机器学习算法预测MTV-MOFs材料碳捕集性能研究毕业论文
2020-02-19 11:51:30
摘 要
本文使用的是李松等人创建的MTV-MOFs数据库,建立了可用于机器学习的数据集。然后使用了机器学习相关模型对数据集进行训练,用以预测MTV-MOFs对于二氧化碳的吸附情况。使用机器学习算法能够快速达到准确筛选的目的。
本文的上半部分主要是对MTV-MOFs数据库进行介绍,并在李松所公开的数据集的基础上扩展对于MOFs材料性质的描述。对与MTV-MOFs进行初步的分析,可以发现下半部分则是使用整理、拓展后的数据集,对SVM、RF、GBRT这几种机器学习模型进行训练,从而预测MTV-MOFs对于二氧化碳的吸附性能。模型的训练是使用共计10995个样本的80%,其余的20%的数据集则用于测试模型的准确性。结果显示,预测选择性时梯度提升树模型的精度最高R2达到0.98439,而预测吸附量最高的模型时神经网络R2值达到0.95502。之后使用梯度提升模型输出了各个输入特征的权重,显示不论是预测吸附量还是选择性,吸附热都是最大的影响因素。
关键词:金属有机骨架材料;二氧化碳吸附;机器学习
Abstract
In this paper, MTV-MOFs database created by song li et al. is used to build a data set that can be used for machine learning. The dataset was then trained using machine learning related models to predict the adsorption of carbon dioxide by MTV-MOFs. Using machine learning algorithm can quickly achieve the goal of accurate screening.
The first half of this paper mainly introduces the MTV-MOFs database and expands the description of MOFs material properties on the basis of the data set disclosed by li song. After preliminary analysis of MTV-MOFs and MTV-MOFs, it can be found that the lower part USES the sorted and expanded data set to train SVM, RF, GBRT and other machine learning models, so as to predict the adsorption performance of MTV-MOFs on carbon dioxide. The training of the model used 80% of a total of 10995 samples, and the remaining 20% data sets were used to test the accuracy of the model. The results show that when the selectivity is predicted, the accuracy of the gradient lifting tree model reaches the highest R2 of 0.98439, while the neural network R2 of the model with the highest adsorption is predicted to reach 0.95502. After that, the weight of each input feature was output by the gradient lifting model, showing that the adsorption heat was the biggest influencing factor whether the adsorption amount was predicted or the selectivity.
Key Words: Metal Organic Frameworks (MOFs);carborn dioxide adsorption; Machine learning;
目录
摘 要 I
Abstract II
第1章 绪论 1
1.1 MTV-MOFs的发展历史及特性 1
1.2 MOFs数据库的创建及分子模拟 2
1.3 MOFs机器学习筛选及预测 3
第2章 MTV-MOFs大数据挖掘及机器学习算法 4
2.1 MTV-MOFs大数据分析 4
2.2 MTV-MOFs大数据库预处理与拓展 6
2.2.1 基于linker、cif的文本数据转换 7
2.2.2 MOFs结构参数模拟 8
2.3 机器学习模型及算法 8
2.3.1支持向量机 10
2.3.2随机森林 11
2.3.3梯度提升回归树 11
2.3.4人工神经网络 11
2.4超参数的优化 12
2.5模型评估方法 13
第3章 结果与讨论 14
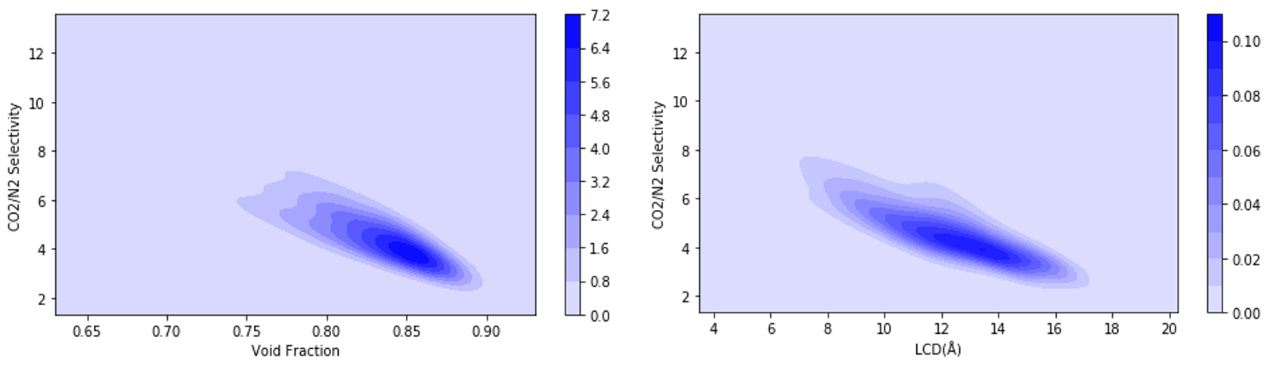
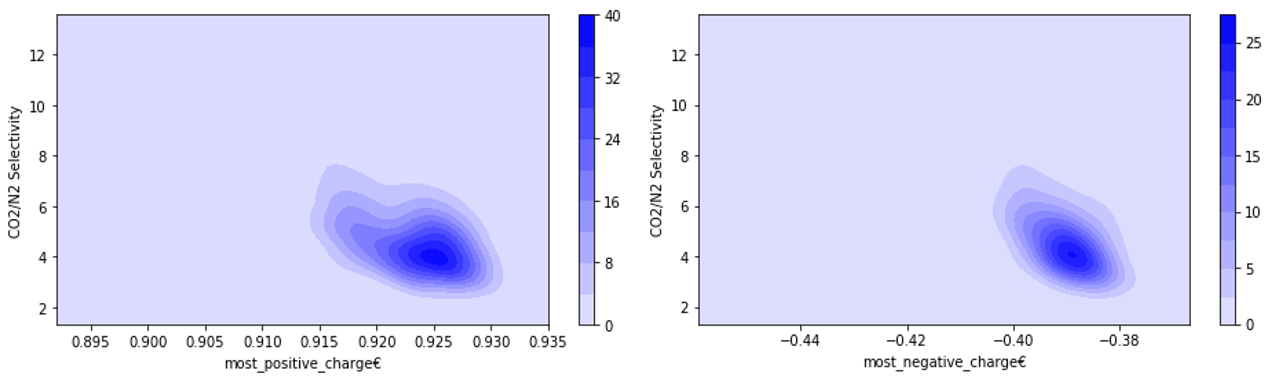
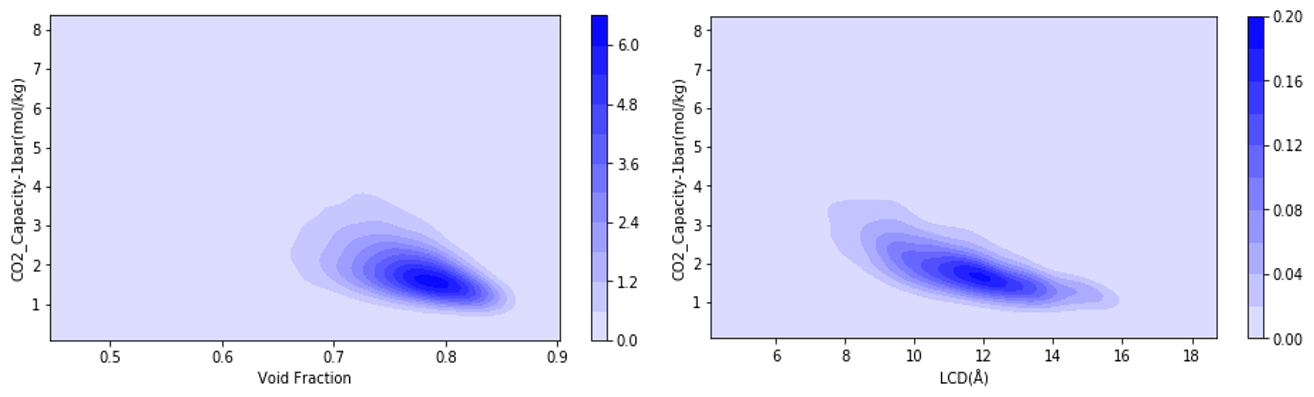
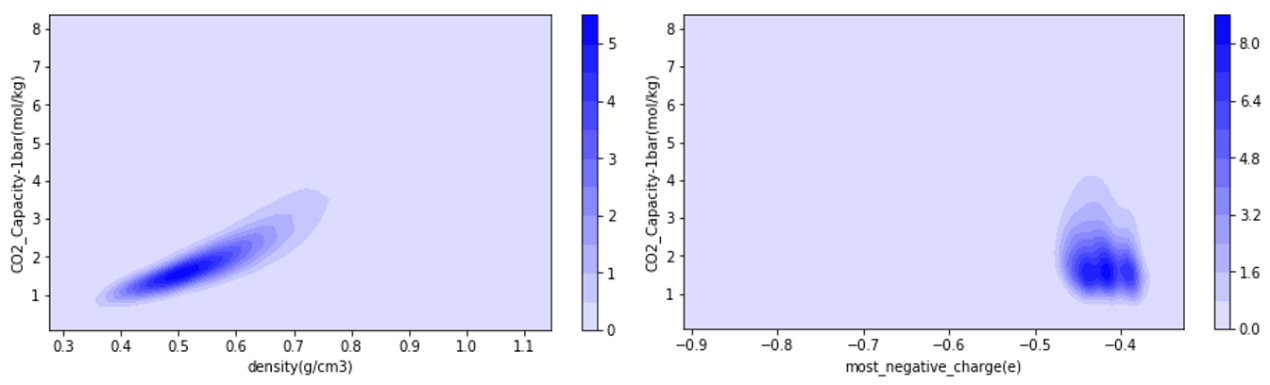
3.1 MTV-MOFs数据特征 14
3.1.1 MTV-MOFs特征分布 14
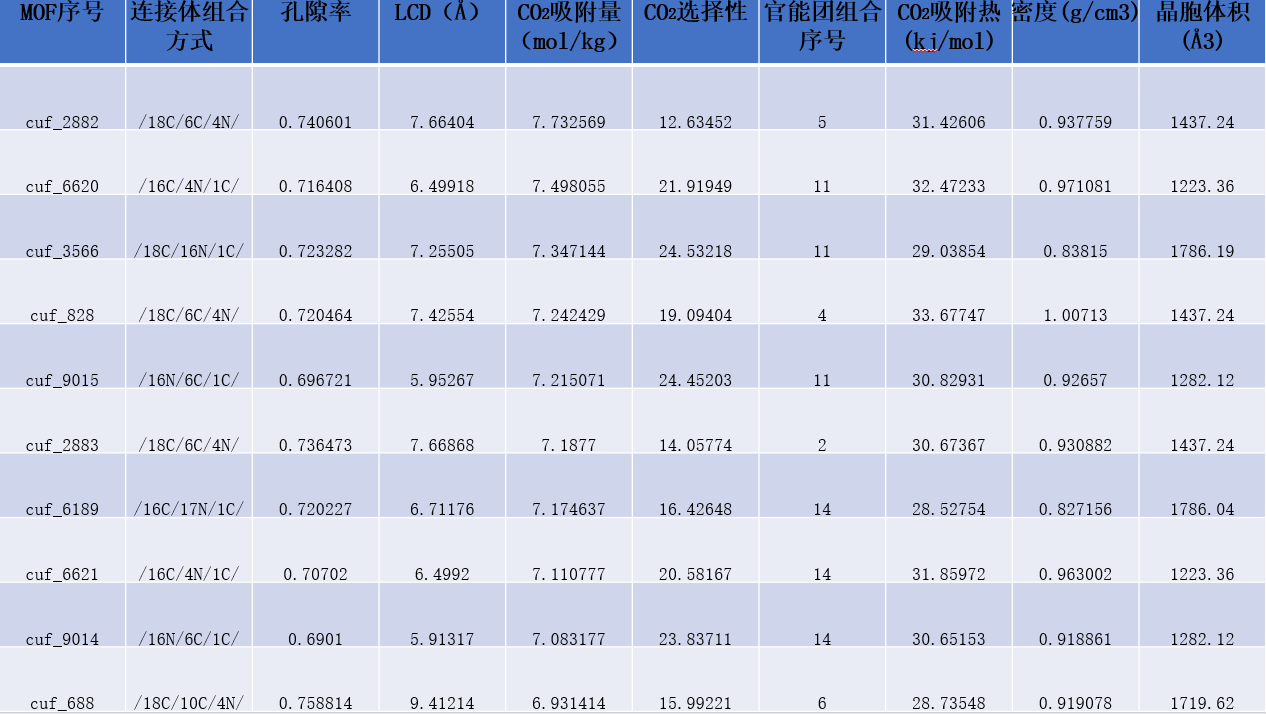
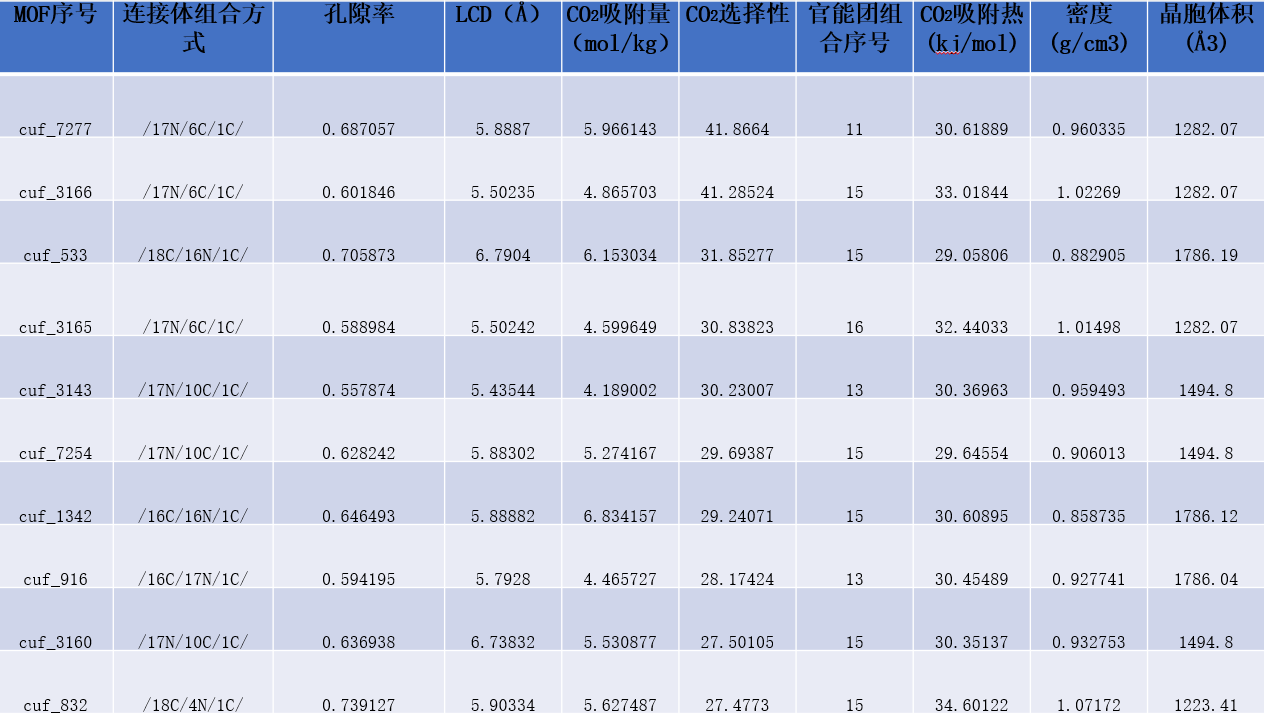
3.1.2高性能MOFs特征 16
3.1.3特征变量相关性分析 20
3.2模型结果分析 23
3.2.1不同机器学习模型结果比较 24
3.2.2特征变量重要性 26
第4章 结论与展望 29
参考文献 30
致谢 32
第1章 绪论
随着目前温室效应的日益严重,对于温室气体排放已经给地球的环境带来巨大的压力。二氧化碳是最大的温室气体,来源很广主要有动物呼吸、烟道气体、汽车尾气等。但二氧化碳也是一种珍贵的碳资源,为了减小化石燃料消耗的大量增加,减小全球变暖的程度,满足节能减排的环保要求,对于二氧化碳的捕集和封存具有重要的意义。对于二氧化碳的捕集有多种方法:液态胺基溶液变温吸收法、低温分离法、吸附分离法。其中吸附分离法采用固体吸附剂通过变压吸附(PSA)或变温吸附(TSA)对CO2进行捕集和分离可克服设备腐蚀问题,而且能耗大幅度降低,是常用的气体分离方法。常见的物理吸附剂有:活性炭、沸石分子筛、金属有机骨架材料等。
活性炭作为较早使用的一种吸附材料,在孔结构上是互通的且比表面积较大,加上加工成本低可大批量生产,因此很早便在催化、纯化以及气体的吸附分离有大量应用。沸石分子筛则是一种微孔晶体骨架材料,其化学组成一般为硅酸盐。如今大部分对沸石分子筛的改性,都是对硅酸盐结构中的铝原子进行其他金属原子的替换,或利用其吸附搭载的特性成为新型催化材料,从而应用于更多的场景。相比于活性炭等碳材料,由于其骨架上由于电荷分布的不均,沸石材料的分离和吸附效果表现出更加优良的性质。本文所讨论的为金属有机骨架材料,虽然其发展相对于前两种材料研究时间较短,但凭借其卓越碳捕集以及催化效果引起了人们广泛关注。
1.1 MTV-MOFs的发展历史及特性
金属有机框架(MOFs)材料是一类由金属离子(簇)和刚性有机分子配位连接形成的多孔结晶框架网络。是有机配体与金属单元通过自组装而形成的具有周期性网络结构的晶体材料。除了具有多样化的设计性和高度可调节性,其比表面也极高,孔容、孔隙率和密度较大。这些物理化学性质上的优势使得MOFs材料,对于传统的多孔材料在CO2吸附分离过程中表现出明显优势[1][2],在净能源、CO2捕集与存贮及CO2催化转化等方面显示出极大的应用潜力。然而实际上MOFs真正进入高速发展的时期还是在用于储氢的MOF-5和用于催化反应的Cu-BTC在实验制备之后。其中MOF-5的结构是以Zn2 为金属中心节点,对苯二甲酸为有机配体,Yaghi等人通过水热法或直接合成法得到八面体的立体骨架。制备得到的MOF-5由于孔道结构高度规则,加上比表面积、孔体积很大,其表现出优良的储氢性能。之后在此基础上,该研究组通过对MOFs中的linker进行官能团的修饰,发现通过官能团的引入能够很好的调控MOFs的物理化学性质,进一步拓展MOFs材料的应用场景。与此同时Williams等人通过水热法,改变次级结构单元合成得到Cu-BTC。很快随着更多制备MOFs的方法如二次生长法、挥发法、扩散法、超声法、微波法被应用,更多种类的MOFs材料被制备出来。MOFs在吸附、催化等多孔材料的诸多领域都开始广泛使用。很快根据MOFs材料的应用需求,实现定向分子设计成为可能。为了让MOFs材料的官能团连接体能够多样化的组合,Deng等人首先提出并合成了MTV-MOFs材料[3]。他们以1,4-苯二甲酸酯为连接体进行官能团化,对MTV-MOFs提出了组建的方法。之后Deng等人发现的一种MOFs材料MTV-MOF-5-EHI(官能团E:-NO2;H:-(OC3H5)2;I:-(OC7H7)2),在多个方面上都有明显的增强。但是要合成结构稳定、孔道可调节、CO2捕集性能优异的MOFs材料,依然面临极大的挑战。尤其是在创建材料结构与性能关系纽带上,存在难以逾越的鸿沟。如今多孔径的材料已被广泛应用于小分子的操作,比如气体的储存、混合物的分离、催化、分析与探测。在这些多孔径的材料之中,由于MOFs材料的的高表面积、孔隙率、稳定性,且易于提前设计合成,它引起了广泛关注。
1.2 MOFs数据库的创建及分子模拟
随着MOFs的构建模块的提出,考虑其组分于拓扑结构的种类各不相同。通过对构建模块进行符合空间规则的组装,就可以大批量的输出得到MOFs材料,从而为相关MOFs能够快速、精确的设计提供可能。这种得到MOFs材料的方法,虽然在模拟过程中存在一定的误差。但考虑到通过实验方法来制备MOFs并进行分析,其过程时间相对较长且花费较大,近年来利用计算机组装、模拟MOFs得到了快速发展。Wilmer等人提出了利用计算机来构建MOFs材料的方法,将自己选定的连接体进行拼装得到大量的MOFs材料数据库[4]。从得到的MOFs数据库中进行筛选为MOFs材料的合成提供指导。很快此方法就应用于MTV-MOFs材料上。比如Wilson等人发表的,MTV-MOFs在氨基酸链修饰后进行计算研究。Yuan等人则采用了新的连接体顺序来安装,从而使MTV-MOFs材料能够精确定位其官能团的位置。有了大量的MOFs数据之后,高通量筛选也应运而生。Colon和Snurr从MOFs材料的结构、特征等方面,提出了对MOFs材料应用高通量筛选的方法,加速了分子模拟和筛选的时间。接着Altintas等人使用剑桥大学关于结构参数的数据集[5]。将高通量筛选的结果与传统的多孔材料(沸石、活性炭)相比较,发现结构参数(孔径、表面积等)对选择性和吸附量有重要影响[6][7]。Jiang等人利用高通量筛选从4764个材料(CoRE-MOFs)中得到了七种合适的膜材料,为天然气的吸附提供指导。MOFs数据库的创建和利用分子模拟对MOFs的吸附性能进行分析,同时也为之后利用大数据分析MOFs特征的内在关系提供了基础。
1.3 MOFs机器学习筛选及预测
利用计算机的计算能力来辅助,对MOFs的吸附性能进行预测逐渐应用于诸多的实验室中,从而在理论上帮助设计最优化之后的MOFs结构,找到新型的MOFs材料。在2012年的Watanabe等人所模拟的1167个MOFs吸附情况,就已经显示了利用计算机的筛选特定MOFs的广泛前景;而在2013年,Goldsmith等人在剑桥MOFs数据库(CSD)里的55万个材料中进行提取,利用计算机进行组装,绘制出22700个MOFs材料的3D模型。通过高通量筛选,来研究MOFs对于氢气的吸附效果。
实践证明,由于机器学习其特殊的开源性、便捷性以及容易移植的特点[8][9],能够在很短的时间在已有MOFs的基础上,对未知的相关MOFs进行准确预测。早在2014年,Michael等人就开始将机器学习算法实际应用于MOFs的筛选上,并且提出了quantitative structure−property relationship (QSPR)。其用于预测的MOFs则是通过分子模拟进行组装获得。虽然当时仅仅只是对组装的MOFs进行机器学习分类的预测,但提出的QSPR思想以及将机器学习应用于MOFs材料领域具有重要的意义。Giorgos等人同样将机器学习模型应用于吸附甲烷的MOFs筛选上,但其在描述MOFs吸附甲烷的过程中,考虑了化学因素可能造成的影响。之后李松等人,在之前MTV-MOFs提出的基础上,利用分子模拟构建大量的MOFs材料(10995),通过对大批量的MOFs进行高通量的筛选,从而研究具有重要影响的结构参数,找到具有潜力的MOFs材料。本文就是在李松等人所构建的MTV-MOFs数据库基础上,应用机器学习算法进一步加快MOFs高通量筛选的速度,进一步提高预测MOFs吸附性能的精度。
第2章 MTV-MOFs大数据挖掘及机器学习算法
本文的工作流程分为5个流程:1、分析MTV-MOFs数据库:在李松等人所构建MTV-MOFs方法的基础上统计MOFs材料的官能团、对应元素的原子数以及不饱和度等特征。2、计算比表面积、孔体积:使用Zeo 来计算温度在298k,压力在1bar的条件下比表面积等参数。3、提取MOFs材料原子中的最大电荷:分析李松所构建的MOFs材料的cif文件,提取得到其中最大电荷量。4、训练机器学习模型:对整理好的数据集分别使用四种模型进行训练,然后逐步调整每个算法的参数,提高模型和数据集的拟合程度。5.评估模型的学习效果:通过程序将机器学习的结果输出,分析评估训练结果。
2.1 MTV-MOFs大数据分析
李松等人挑选出21个连接体,其中可官能团化的连接体有20个(可见图2.2、图2.3),不能官能团化的有一个。以Cu作为节点采用pcu拓扑结构进行组装。为了区分linker的种类分别为其编号可见表。为了进一步研究其MOFs材料的官能团化对于吸附性能的影响,李松等人让每种linker有固定的官能团化的位点,并对官能团化前后的每个MOFs都计算了选择性、吸附量、吸附热等参数。其中未官能团化的MOFs有560个,官能团化之后的MOFs有10995个,
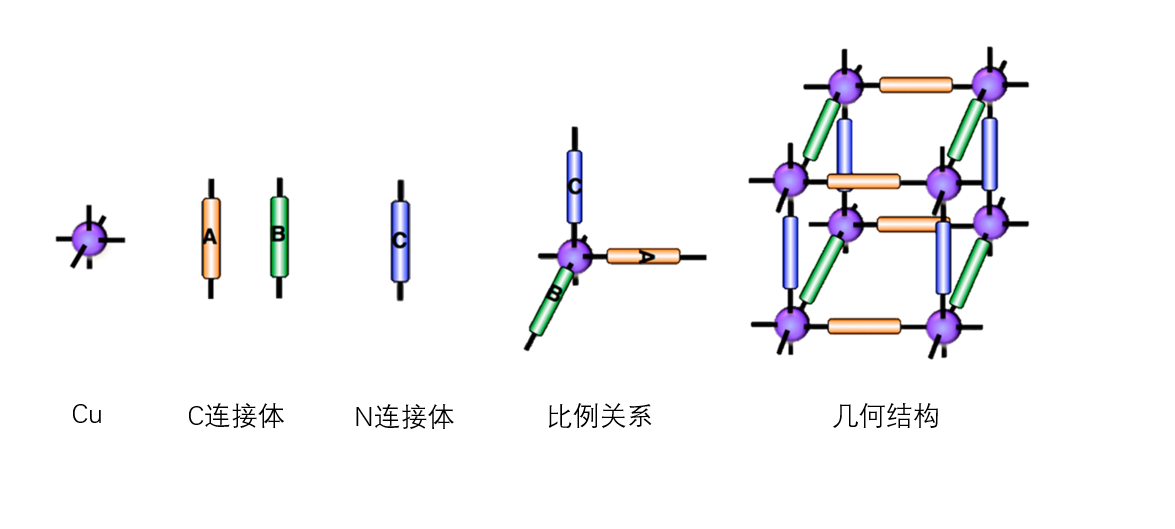
图2.1 进行组装的比例关系及空间构型
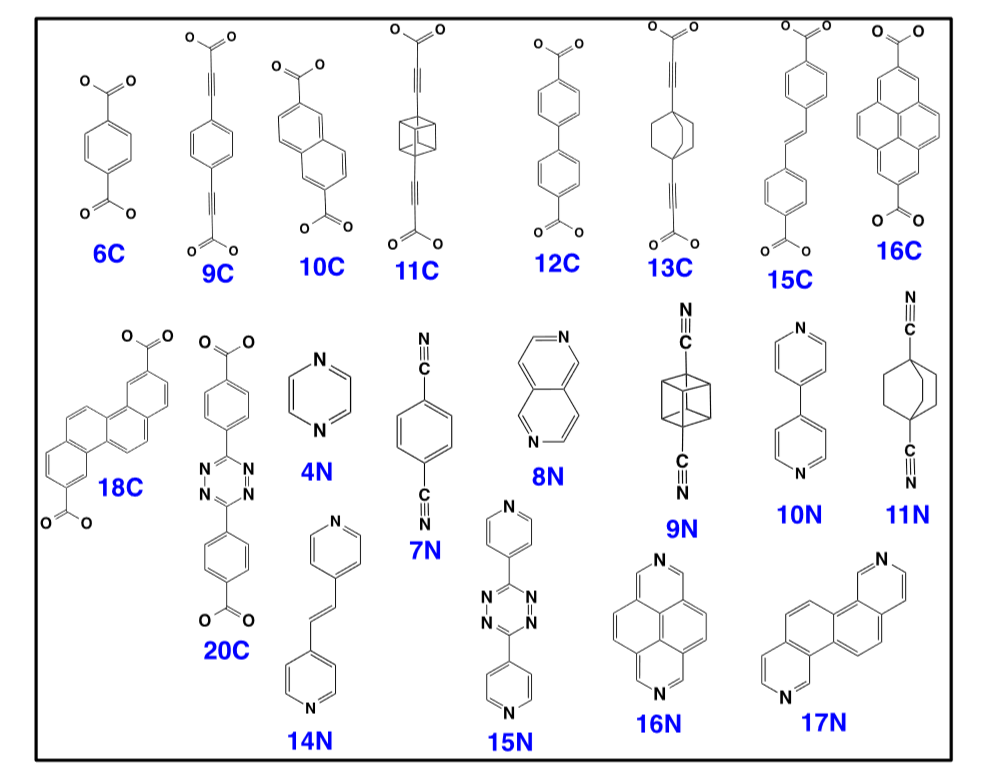
图2.2 用于parent-MOFs组装的连接体
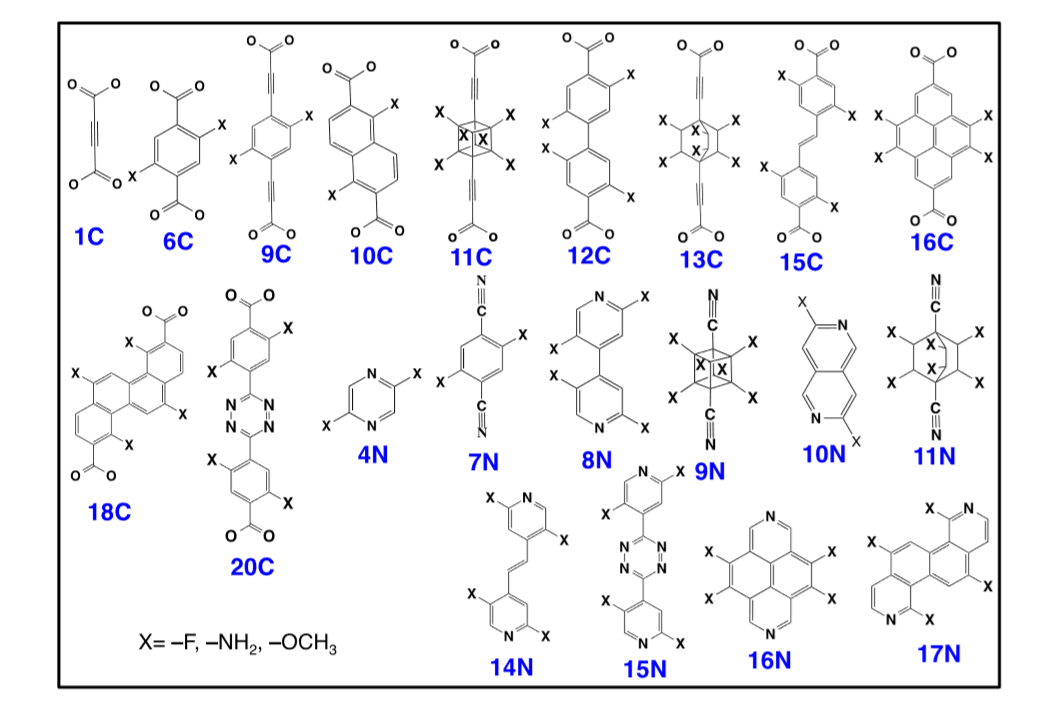
图2.3 用于MTV-MOFs组装的连接体
在进行MOFs材料组装的过程中,为了保证MOFs的稳定性,达到高度的表面不均匀性,每一个多变量MOFs材料都是由三个不同的连接体组成(图2.3)。组装linker的规则是每个Cu节点都必须与两个含有羧酸根的linker,和一个含有硝酸根的linker组装。其目的是让含有羧酸根的linker形成二位网格,而含有硝酸根的linker则是用于支撑其结构。此外对于这三种官能团的组合是排列而不包括相互交换。例如NH2-F-OCH3,F-NH2-OCH3,OCH3-F-NH2和NH2-OCH3-F是属于等价的组合方式。而对于三个连接体和一个不能官能团化的连接体组成的MOFs材料则有十种可能的组合方式。
2.2 MTV-MOFs大数据库预处理与拓展
在往机器学习模型输入数据之前,最常见同时也是最重要的工作就是对数据集进行预处理。基本的数据预处理的手段有数据的清洗、数据的集成、数据的变换和数据的规约。考虑到李松等人发布的数据集内容没有缺失,分布较为完整,本章所作的工作主要是对现有数据集进行拓展,并在最后将要输入模型时进行标准化处理。
2.2.1 基于linker、cif的文本数据转换
在数据库中使用的官能团总共只有三种,但是考虑到MOFs进行三维组装为了方便进行统计(表2.1)。同时通过对官能团组合编号,让这种组合问题能够数字化,使得官能团的组合信息能够成为机器学习的输入数据。编号选择的方法是基于构建模块的规则,让三个官能团不同组合来编号。
表2.1
官能团的组合序号 | 官能团组合方式 | 每种组合方式数目 |
1 | F-F-F | 420 |
2 | NH2-NH2-NH2 | 420 |
3 | OCH3-OCH3-OCH3 | 256 |
4 | F-NH2-OCH3 | 2379 |
5 | F-NH2-NH2 | 1330 |
6 | F-OCH3-OCH3 | 1002 |
7 | NH2-OCH3-OCH3 | 991 |
8 | NH2-F-F | 1330 |
9 | OCH3-F-F | 1158 |
10 | OCH3-NH2-NH2 | 1158 |
11 | F-F | 70 |
12 | NH2-NH2 | 70 |
13 | OCH3-OCH3 | 45 |
14 | F-NH2 | 140 |
15 | F-OCH3 | 113 |
16 | NH2-OCH3 | 113 |
为了充分的描述MOFs各个方面的性质[11][12][13][14][15],本文将每个构建单元的原子数、总不饱和度、总环数进行统计。采用python代码提取出各个linker的信息,按照MOFs的组装规则统计得到各个MOFs的原子数、环数度等信息。而对于MOFs材料的不饱和度,同样也是采取收集各个linker的不饱和度再进行累加。考虑到linker中只含碳、氢、单价卤素、氮和氧的化合物,对于单个linker的不饱和度,使用公式(2.1)
(2.1)
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: