机器人智能对话技术研究毕业论文
2020-02-17 22:08:37
摘 要
本文针对近几年火热的智能对话系统进行研究,分别研究了智能对话系统的语音采集技术、语音识别技术和对话管理技术等三个主要部分,并深入研究了三个主要部分的常见算法。在设计和实现系统中,本文将双门限端点检测法、MFCC算法、隐马尔可夫模型和基于有限状态机的对话管理技术相结合,通过MATLAB搭建了一个简易的智能对话系统,该系统可以实现对30个特定汉语发音的问题进行识别并利用对话管理技术作出相应回复。
关键字:双门限端点检测法、MFCC、HMM、有限状态机、MATLAB。
Abstract
In this paper, the hot intelligent dialogue system in recent years is studied, including three main parts: voice acquisition technology, voice recognition technology and dialogue management technology, and the common algorithms of the three main parts are deeply studied. In the design and implementation of the system, this paper combines the two-threshold endpoint detection method, MFCC algorithm, hidden Markov model and finite state machine-based dialogue management technology, and builds a simple intelligent dialogue system through MATLAB. The system can recognize 30 specific Chinese pronunciation problems and respond accordingly by using dialogue management technology.
Key words: double threshold endpoint detection method, MFCC, HMM, finite state machine, MATLAB.
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景及意义 1
1.2 智能对话技术的研究现状 1
1.3 论文研究内容与组织安排 2
第2章 语音采集技术 3
2.1 采样与量化 3
2.2 预加重处理 3
2.3 分帧和加窗处理 4
2.4 短时能量和短时平均过零率 4
2.5 端点检测 5
第3章 语音识别技术 7
3.1特征参数的提取 7
3.1.1 时域特征参数的提取 7
3.1.2 频域特征参数的提取 7
3.2模式匹配算法 10
3.2.1 动态时间规整算法 10
3.2.2 隐马尔可夫模型 11
第4章 对话管理技术 15
4.1 基于有限状态机的对话管理 15
4.2 基于槽的对话管理 15
4.3 基于任务的对话管理 16
第5章 机器人智能对话系统总体设计 18
5.1 语音采集模块 18
5.2 语音识别模块 18
5.3 对话管理模块 19
第6章 智能对话系统的实现与测试 20
第7章 结论与展望 26
参考文献 27
致 谢 28
第1章 绪论
1.1 研究背景及意义
近几年来,语音助手成为了商家着力宣传的热点功能,几乎所有的手机都内置了语音助手,具备语音助手功能的智能音箱也一夜之间红遍大江南北,成为炙手可热的明星产品。而这一切都归功于智能对话技术的迅猛发展。
智能对话技术不仅使我们的生活更加便捷,而且在其他领域也发挥着重要的作用。在日常的生产生活中,以智能对话技术为基础的产品应用领域十分广泛,有语音通信系统、工业控制、翻译系统和银行服务等。智能对话技术几乎深入到生产生活的各个领域,由此产生的社会经济效益十分可观,是一个国家发展的重要技术支撑。因此,研究智能对话技术具有深刻的社会经济意义。
1.2 智能对话技术的研究现状
自从计算机学科诞生以来,实现人与机器的自然语言对话就是人们永恒的追求。早在上世纪五十年代,Alan Turing的《计算机与智能》中就定义了能通过图灵测试的终极对话系统。然而,到目前为止,人们仍然没有制造出完全意义上的智能对话系统。
经过半个多世纪的发展,智能对话系统逐渐形成了两个主要方式:聊天机器人方式和对话管理方式。聊天机器人方式起源于上世纪六十年代麻省理工学院开发的Eliza,此方式不能对人们所说的内容进行理解,仅仅依靠简单的规则选择系统中已经定义好的答案。利用这种方式的智能对话系统对数据具有极大的依赖性,如果系统内的数据量过少,系统极易产生答非所问的情况。对话管理方式出现的时间比聊天机器人方式晚一些,在上世纪八十年代,采用对话管理方式的对话系统才逐渐起步。对话管理方式是将人们说的话进行智能拆分与理解,并利用相当复杂的知识来回答人们提出的问题。与聊天机器人方式相比,对话管理方式对数据的依赖性较小,可以更为独立地处理一些人们提出的问题,智能化水平更高。
目前的智能对话系统已经处于一个比较高的水平,但距离真正意义上的智能对话系统还相距甚远。为了进一步提高智能对话系统的智能化水平,智能对话系统有以下三个主要的发展趋势。
1)提高可靠性
虽然当前的智能对话技术在纯净条件下准确率已经处于比较高的水平,但是在有外干扰的情况下准确率仍有待提高。除此之外,人类语言的随意性、不确定性和多样性也给智能对话技术造成了不小的困难。因此,智能对话需要依靠更加先进的技术以达到更好的对话效果[[1]]。
- 深度学习。
现阶段的智能对话系统在很大程度上依赖于人工标注好的数据,回复的内容缺乏多样性。因此对话系统应当进一步理解自然语言,根据语言内容做出相应回复。
3)微型化并降低成本
智能对话技术用途十分广泛,把智能对话技术与先进的微电子技术相结合,将具有先进功能和性能的智能对话系统集成到芯片或模块上,可以大大降低成本,便于推广和使用。
1.3 论文研究内容与组织安排
本文对智能对话系统的实现过程进行研究,分别设计与实现了基于隐马尔可夫模型的语音识别模块和基于有限状态机的对话管理模块,通过这两个模块最终实现一个简易的智能对话系统。在语音识别方面,本文针对特定30个汉语发音问题收集了大量语音材料,利用隐马尔可夫模型对其进行训练并生成语音模型库,然后将未知语音与模型库内语音匹配实现语音识别。在对话管理方面,本文利用有限状态机,根据语音识别模块识别出的内容和系统的当前状态,匹配出最佳结果并输出,用户即可得到智能对话系统的回复。
本文主要分为七个部分,具体内容安排如下:
第一章是绪论部分,主要介绍智能对话系统的研究背景和现状。
第二章介绍了语音采集技术的主要内容和实现算法,包括双门限端点检测法的理论和实现方法。
第三章介绍了语音识别技术中的常用方法,依次讲述了语音特征参数提取和模式匹配算法。
第四章主要介绍了智能对话系统的核心,即对话管理技术。并且分别介绍了常用的三种对话管理技术方法。
第五章从整体上对智能对话系统进行设计,其中包括系统的总体设计、系统组成和关键技术等内容。
第六章讲述了基于MATLAB的智能对话系统的实现过程,包括MFCC的提取、隐马尔可夫模型和基于有限状态机的对话管理技术的实现,并对智能语音系统的性能做了实验和分析。
第2章 语音采集技术
2.1 采样与量化
作为模拟信号的一种,人们发出的语音信号在时间上连续,在幅值上也连续,而计算机是由数字电路组成,只能对数字信号进行处理,因此需要将语音信号转变为数字信号。对语音信号而言,浊音的频谱一般在4kHz以内,而清音的频谱甚至超过了8kHz,但实验表明,对于影响语音清晰度和可懂度的信号频谱一般在3.4kHz以内。根据奈奎斯特采样定理,只有当采样频率高于信号中最大频率的两倍,才能从数字信号中将原始信号还原出来。因此,语音信号的采样频率需要定为8kHz,既可以满足语音清晰度和可懂度的要求,又可以降低计算机处理难度与压力,提高处理速度。
为了抑制输入信号中无用的频率分量和50Hz电源的干扰,在对语音信号采样之前还需要一个步骤:预滤波处理。预滤波处理可以把对输入信号产生干扰的信号滤除。
在预滤波处理结束后,智能对话系统将输入信号以8kHz的采样频率进行采样,再将采样后得到的离散时域语音信号通过A/D转换器进行量化处理,量化为多位二进制数码,完成语音信号的采样与量化。
2.2 预加重处理
预加重是一种十分重要的前处理技术。虽然对于日常生活中的对话,人耳听起来并不会感觉有异常,但这并不是人们真正发出的语音信号。人的语音信号在产生时就会受到声带、嘴巴和鼻子的影响,使信号产生衰减,这种影响被称为口鼻辐射和声门激励。所以,在处理语音信号之前,需要语音信号的高频部分增强,补偿语音信号中衰减的高频成分。预加重技术有利于大幅降低较低频率的干扰,增强已衰减的高频能量,使信号变得较为平坦,提高语音识别性能。预加重技术的通常方法是给语音信号加一个预加重滤波器,其公式表示为:
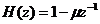
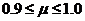 (2.1)
(2.1)
其中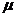 为预加重系数,根据该公式可以将预加重网络的输出
为预加重系数,根据该公式可以将预加重网络的输出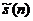 和输入信号
和输入信号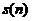 的关系用差分方程表示
的关系用差分方程表示
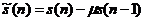 (2.2)
(2.2)
预加重技术的作用主要是增加一个零点,降低唇边辐射和声门脉冲引起的高频幅度下跌,增强高频部分能量,使高频提升,让语音信号中只剩下声道部分影响,提取到更符合声道模型的特征参数[[2]]。
2.3 分帧和加窗处理
语音信号是一种典型的非平稳信号,语音信号的特性随时间的变化而变化。可是计算机只能对平稳信号进行处理,所以计算机对语音信号无法直接进行处理。任何非平稳信号在极短的时间内都可以被认为是平稳信号,因此我们可以将连续语音信号分割成时间极短的信号帧,每一帧的时间很短,所以在每一帧内的信号都是平稳信号,便于计算机进行信号处理。为了保证特征矢量系数的平滑,我们使帧与帧之间有部分样本重叠使用[[3]]。
语音信号加窗处理是将语音信号分段处理的最基本手段,即用一个有限长度的窗序列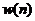 ,截取一段语音信号进行分析。该窗函数可以按照时间轴移动,便于分析任一时刻附近的信号。加窗运算的公式为:
,截取一段语音信号进行分析。该窗函数可以按照时间轴移动,便于分析任一时刻附近的信号。加窗运算的公式为:
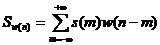 (2.3)
(2.3)
加窗运算是卷积运算的一种,语音信号的带宽和频率响应由窗函数决定。在数字信号处理中,常用的窗函数为矩形窗、汉明窗和汉宁窗三种,其定义分别为:
- 矩形窗:
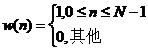 (2.4)
(2.4) - 汉明窗:
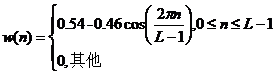 (2.5)
(2.5) - 汉宁窗:
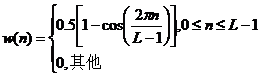 (2.6)
(2.6)
对于语音信号处理来说,需要选择旁瓣值要小,主瓣宽度要窄的窗函数,可以使能量集中在主瓣上,从而抑制频谱泄漏。目前使用较多的窗函数是汉明窗。
2.4 短时能量和短时平均过零率
对于时域语音信号来说,其振幅或能量的变化规律能够代表这一语音的特点,而短时能量可以准确地表达该规律。在语音信号的时域波形图中,我们可以直接观察出振幅和能量的变化,尤其是清音和浊音的区别。因此,可以通过语音信号的短时能量来描述语音信号的幅度变化。语音信号的短时能量定义为:
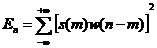 (2.7)
(2.7)
其中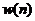 是窗函数,对于语音信号而言,窗函数的长度几乎决定了信号的幅度变化特征。窗长过短时,窗内语音信号不够平滑,很难进行处理;而窗长过大时,语音信号的幅度变化规律很容易被忽略。因此,在选择窗函数时,窗函数的长度不应过长也不应过短。
是窗函数,对于语音信号而言,窗函数的长度几乎决定了信号的幅度变化特征。窗长过短时,窗内语音信号不够平滑,很难进行处理;而窗长过大时,语音信号的幅度变化规律很容易被忽略。因此,在选择窗函数时,窗函数的长度不应过长也不应过短。
语音信号中的清音段和浊音段的短时能量水平有较大不同,因此可以通过短时能量进行粗略区分,除此之外,短时能量还可以区分高信噪比语音信号中是否含有语音。
过零分析法是语音信号时域分析中十分重要的方法,过零就是信号通过坐标轴的横轴。对于模拟信号来说,信号是否过零可以通过观察其时域波形通过时间轴来确定。若相邻取样值符号改变,则可以认为离散信号通过零点。据此可以计算过零率,单位时间内的过零率称为平均过零率。
语音信号的短时平均过零率定义为:
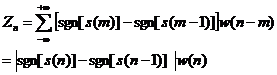 (2.8)
(2.8)
根据声学原理,在3kHz以下的能量主要是浊音段,在3kHz以上的能量主要是清音段。根据实验结果可以得出,过零率较高的频率段主要集中在高频部分,而过零率较低的频率段主要集中在低频部分。因而可以根据平均过零率水平的高低来粗略区分清音和浊音。平均过零率除了具有将清音和浊音区分开的能力之外,还具有分辨含有语音信息信号和背景噪声的能力,所以我们可以利用平均过零率检测语音信号是否开始或结束。
2.5 端点检测
端点检测是智能对话技术中的重点,是语音信号处理领域中一个基本且重要的问题。若计算机对直接输入的语音信号进行处理,那么计算机会处理大量不包含语义信息的语音信号,大大增加计算机的负荷。为了降低计算机的处理负荷,提高处理速度,我们可以通过找到有效语音信号起止点,仅对该部分语音信号进行处理。语音信号通过端点来分割,因此端点在很大程度上影响智能对话的性能。优秀的端点检测算法应具有高可靠性、自适应性和对噪声特征无需先验知识等特性[[4]]。目前有很多种端点检测算法,如:基于线性预测梅尔频率倒谱特征的检测方法、应用倒谱特征的检测方法、基于能频值的检测方法、基于熵函数的语音端点检测方法等。本文主要介绍一下目前最为常用的双门限端点检测法。
利用两个门限值在语音信号中分辨背景噪声以及确定有效语音信号的起点和终点的方法称为双门限端点检测法。语音信号中的清音过零率较高,利用短时过零率来检测,浊音短时能量较大,利用短时能量来检测。此方法之所以称为双门限端点检测法,其原因是该方法分别为短时能量和短时过零率确定了两个门限,较低的门限数值较小,对语音信号的变化较为敏感,较容易被超过;较高的门限数值较大。虽然背景噪声有可能超过低门限值,但因为背景噪声是随机噪声,不可能长时间超过低门限值,因此通过双门限的办法可以有效检测出含有语义信息的语音段。
第3章 语音识别技术
语音识别技术主要分为两个部分:提取语音特征参数和模式匹配算法。语音特征参数是每段语音信号独特的特点,将输入语音信号的特征参数提取出来并利用模式匹配算法与已知语音模版库中的特征参数进行匹配,得到最佳的语音识别结果。
3.1特征参数的提取
语音信号的特征参数一般分为两类:时域特征参数与频域特征参数。时域特征参数是利用时域语音信号特点直接生成特征参数。频域特征参数是将时域语音信号变换到频域后,对频域内的信号进行处理并生成特征参数。在语音参数提取时,需要将区分度高、计算量小、独立性强的语音特征参数作为优先选择对象。因为频域特性参数的优势较时域特征参数更为突出,所以在目前的智能对话领域比较常用。
3.1.1 时域特征参数的提取
短时能量、基音周期和短时过零率作为语音信号时域特征参数中最主要的三个特征参数[[5]],在智能对话技术中占有较为重要的地位。在上一章中,本文已经对短时能量和短时过零率作了较为详细的介绍,因此在这主要介绍以下基音周期。想要了解基音周期首先就要明白基音是什么,基音是人们在发出浊音时声带的周期性振动。因此声带振动频率的倒数就是基音周期[[6]]。因为基音周期并不具备严格的周期性,只有准周期性,所以基音周期只能通过平均法进行估计。估计基音周期就是基音周期检测。基音周期检测的方法主要有三种:变化域法、波形估计法和相关处理法。
3.1.2 频域特征参数的提取
因为线性预测系数(LPC)、线性预测倒谱系数(LPCC)和梅尔频率倒谱系数(MFCC)具有不同的特点,作为语音信号频域特征参数各具优势,所以运用领域十分广泛。在此主要介绍一下梅尔频率倒谱系数。
梅尔频率倒谱系数是最常用的语音特征参数,这种参数符合人耳的听觉特征。人的听觉系统对不同频率语音信号的感受程度不同,对于频率在1kHz以内的语音信号,听觉系统的感知能力随着频率的增长而增强,增幅比例几乎不变,因而是线性系统,而对于频率超过1kHz的语音信号,听觉系统的感知能力与随着频率的增长增速逐渐降低,大体上成对数关系,因此人的听觉系统是非线性系统。大量实验表明,相比于线性预测参数和线性预测倒谱参数,梅尔频率倒谱参数可以增强智能对话系统的感知能力。梅尔频率与普通频率的关系如图3.1所示。
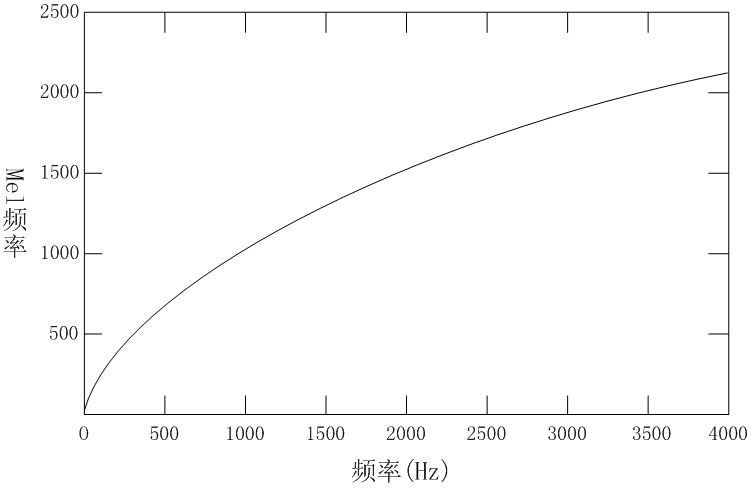 图3.1 梅尔频率与普通频率的关系
图3.1 梅尔频率与普通频率的关系
梅尔频率倒谱系数的求解过程包括一下几个步骤:
- 预加重:利用高通滤波器对语音信号进行滤波处理,滤波器函数定义为:
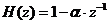 (3.1)
(3.1)



