基于AIS数据的船舶航迹规划研究毕业论文
2020-02-28 00:30:06
摘 要
为更好地识别船舶交通流,分析水上交通特征,本文提出一种基于船舶自动识别系统(Automatic Identification System, AIS)数据的船舶航路规划研究方法。该方法基于AIS数据的原始数据,数据经过专业工具解析后,选取合适的数学模型和计算机算法对其进行提取、压缩、聚类,挖掘轨迹,以期为海事管理部门判断航路、优化航路提供决策支持。
首先,对AIS数据进行解析、筛选和插值等预处理工作,最大限度地恢复原始数据,并提取其中的船舶轨迹数据;在此基础上,使用道格拉斯-普克(Douglas-Peucker,D-P)算法对提取的船舶轨迹数据进行压缩,以降低大量船舶轨迹数据的存储成本,同时保证数据的质量。
然后,采用动态时间规整(Dynamic Time Warping, DTW)算法度量各船舶轨迹数据之间的相似性,得到轨迹数据之间的距离矩阵,进一步利用层次聚类(Hierarchical Clustering,HC)算法对获得的距离矩阵进行聚类分析,进而实现轨迹挖掘和规划。
最后,基于以上理论方法,选取长江口水域进行实例验证,聚类结果与实际情况相符,很好的区分了上、下行船舶和异常轨迹船舶。表明该方法对于统计处理大量AIS数据有明显效果,能够为海事管理部门识别船舶交通流,判断航路提供依据。
关键词:AIS数据;航路规划;D-P算法;DTW算法;层次聚类
Abstract
In order to identify the marine traffic flow and analyze the characteristics of marine traffic, this paper proposes a research method of ship trajectory planning based on Automatic Identification System (AIS) data. This research method is based on the raw AIS data. After parsing the data, we select the appropriate mathematical model and computer algorithm to extract, compress and cluster it and excavate the trajectories, hoping to provide a better way to determine and optimize the route for the maritime administration.
Firstly, the AIS data need to be parsed, filtered and interpolated to recover the original data to the utmost extent and extract the trajectory data from it. Then, the Douglas–Peucker (D-P) algorithm is utilized to compress the trajectory data, which can help save the storage of a large quantity of trajectory data while ensuring the quality.
After that, Dynamic Time Warping (DTW) algorithm is used to calculate the similarity between the trajectory data to get the distance matrix based on it, further the Hierarchical Clustering (HC) algorithm is adopted to analysis the distance matrix generated in the previous step to realize the trajectory mining and planning.
Finally, based on the above theoretical methods, the Yangtze Estuary Area was selected for verification. The clustering results were consistent with the actual situation, in which the up-bound vessels and down-bound vessels and vessels of abnormal behavior were well distinguished. It shows that this method is obviously effective for the statistical processing of a large number of AIS data, and provides a basis for maritime administration to identify the marine traffic flow and determine the route.
Key words: AIS data; Route planning; D-P algorithm; DTW algorithm; Hierarchical Clustering algorithm
目 录
第1章 绪论 1
1.1 研究的目的和意义 1
1.2 国内外研究现状 1
1.2.1 船舶轨迹研究现状 1
1.2.2 船舶轨迹数据压缩 2
1.2.3 船舶轨迹聚类 3
1.3 论文主要研究内容 4
第2章 船舶轨迹压缩和聚类 6
2.1 船舶轨迹压缩算法 6
2.2 船舶轨迹聚类算法 8
2.2.1 动态时间规整算法 9
2.2.2 层次聚类 10
2.3 本章小结 11
第3章 AIS数据收集与预处理 13
3.1 AIS数据收集 13
3.2 AIS数据分类 14
3.3 AIS数据预处理 14
3.2.1 AIS数据解码 14
3.2.2 AIS数据筛选与插值 15
3.4 AIS数据预处理应用 15
3.5 本章小结 16
第4章 船舶航路规划实现 17
4.1 基于D-P算法的船舶轨迹压缩 17
4.1.1 船舶轨迹压缩 17
4.1.2 压缩结果 18
4.2 基于层次聚类的船舶轨迹聚类 20
4.1.1 DTW算法 21
4.1.2 层次聚类 22
4.3 船舶航路规划 24
4.4 本章小结 24
第5章 总结与展望 25
5.1 总结 25
5.2 展望 25
参考文献 26
附录 28
附录A D-P算法的MATLAB代码 28
附录B DTW的MATLAB代码 28
附录C 层次聚类算法的MATLAB代码 29
致谢 31
第1章 绪论
1.1 研究的目的和意义
在现代全球化的经济中,远洋运输成为远距离运输大宗商品最高效的方式。世界经济的持续增长,导致海上运输需求增加,运输速度加快,船舶数量不断增长。海上船舶数量激增带来贸易繁荣,但也容易造成水上交通安全问题,如航线负担,船舶自身问题等引起的航道拥挤和事故,使船员的生命和财产安全受到威胁。海上运输需要重点考虑航行安全问题。
与使用人工判断的传统水上交通系统相比,水上智能交通系统通过利用AIS数据,既提高了水上安全又降低了成本。AIS信息包含播发的动态信息和静态信息,这些信息可以转化为船舶智能操纵的有用信息,如船舶跟踪和预测、船舶行为识别、船舶异常性检测以及避免碰撞等,从而在未来的自治水上交通系统中发挥核心作用。如今,从船载设备和岸基设施接收AIS信息变得越来越平常,在基础研究和实际应用方面,人们对AIS信息的数据挖掘和模式分析都比以往更为重视。
聚类是数据挖掘的重要研究方法之一,通过聚类可以获取船舶在一定条件下的模式信息。对船舶AIS数据的聚类可用于识别异常模式并挖掘运输安全中的习惯路线,因此,可以相应地提高航行安全和水上交通监控的能力。以基于AIS数据的船舶轨迹为研究对象,通过运用数据压缩、聚类分析和数据挖掘等先进手段,对船舶航路规划进行研究,可以帮助海事管理部门更好地识别船舶交通流,分析水上交通特征,从而促进船舶交通安全,保障船舶经济航行,提高航运效率,对降低营运成本、避免水上交通事故的发生、减少船舶运输对环境的影响以及对了解船舶定线通航的实施情况具有重要意义。
1.2 国内外研究现状
1.2.1 船舶轨迹研究现状
国内外关于AIS数据应用的研究主要包括避免碰撞、异常检测、船舶行为识别和船舶跟踪和预测。Statheros等人[1]对船舶避碰的原因和研究方法进行了清晰的回顾,分析了人的航海能力和不同的避碰数学模型。马斯卡罗等人[2]提出了基于典型AIS数据中提取的正常行为及异常行为信息的动态和静态贝叶斯网络异常检测模型。此外,随着智能海事系统的快速发展,船舶航迹挖掘研究也有了极大的改进。例如,2008年,B-Ristic等人[3]提出了基于AIS数据运动模式统计分析的异常检测和运动预测算法。2013年,Premalatha Sampath[4]根据原始AIS数据生成船舶航迹,分析了航迹以确定新西兰航道船舶的运动模式。2015年,Goldwell等人[5]通过对AIS数据进行深入挖掘,进一步对船舶避碰行为分析和研究。Pallotta G等人[6]对船舶避碰的原因和研究方法进行了清晰的回顾,分析了人的航海能力和不同的避碰数学模型。Mazzarella等人[7]提出了一种自动提取方法,从历史AIS数据中获取真实知识,并评估渔船的行为,从而自动发现捕捞区域。
国内也不乏对船舶轨迹进行研究和创新的学者。肖潇[8]等学者对相似度度量方法进行创新,在轨迹聚类过程中融入了位置信息与航向信息,使聚类结果中各簇能更好地区分船舶进出航道的轨迹。刘敦伟[9]等学者在传统D-P压缩算法的基础上,改进并设计了基于速度和航向约束的船舶轨迹数据压缩方法,使压缩结果有效地保持了船舶原始轨迹的速度和航向特征。吕建[10]等学者通过建立一个系统的匹配与筛选机制,并将匹配与筛选机制通过计算机语言程序建立检索条件到数据库之间的桥梁,实现了与历史轨迹的航线匹配与筛选技术。
1.2.2 船舶轨迹数据压缩
目前,船舶轨迹数据压缩的方法主要有垂距限值法、光栏法和道格拉斯-普克(Douglas-Peucker, D-P)算法[11]。
垂距限值法的基本思路是先设置一个距离阈值D,然后比较中间点到与之相邻的两点的连线的距离d是否大于设置的距离阈值D,如果距离大于设置阈值,则保留该点,否则,舍去。通过不断比较,垂距限值法将弯曲程度较大的点保留下来,而舍去那些弯曲程度较小的点,因而不难看出,垂距限值法虽然原理简单且压缩速度快,但对于弯曲程度较小,幅度较平缓的曲线,其表现出的压缩效果较差。
光栏法的基本思路是先定义一个以起始点为顶点,以起始点与上一个点的连线为角平分线的扇形区域,判断曲线上的点在扇形外还是在扇形内,如果该点在扇形外,保留该点,如果在扇形内则舍去,如此重复直至所有点被检查完。可以看出光栏法在判断点的过程中并不需要下一个点参与,计算量较小,但所定义的扇形区域口径不变而需要判断的点与起始点间的距离却逐渐变大,因而造成压缩效果不明显。
D-P算法的基本思路是先设置一个距离阈值D,连接曲线的起点和终点,然后找出距离这条连线最远的点,比较该点与这条连线的距离d与距离阈值D的大小,如果距离小于设置的阈值,将这条曲线上的所有中间点全部舍去,否则,以该点为界,把曲线分成两个部分,再重复以上距离与阈值的比较直至结束[12]。D-P算法虽然计算量较大,但能全面考虑曲线的整体特征,能非常精确地选取特征点,且压缩得到的曲线在视觉上最优。鉴于此,本文采用D-P算法对轨迹数据进行压缩。
1.2.3 船舶轨迹聚类
聚类是数据挖掘的核心,利用聚类可以获取船舶模式信息。聚类过程也称为无监督学习方法,即无需事先了解数据。现已经提出了大量的聚类方法,这些聚类方法大致可以分为五类,即基于距离的方法(如K-means方法),层次方法(如AGNES算法和DIANA算法),基于密度的方法(如DBSCAN算法),基于网格的方法(如STING算法)和基于模型的聚类方法(如高斯混合模型(GMM,Gaussian Mixture Models))。
具体而言,基于距离的聚类方法要求首先建立初始分区,然后不断对对象定位以优化聚类结果。优化标准基于不同分区中对象的变化,直到分区结果满足最小目标函数值及实现最优分区。划分时,要尽可能使同簇对象相似而不同簇对象相异。K-means方法是基于距离聚类的典型算法,它通过判断距离来评价对象的相似度,两个对象的距离越近,其相似度越高。该算法要求首先任意选取k个对象作为初始聚类中心,然后将每个对象分配到与自身最近的聚类中心中去,将所有对象进行检测完后,形成k个新的簇[13]。其缺点是对初始聚类中心的选取要求非常严格且并不适用于所有类型的数据。
基于密度的聚类算法的主要思路是不断寻找高密度区域。其典型算法是DBSCAN算法。首先从所有对象里任选一个对象作为核心点,然后找到该核心点的所有密度相连的点,找到该核心点邻域内所有的核心点及与这些点密度相连的点对该核心点进行扩充,再寻找没有被聚类过的核心点对其进行以上扩充,不断重复知道所有对象里没有新的核心点[14]。与K-means方法相比,DBSCAN算法对对象的顺序要求并不严格,对簇类形状也不敏感,但对对象密度不均匀或是聚类间距差相差大的对象集,其聚类效果不乐观。
基于网络的聚类算法是指构建一个网络结构,而对象被量化为这个网络结构中有限数目的单元,然后在这个网格结构里对所有对象聚类,其典型算法为STING算法。STING算法要求从一个层次开始,计算这个层次的每个单元格的相关属性值,基于计算出的相关属性值及约束条件,将每一个单元格标记成相关或者不想关,对于不相关的单元格不再考虑,接着检查剩余的相关单元,接着层次结构转到下一层重复以上操作直至底层,即根据属性的相关统计信息进行划分网格,而且网格是分层次的,下一层继续划分上一层[15]。与其它聚类算法相比,STING算法处理数据的速度与数据的数目无关,只与构建的网络结构中的量化空间的单元数目有关,适用于大数据集中的聚类,但它们对输入参数敏感,而且在理论上很难找到有效的参数设置方法。
基于模型的聚类算法的基本思想是找到一个合适的数学模型使所有对象能够代入其中。它们可以通过构造有效密度函数来反映数据点的分布,并自动获得聚类数量。高斯混合模型聚类首先要设置GMM参数,均值、协方差矩阵、混合系数,基于这些参数,计算对象属于某个类别的概率,然后基于概率重新计算GMM的参数[16]。重复以上直到参数稳定,最后得到每个对象属于各个类的概率。这种方法的优点是通过概率对类进行划分,且每个类的特征也可以用具体参数来表达;但实现效率不高,尤其在数据量较小而类别较多时。
基于层次的聚类方法要求先计算各对象间的距离,然后将距离最相近的点合并到一个类中,接着计算各类之间的距离,将距离最相近的类合并到一个类中,重复以上知道所有对象合成一类。层次聚类算法分成自下向上的凝聚的层次聚类和自上向下的分裂的层次聚类。以凝聚的层次聚类算法为例该算法首先把每一个对象都作为一个类,即一个簇,然后将距离最相近的两个类合并成一个类,然后不断将距离最近的类合并成越来越大的类直到聚成一类[17]。其优点是原理简单,不需要预先设定聚类数,且通过形成层次聚类树非常容易找到各类的层次关系。鉴于此,本文采用凝聚的层次聚类算法为聚类方法。
1.3 论文主要研究内容
本文围绕一种基于AIS数据的船舶航路规划研究方法展开研究,主要内容包括:
第一章,介绍论文的研究目的和意义,并从船舶轨迹数据压缩和船舶轨迹数据聚类两个方面阐述了船舶轨迹的国内外研究现状;
第二章,详细介绍了本文用来处理船舶轨迹的算法:本文共涉及到轨迹压缩算法和轨迹聚类算法,针对具体运用情况,详细介绍D-P算法和凝聚的层次聚类算法。
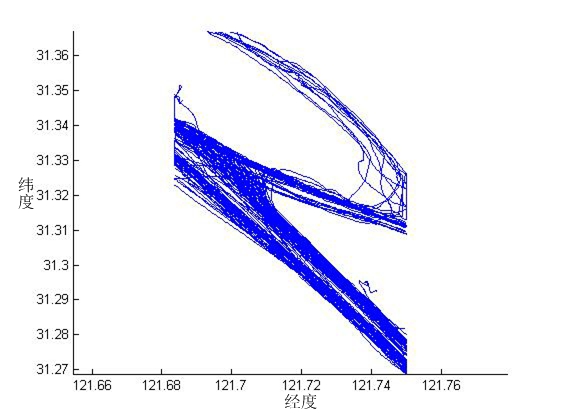
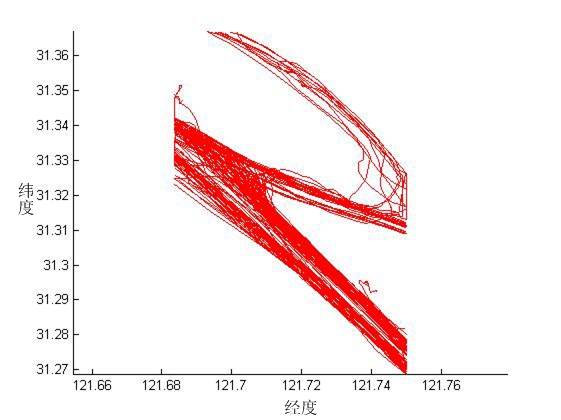
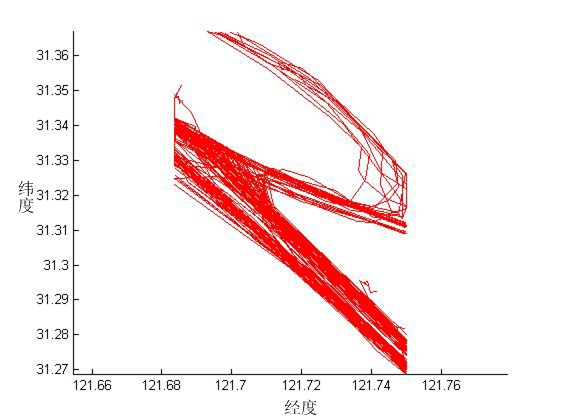
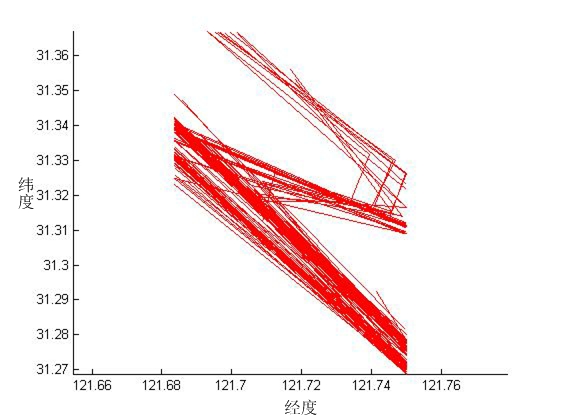
第三章,阐述AIS数据的收集与预处理,并提取了实验需要的船舶轨迹数据。目标区域AIS数据收集,是指通过学院大数据实验室平台对长江口水域的AIS数据进行收集,再将从大数据实验室平台采集到的AIS数据解码整理并存储。接着对AIS数据进行一定的筛选与插值处理,最后针对船舶航迹,提取经处理后的经、纬度数据信息。
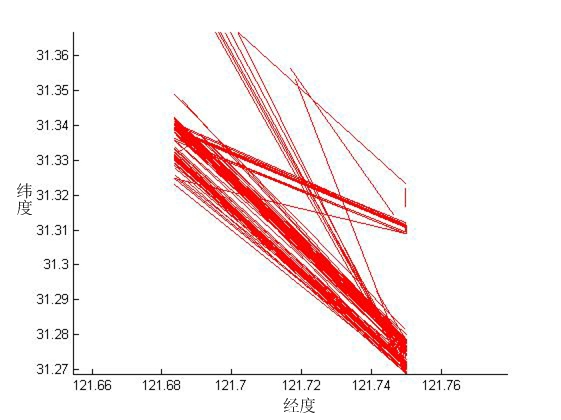
第四章,基于在AIS数据中提取的船舶轨迹数据,对船舶轨迹数据进行压缩和聚类实验。先对船舶轨迹进行压缩:利用D-P压缩算法,对船舶轨迹进行数据压缩,压缩无效的冗余点,使数据减少,方便船舶AIS数据的储存传输和调用。再对船舶轨迹聚类与航迹挖掘:对压缩后的轨迹,运用动态时间规整(DTW)度量轨迹间的相似度,接着通过层次聚类方法进行分析,从聚类结果中发现船舶运动特征规律,利用典型特征轨迹表示轨迹聚类信息,从而分析长江口水域的航迹分布规律并进行深入挖掘,进而对船舶航路规划进行研究。
第五章,论文的总结与展望。对本文的主要研究内容,所涉及算法及其应用进行了总结,并对后续研究的开展提出了展望。
根据研究内容和研究目标,设计研究路线如下图1.1 所示。
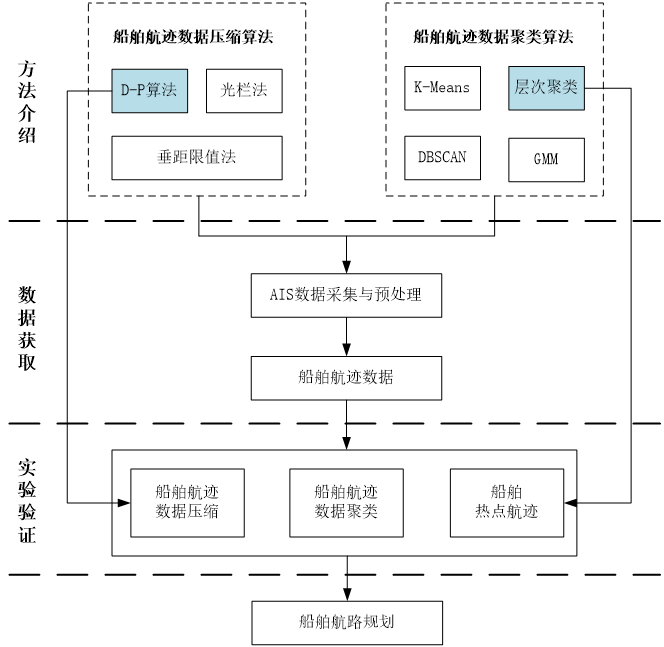
图1.1 研究技术路线图
第2章 船舶轨迹压缩和聚类
顾名思义,船舶轨迹压缩和聚类包括船舶轨迹压缩和船舶轨迹聚类。本文使用D-P算法作为船舶轨迹压缩算法,对其压缩原理及过程进行详细分析;使用层次聚类作为船舶轨迹聚类算法,主要对聚类中涉及的相似度度量及层次聚类的原理和过程进行阐述。
2.1 船舶轨迹压缩算法
D-P算法是一种离线压缩算法。不同于传统离线压缩算法,D-P算法能够有目的的保留重要的、能体现轨迹特征的点而不是均匀的删除点,而能够使压缩后的轨迹较好的反应真实的船舶运动轨迹在船舶AIS轨迹数据压缩中极为重要[18]。D-P算法使用近似原始轨迹的直线段来表示原始轨迹,运用D-P算法,必须先定义作为简化线段的阈值。D-P算法是通过原始曲线和简化曲线之间的最大距离来定义的“不相似”,其最终目的是得到由直线段组成具有较少点的相似曲线。简化的相似曲线由原始曲线的点的子集有序排列组成,该算法描述如下:
起始曲线是有序的一组点,距离维度为。该算法递归地划分线。首先在给出的所有点中自动标记第一个点和最后一个点并保存,然后连接第一个点和最后一点形成一条线段,将距离该线段最远的点作为最远点。如果该点离该线段的距离小于r,那么当前未被标记的任何点及该点将被舍去,简化曲线即第一点和最后一点的连线。如果该点离该线段的距离大于r,则保留该点并以该点与第一个点和最远点连接成线段,递归地标记最远点和阈值比较,对点舍去或保留。对点递归处理知道完成,最后输出一条新的曲线,该曲线由所有标记为保留的点构成。D-P算法原理图如图2.1所示。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: