基于深度学习的行人违章识别系统设计与实现毕业论文
2020-04-08 14:32:39
摘 要
行人违章识别系统的实现是基于深度学习技术。深度学习(Deeplearning,DL)是机器学习(MachineLearning,ML)的崭新的领域,是人工智能中最关键的技术。这使得智能识别行人违章成为可能。违章识别的过程就是对图片处理的过程,所以本系统最关键技术就是人脸识别技术,通过卷积神经网络来实现对人脸的智能识别。卷积神经网络是神经网络的一个经典模型。卷积神经网络中的卷积层用于提取图像特征,采样层则大幅度降低了网络的结构参数。基于卷积神经网络的这种结构特点及工作原理,本文提出了一种基于tensorflow框架的卷积神经网络的人脸图像识别方法。通过tensorflow框架来实现行人违章识别。本系统的实现需要两个数据训练集:交通摄像头每时每刻都在对城市的某个角落进行抓拍,抓拍到的图片有违章图片也有没有违章的图片。我们需要一个这样的训练集,通过该训练集训系统后,系统能智能识别出哪些是违章图片,哪些是没有违章图片。第二个训练集就是人脸识别的训练集。识别出了违章图片之后就可以对违章图片上的行人进行人脸识别,识别出具体行人后可以在数据库中检索出该违章行人的身份信息,最终实现对该行人的违章处罚并做相应记录。
关键词:卷积神经网络;训练集;tensorflow;人脸识别
Abstract
Deep learning (DL) is a brand new field of machine learning (ML). Its purpose is to make machine learning closer to its ultimate goal - artificial intelligence. Convolutional neural network is one of the deep learning algorithms. It has the characteristics of simple structure, strong adaptability, few training parameters and many connections. It has been widely used in image processing and pattern recognition in recent years.
As a classical model of neural networks, convolutional neural networks play an important role in the field of pattern recognition, but their application in image processing is rare. Convolutional neural networks in the convolutional layer are used to extract image features. The sampling layer greatly reduces the network structure parameters. Based on this structural feature and working principle of convolutional neural network, this paper proposes a convolutional neural network image recognition method based on tensorflow framework. In order to improve the image classification performance of convolutional networks, this paper gives a detailed theoretical analysis of convolutional neural network models, and through a large number of comparative experiments, the factors that affect the performance of convolutional networks are obtained. The realization of this research has expanded the convolution Application of Neural Network in Image Processing.
Key Words: Convolutional neural network; image processing; tensorflow; artificial intelligence
目录
第1章 绪论 1
1.1 研究背景及意义 1
1.2研究现状 2
1.3课题结构安排 3
第2章 卷积神经网络的模型分析 4
2.1网络基本拓扑结构 4
2.2激活函数 5
2.3 Softmax分类器与代价函数 6
2.4学习算法 7
2.4.1 随机梯度下降 8
2.4.2 自适应矩估计法 8
2.5 Dropout 9
第3章 模型设计与实验分析 11
3.1 模型设计 11
3.1.1 前提分析 11
3.1.2 图片获取 11
3.1.3 图片预处理 11
3.1.4 训练 12
3.1.5 测试 13
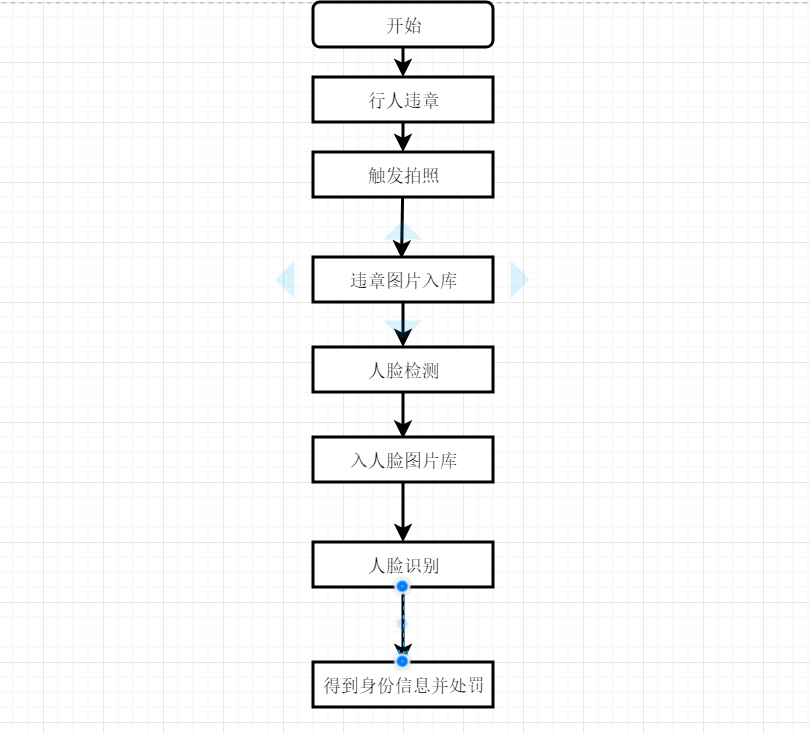
3.1.6 流程图 13
3.2 实验及结果分析 14
3.2.1实验环境与基本参数设置 14
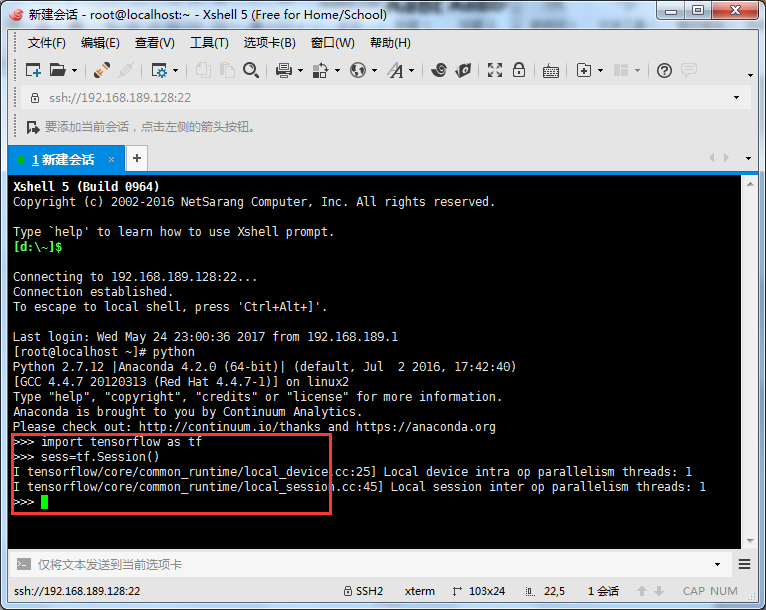
3.2.2 Tensorflow的安装 15
3.2.3 实验结果分析 16
第4章 结论 19
参考文献 20
附录 21
致谢 26
第1章 绪论
1.1 研究背景及意义
人工智能大爆发的时代,各种智能产品层出不穷。智慧交通系统下车辆违章一定会被记录并且扣分,无疑这是人工智能大爆发的福利。当下车辆闯红灯几乎已经消失。因为大家都心知肚明,闯红灯一定会被记录并且会扣分和罚款。但是行人闯红灯确屡见不鲜,行人闯红灯不仅给自己的生命带来了危险也会影响到他人,更有甚者,可能就是因为行人闯红灯,导致了异常严重的交通事故。评价一个城市的环境,人们首先想到的就是交通。就像一面镜子,交通秩序映射着城市形象、文明程度、管理水平和百姓民生,反应着城市的综合实力和核心竞争力。城市的现代化建设正在如火如荼的进行着,当下中国拥有像香港、上海这样的国际化大都市,一线二线城市更是数不胜数。交通是一座城市的命脉,顺畅的交通会给一座城市注入活力,让城市的一切有条不紊的进行着。我来自于中国的一个贫困县城,虽然是贫困县城,但是城市的车流量也大得吓人,每当我走在故乡的小城中时,各种行人违章数不胜数,因为大家都抱有侥幸心理,我违章不会造成交通事故并且也没有人知道我违章了。殊不知大多数交通事故就是因为行人不遵守交通规则才发生的。行人扎堆闯红灯过马路,一直是交通治理的老大难问题,大家都知道闯红灯是违法的,但几乎每个人都闯过红灯,因为违法成本低,很少有人管,即便闯了也很难被发现。如果行人违章也能像车辆闯红灯那样被记录并惩罚,那么行人违章的现象一定会彻底消失。基于深度学习的行人违章识别系统就是为了解决行人违章问题而设计开发的。本系统基于深度学习,通过分析抓拍行人违章的图像,通过图像识别可以精确查出此人的身份信息,从而通过个人信用系统或者其他的途径对此人实施处罚。如果此系统普及全国,会给城市交通带来巨大的改善和极大程度的减少交通事故的发生。行人不在违章,一座城市的交通才会保持顺畅,城市才会有活力,从而加速城市的现代化建设。有了此系统对行人的约束,久而久之,遵守交通规则就会成为一种习惯,国民素质也会大大提高。
基于深度学习的行人违章识别系统的核心技术是人脸识别技术。该技术是一种新型的身份识别技术,人脸识别技术应用领域越来越多。最开始该技术应用在上班打卡,用人脸打卡,只要你的头像图片在库,就能识别出你的身份信息。现在越来越多的手机也都有了人脸识别的功能,说明了该技术越来越纯属,走进了普通大众的生活。
所谓人脸识别,是指对输入的人脸图像或者视频,判断其中是否存在人脸,如果存在人脸,则进一步给出每张人脸的位置、大小和各个面部主要器官的位置信息,并且依据这些信息,进一步提取每张人脸蕴含的身份特征,并将其与已知人脸库中的人脸进行对比,从而识别每张人脸的身份。其研究内容包括以下五个方面:
(1)人脸检测 从不同的背景中检测是否存在人脸,并确定其位置、大小、形状、姿态等信息的过程。它关系到后续识别工作能否正确进行,并保障最终识别结果的可靠性。
(2)人脸表征 确定表示检测出的人脸和数据库中的已知人脸的描述方式。通常的表示方式包括几何特征(如欧氏距离、曲率、角度等)、代数特征(如矩阵的特征矢量)和固定特征模板等。
(3)人脸鉴别 即狭义的人脸识别,就是通常所指的将待识别的人脸与数据库中的已知人脸进行比较,得出相关信息。这一过程的核心是选择适当的人脸表示方式和匹配策略,系统地构造与人脸的表征方式密切相关。
(4)表情/姿态分析 即对待识别人脸的表情或姿态进行分析,并对其加以归类。
(5)生理分类 对待识别人脸的物理特征进行分类,得出其年龄、性别、种族等相关信息,或从几幅相关的图像中推导出希望得到的人脸图像,如从父母的脸推导出孩子的脸像等。
本论文中的人脸识别主要是指狭义的人脸识别,指将待识别的人脸与数据库中的已知人脸之间进行匹配的人脸鉴别。人脸识别的目的是让计算机具有通过人脸的特征来鉴别身份的功能。基于人脸特征的身份识别主要设计到复杂场景中的人脸检测及识别技术,是一种依托于图像理解、模式识别及计算机视觉、统计学和人工智能等高技术的研究方向。
1.2研究现状
1986 年, Rumelhart 等提出人工神经网络的反向传播算法 (Back propagation, BP), 掀起了神经网络在机器学习中的研究热潮。但是由于BP神经网络存在容易发生过拟合、训练时间长的缺陷, 90年代兴起的基于统计学习理论的支持向量机具有很强的小样本学习能力。学习效果也优于BP神经网络,导致了神经网络的研究再次跌入低估。
2006 年, Hinton 等人在 Science 上提出了深度学习. 这篇文章的两个主要观点是: 1) 多隐层的人工神经网络具有优异的特征学习能力, 学习到的数据更能反映数据的本质特征,有利于可视化或分类;2) 深度神经网络在训练上的难度, 可以通过逐层无监督训练有效克服。理论研究表明为了学习到可表示高层抽象特征的复杂函数, 需要设计深度网络。深度网络由多层非线性算子构成, 典型设计是具有多层隐节点的神经网络。但是随着网络层数的加大, 如何搜索深度结构的参数空间成为具有挑战性的任务。近年来, 深度学习取得成功的主要原因有:
1) 在训练数据上, 大规模训练数据的出现 (如ImageNet), 为深度学习提供了好的训练资源;
2) 计算机硬件的飞速发展 (特别是 GPU 的出现) 使得训练大规模神经网络成为可能。
卷积神经网络 (Convolutional neural networks, CNN) 是一种带有卷积结构的神经网络, 卷积结构采用权值共享的方式减少了深层网络占用的内存量, 也减少了网络的参数个数, 缓解模型的过拟合问题。为了保证一定程度的平移、 尺度、 畸变不变性, CNN 设计了局部感受野、共享权重和空间或时间下采样, 提出用于字符识别的卷积神经网络LeNet-5。LeNet-5 由卷积层、下采样层、全连接层构成, 该系统在小规模手写数字识别中取得了较好的结果。2012 年, Krizhevsky等采用称为AlexNet 的卷积网络在 ImageNet 竞赛图像分类任务中取得了最好的成绩, 是 CNN 在大规模图像分类中的巨大成功。AlexNet 网络具有更深层的结构, 并设计了ReLU (Rectified linear unit) 作为非线性激活函数以及 Dropout 来避免过拟合。在 AlexNet 之后, 研究者由提出了网络层数更深的神经网络,例如Google设计的GoogLeNet和MSRA设计的152层的深度残差网络等。表 1 是 ImageNet 竞赛历年来图像分类任务的部分领先结果,可以看出,层数越深的网络往往取得的分类效果更好。为了更好地改进卷积神经网络, 本文在KERAS10数据集上研究了不同的网络层设计、损失函数的设计、激活函数的选择、正则化等对卷积网络在图像分类效果方面的影响,本文引入了Batch Normalization与dropout结合的方法,通过加深卷层神经网络的层数,有效地提高了卷积神经网络在图像分类准确率。
1.3课题结构安排
本论文的主要研究内容怎样是被出违章行人的身份。第一章介绍了课题研究的意义、国内外的研究现状等内容。第二章是对卷积神经网络的模型分析。第三章模型设计与实验分析。最后,对全文进行了总结。
第2章 卷积神经网络的模型分析
2.1网络基本拓扑结构
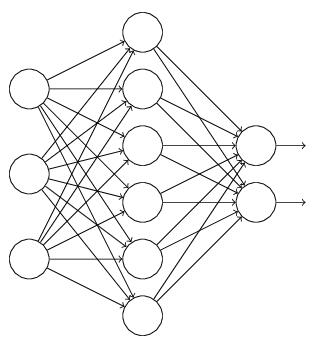
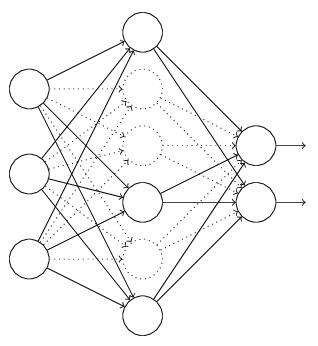
卷积神经网络与其他神经网络模型最大的区别是卷积神经网络在神经网络的输入层前面连接了卷积层,这样卷积层就变成了卷积神经网络的数据输输入。 LeNet-5是Yan Lecun开发的用于手写字符识别的经典卷积神经网络模型,图2-1是其结构图。
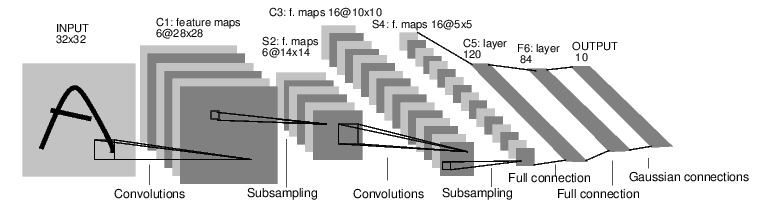
图2.1 LeNet-5结构图
LeNet-5的体系结构有7层,其中有3个卷积层。第一卷积层由6个特征图 (Feature Maps, FM)组成,故C1包含156可训练参数((6个5X5内核加上6偏值)来创建122304 (156* (28*28) -122, 304)个连接。在C1层FM的尺寸为28 x 28,由于边界条件,第二卷积层,C3包含1500权重和16偏置,C3层共有1516个可训练参数以及151600个连接。S2和C3之间的连接如表2-1所示。Lecun设计这些连接最大化的特征由C3提取的数目,同时减少权重的数目。在最后的卷积层C5包含120个FM,输出尺寸为1X1。
LeNet-5的体系结构还包含有两个子采样层:S2和S4,S2包含6个特征图和S4有16个特征图。层S2有12个可训练的参数与5880连接,而层S4有32个可训练参数与156000连接。
表2.1 S2与S3之间的连接
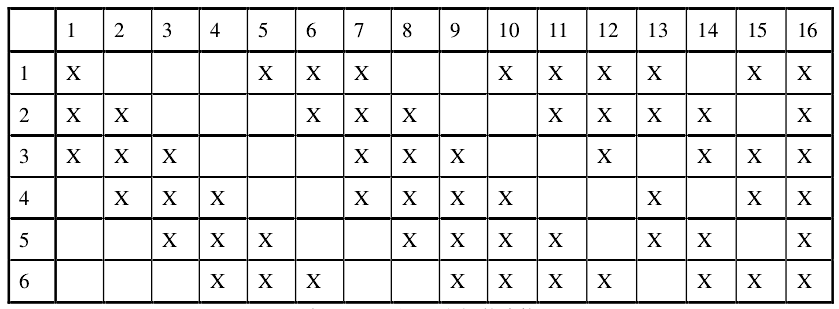
总结LeNet-5的网络结构,我们得到卷积神经网络的基本结构可以分为四个部分:输入层,卷积层,全连接层和输出层四个部分:
输入层:卷积输入层可以直接作用于原始输入数据,对于输入是图像来说,输入数据是图像的像素值。
卷积层:卷积神经网络的卷积层,也叫做特征提取层,包括二个部分。第一部分是真正的卷积层,主要作用是提取输入数据特征。每一个不同的卷积核提取输入数据的特征都不相同,卷积层的卷积核数量越多,就能提取越多输入数据的特征。第二部分是pooling层,也叫下采样层(Subsamping),主要目的是在保留有用信息的基础上减少数据处理量,加快训练网络的速度。通常情况下,卷积神经网络至少包含二层卷积层(这里把真正的卷积层和下采样层统称为卷积层),即卷积层-pooling层-卷积层-pooling层。卷积层数越多,在前一层卷积层基础上能够提取更加抽象的特征。
全连接层:可以包含多个全连接层,实际上就是多层感知机的隐含层部分。通常情况下后面层的神经节点都和前一层的每一个神经节点连接,同一层的神经元节点之间是没有连接的。每一层的神经元节点分别通过连接线上的权值进行前向传播,加权组合得到下一层神经元节点的输入。
输出层:输出层神经节点的数目是根据具体应用任务来设定的。如果是分类任务,卷积神经网络输出层通常是一个分类器,通常是Softmax分类器。
2.2激活函数
在神经网络中经常使用的激活函数有Sigmoid函数、Tanh函数、ReLu函数等,前两种激活函数在传统的BP神经网络使用的较多,ReLu函数在深度学习中使用的较多。
ReLu ( rectified finear unit)函数是Hinton提出的修正线性单元(Relu) ,CNNs在利用ReLu函数进行训练几次之后明显比传统的sigmoid和tanh函数更快。
假设一个神经单元的激活函数为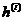 ,其中i表示隐含层单元的个数,
,其中i表示隐含层单元的个数,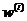 表示隐含单元的权值,那么ReLu函数的表达式为:
表示隐含单元的权值,那么ReLu函数的表达式为:
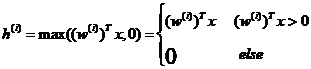
其函数图像如图2-3所示:
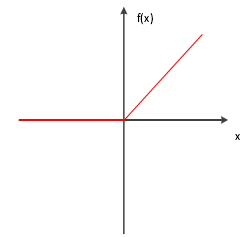
图2.2ReLu函数图像
由于ReLu函数具有线性的、非饱和的形式,单侧抑制,相对宽阔的兴奋边界,稀疏激活性,所以在卷积神经网络中的使用效果好于sigmoid和tanh函数。
2.3 Softmax分类器与代价函数
在卷积神经网络应用于图像分类任务时,我们在神经网络最后一层全连接层后接一个Softmax分类器用于图像标签的预测。
在softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),类标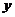 可以取
可以取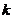 个不同的值(而不是2个)。因此,对于训练集
个不同的值(而不是2个)。因此,对于训练集
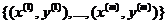 ,我们有
,我们有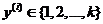 。(注意此处的类别下标从 1 开始,而不是0)。
。(注意此处的类别下标从 1 开始,而不是0)。
对于给定的测试输入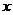 ,我们想用假设函数针对每一个类别j估算出概率值
,我们想用假设函数针对每一个类别j估算出概率值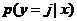 。也就是说,我们想估计的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个维的向量(向量元素的和为1)来表示这个估计的概率值。具体地说,我们的假设函数
。也就是说,我们想估计的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个维的向量(向量元素的和为1)来表示这个估计的概率值。具体地说,我们的假设函数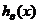 形式如下:
形式如下:
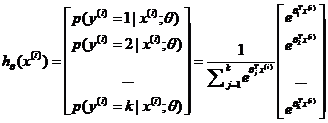
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: