基于SVM的股票指数开盘指数预测及变化趋势分析——以上证指数为例毕业论文
2020-02-19 20:11:14
摘 要
1979年美国L.A.Zadeh教授提出的信息粒与1995年Vapnik等人提出的支持向量机扩宽了数据挖掘领域的研究范围,直到现在,不管是信息粒化还是支持向量机都一直在数据挖掘领域的研究中有着持续的热度,表现出重要的理论与实际应用价值。
股票预测对于投资决策是不可缺少的一步,尽管股票数据波动频繁,难以预测,但是经过前人的不断探索,将支持向量机擅长预测非线性数据的特性用于股票预测之中,最终得到了较好的模型拟合结果。但是传统支持向量机只能对未来一天的股票指数进行预测,这样的预测结果对投资并没有什么参考价值。为了预测未来一段时间里股票指数的变化趋势与变化范围,本文利用模糊粒子描述股票原始数据,从而预测出未来多天股票指数的上界、中值与下界。
本次研究使用matlab进行数据分析,在建模上文章前部分对影响支持向量机的核函数与参数进行讨论,得出径向基核函数为最佳的核函数。为了优化模型,在后部分将不同自变量与隶属函数组成混合模型,讨论出最佳的组合为:以上一个窗口六个股票指数指标为的模糊粒子自变量,以非对称抛物线型隶属函数为模糊粒化的隶属函数。最后将传统支持向量机与基于模糊信息粒化的支持向量机进行比较,提出股票分析的建议。
关键词: 支持向量机;模糊信息粒化;股价预测;核函数;隶属函数
ABSTRACT
In 1979, the information granule proposed by Professor LAZadeh of the United States and the support vector machine proposed by Vapnik et al. in 1995 widened the research scope of data mining. Until now, both information granulation and support vector machine have been in the field of data mining. The research has sustained enthusiasm and shows important theoretical and practical value.
Stock forecasting is an indispensable step for investment decision-making. Although stock data fluctuates frequently and is difficult to predict, after the continuous exploration of the predecessors, finally find the good model fitting results. However, the traditional support vector machine can only predict the stock index of the next day, and such prediction results have no reference value for investment. In order to predict the trend and variation range of the stock index in the future, this paper uses fuzzy particles to describe the stock raw data, so as to predict the upper, middle and lower bounds of the future multi-day stock index.
In this study, matlab is used for data analysis. The kernel function and parameters affecting the support vector machine are discussed in the previous part, and the radial basis kernel function is the best kernel function. In order to optimize the model, a mixture model of different independent variables and membership functions is composed in the latter part. The best combination is discussed as: the fuzzy particle independent variable of the six stock index indicators in the above window, and the membership function of the fuzzy granulation with the asymmetric parabolic membership function. Finally, the traditional support vector machine is compared with the support vector machine based on fuzzy information granulation, and the suggestion of stock analysis is proposed.
Key Words: Support vector machine; fuzzy information granulation; stock price prediction; kernel function; membership function
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 研究目的 2
1.3 国内外研究现状 2
1.4 主要研究内容与研究方法 4
1.4.1 主要研究内容 4
1.4.2 研究方法与技术路线 5
1.5 预期目标 5
第2章 基于SVM的股价回归预测模型 7
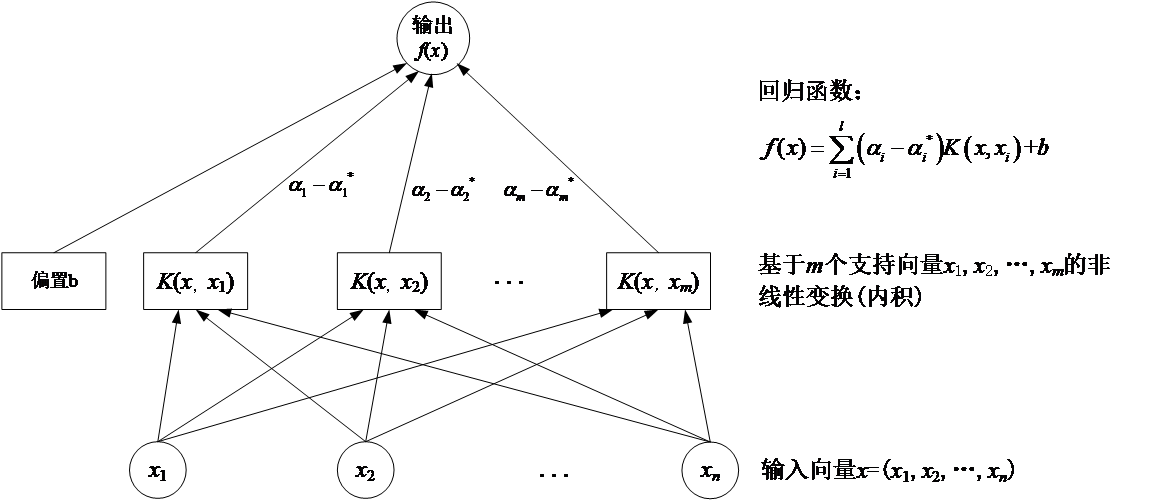
2.1 SVM的基本原理介绍 7
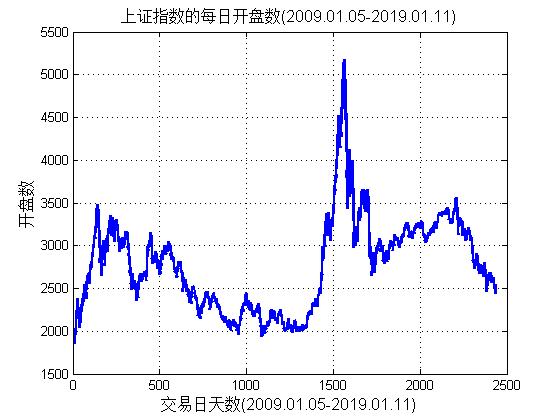
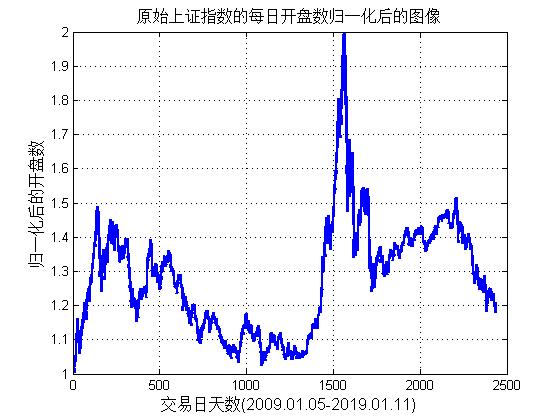
2.2 数据选取与预处理 8
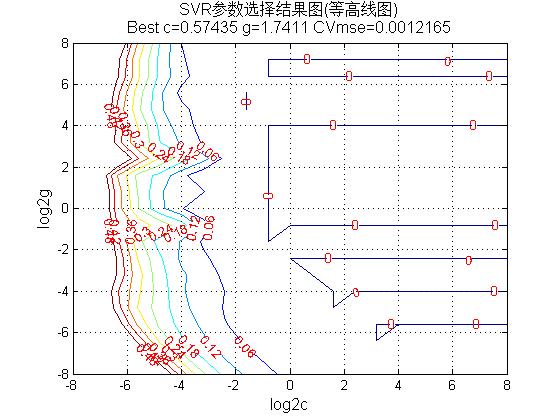
2.3 参数寻优 10
2.4 核函数选择 11
2.5 建立回归模型与实例分析 12
2.5.1 模型构建思路 12
2.5.2 实例分析 13
2.6 本章小结 15
第3章基于信息粒化的趋势预测模型 16
3.1 信息粒化简介 16
3.2 模糊信息粒化方法模型介绍 16
3.3 趋势分析模型优化 18
3.3.1 数据来源 18
3.3.2 模型优化思路 18
3.3.3 实例分析 18
3.4 模型验证 21
3.4.1 数据选取 21
3.4.2 实例分析 21
3.5 本章小结 25
第4章 模型比较分析 26
4.1 两类回归模型比较 26
4.2 股票分析建议 29
4.3 本章小结 29
第5章 总结与展望 30
5.1 论文总结 30
5.2 存在的局限及展望 31
参考文献 33
附 录 35
致 谢 48
第1章 绪论
研究背景与意义
证券市场在金融市场中独占鳌头,通过证券发行和交易的方式实现融资与投资的对接,有效解决资金供需矛盾和资本结构调整,发展到今天,已经成为了金融交易必不可少的渠道。其中股票市场的出现降低了资本的交易成本,并且由于规模经济的存在,大资本的生产成本往往较低,股市可以将大量的小资本聚集到一起,形成大资本,这吸引了大量的投资者。然而众所周知,股票市场兼有高风险与高收益的特征,股票价格的涨跌及变化趋势也一直受到政府和股民大众的密切关注,证券市场的波动性也逐渐成为衡量一个国家经济发展水平的重要指标。随着股票市场的扩大,股票价格预测已经成为当前国际学术界金融证券领域的研究热点。
如今随着互联网技术发展、数据指数式增长以及量化投资的出现,越来越多的投资分析师开始将传统证券投资方法与计算机技术结合,利用计算机分析数据的优势来进行股票交易。在这个过程中涌现了一系列新型的股价预测方法,例如:小波分析、分形理论、神经网络、混沌动力学、支持向量机等等,支持向量机就是其中研究的一个热点。支持向量机是从统计学习理论中衍生出来的,同时基于结构风险最小化原则,在高维模式识别、函数拟合、时间序列回归预测中其优越性会更加明显,对于小样本非线性的数据有着良好的预测效果,同时也具有较好的弹性和泛化能力。股指期货的历史数据往往具有非线性、高噪声的特点,相比于其他方法,通过支持向量机对股指期货进行预测能够得到较好的预测结果。
尽管在股票价格的预测上前人已经进行了大量的研究,但时代发展至今,不论是股票价格相关信息的变化,还是科学技术的进步,都预示着需要在最新的时代背景下探索与完善新的方法来研究股票价格。由于支持向量机在时间序列预测方面表现出特有优势,因此它在股票价格预测中的应用也备受关注。本文研究的是股票价格中的开盘价格,也就是开盘指数。在我国股市中有四个重要价位(开盘价、最高价、最低价、收盘价),一般情况下,前后两个生意日的集合竞价不会呈现很大的改变,但是一旦这种均衡被打破,往往预示着股价走势将有明显的改变,其运转方向将进行跳转(向下或向上),开盘不仅仅是前一生意日的连续,并且仍是当日生意走向的先期预演。而人们之所以注重开盘的原因在于,离上一个买卖日后投资者经过了二十多个小时的考虑研究,投资者目前所做出的投资决策是较为坚决且接近理性的,所以只要投资者能够把握开盘的这三十分钟就大致能够剖析全天的走势,可见开盘指数的研究将对投资者有着重要的意义。本文研究意义具体如下:
(1)理论意义
本文在前人研究的基础上,不仅基于传统支持向量机对上证指数开盘指数进行了回归预测,还进一步结合信息粒化来预测开盘指数未来的趋势与变化空间,经过参数调优,增加了模型预测的准确度,并且对股票变化趋势的预测模型进行了优化,得出了最佳的模型组和。最后对两种模型的比较为之后支持向量机的优化与股票价格的研究提供了参考。
(2)实践意义
股票预测是投资市场发展以来人们研究的焦点,从传统的证券投资分析法到今天的数据挖掘方法,不论方法预测的准确与否,都给投资者提供了一条参考路径。而基于支持向量机的预测方法经过前人的研究表明,相比于其他方法更加适合股票价格非线性的特征。因此,本文所做的研究是将当下数据挖掘中最新最适合非线性特征分析的方法用于股票价格的预测,在实践上,能协助投资者在投资活动中不被多变的股票市场所干扰,使其更加客观理性地看待价格波动,最终做出正确的投资决策,以获得收益。
研究目的
对于股票价格预测的研究,已有研究结果显示,相对于传统的股票价格预测方法与现在的神经网络预测方法而言支持向量机更加适合具有非线性、非参数特征的股票价格预测。也有一些人已经使用了支持向量机来预测股票价格,但是传统的支持向量机回归分析只能最大限度拟合过去股票价格的变化趋势,以此来对股票价格进行粗略的点预测,而这样的预测精度并不高。想要得到更加精确的结果,还需对股票价格变化趋势和变化范围进行预测,这就需要引入模糊信息粒化。本文研究的目的就是期望通过支持向量机将模糊信息粒化后的上证指数数据来对开盘指数进行回归预测,从而得出在未来5天内上证指数开盘指数的变化趋势与变化范围。同时,本文将在模型优化方面,通过对比不同的核函数、自变量与隶属函数回归效果,选取最适合的一种模型组和。最后还将对比信息粒化之后的支持向量机回归与未信息粒化的支持向量机回归的预测效果,以验证精确度最高的预测方法。
国内外研究现状
支持向量机是Corinna Cortes和Vapnik等人于1995年首先提出的,它产生的后几年也就是本世纪初就开始应用于股票价格的预测,在这过去的接近20年中,研究者们利用支持向量机在股票的预测上得到了许多不朽的成果,这些研究成果也将作为基石,指导后来的研究。
(1)国外研究现状
在支持向量机被发现之前,金融预测领域最流行的预测技术是BP神经网络,然而在支持向量机出现的后几年,就有人发现了BP神经网络不可忽视的缺点。2001年Francis EH Tay与Lijuan Cao通过与BP神经网络对比来研究SVM在金融时间序列预测中的可行性,他们在研究中就提出BP神经网络存在许多缺点,包括需要大量控制参数,难以获得稳定的解决方案以及过度拟合的危险,而SVM为BP神经网络提供了一种有前途的金融时间序列预测替代方案[1]。这几乎是最早的利用支持向量机预测股票的研究,当支持向量机的优势显现出来后,随后股票价格研究的焦点就放在了支持向量机上。
近年来,研究不再局限于标准的支持向量机,人们尝试将支持向量机与其他模型相结合来探索预测精度更高的组合。Nadh V L等人在股票的研究中运用了遗传算法(GA)、支持向量机(SVM)和人工神经网络(ANNs),他分析了每种方法的优劣之后得出:每种算法都有一些优点,也有一些限制,因此,一些技术指标和机器学习算法的结合将产生最佳结果[2]。也就是说组合模型使得各种方法互补,能得到更好的预测结果。在Ahmadi E 等人的研究中就开发出两种创新且结构不同的混合预测模型,他们以SVM为分类器,帝国主义竞争算法(ICA)和遗传算法(GA)用于优化SVM参数的方式,为股票市场时机提出了两种SVM-ICA和SVM-GA模型[3]。这样组合的模型效果较好,命中率都达到了百分之七十以上。Nahil A等人则是通过基于核主成分分析(KPCA)和回归支持向量机(SVR)的综合预测模型来提高股票价格的预测能力。实验结果表明,采用KPCA进行特征提取的SVR比没有特征提取的具有更好的泛化性能[4]。同样地,Chowdhury U N等人也在股票的预测中采用了组合模型,他们使用主成分分析(PCA)提取低维有效的特征信息,然后使用独立分量分析(ICA)对提取的特征进行预处理以使其无效。最后经过模型对比得出,提出的模型(PCA-ICA-SVR)优于PCA-SVR,ICA-SVR和单一SVR方法[5]。
随着组合模型在股票价格预测上应用逐渐广泛,专家们已经开始从以往的比较各个单一模型转为现在的比较各个组合模型的研究,以寻找最佳的组合模型。Lahmiri S在研究中使用奇异谱分析(SSA)和支持向量回归(SVR)与粒子群优化(PSO)相结合的日内股票价格预测模型来预测股票价格[6]。为了检验该模型的预测效果,他选择了小波变换(WT)与前馈神经网络(FFNN)的组合模型WT-FFNN,自回归移动平均(ARMA)过程,多项式回归(PolyReg)和幼稚模型相结合的组合模型这三个模型来与SSA-PSO-SVR模型进行比较分析。
还有人对支持向量机进行了纵向的研究,挖掘如何改进支持向量机从而使它的预测更加精确。例如Henrique B M, Sobreiro V A,与Kimura H在2018年的研究表明在每日价格上使用固定训练集,在使用线性内核时,可以在测试集中获得比训练集中更小的预测误差[7]。Gupta D等人更是尝试使用最新提出的双支持向量机来预测金融时间序列,得出的结果也是比传统的支持向量机更精确、更高效[8]。
(2)国内研究现状
国内近年来的研究也把重点放在了组合模型上,例如张贵生与张信东将提出一种新的基于近邻互信息特征选择的SVM-GARCH预测模型[9];傅航聪与张伟整合K-近邻算法、支持向量机算法和时间序列算法的预测结果的优点,提出一种综合预测算法[10];冉杨帆与蒋洪迅将情感分析和机器学习方法相结合,以股票新闻数据为基础,分别采用BP神经网络(BPNN)和支持向量机回归 (SVR)两种方法,对股票价格进行预测分析[11];李辉与赵玉涵利用DFS-BPSO-SVM模型预测股票价格[12];严骏宏结合离散小波分解和支持向量机方法对股票指数进行组合预测研究[13];提出了一种基于特征选择 (Boruta算法) 和粒子群优化(PSO)算法SVM的新算法[14]等等。这些研究经过模型组和来对股票价格进行研究,最后得出的结果都优于单一模型。
当然也有研究者开始寻找新的研究组合,董理、王中卿等2017年发表基于文本信息的股票指数预测一文,他们将情感分析与支持向量机相结合来研究股票价格,开辟出一个新的研究角度,并且取得了较好的结果[15]。2019年张晶华与甘宇健的研究中利用深度学习支持向量机模型对上证指数进行数值预测,并得出此方法与已有的支持向量机算法相比,在预测精确度方面有明显的改善[16]。
具有代表性意义的是,2005年俞坤宝、刘志涛等在机器学习与控制论国际会议上发表了一篇论文,使用2002年LIN Chun-fu等人提出的模糊支持向量机(FSVM)来预测股票综合指数,得出将模糊隶属度应用于SVM的每个输入点之后,能够增强SVM以减少异常值和噪声的影响,得到的结果比标准SVM和传统时间序列预测模型更加精确[17]。此后有人抓住这一点,开始将信息粒化与支持向量机相结合,其中周晓辉与姚俭2014年在股票价格预测中引入了混沌粒子群优化算法,该方法克服了传统时间序列模型仅局限于线性系统的缺点,得出的模型能够较好的实现短期股票开盘数的预测范围[18]。随后,2015年陈孝全、刘波[19]与2018年郑明[20]等人的研究中也相继利用信息粒化来增加模型的准确度,并都通过实践证明,信息粒化的引入确实能够优化模型。
主要研究内容与研究方法
主要研究内容
论文的核心内容是利用支持向量机(SVM)来对股票价格进行预测。其中分为传统的支持向量机回归分析与基于模糊信息粒化的支持向量机回归分析两部分,在回归分析前还有参数寻优方法与核函数选择的讨论。本文使用上证指数的历史数据来作为研究的数据基础,选取了与股票价格相关的六个指标,分别为:开盘指数、指数最高值、指数最低值、收盘指数、交易量、交易额。本文共有五章,主要内容如下:
第一章绪论,阐述论文研究的背景与意义、研究目的,并介绍国内外的研究现状,对股票价格预测方法进行综述。同时还说明了本文的研究内容、研究方法与预期目标。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: