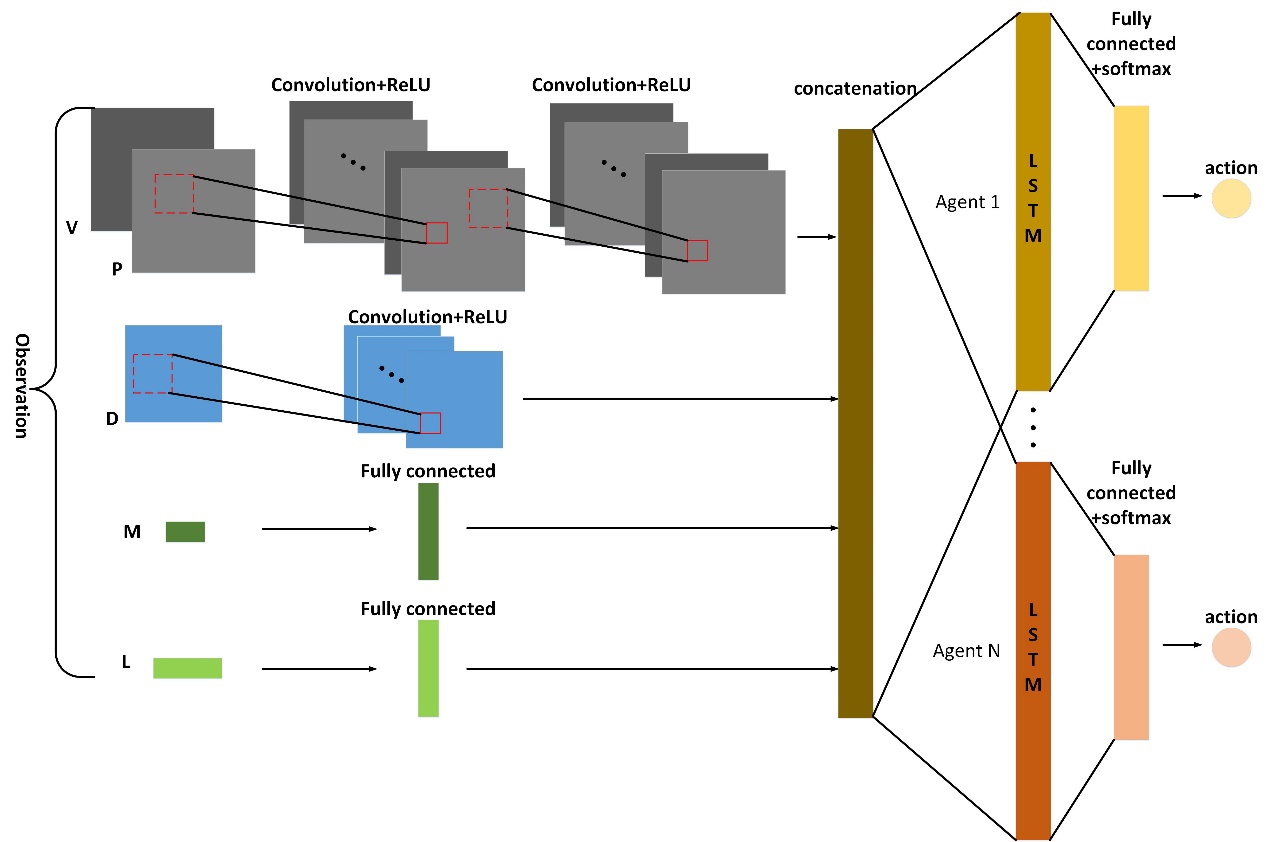
4.4 网络结构17
4.5 参数共享18
4.6 最优策略19
第5章 仿真实验20
5.1 实验参数设置20
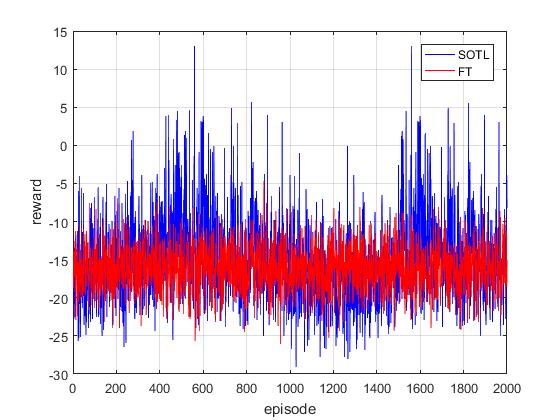
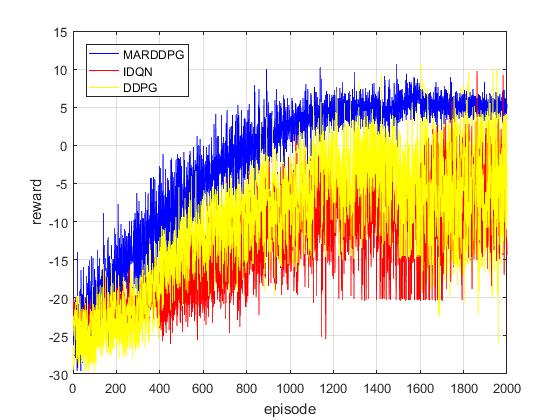
5.2 方法比较21
5.3 实验结果22
5.3.1 累积奖励22
5.3.2 综合评估24
第6章 结论26
参考文献27
致 谢30
第1章 绪论
1.1 背景、目的和意义
 随着社会经济的快速发展,人们物质和精神生活的改善,城市不断发展壮大,私家车越来越普遍,给交通问题带来很大压力。 由于交通问题影响到各个行业,城市交通拥堵已成为一个不容忽视的重要问题。同时,交通拥堵也会带来不必要的资源损失和环境污染,同时也会增加交通事故的概率。因此,我们需要关注这些问题。此外,城市交通条件复杂,交叉口较多,没有固定的规则,不同交叉口的交通拥堵也不一致。传统的固定时长的交通灯控制策略只能应用在一些简单的交通拥堵状况,因为交通状况在随着时间不断变化。最长队列优先的交通灯控制算法虽然有时能比固定时长的交通灯控制算法更有效,但是仍然无法解决根本问题,因为各个交叉路口相互关联,有时候需要考虑多个交叉路口的交通情况才能更好控制交通灯,所以这种算法没有办法同时解决各个交叉路口交通拥堵的问题。有时我们经过拥堵的交叉路口时会看到有经验丰富的交警在手动指挥车辆,这种方法有时很有效,但是十分浪费人力和时间,所以最好的方法就是用计算机指挥来代替交警的指挥,我们需要计算机能够像人一样在与环境交互中不断地从环境中学习经验,拥有自己的思考,从而更好的控制交通灯,缓解交通拥堵。
随着社会经济的快速发展,人们物质和精神生活的改善,城市不断发展壮大,私家车越来越普遍,给交通问题带来很大压力。 由于交通问题影响到各个行业,城市交通拥堵已成为一个不容忽视的重要问题。同时,交通拥堵也会带来不必要的资源损失和环境污染,同时也会增加交通事故的概率。因此,我们需要关注这些问题。此外,城市交通条件复杂,交叉口较多,没有固定的规则,不同交叉口的交通拥堵也不一致。传统的固定时长的交通灯控制策略只能应用在一些简单的交通拥堵状况,因为交通状况在随着时间不断变化。最长队列优先的交通灯控制算法虽然有时能比固定时长的交通灯控制算法更有效,但是仍然无法解决根本问题,因为各个交叉路口相互关联,有时候需要考虑多个交叉路口的交通情况才能更好控制交通灯,所以这种算法没有办法同时解决各个交叉路口交通拥堵的问题。有时我们经过拥堵的交叉路口时会看到有经验丰富的交警在手动指挥车辆,这种方法有时很有效,但是十分浪费人力和时间,所以最好的方法就是用计算机指挥来代替交警的指挥,我们需要计算机能够像人一样在与环境交互中不断地从环境中学习经验,拥有自己的思考,从而更好的控制交通灯,缓解交通拥堵。
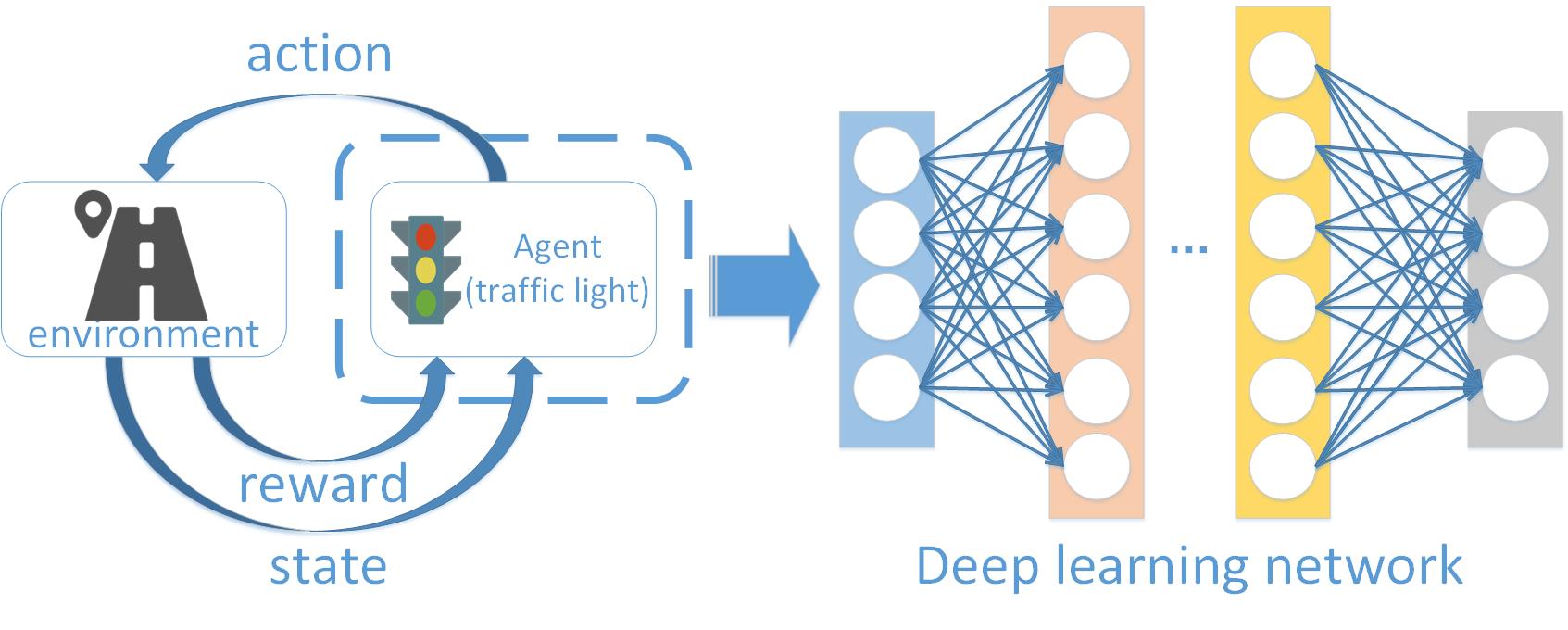
图1.1 深度强化学习应用在交通灯控制中
在早期的研究中,有一些研究人员曾使用模糊逻辑[1][2](neuro-fuzzy)、神经网络(Neural Networks)和遗传算法[3](genetic algorithms)来解决交通灯控制的问题,遗传算法和神经网络需要的计算量大且复杂,并且遗传算法存在早熟收敛的问题,模糊逻辑不适用于复杂或多个交叉路口。所以针对多个交叉路口的交通灯的控制,强化学习[4]的方法很适合来解决上述问题。在之前的一些研究中,强化学习在机器人控制和博弈论中有着广泛的应用,也有不少人已经将强化学习应用到交通灯控制中。但是传统的强化学习系统的复杂度会随着状态空间的增大而成指数级增长,而将现在发展迅速的深度学习与强化学习结合起来就能解决这个问题。深度强化学习[5]应用在交通灯控制的基本框架如图1.1所示。在深度学习中可以利用深度神经网络来逼近值函数。不同的交叉路口的拥堵情况各不相同并且多个交叉路口的拥堵程度会相互影响,所以每次只考虑本地交叉路口的交通情况显然是不够的,我们应该在控制本地交叉路口的交通灯的同时考虑多个交叉路口的交通情况。
近年来互联网和无线通信的不断发展,各种数据的获取变得比以前更加的方便快捷,并且合理利用各种交通数据也是解决交通拥堵问题的关键。其中物联网[6]作为新一代信息技术的关键成分,在我们生活中发挥着重要的作用,交通数据具有明显的时空特征,可以从中获得很多有价值的信息。我们可以使用物联网来捕获用于交通灯控制的实时的车辆信息和路况信息,利用这些时空交通信息更好来调节多个智能体之间的交流,从而进行多个路口的交通灯控制,找到一个最优的交通灯控制策略。
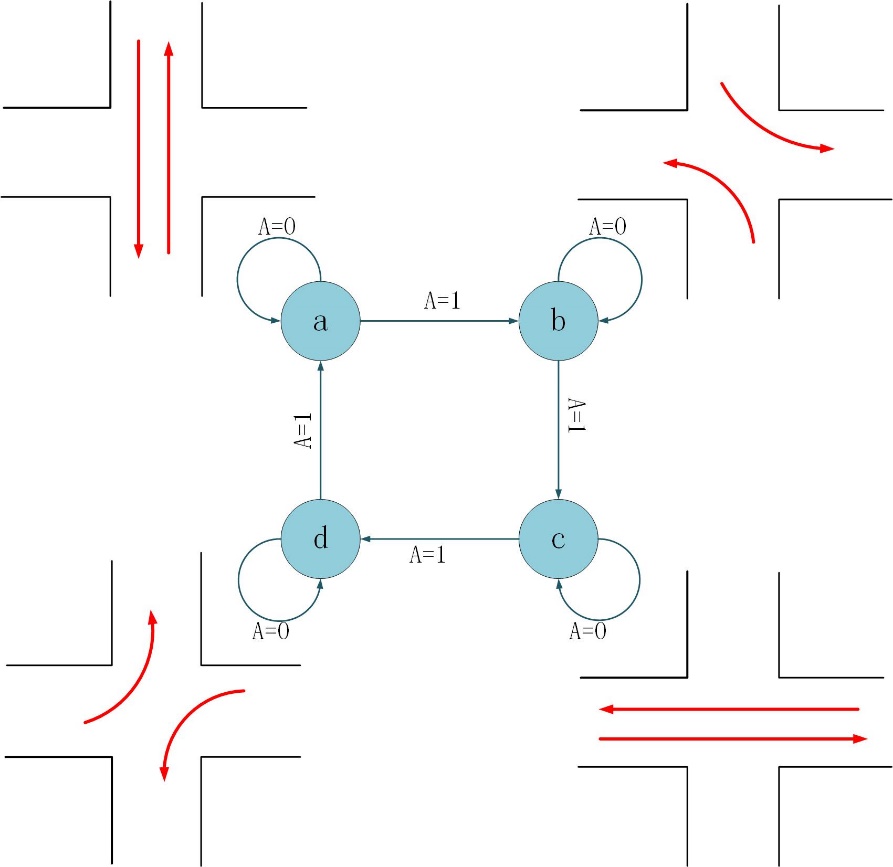
在多个交叉路口的情况下,每个交叉路口无法完全了解所有交叉路口的交通情况,即每个智能体只能观察到部分的交通情况,这是一种非平稳的环境,所以可以将这种多智能体的系统看成部分可观测MDP[7](POMDP)模型,我们可以通过给系统加入记忆模块来解决这一问题,就如使用递归神经网络[8](RNN)。此外,在复杂的多交叉路口的情况下,单独考虑某一时刻的交通状况来进行交通灯的控制是不够的,因为车流和人流是具有时间连续性的,不考虑时间连续性会导致失去很多的重要信息从而无法进行正确的决策,所以我们也可以利用RNN来捕获和时间有关的信息
我们提出MA-RDDPG算法来解决多个交叉路口的交通灯控制的问题。我们把每个交叉路口视为一个智能体,多个交叉路口即多个智能体之间并不是孤立的,多个交叉路口之间具有空间相关性,他们之间可以相互竞争和协作,最终达到最优的联合策略。我们将我们的方法用于大规模的交通网络中的多个交叉路口的交通灯控制,这里我们考虑6个交叉路口的交通网络。另外,为了使我们的模型更贴近真实的交通问题,在考虑车辆的同时,我们还需要考虑过马路的行人数量,确保行人的等待时间不会过长。因为在市区或者商业区行人数量很多,有时通过车辆状态来控制的交通灯会导致将要过马路的行人等待过久,这样也会给行人带来极大的不便。不同于之前的研究,我们不再视所有的车辆为同一优先级,公交车作为城市公共交通工具,乘客的数量远超普通车辆上乘客数量,所以我们给予公交车更高的通信优先级,也就是说,减小公交车的拥堵比减小普通汽车的拥堵能或得更多的奖励。
本文的其余部分安排如下。在第二章中,介绍系统模型和问题描述。在第三章中,我们定义了深度强化学习模型。第四章展示了我们的交通灯控制算法的细节。在第五章中,我们通过模拟评估了算法。最后,我们在第六章中总结了这篇论文。
1.2 国内外研究现状
如今,在交通灯控制技术方面,最适用于现实世界的是固定时间的交通灯控制。还有一些地区使用根据不同时间控制交通灯的方法。但是,此方法中设置的交通灯的持续时间也是预先设计的,而不是实时的。在以往的研究中,为了解决交通灯控制问题,许多研究人员提出了各种自适应交通控制系统(ATCS),它们不像传统的固定长度交通灯控制系统。交通灯可以根据当前的交通拥堵情况合理地改变,例如SCOOT[9](分裂,周期和偏移优化技术),SCATS[10](悉尼协调自适应交通系统),OPAC[11](优化自适应控制政策),RHODES[12](实时分层优化分布式有效系统)。对于复杂的交通系统,强化学习方法可以更有效地解决交通拥堵问题,越来越多的研究人员提出使用强化学习来解决交通灯控制问题。Q学习[13]算法是一种无模型强化学习算法,Q学习算法非常适合这类问题。但是,在Q学习算法中,所有Q值都存储在一个表中,表的行和列分别是状态和动作。当我们的状态和动作非常大时,Q表会非常大,以至于计算机的内存不能支持如此大的Q表。因此,我们可以使用深度强化学习[14]来解决这个问题。深度强化学习将快速增长的深度学习与传统强化学习相结合。与经典强化学习最大的区别在于它直接处理像素级超原始图像状态输入而不是将状态抽象为低维状态。近年来,许多研究人员已应用深度Q学习(DQN)引用[15]和深度循环Q学习[16](DRQN)来指示单个交叉路口的交通灯控制。但是,在实践中只考虑一个交叉点是绝对不够的。由于多个交叉点会相互影响,许多研究人员已经提出应用多智能体DRL算法[17]来控制交通信号灯。
用于解决多个交叉口的交通灯控制的多智能体强化学习方法可以分为三类。第一类是完全孤立的多智能体强化学习[18],它假设每个智能体彼此独立。观察当地的交通状况,只控制当地交叉路口的交通信号灯。虽然这种方法很简单,但它缺乏智能体之间的合作,因此很难收敛到最优的联合政策。第二类是部分状态合作的多智能体强化学习[19]。该方法通常考虑相邻交叉口的部分状态信息,并将邻近智能体的本地交通状态与部分状态信息组合以控制本地交通灯。它将取得比第一类更好的结果。由于仅考虑了邻近智能体的部分状态,因此忽略了动作之间的内在关系。此外,每个代理仍然使用贪婪算法进行独立选择操作,并且可能不会收敛到均衡的联合策略,并且需要改进效果。第三类是动作联合的多智能体强化学习[20],它代表一些或所有智能体作为联合动作。尽管此方法充分考虑了某些智能体或所有智能体的状态,但随着智能体数量的增加,动作空间和状态空间也非常大,这可能导致维度灾难,因此很少使用此方法。
这些研究中的状态,奖励和行动是不同的。通常,有两种类型的动作设置,一种是固定相序[21],另一种是可变相序[19]。虽然可变相序更灵活,但驱动程序通常不知道下一阶段是什么,因此它不适合实际交通。
1.3 本文的工作
在上述工作中还存在一些其他问题,即它们不考虑多个交通灯控制器之间的协调和协作。并且,我们不应该利用相邻交叉口的普通部分状态信息来独立控制当地交通灯。针对上述问题,本文的主要工作为:
(1)本文采用深度强化学习方法对多个交叉口的交通信号灯进行控制,多个交叉口的交通灯控制器相互配合,达到全局最优交通灯控制策略。
(2)以前的工作并没有结合实际交通中不仅车辆想要通过,还有行人要通过,所以本文也考虑了将要通过交叉路口行人的数量。
(3)公交车上的乘客数量可以达到其他车辆乘客数量的几倍,将两者视为一样,这显然是不公平的,所以本文中我们定义公交车和普通车辆有不同的优先级。
(4)我们还定义了新的状态和奖励。
第2章 系统模型与问题描述
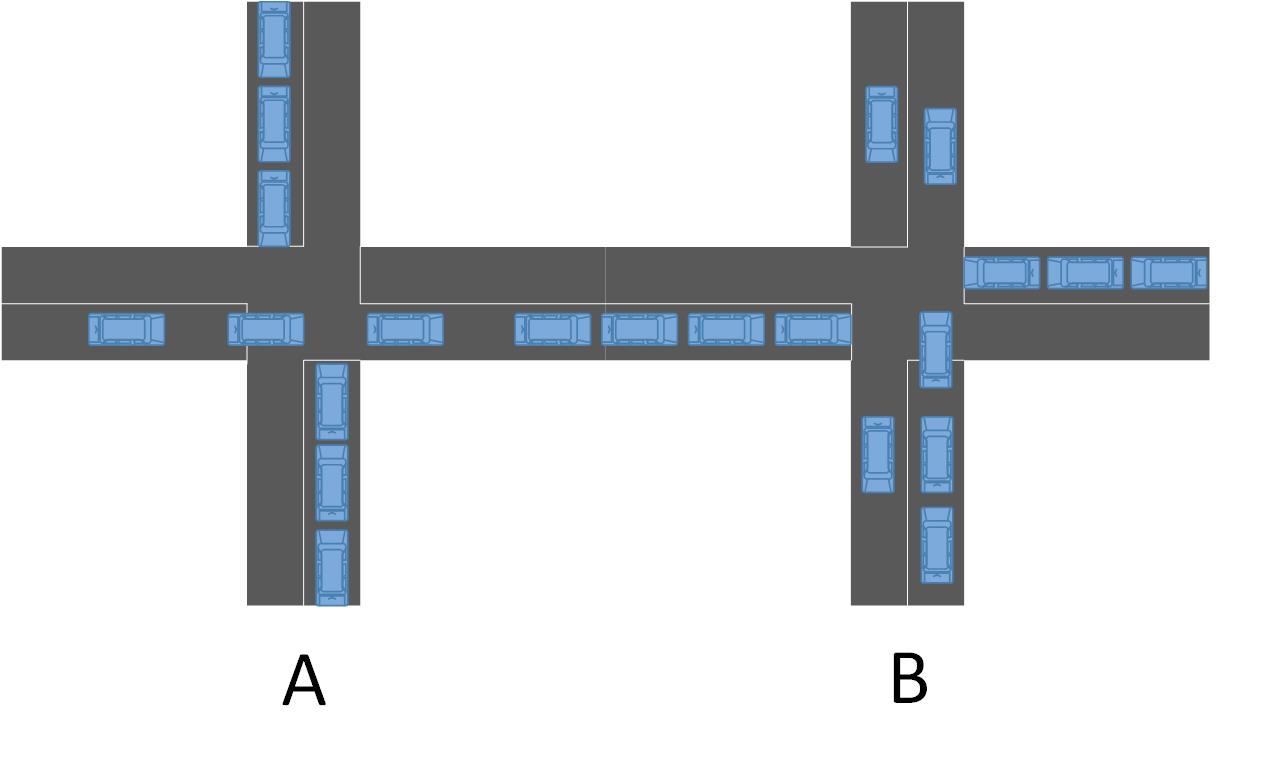
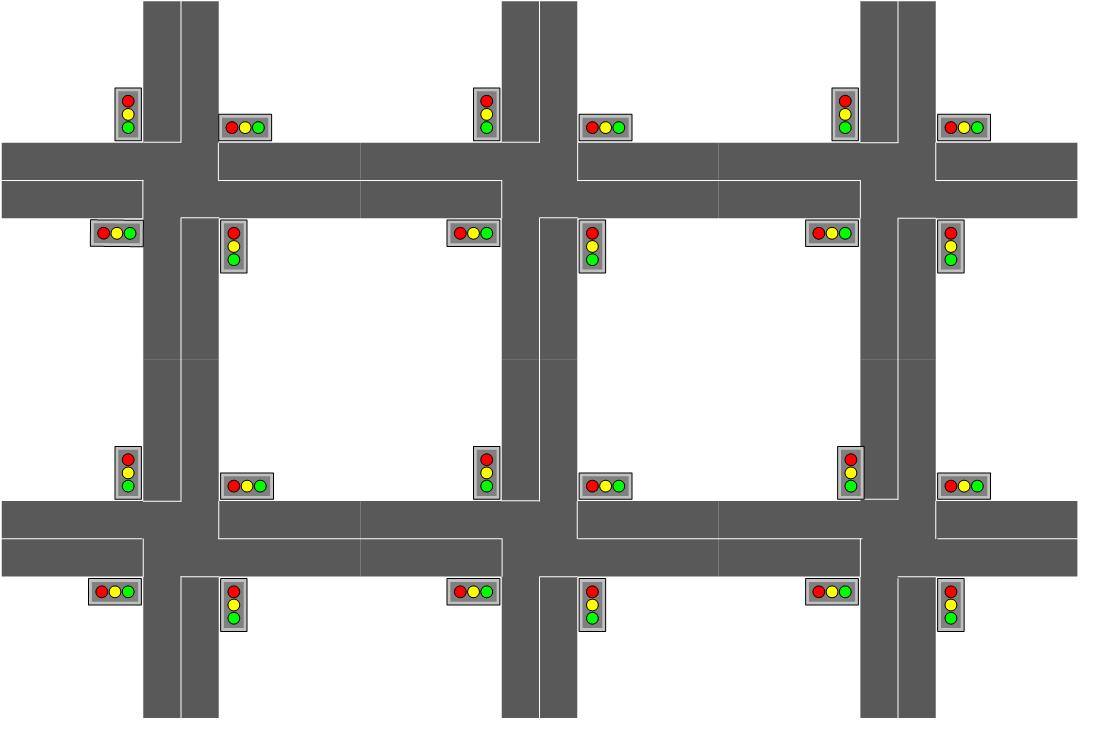
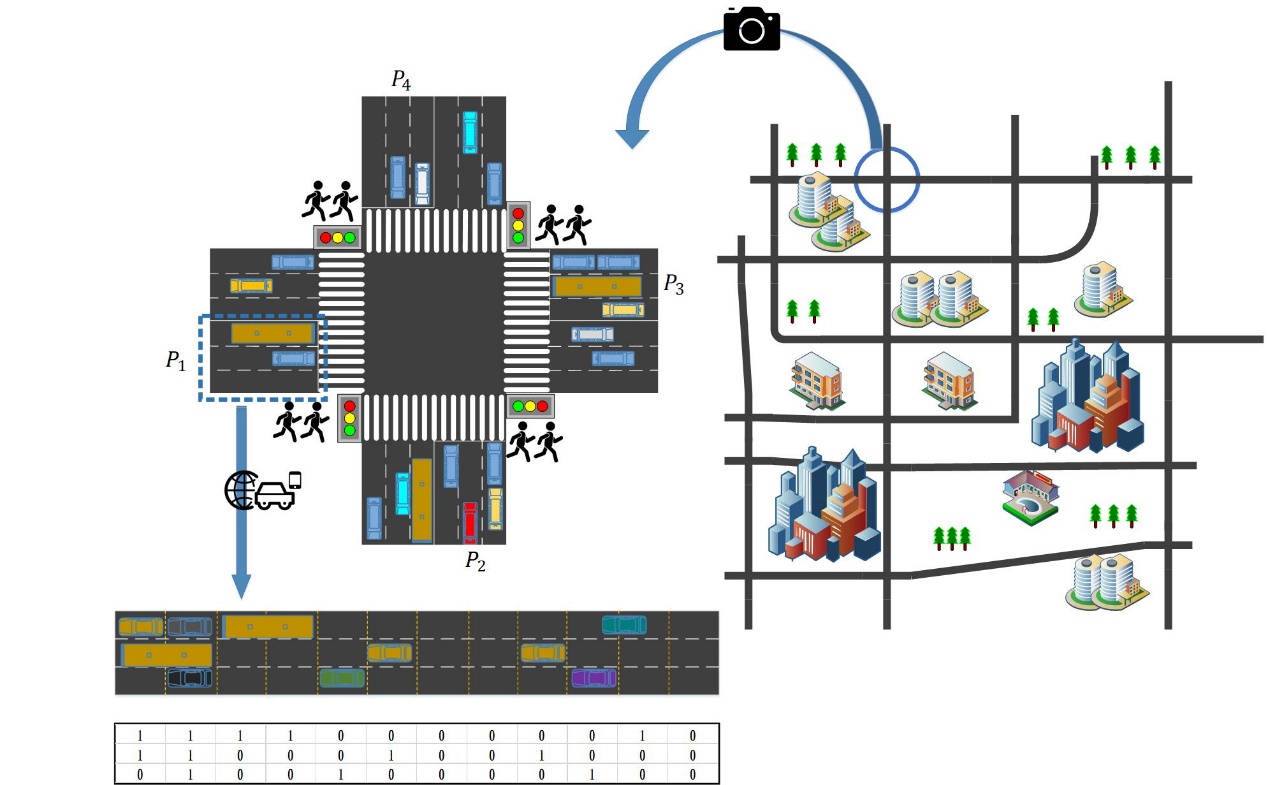 在本文中,我们应用深度强化学习来控制交通信号灯。从而缓解多个交叉口的交通拥堵。我们通过物联网收集交叉路口的交通信息,并利用时空数据根据不同的环境控制每个交叉路口的交通信号灯。假设每个交叉口是一个四向交叉口,每条道路包含三条车道如图2.1所示。最里面的车道是左转车道,中间是直线车道,最外面的车道是直线和右转车道。通过交叉路口的每辆车都将由红绿灯控制。绿灯阶段可以通过,红灯阶段代表停车等待,绿灯和红灯阶段之间将有固定的黄灯时段,以确保交通安全。在我们的模型中,我们通过调整红灯和绿灯的持续时间来控制交通流量,以最大限度地减少交通拥堵,并且我们在每次调整后获得状态和来自环境的反馈,如图1.1所示。我们使用两个深度神经网络来估计Q值函数并进行每个动作选择。与此同时,我们需要综合国家信息的各个方面。在多个交叉口的情况下,我们需要考虑多个交叉口的时空信息,以最大限度地减少所有交叉口的总拥堵。
在本文中,我们应用深度强化学习来控制交通信号灯。从而缓解多个交叉口的交通拥堵。我们通过物联网收集交叉路口的交通信息,并利用时空数据根据不同的环境控制每个交叉路口的交通信号灯。假设每个交叉口是一个四向交叉口,每条道路包含三条车道如图2.1所示。最里面的车道是左转车道,中间是直线车道,最外面的车道是直线和右转车道。通过交叉路口的每辆车都将由红绿灯控制。绿灯阶段可以通过,红灯阶段代表停车等待,绿灯和红灯阶段之间将有固定的黄灯时段,以确保交通安全。在我们的模型中,我们通过调整红灯和绿灯的持续时间来控制交通流量,以最大限度地减少交通拥堵,并且我们在每次调整后获得状态和来自环境的反馈,如图1.1所示。我们使用两个深度神经网络来估计Q值函数并进行每个动作选择。与此同时,我们需要综合国家信息的各个方面。在多个交叉口的情况下,我们需要考虑多个交叉口的时空信息,以最大限度地减少所有交叉口的总拥堵。
图2.1 交叉路口与位置矩阵
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: