基于微博数据的用户画像构建方法研究毕业论文
2020-02-15 16:52:50
摘 要
随着互联网的高速发展,数据也处于指数型增长,然而,在庞大的数据信息中,大多信息属于无效信息,如何从海量数据中提炼出有效信息并加以利用已成为一门热门课题。社交网络的快速发展带来了大量的用户社交数据及属性数据,这些数据成为了构架用户画像的基础。个性化推荐能够帮助企业针对不同类型的用户快速制定合适的营销策略,而用户画像对基于个性化推荐系统的应用有很大的帮助,在其中占有举足轻重的地位。用户画像由用户的基本属性和兴趣爱好组成,本文基于微博平台的用户社交信息对用户进行情感分析、兴趣提取,挖掘出用户兴趣偏好及情感倾向,并结合用户属性信息对用户属性进行统计学分析,从三个不同的维度对特定群体用户标签化,从而较为准确地构建出微博平台用户画像。
关键词:用户画像;社交网络;TF-IDF算法;情感分析
Abstract
With the rapid development of the Internet, data is exponentially growing. However, in the huge data information, most of the information is invalid information. How to extract and use effective information from massive data has become a hot topic. The rapid development of social networks has brought a large amount of user social data and attribute data, which has become the basis for the framework of user images. Personalized recommendations can help companies quickly develop appropriate marketing strategies for different types of users, and user portraits are very helpful in the application of personalized recommendation systems, and they play a pivotal role. The user's portrait consists of the user's basic attributes and hobbies. Based on the user's social information of the Weibo platform, this paper analyzes the user's sentiment and interests, extracts the user's interest preference and sentiment tendency, and combines the user attribute information to calculate the user attribute. Analysis, labeling specific groups of users from three different dimensions, thus more accurately constructing the user image of the Weibo platform.
Key words:User’s Profile;social network;TF-IDF algorithm;sentiment analysis
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景 1
1.2 研究意义 1
1.3 论文主要研究内容 2
1.4 论文组织结构 3
第2章 研究综述和理论基础 4
2.1 用户画像构建方法研究综述 4
2.2 用户画像构建理论基础 5
2.2.1 网络爬虫技术 5
2.2.2 中文分词概述与Jieba分词原理 6
2.2.3 TF-IDF算法 8
2.2.4 SnowNLP情感分析 8
第3章 基于微博数据的用户画像构建 9
3.1 微博数据的特点 10
3.2 用户画像构建研究思路 10
3.3 实验数据采集及处理 11
3.3.1 实验数据采集 11
3.3.2 数据清洗与文本去重 14
3.3.3 jieba分词及去停用词 15
3.4 用户画像构建 17
3.4.1 TF-IDF算法提取关键词 17
3.4.2 SnowNLP用户情感分析 19
3.4.3 用户属性分析 20
3.5 实验结果分析及小结 22
第4章 结论与展望 24
4.1 全文总结 24
4.2 未来展望 24
参考文献 26
致谢 27
第1章 绪论
1.1 研究背景
互联网从1964年诞生到现在已经经历了五十余年的风风雨雨,现如今,网络已然成为人们生活中不可分割的一个重要部分,不论是从网络游戏、社交媒体、投资理财还是从网络购物、在线阅读等日常生活操作来说,几乎每时每刻人们都在享受着互联网网络时代在工作、学习、休闲娱乐、交通出行等方面带给我们的便利。随着时代的变换迁移,人们了解并获得信息的主要渠道已经从口口相传发展到如今的互联网。互联网在迅速蓬勃发展的过程中伴随着产生了海量数据,并且这些数据仍在以指数型增长的态势急剧增多。在目前的时代,各种各样的数据渗透于人们生活的方方面面,各行各业都在产生数据、也都需要已然成为企业最重要的生产因素之一的数据。然而,并不是所有的数据都是有效的,大多数数据对于我们而言是无用信息,因此我们需要在海量的数据中寻找出有用的数据进行研究。合理且高效地挖掘数据并对数据中蕴含的信息进行分析运用从而满足不同用户的个性化需求已经成为了目前需要各个行业去解决的问题,因此用户画像的构建十分有必要。对于我们分析用户的行为、制定个性化营销方案、加强用户管理、发展潜在用户从而优化用户体验、增强用户黏性,进而提高核心竞争力、创造更高的收益而言,用户画像的构建有着不可忽视的重大意义。
社交网络的快速发展所带来的海量用户社交信息及用户个人属性数据为我们构建用户画像提供了基础。随着个性化应用深入各行各业,用户画像日益成为人们关注与研究的课题,它为包括个性化推荐和个性化搜索在内的用户个性化应用研究带来了极大的便利,而个性化应用的实现离不开用户画像的构建,用户画像构成了个性化应用的基础。本文以华为手机为例,基于用户在微博平台生成的社交话题内容及用户自定义标签数据进行关键词提取,深度挖掘特定用户群的兴趣偏好及情感倾向,并结合用户的个人属性信息分析,将多个维度结合起来构建生成用户画像。
1.2 研究意义
Web2.0时代催生了大量的社交媒体网络平台,微博就是其中一个典型的社交平台。第42次《中国互联网发展统计报告》数据显示,到2018年6月为止,中国网民规模已经到达8.02亿的数量值,根据2018年Q2微博财报数据显示,2018年6月微博月活跃用户共4.31亿,不难发现,微博用户已经成为中国网民的重要组成部分。作为国内最大的社交媒体之一,微博产生了大量的用户社交信息以及属性信息,因此,根据微博平台用户信息构建用户画像、研究微博平台的用户群体特征极具代表性及研究意义。
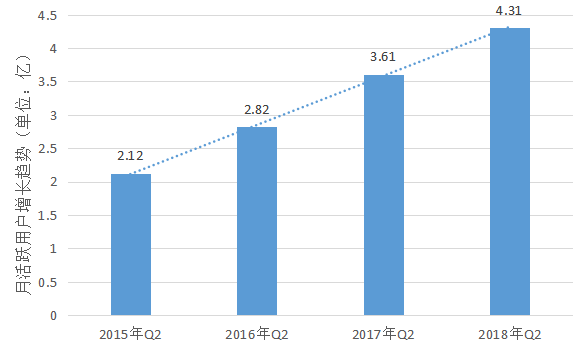
图1.1 微博月活跃用户增长趋势
根据微博平台产生的相关数据进行分析,从而建立用户画像具有极大的应用价值。它能够在信息过载的大数据时代中挖掘出有效信息,同时能帮助我们对用户进行深度刻画。对于企业而言,用户画像能够帮助企业更好地针对用户制定个性化营销策略,挖掘潜在客户、加强客户关系管控、大大提高生产率、促进经济发展;对于微博平台而言,它能够增加用户黏性、提高平台口碑、建立与用户长期稳定的关系、提升效益;对于微博用户而言,用户画像本身能够被用来进一步优化用户体验、提高用户满意度。因此,不论是对企业、微博平台还是微博用户自身,研究基于微博数据的用户画像构建方法,意义都十分重大。
1.3 论文主要研究内容
本文基于微博社交平台上产生的大量社交数据,以参与华为话题讨论的用户群为例,采集微博平台上用户所生成的华为话题内容以及用户在该平台个人资料中所填写的包含地址、生日、学校、公司、性别、自定义标签等在内的属性信息进行文本挖掘分析,从用户带有“#华为#”话题的微博正文文本及用户个人页面所填写的自定义标签中使用TF-IDF算法提取关键词,并采用Python自带的类库SnowNPL对微博正文文本进行情感分析,掌握该类人群的兴趣特征以及对华为品牌的情感偏好,同时根据用户的个人属性信息进行统计学分析,最终结合特定人群的情感偏好、兴趣特征与用户个人属性分析来综合构建华为用户群标签,进行多维度的特定用户群画像研究分析。
1.4 论文组织结构
本论文的主要研究内容是基于微博数据的用户画像构建方法,论文体系结构如下:
第一章主要介绍了本论文的研究背景与研究意义、研究内容、论文的创新点及此篇论文的组织结构。
第二章主要进行了国内外用户画像构建方法研究领域的研究综述,并阐述了本文撰写所使用的理论基础。
第三章为基于微博数据的用户画像构建方法研究,首先从理论部分阐述用户画像的作用、微博数据的特点,并且表明本文的研究思路,接着以华为话题为例,在微博平台进行数据采集、数据预处理操作,进而通过TF-IDF算法、SnowNLP情感分析进行深度分析,并结合用户属性统计特称来分析聚集在华为话题下的特定人群特征、构建用户画像,并对结果进行分析及小结。
第四章为总结与展望,分析了本文研究的意义以及当前研究所存在的不足与缺陷,并对未来进行了展望。
第2章 研究综述和理论基础
2.1 用户画像构建方法研究综述
伴随着社交网络的快速发展,用户在社交平台产生的社交数据及其属性信息也呈现着指数型的增长,从海量用户数据中提炼有效可用信息并且加以分析利用能够为企业大大地节省时间、节约成本、提高效率,使得工作更为便捷。因此,随着各行各业对于个性化应用愈来愈强烈的需求,作为个性化应用中最重要的一个环节——用户画像的构建,已经成为了被目前国内外学者们大量研究的热点课题。社交网络平台上的用户具有不同的兴趣偏好以及个人属性,因此,用户画像的构建能够将用户在计算机可以进行理解分析的基础上进行深刻刻画。为了更好地对用户进行个性化应用,国内外学者对用户画像的构建方法进行了大量的相关性研究。
在用户兴趣的提取方面,雷兵和刘维通过目前单一维度造成用户兴趣模型构建效果不好的现状提出了一种基于关键词、用户行为、用户属性三个维度的综合用户兴趣模型构建[1]。司新霞和余肖生在构建用户兴趣模型时,采用基于加权关键词的方法来完成兴趣模型的构建[2]。宋天勇提出将划分用户浏览历史的单位定义为查询,通过聚类算法组合相似的查询从而实现用户兴趣模型的建立[3]。潘峰、郭鹏、顾其威通过用户对手机广告的操作行为及其历史访问记录来构建用户对于广告的非兴趣模型和兴趣模型,并结合了对用户访问模式的研究,综合生成了用户兴趣模型[4]。张舒雅在传统TF-IDF算法的基础上进行改进,加入对类别相关程度和特征项的考虑,通过使用TFC-IDFC的算法来提高分类效果,从而优化用户特征分析的准确度[5]。何跃、朱超等人通过采集微博文本数据,对其进行情感分析,并识别计算出微博平台用户的影响力,结合这两个维度来进行用户特征的分析[6]。Zhang Yanfeng等学者通过对大量的终端日志进行数据分析与挖掘,对用户特征进行分析[7]。Moore T等人通过用户在平台上的特征标签,采用基于权重的算法监督来完成对用户的特征分析[8]。
在直接对用户画像进行构建研究方面,曾鸿和吴苏倪基于新浪微博平台的数据,采用相关技术手段来简单分析用户数据,基于搜索量、粉丝爱慕值、互动量、提及量四个不同维度进行综合评分,进行粉丝人群用户画像的构建[9]。汪强兵基于微博用户的生成内容预测其包括性别、地区、年龄等在内的基本属性,并采集移动端用户所产生的手势行为进行用户兴趣画像的挖掘分析,结合用户基本属性和用户兴趣画像进行多维度的用户画像构建[10]。费鹏从电网和微博平台两个方面进行用户画像构建方法的研究,并针对微博用户画像的构建提出在卷积神经网络基础上的改进,融合了多粒度特征体系,充分利用多种类粒度[11]。马超将主题模型应用于用户画像的构建上,基于主题模型,提出一种半监督学习算法框架,通过把用户在社交平台上的社交数据以及用户在页面所填写的用户基本属性整合进统一的框架中,并采用标签传播算法对所产生的结果进行更为精细的调整,最终针对社交网络提供一种基于主题模型的用户画像构建方法[12]。储涛涛针对微博短文本,引入LDA主题模型,解决上下文依赖的问题,提高用户兴趣的发现效果[13]。周妹璇基于传统的浅层学习模型存在的问题,提出一种结合梯度提升决策树与深度学习网络的组合模型,以此预测用户画像[14]。Weng Jianshu等学者通过使用主题模型来对推特的数据进行挖掘分析已得到用户的兴趣偏好,从而构建用户画像[15]。
2.2 用户画像构建理论基础
基于加权关键词来对用户画像进行构建研究是目前较为常用的用户画像构建方法之一,与其他用户画像构建方法相比,它的可操作性更强、更为通俗易于理解,且较为简便。随着用户画像的研究更为深入,逐渐衍生出结合关键词抽取方法的多维度的用户画像构建方法,多个维度使得用户画像的构建结果更为精准,因此被广泛普遍开来。本文正是采用这种多维度构建用户画像的研究方法,综合微博用户情感、用户兴趣、用户属性三个维度的结果构建出特定人群的用户画像。通过爬虫技术采集相关微博数据,使用Python语言对文本数据进行清洗、去重、提取等数据预处理操作,并使用其自带的分词包jieba实现对文本的分词、去停用词操作。SnowNLP是Python中专门针对中文语言的一个类库,它可以实现包括文本分类、词性标注、情感分析、文本相似、提取关键词等在内的对中文自然语言的操作,本文主要用其来进行情感分析,得到三个维度之一的用户情感偏好。对于维度中的用户兴趣,通过使用关键词提取的算法进行挖掘。常见的关键词提取算法主要有LDA、TF-IDF、TextRank、PageRank这四种,本文选择易用性更强、简单快捷的TF-IDF加权算法提取关键词并生成对应权重。用户属性维度主要通过对采集到的数据进行统计学分析,生成热力数据地图等易于观察结果的图像。最终根据用户情感倾向、兴趣偏好、属性分析三个维度得到综合用户画像生成词云,完成对用户画像构建方法的研究。
2.2.1 网络爬虫技术
随着大数据时代的到来,网络爬虫技术对于这个时代已经成为不可缺少的一部分,各行各业都需要获取数据进而分析用户行为。网络爬虫技术可以帮助我们便捷快速地完成海量数据的采集,提高生产生活的效率。网络爬虫(又名网页蜘蛛)是通过一定的规则自动提取网页的程序。其结构大致可以由数据、采集、处理、存储等部分组成。它可以选择性地爬取预先指定好的页面,将与指定目标无关的链接通过一定算法过滤,建立等待抓取的URL队列并放入有效的链接。从初始需要抓取的网页的URL开始,获得其URL,然后在还未达到系统的停止条件前,在队列中增添不断获取的新的URL。在此过程中,系统将会存储一切被爬虫爬取的网页,并通过分析、过滤后建立出便于后续查询检索的索引。
2.2.2 中文分词概述与Jieba分词原理
一、中文分词概述
中文中表达语言含义的最小单位就是词,分词是对于自然语言最基础的处理流程,分词效果的好坏与否将会直接影响中文的信息处理结果。目前基于统计的分词方法和基于词典的分词方法这两个类别为实现中文分词的两大基础方法。
基于词典的分词方法
基于词典进行分词的优势在于方法简便快捷,该方法会在初始时构建一个足够大的词典,接着通过一定秩序对文本进行扫描,当词典中的某个词汇与文本中的字词形成匹配就成功完成了分词操作。最少切分、正/逆向最大匹配法与双向最大匹配法为四种较为常见的扫描策略。
(1)最小切分(使每句切出的词数量最少)
先将词典中最长的词与需要分词的文本中的字串进行比对,若比对符合则进行切分,不断重复此过程以在最终将词数分到最少。
(2)正向最大匹配法(方向从左至右)
从首字开始,以从左至右的顺序对文本进行扫描,在当前的位置切分出长度最长的词。对该方法而言,颗粒度越大的词表达的含义越为精准明确。
(3)逆向最大匹配法(方向从右至左)
该方法使用的是将词条逆着顺序排放的逆序词典,可以理解为从末字开始,以从右至左的方式对文本进行扫描。同正向最大匹配法的原理一样,对采用的逆序字典采用正向最大匹配的方法。
(4)双向最大匹配法(使用从左至右、从右至左两种扫描方式)
结合正/逆向最大匹配法这两种方法,使用这两种扫描方式对文本进行扫描及切分,判定分词正确与否是观察切分后这两种方法得到的结果一致。
基于统计的分词方法
基于统计的分词方法与基于词典的分词方法相比较,其优势在于能够较好地将新词与歧义问题进行处理,该方法是利用统计学的方法从已经实现分词操作的众多文本中来研究学习分词规律,以此来完成切分未知文本的任务。CRF即条件伴随机场、基于深度学习的方法以及HMM即隐马尔可夫模型是三种比较常用来进行统计的方法。在标注词性、识别出命名实体对象的研究上,基于深度学习的神经网络序列标注的算法已经有相当不错的进展,这种方法同样可以用到对文本的分词任务上,为了体现其优点,训练语料需要比较大才行。条件伴随机场和隐马尔可夫模型方法的实质是把分词任务转变为对字进行分类的任务,标注出其序列。并不需要依靠初始时就编好的词典,这种把字生成词的途径仅仅只用训练已经完成分词的语料,训练完成即可预测新句子,在这个过程中,就会针对每个不同的字生成不一样的词位。
在实际的分词应用过程中,一般是将基于词典的分词方法与基于统计的分词方法结合起来使用,这样既具有词典分词法简单快捷的优势,又具有统计学习法消除歧义、识别生词的优点,Jieba分词正是这种实际应用的典型代表。



