互联网运营类岗位需求与人才特征数据分析——以拉勾网为例毕业论文
2020-02-19 20:10:03
摘 要
现在求职热门领域在哪里?毫无疑问是互联网行业。相较于互联网其他岗位,互联网运营是很多非计算机专业出身的求职者进入互联网行业的优选。然而虽然运营的进入门槛较低,但是企业还是会有自己的用人维度和需求,如何把握运营类求职的市场需求标准,找准自己求职方向是本论文想讨论、研究和解决的问题。
本论文选取垂直互联网招聘的拉勾网为数据源,通过网络爬虫采集招聘文本信息,选取市场需求比较大的五大类运营岗位为研究对象,利用自然语言处理技术构建运营类岗位招聘词典,对运营类岗位的技能维度需求特征进行分析,并进行对比分析、技能相关性分析、关联分析,了解市场对运营类岗位人才的需求情况和招聘要求。
此外,针对分析结果,设计“运营求职机器人”,将求职者技能和岗位需求特征进行匹配。为有意愿到运营类方向岗位发展的求职者提供求职运营岗位方向指导,将分析结果应用到实际。
关键词:运营类岗位;互联网行业;岗位需求特征;
Abstract
Where are the hot areas these days? The Internet industry, no doubt. Compared with other positions on the Internet, Internet operation is the preferred choice for many non-computer majors to enter the Internet industry. However, although the entry threshold of operation is relatively low, enterprises still have their own employment dimensions and needs. How to grasp the market demand standard of operation job hunting and find their own job hunting direction are the problems this paper wants to discuss, study and solve.
This paper takes the vertical pull hook of Internet recruitment network data sources, through collecting web crawler for text messages, select the market demand is larger the five types of operation jobs as the research object, using natural language processing technology to build operating positions recruiting dictionary, skills dimension for the operating positions demand characteristics were analyzed, and the skills and comparison analysis, correlation analysis, correlation analysis, to understand the needs of the market for operating positions talent and recruitment requirements.
In addition, based on the analysis results, a "job-hunting robot" is designed to match job seekers' skills with the characteristics of job requirements. Provide guidance for job seekers who are willing to work in operational positions, and apply the analysis results to practice.
Key Words:Operation position;Internet industry;Job demand characteristics
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.1.1 研究背景 1
1.1.2 研究意义 1
1.2 国内外研究现状 2
1.3 研究内容及技术路线 3
1.3.1 研究内容 3
1.3.2 研究思路和技术路线 3
1.4 研究方法 3
第2章 理论基础 5
2.1 网络招聘概述 5
2.2 Web文本挖掘技术与模型研究 5
2.2.1 中文分词技术 5
2.2.2 TF-IDF算法 6
2.2.3 TextRank算法 6
第3章 招聘信息的采集和预处理 8
3.1 数据来源 8
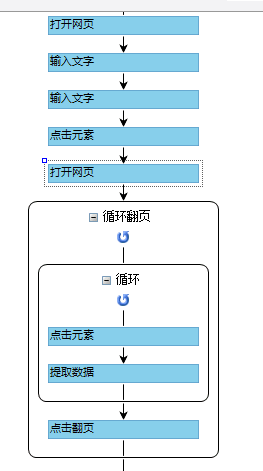
3.2 网络文本采集 9
3.2.1 网络文本提取 9
3.2.2 数据采集 11
3.3 招聘信息的预处理 11
3.3.1 数据简单处理 11
3.3.2 中文分词、去停用词 12
3.4 网站运营类岗位招聘信息词典 13
3.4.1 运营类岗位招聘词典类目构建 13
3.4.2 运营类岗位招聘词典构建 14
3.5 分析方法准确性 15
第4章 互联网运营类岗位招聘信息需求特征分析 16
4.1 整体情况 16
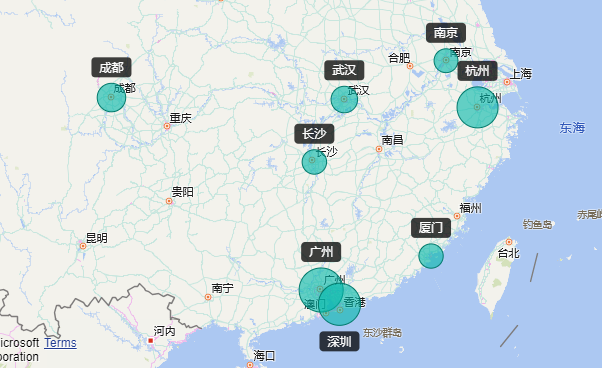
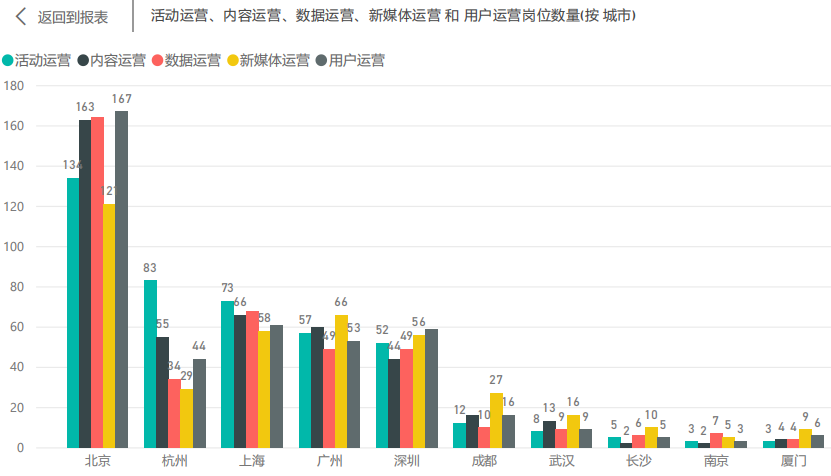
4.1.1 岗位城市分布情况 16
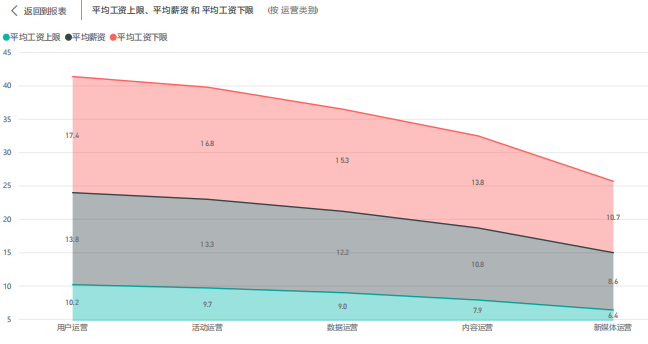
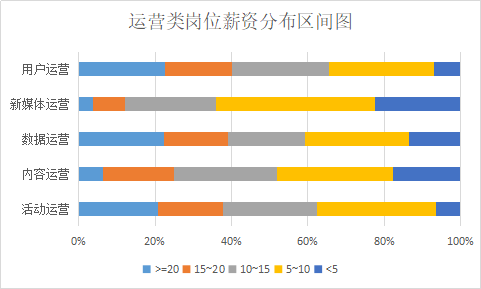
4.1.2 岗位薪资 17
4.1.3 运营类岗位公司发展情况、领域分布情况 18
4.1.4 学历要求 18
4.1.5 专业要求 19
4.1.6 工作经验 20
4.1.7 人员性格素质要求 21
4.2 互联网运营岗位招聘信息需求特征分析 22
4.2.1 岗位技能要求总体分析 22
4.2.2 岗位相关性分析 24
4.3 岗位核心技能关联规则分析 27
4.4 岗位与求职者需求关联匹配 30
4.4.1 开发平台 30
4.4.2 功能介绍 30
第5章 结论与不足 33
5.1 结论 33
5.1.1 工作量总结 33
5.1.2 运营类岗位需求特征总结 33
5.2 创新点 34
5.3 不足 34
参考文献 35
致 谢 37
第1章 绪论
1.1 研究背景及意义
1.1.1 研究背景
随着互联网在各行业的不断渗透,大数据、人工智能的兴起,互联网行业和泛互联网行业的热门和高薪吸引了大批人才的涌入。根据拉勾网2017年发布数据,2017年互联网行业求职人数较2016年增加六倍,互联网行业从业人员持续增加。
而互联网行业中门槛相对比较低的工作就是运营了。中国互联网发展至今,由于本土文化影响,也走出了一条不同于美国互联网的创新发展之路。而互联网运营这一职位的出现,应该是中国互联网和国外的最大不同之一。相较于互联网开发人员和产品人员,运营不需要太多技术的积累,成为了很多人想迈入互联网的敲门砖。而最近几年,随着互联网行业的飞速发展,互联网产品的竞争日益加剧,产品同质化越来越严重,运营的重要性开始得到重视。人潮也越来越多往运营岗位涌入,互联网运营也成为很多信管学生会选择的就业岗位方向。但这也导致运营类岗位出现僧多粥少,竞争剧烈的局面,如何准确把握运营类岗位特征,正确选择择业方向成为一个重点问题。
另方面,随着信息的高度互联网化,网络成为信息传播的高效渠道,在求职信息发布,人才需求咨询更新等方面更是承担着一定的意义。和传统招聘方式不同,通过互联网招聘人才,让企业节约了招聘的人力、物力和财力,同时也让求职者打破了地域的限制,可以及时收集到各地的人才招聘信息,给予应聘者和企业方双向选择的便利。从51JOB、前程无忧、赶集网到专注互联网招聘的拉勾网,互联网招聘可以说现在是世界范围内最主流的招聘形式。因此通过研究网络信息招聘文本可对市场人才需求有一个比较全面准确的的研究。
1.1.2 研究意义
现在是信息的时代,求职不仅是一场个人能力素质的战斗,更是一场信息战。目前越来越多的企业开始采用网络招聘作为招募人才的主要渠道。求职者通过招聘信息可以快速瞄准自己想进入的目标公司。公司可以根据招聘信息要求提高应聘者的面试门槛。通过网络招聘平台,公司结合自身需求对各大岗位做出岗位描述和人才需求描述。收集各大企业的招聘信息,可以归纳出专业人才发展态势和市场需求的趋势。
本研究通过对互联网行业中运营类岗位招聘信息情况进行研究,可以及时收集现互联网运营类岗位的市场特征和需求信息,并可对求职者和招聘者形成有效反馈;其次,对于求职主体而言,本研究可以帮助就业者对目前互联网运营就业形势有更全面的了解,对不同运营岗位的技能要求和特性要求有大体的认识,从而明确自身和职业发展方向,对求职择业、个人技能提升都有一定的指导意义。从各个角度分析来看,本次研究挖掘出的信息对我们的生活、工作都有一定潜在价值。总结说,本研究目标主要为以下三点:
(1)该研究通过收集国内知名互联网求职平台拉勾网上有关互联网运营类岗位招聘的相关信息,统计分析总结了现互联网运营人才的市场需求特点和分布特点,为应聘者求职提供参考;
(2)比较、选择和运用适当的数据挖掘方法对岗位需求能力进行分析,对互联网运营类人才需求进行画像,为求职者针对相关岗位有针对性的进行技能和能力培养提供意见;
(3)建立互联网人才特征挖掘模型,针对求职者个人特征和需求,进行岗位匹配,对择业提出指导。
1.2 国内外研究现状
本次研究针对互联网运营这一类行业进行岗位需求分析,通过建立运营类岗位需求特征模型,对岗位需求进行精准、多维度的深入分析和数据挖掘。对于岗位需求特征模型,国内外的研究其实已经有很多。
传统的研究方式是通过问卷调查、实地调查进行。韩玉以企业生产一线专家型实践者为咨询对象,运用专家预测法对高职数控技术、汽车检测与维修专业毕业生职业核心能力结构进行需求预测[1]。杨甜甜等用座谈会、问卷调查、电话回访的方式,收集了浙中地区网络零售岗位特征,将岗位技能分为基本技能、扩展技能和发展技能[2]。传统的需求调研方法较为成熟,但具有耗时费力、调研面窄等固有缺陷,更加适合小范围的研究。
另一种岗位需求分析的思路就是利用招聘广告进行数据挖掘分析企业对岗位人才的能力需求。网络招聘就业数据已经是现在就业大数据组成中的重要一环。拉勾网、智联招聘、51JOB等招聘网站的出现,企业开始习惯借助网络去传递招聘信息,通过在线招聘网站可更便捷获得岗位数据,并且也更具有代表性。钟利红、邓之宏采用统计分析、析因方差分析和关联规则等数据挖掘方法研究了深圳市电子商务岗位对高职毕业生的岗位核心能力需求[5]。邵兵家,刘晓钢等通过招聘网站发布的网络营销类岗位招聘广告,对我国企业网络营销核心技能特征进行了研究和分析,并对其人才培养提出了相关建议[6]。詹川回顾近年来人才技能需求分析的相关研究,设计一个从非结构化招聘大数据中快速智能挖掘专业技能需求的分析系统,对66925条电商行业招聘信息进行数据分析[7]。相比传统岗位需求调研,网络招聘信息更方便获得信息,并可在大范围内展开需求调研,但由于互联网行业用词的特殊性和多样性,使得文本分析不那么容易展开。并且现在已有的大部分研究仅是为培养、就业提出统括的意见,没有给予针对性的建议。
本研究主要使用第二种办法,通过计算机技术自动处理运营类岗位招聘信息,使数据源更为全面丰富。此外,本研究为更好分析、挖掘运营类人才的是市场需求特征,将结合自然语言处理技术构建运营类岗位招聘词典。在得出市场人才需求特征后,将应用结果,设计程序为求职者提供更为直观的帮助建议。
1.3 研究内容及技术路线
1.3.1 研究内容
(1)设计运营运营类岗位多维度的岗位特征模型。通过学习现今国内外关于人才特征模型构建的方法和模型,设计适用于本论文的运营类招聘信息模型;
(2)构建运营岗位多维度特征模型。采集拉勾网上的运营类岗位招聘文本信息,分析结果,将数据进行处理,对中文文本进行自然语言处理,文本聚类,提取出岗位技能维度关键词;
(3)依托(1)计划实施的模型,从不同角度,对运营类岗位招聘文本进行分析、建模,并用可视化方式进行展示;
(4)在分析建模的基础上,将结果运用于实践,针对求职者设计简单的“运营类求职机器人”,将求职者和岗位进行简单匹配;
(5)总结运营类五大岗位需求特征模型后,对本研究的创新和不足之处进行阐释,希望在之后的学习研究中进一步加强完善。
1.3.2 研究思路和技术路线
对该课题的研究拟分为以下5个阶段:研究目标、数据的采集、数据预处理、构建运营类岗位招聘词典、数据分析、人才匹配。技术路线如图1.1。
1.4 研究方法
(1)文献分析法
在确定课题的基础上,了解一般招聘组成和架构,以及相关文献研究,通过学习相关文献的研究内容、研究方法、研究路线和成果等,确定本研究将采取的研究主题、方法和路线。
(2)频数分析法
在采用某种标准分类数据后,对各组中含每组标志值的个体数进行统计。频数越大,表明标志值对于总体的作用就越大。本研究将构建岗位技能维度表统计各个岗位维度下不同关键词的频次,表明该该关键词对于岗位的重要性。
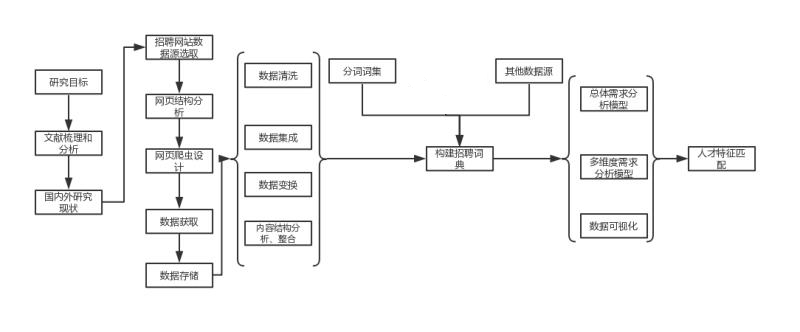
图1.1 技术路线图
(3)关联分析
关联分析法是在数据集中找出数据之间潜在的关系。关联规则则表明两个事物之间可能存在比较强的关系。在本研究中,采用关联规则分析方法来挖掘互联网企业发布的运营类岗位招聘信息中同时关注的各类技能。
第2章 理论基础
2.1 网络招聘概述
网络招聘,又名电子招聘,是指企业的人力资源部门利用互联网中企业自身网站或者招聘网站平台发布相关的招聘信息,通过对求职者投递的简历以及电话咨询,进行初步筛选应聘者的招聘程序。网络招聘起源于美国,目前已成为很多发达国家或地区人才招聘的主要方式[9]。网络招聘的优势在于:
- 成本低。通过网络进行招聘可以有效节约企业的招聘成本,不需要企业来往奔波于人才市场、招聘会,只要通过网站在线发布信息即可,且大多数招聘网站发布招聘信息是免费的;
- 效率。招聘企业通过互联网可向全国求职者发送招聘信息,并且通过网站,就可以清楚描述岗位职责、招聘需求,不需要重复向招聘者介绍。此外,现在招聘网站一般都有检索功能,求职者根据自己的需求就能最快匹配适合自己的岗位。网络招聘一定程度上提高了招聘双方的效率。
但是网络招聘也有劣势,主要体现在招聘虚假信息过多和招聘信息文本处理难度大。网站面对各类招聘岗位信息,无法保证其真实性。很多招聘信息发布放并未进行实名制度,部分企业借之发布虚假信息,更有甚者,借之收集求职者信息。招聘信息文本处理难度大,一方面对于求职者来说,企业在互联网上发布简历,因为网站的信息规则设置,如果没有准确填写对应信息文本,在规定信息展示版块填写了其他信息,则会使求职者会产生一定误解。另方面对于企业方来说,因为企业描述招聘信息和招聘者理解招聘信息会有偏差,可能由于对职位的理解偏差,就投递了简历,而企业方面们面对大量简历,部分还是无效简历,也无暇应付。
2.2 Web文本挖掘技术与模型研究
2.2.1 中文分词技术
中文分词简单来说,就是通过计算机分词算法,将句子分解成有用的词语。中文相对其他语言来说,更为难以处理。中文分词不像英文那样,天然有空格作为分隔。而且中文词语组合繁多,一个中文词在不同的句子情境下经常会有不同的意思,甚至连词性都会有所不同。用计算机来对中文进行分词,来理解中文,是比较困难的。切分歧义和未登录新词是中文分词过程中,遇到的最难解决的两个问题。
歧义,简单说就是同一句话可以有很多种分词结果,在计算机逻辑中都成立。比如,土包子,“土包”和“包子”都是词,很有可能机器会把这个词分为“土包 子”和“土 包子”。这样就构成了歧义。再谈谈新词识别。新词就是那些在既有词典中没有收录过的词,也叫做未登录词,但是这些词又是约定俗成,不可分割的词汇,一旦分割可能就会造成语义曲解。新词主要有以下几种类型:
- 新出现的词汇,比如一些新出现的网络热词,像“大碗宽面”等;
- 专业名词和研究领域,像“九价疫苗”;
- 其他专有名词,比如一些书名,人名、地名等的收录。
分词词典的收录单词是有限的,而世界上新词的量是不可计数的,并且很多新词都是由普通词汇构成,长度不定,也没有明显的边界标志词,还有可能与上下文中的其他词汇构成交集型歧义,甚至夹杂着英语字母等其他符号,都在分词过程中造成困难。
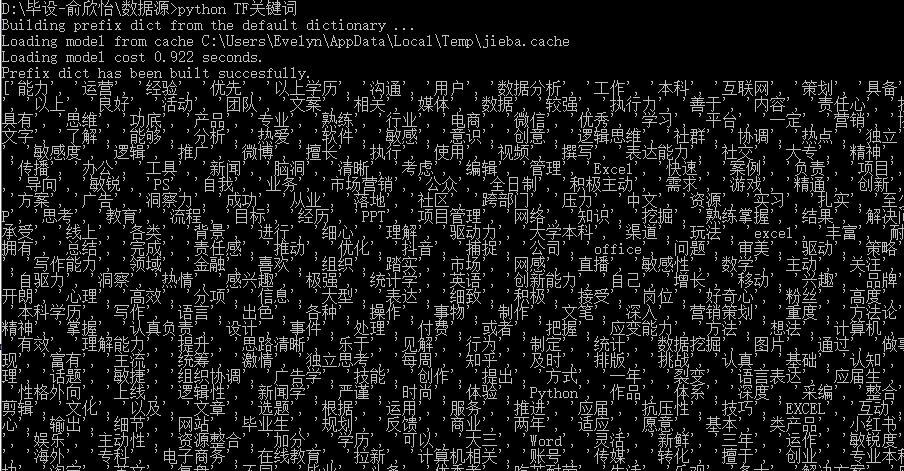
2.2.2 TF-IDF算法
TF-IDF算法是通过计算词频,给每个字或词语配比一个重要性权重,从而评估其语料库中的重要程度。它的评价指标有:(1)词频(TF);(2)逆文档率(IDF)。
词频(TF),是字词在文件中出现的次数。词频越高,则说明该字词在文档中越重要。为了方便在不同文章中进行比较,需要进行标准化处理,公式为2.1。
 (2.1)
(2.1)
逆文档率(IDF),是字词在语料库文档中出现的频率的对数,若一个词在语料库中是常见的词则给予较小的权重,若是不常见的词则基于较大的权重,公式为2.2。
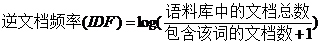 (2.2)
(2.2)
如果一个词比较少见(IDF大),但是它在文章中的词频比较高(TF大),那么这个词很有可能是我们需要的关键词,体现了这个词对文章的重要性,关键程度则可以用TF-IDF值表示。TF-IDF值排在前面的几个词即为文章的关键词。
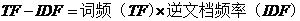 (2.3)
(2.3)
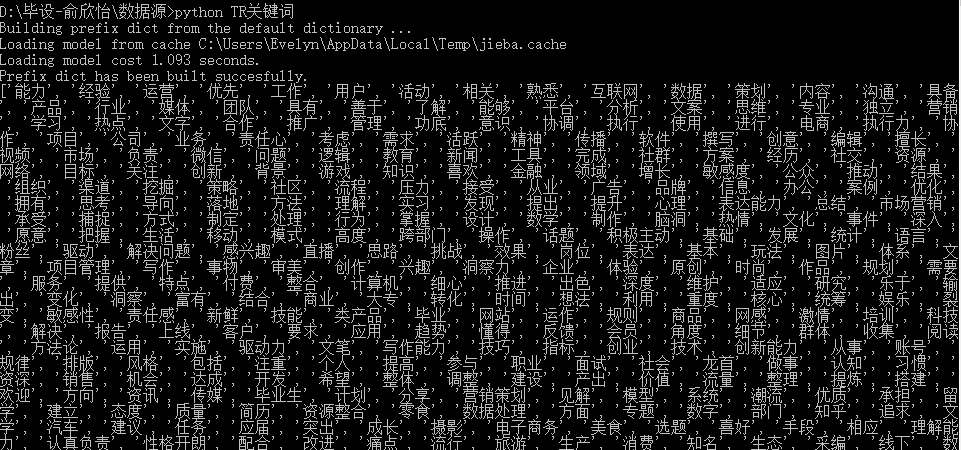
2.2.3 TextRank算法
TextRank算法首先将原文拆分为单句,对每个文句分词和标注词性,过滤停用词,即可得到指定词性的字词集合。算法可设定需保留的词性的单词。TextRank算法来源于PageRank算法,对文本中的重要成分进行排序,构建保留字词图G:
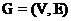 (2.4)
(2.4)
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: