基于Tensorflow的Faster R-CNN目标检测算法设计毕业论文
2020-02-17 22:20:45
摘 要
目标检测的目的是判断图像中是否有感兴趣的目标,如果存在则从中提取出该目标,然后估计其空间位置、覆盖范围、形状和类别等特性。本文利用TensorFlow作为实验框架,选取VGG16特征提取模型,构建Faster R-CNN算法框架, 并完成了在VOC数据集和COCO数据集上的训练。
实验中对训练过程和测试过程分别进行了参数调优。根据训练和测试过程中的相应效果进行参数调整,不断优化直至满意效果。设计了一个断点续训的功能,即可以设置从上次训练保存的文件开始继续进行训练。除此以外,还设计了一个批量测试函数,然后让测试结果图自动保存。又在原来一张结果图只显示一个类别的检测结果的基础上,改成了一次性框出图上的所有类别及相应的检测得分。
为进一步分析本文中搭建的Faster R-CNN框架的训练测试结果的优劣,用API在COCO数据集上检测训练效果。分别测试了Faster R-CNN ResNet101、Faster R-CNN Inception_ ResNet、SSD MobileNet。
实验得到了很高的检测精度,且API的对比实验证明本文使用的Faster R-CNN算法本身精确度可以达到更优,精确度方面可以进一步优化。
关键词:目标检测,卷积神经网络,Faster R-CNN,TensorFlow
Abstract
The purpose of object detection is to determine whether there is an interesting target in the image, and if there is, extract the object, and then estimate its spatial position, coverage, shape, category and other characteristics. This paper uses TensorFlow as the experimental framework, selects the VGG16 feature extraction model, constructs the Faster R-CNN algorithm framework, and completes the training on VOC dataset and COCO dataset.
In the experiment, the parameters of the training process and the testing process are optimized respectively. The parameters are adjusted according to the corresponding effects in the training and testing process, and the parameters are optimized continuously until the satisfactory effect is obtained. A breakpoint continuation function is designed, that is, it can set up to continue the training from the file saved in the last training. In addition, a batch test function is designed, and then the test result diagram is saved automatically. On the basis of showing only one category of test results in the original result chart, it is changed to frame all the categories on the diagram and the corresponding test scores at one time.
In order to further analyze the advantages and disadvantages of the training and testing results of the Faster R-CNN framework built in this paper, API is used to test the training effect on the COCO dataset. Faster R-CNN ResNet101, Faster R-CNN Inception_ResNet and SSD MobileNet were tested respectively.
The experimental results show that the detection accuracy is very high, and the comparative experiments of API show that the accuracy of the Faster R-CNN algorithm used in this paper can be better, and the accuracy can be further optimized.
Keywords:object detection,Convolution neural network,Faster R-CNN,TensorFlow
目 录
目 录 1
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外发展现状 2
1.2.1 非神经网络算法 2
1.2.2 神经网络算法 2
1.3 本文研究内容与结构安排 4
第2章 相关算法基础 5
2.1 传统非神经网络算法 5
2.1.1 特征提取算法SIFT 5
2.1.2 分类器SVM 6
2.2 卷积神经网络结构与运算 8
2.3 卷积神经网络模型 10
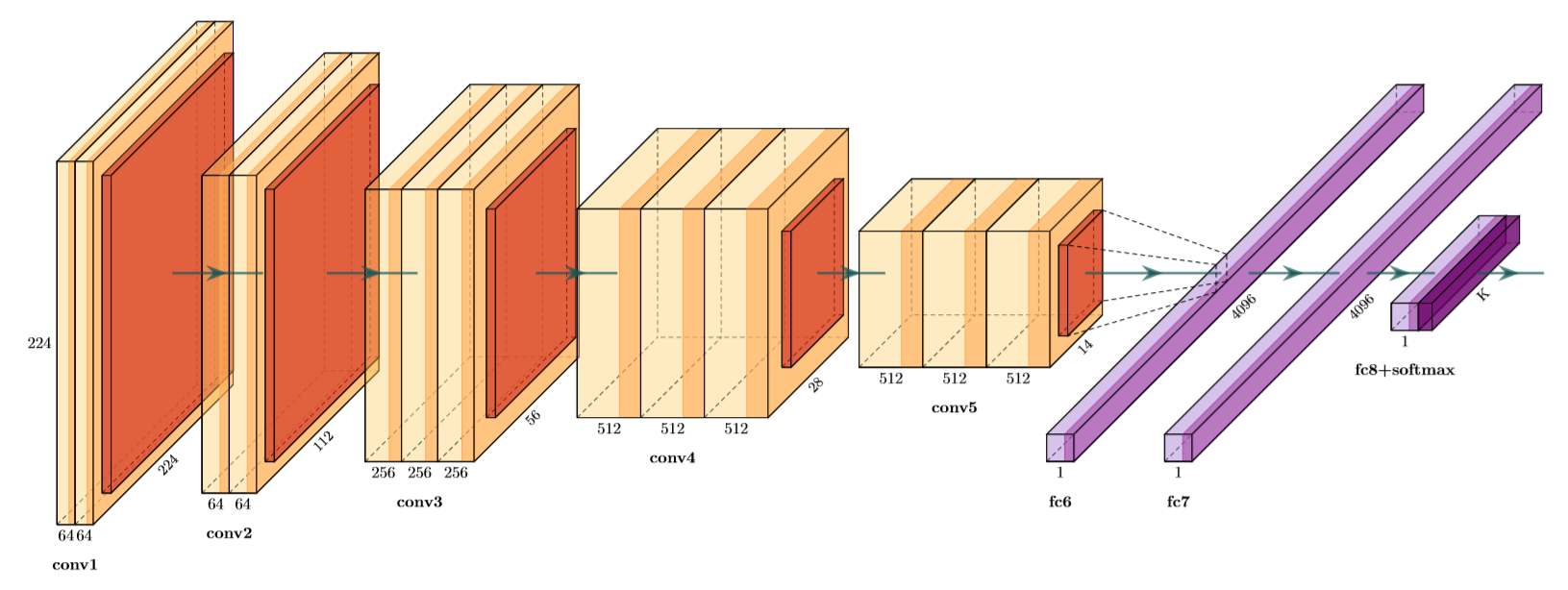
2.3.1 VGG16 10
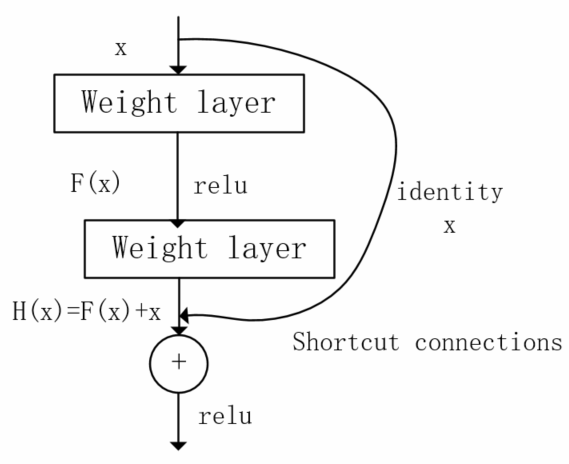
2.3.2 ResNet 11
2.4 本章小结 12
第3章 基于Faster R-CNN目标检测算法 13
3.1 框架对比选择 13
3.1.1 Caffe 13
3.1.2 TensorFlow 14
3.2 数据集选择 14
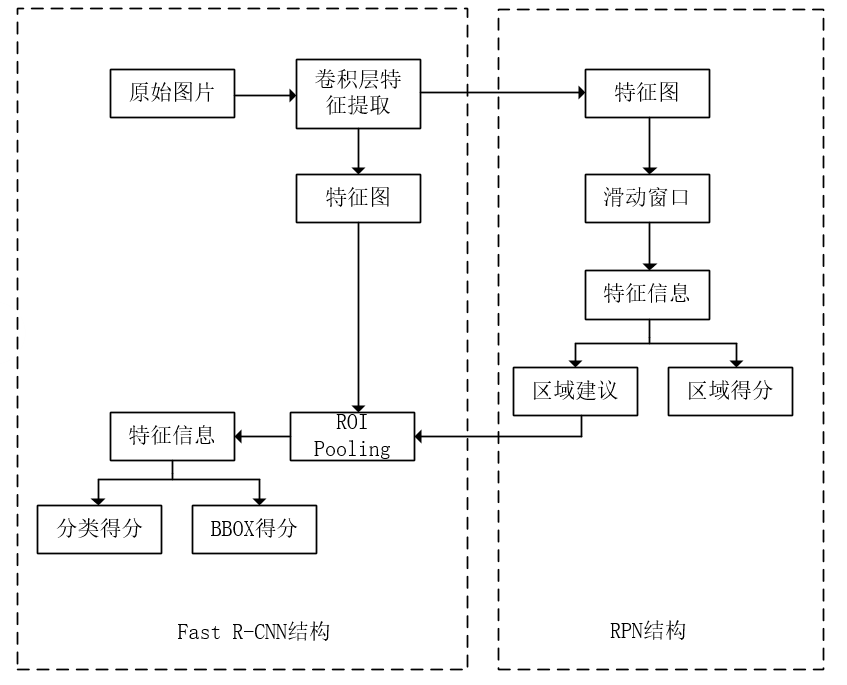
3.3 Faster R-CNN算法的结构原理 15
3.3.1 整体结构 16
3.3.2 RPN网络 16
3.4 本章小结 18
第4章 实验结果分析 19
4.1 实验软硬件环境 19
4.2 实验设计及结果分析 20
4.2.1 实验流程 20
4.2.2 训练及参数调整优化 20
4.2.3 测试结果 22
4.3 API测试结果 25
4.4 本章小结 26
第5章 总结与展望 27
5.1 总结 27
5.2 展望 28
参考文献 29
致谢 31
绪论
研究背景及意义
独特的视觉器官构造使得人类很容易看清并理解眼前的世界,但是计算机要做到这一点,却显得尤为不易。人工智能技术的飞速发展迫切地需要计算机来辅助人类处理各类视觉相关的任务,甚至代替人类的视觉感知过程,进而创建起一个能够从海量数据中提取所需信息的人工智能系统。
在计算机视觉领域的研究中,目标检测既是的一个经典挑战,也是一个重要目标。目标检测的目的是判断图像中是否有感兴趣的目标,如果存在则从中提取出该目标,然后估计其空间位置、覆盖范围、形状和类别等特性。作为图像分析和计算机视觉的基础,目标检测能帮助解决更为繁杂的视觉任务,如语义分割、目标跟踪、图像描述、事件检测和识别等。它能够提供精确和及时的信息,因此在人工智能等许多领域都有广泛的应用前景。
目标检测在实现农业机械自动化过程中可应用于果实采摘识别、植株病害识别等[1];在医学图像分析上的运用有医学图像的分类、定位病变部位等[2];在人机交互方面,可以识别人的肢体动作、面部表情进而操作机器;还可以对行人和交通工具进行行为监测,规范交通秩序,降低安全隐患。
目标检测应用之广促使众学者们纷纷参与到它的研究开发中来。然而,从定位和识别的精度考虑:一方面要提高面对成千上万结构化和非结构化的不同类实际目标时的鲁棒性,另一方面要提高面对类内差异的鲁棒性,因为即使是同一类目标在颜色、质地、材料、形状等方面也存在差异。而现实环境中不同程度的光照、遮挡,不同的视角、比例,还有一系列的干扰如成像噪声、滤波器畸变、压缩噪声等都对目标检测的精度提出了挑战。从效率考虑,如何提高检测的时间效率、内存效率、存储效率,也是亟待探索的方向。
Hinton等人提出的深度学习概念迎来了人工智能领域的又一个春天,在图像识别、目标检测等领域展现出里程碑式的进步[3]。深度学习所带来的研究方向,已经运用到目标检测领域并获得了一定的成效,未来也将随着理论知识的深入而不断进步。
本文结合现有的深度学习发展状况,研究目标检测算法中的一种主要倾向——Faster R-CNN(Faster Region-Based Convolutional Neural Networks)算法,该算法是卷积神经网络中一个非常重要且非常成功的通用目标检测框架,在最近目标检测方面的一系列进展通常遵循这一研究路线。目标检测现已逐步扩展应用到各行各业,因此对该课题的研究极具现实意义和价值。
国内外发展现状
目标检测的研究最早可以追溯到1960年,经历了近六十年的研究,从只针对单一特定目标进行检测,到开始构建通用目标检测系统,检测精度和速度也越来越贴近人眼所达到的水平。在这一部分中,简要介绍了现存目标检测方面的工作。考虑到深度学习方法在目标检测中的突出性能,本文将现有的工作简单地分为基于非神经网络的算法和基于神经网络的算法。
非神经网络算法
以往的非神经网络目标检测算法是在目标特征提取基础上的分类算法。早期的目标检测通过提取全局特征来对图像进行描述,主要采用的是几何特征的检测方法。匹配识别系统SCERPO[4]、哈希法(hashing)等几何特征检测方法都具有对仿射的不变性。但这类方法只关注目标的几何轮廓,只能应用于检测某类外形一致的目标。一旦背景发生变化或目标被遮挡,检测效果就会产生很大的影响,而且对于真实世界中存在的成千上万外形不定的目标,这种算法显然是不够的。
针对这些缺点,基于局部特征的算法开始发展起来,该概念最早由Schmid等人提出[5]。其基本流程分为检测特征点和表示描述子。T.Ojala等提出局部二值模式(Local Binary Pattern,LBP),可用于表述图像的局部特征,特征提取简易且对光照变化是稳健的[6]。有向梯度直方图(Histogram of Oriented Gradient,HOG)可以统计像素点方向等信息[6][7]。LBP和HOG都省略了特征点检测,只有描述子提取的过程,不同的是,LBP在整个图像内,而HOG是在滑动窗口内,均匀地去特征点。1999年,Lowe提出尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[8],2004年又对之前的算法做出改进。之后在此方法的基础上又衍生出了许多改进算法,如2006年的ECCV大会上所发表的加速增强特征(Speeded Up Robust Features,SURF)[9],灵感便是来自SIFT算法。
分类器通常是线性的支持向量机(Support Vector Machine,SVM)[10]、非线性的Adaboost(Adaptive Boosting)分类器[11]以及加性核支持向量机[12]等。其中SVM分类器在理论和应用中都有尤其出色的表现。
神经网络算法
以前对目标检测的研究工作,不论出现了多少改进和优化算法,都还是采取的手工设计特征的方法。这种方法极大地发展了目标检测领域,但是其建模及表示能力却无法进一步应对更加复杂的图像。
近年来,目标检测技术在深度学习中的应用取得了显著成效。与传统的非神经网络算法不一样的是,深度学习借鉴了人类大脑的神经结构,将信息经过了多层次的变化,可以自主学习并将输入端的内容直接送给输出端,避免了对图像进行繁杂的前期处理,且不依赖于专业的手工设计特征,因此性能得到了很大提升。
总结而言,目前基于神经网络的目标检测框架主要分为两类,一类是两步式检测框架,包括计算候选区域和特征提取两个步骤;另一类是一步式检测框架,即没有对候选区域的预处理步骤,这是一种基于回归的方法。两类算法各有其优势,前者对复杂的多物体重叠图像检测精度相对更高,后者则侧重于检测的实时性。
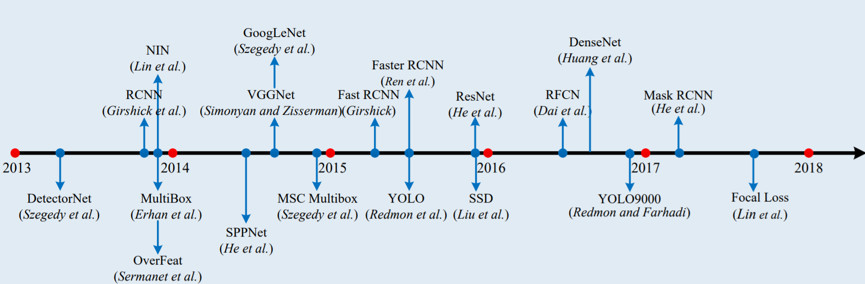 总结了深度学习进入目标检测领域后出现的里程碑式的检测框架,如图1.1所示[13]。
总结了深度学习进入目标检测领域后出现的里程碑式的检测框架,如图1.1所示[13]。
图1.1 深度学习进入目标检测领域后的里程碑
2013年Ross B. Girshick提出的R-CNN算法算得上是卷积神经网络应用于目标检测的开山之作,而后抛砖引玉,在此基础上衍生出一系列的算法。何恺明团队提出了SPP Net,Ross B. Girshick在R-CNN算法上优化出Fast R-CNN,何恺明团队和Ross B. Girshick一起研究出Faster R-CNN,任少卿提出Region Proposal Networks,让网络自主学习形成候选区域。Mask R-CNN 则是进一步提升了检测精度,同时还能应用到语义分割领域。
以上算法都属于两步式检测框架,在检测速度上还存在一定缺陷,针对实时目标检测,提出了一步式检测框架算法,如YOLO(You Only Look Once)算法,但该算法对小物体的检测效果不理想。SSD算法是在YOLO的基础上加入了Faster R-CNN的Anchor的概念,很好地提升了检测的精度。除此以外,还有 RRC detection、Deformable CNN等也都属于单级式检测框架算法。
本文研究内容与结构安排
本文主要研究了一种基于神经网络的目标检测算法——Faster R-CNN,并选取深度学习框架TensorFlow在公开的COCO数据集上进行训练,然后进行目标检测,得到图像的中目标的位置、类别和精确度等信息。
本文主要结构如下:
第一章主要介绍了目标检测的背景及意义,目标检测可以应用的领域和目标检测需要解决的问题。然后从非神经网络算法和神经网络算法两个角度介绍了目标检测的国内外发展的现状。
第二章有详有略地介绍了传统的非神经网络算法和卷积神经网络算法及其优缺点。其中重点描述了传统的非神经网络算法中的特征提取算法SIFT和分类器SVM,卷积神经网络中的前向传播、反向传播方式,以及典型卷积神经网络的层次。最后介绍了卷积神经网络的模型中的VGG16和ResNet模型。
第三章先对实验设计中两种有代表性的深度学习框架:TensorFlow、Caffe进行了比较分析和特点描述。相比于Caffe,TensorFlow更加成熟,功能更加强大,且资源更丰富,故选择TensorFlow框架作为实验框架。然后简要介绍了实验中使用的两个数据集,VOC2007数据集和COCO数据集。最后分析了Faster R-CNN算法的结构和原理,描述了整体的算法思路和RPN网络原理。
第四章先介绍了实验的软硬件环境,然后描述了实验的设计流程,训练过程及参数调整优化过程,然后调整优化了测试参数,展示了在COCO数据集和VOC数据集上的检测图。最后用Google object_detection API在COCO数据集上检测训练效果,对比分析所搭建的Faster R-CNN框架的训练及测试结果的优劣。
第五章对本文的所有研究内容做出全方位的总结,对比用到的方法,得出相应结论。并找出可以改进的地方,进一步得出下一步的研究目标。
相关算法基础
本章节旨在通过介绍现存的主要目标检测算法,为后文选用的算法框架做好理论知识准备。详略分明地介绍了传统的非神经网络算法和卷积神经网络算法及其优缺点,其中详述卷积神经网络的结构运算和模型及其原理。
传统非神经网络算法
传统的目标检测算法注重特征提取和分类器的研究。在特征提取和分类之前,一般先采用候选框或滑动窗口进行区域选择,得到可能存在目标的区域。然后对完成该区域的特征提取,最后通过分类器对其进行分类。特征提取模块是一个人工设计的模块,常用的描述图像特征的算法有LBP、HOG、SIFT等。分类器通常采用Adaboost 、SVM等。
接下来将对特征提取算法SIFT和分类器SVM进行着重描述。
特征提取算法SIFT
图像是由像素矩阵构成,特征提取就是要在图像的像素矩阵中找到有判别力的视觉特征。SIFT先检测图像中具有显著特征的像素点,然后以这些特征点为中心,计算得到的特征向量维度为128。而图像无论是缩放、平移还是旋转,该特征向量都保持其固有值。光照、仿射的变化对特征向量也几乎没有影响。因此,SIFT算法是非常优秀的特征提取算法之一,在现实目标检测中也发挥出很高的水平。
SIFT算法的基本流程分为检测特征点和表示描述子两步。在连续的尺度空间下位置不变的点即是需要的特征点,故需要创建尺度空间,通过连续尺度变换找出稳定点。尺度空间内核是高斯函数,假设(x,y)表示图像像素点的位置,I(x,y)表示原图像,G(x,y,σ)表示高斯函数,则该图像的尺度空间可以定义为原始图像和高斯函数的卷积,定义式如下:
| (2.1) |
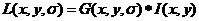
式中的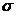 为高斯函数中的方差,该式中表示尺度空间,值的大小与图像清晰度成反比。其中高斯函数
为高斯函数中的方差,该式中表示尺度空间,值的大小与图像清晰度成反比。其中高斯函数 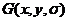 的具体定义如下:
的具体定义如下:
| (2.2) |
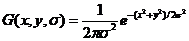
用高斯差分(Difference of Gaussians,DoG),找出稳定的极值,其定义如下式:
| (2.3) |
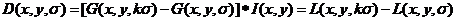
式中的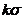 和是连续的尺度,两个连续尺度空间中的图像相减,再将结果存入高斯金字塔。DOG与高斯拉普拉斯算子(Laplacian of Gauss,LOG)相近似,而算法复杂度又比LOG低。
和是连续的尺度,两个连续尺度空间中的图像相减,再将结果存入高斯金字塔。DOG与高斯拉普拉斯算子(Laplacian of Gauss,LOG)相近似,而算法复杂度又比LOG低。
高斯金字塔的产生过程如下:设输入图像的尺度为0.5,极值检测需要的层数为s,则每组金字塔的层数为s 3层。通过高斯模糊得到0组0层的图像,设该层尺度为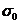 ,然后以
,然后以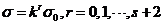 的规律类推下去得到其他层的尺度,构建出第0组。然后对第i-1组图像中倒数第3层的图像下采样可以得出第i组第0层图像,然后依据上述方式继续递推第i组其余层的图像。最终得到全部图像。
的规律类推下去得到其他层的尺度,构建出第0组。然后对第i-1组图像中倒数第3层的图像下采样可以得出第i组第0层图像,然后依据上述方式继续递推第i组其余层的图像。最终得到全部图像。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: