基于网络爬虫技术的电影点评情感分析研究毕业论文
2021-03-12 23:47:12
摘 要
在互联网社区平台越来越火热的发展趋势下,全民影评的时代已经到来。许多电影网站蕴藏着海量的电影评论信息。对这些信息的挖掘将给电影制作人带来巨大的价值。本文将结合网络爬虫和文本分类技术对电影点评进行情感分析。
论文首先研究了爬虫的原理,然后基于豆瓣网实现了多线程评论爬虫,该爬虫能够随机地挑选不同风格和质量的电影。在取得大量的网页数据后,本文使用页面解析器抽取其中的数据并将其存储至本地。为了使分类器有更好的效果,本文研究了中文分词的多种算法原理,并结合自定义的停用词表对文本进行预处理。
本文研究了常用的特征选择方法和基于监督学习的分类算法。通过对比实验选择出合适的TF-IDF特征选择改进方法。通过对朴素贝叶斯分类算法的优化,构建出一个针对电影点评情感分析的文本分类器。在最后,实现了将分类结果以图形化展示给用户。
关键词:网络爬虫;文本分类;情感分析;朴素贝叶斯
Abstract
With the rapid development of the internet community platform, the era of national film reviews has arrived. Some film websites storage huge number of movie reviews, which contain great value to film-makers. This thesis will combine web crawler and text classification technology for sentiment analysis of film reviews.
This thesis firstly analyzes how to crawl reviews from film websites, and then develops a multi thread crawler which can collect data randomly based on the website of Douban. After a large amount of web data is obtained, this thesis will use a page parser to extract the data and store them at local. In order to make the classifier more effective, this thesis also studies various algorithms for Chinese text segmentation, and combines the custom stop-words to segment the film reviews into word.
This thesis studies in several feature selection methods and supervised machine learning algorithms. Through the contrast experiment, this thesis chooses an appropriate improved TF-IDF algorithm. And after various optimization methods are discussed, a Naive Bayes classification algorithm is proposed to construct a text classifier. Finally, this thesis studies and implements how to display the result in a graphical to users.
Key Words:web crawler; text classification; sentiment analysis; Naive Bayes
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 国内外研究现状 2
1.3 研究内容 4
第2章 数据采集 5
2.1 豆瓣网 5
2.2网页收集 6
2.2.1爬虫的基本原理 6
2.2.2并发执行 7
2.2.3随机选择数据 8
2.3 网页解析 9
2.3.1 Jsoup解析器 9
2.3.2 豆瓣网的评论解析 11
2.4 本章小结 14
第3章 文本预处理 15
3.1 中文分词的原理 15
3.2 IKAnalyzer分词器 15
3.3停用词表 17
3.4 文本表示 18
3.5本章小结 19
第4章 特征选择 20
4.1 常用的特征选择方法 20
4.1.1 文档频率方法 20
4.1.2 信息增益方法 20
4.1.3 互信息方法 20
4.2 TF-IDF特征选择算法 21
4.2.1 基本原理 21
4.2.2 不足与改进 21
4.3 特征选择的实现 23
4.4本章小结 24
第5章 分类器训练 25
5.1常用的文本分类算法 25
5.1.1 支持向量机分类算法 25
5.1.2 k-最近邻分类算法 26
5.1.3 神经网络分类算法 27
5.2分类器的性能评判 28
5.3朴素贝叶斯分类算法 29
5.3.1基本原理 29
5.3.2先验概率 30
5.3.3条件概率 30
5.4 分类器的实现 31
5.4.1拉普拉斯平滑 31
5.4.2 对数转化 32
5.5本章小结 32
第6章 可视化处理 33
6.1 流程设计 33
6.2爬取和分析 34
6.3 结果可视化 36
6.3.1创建词云 36
6.3.2绘制统计图表 38
6.4 本章小结 39
第7章 总结与展望 40
7.1研究工作的总结 40
7.2未来工作的展望 40
参考文献 41
致 谢 43
第1章 绪论
1.1 研究背景
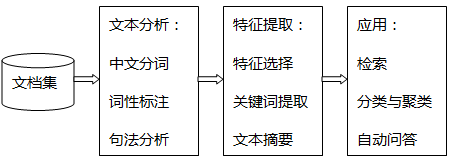 截至2016年12月,中国的网民人数达到了7.3亿,网络已经全面渗透到社会生活中。在这个时代下,人们也开始习惯于在网络上分享自己对热点新闻的观点,或者对某个产品的评价。这些非结构化的文本遍布在互联网的各个角落,它们篇幅短小、表达风格自由,通常包含了发表人鲜明的喜怒哀乐。合理地利用这些海量信息,提取并整合分析数据中包含的观点,可以为政府提供决策支持,及时掌握广大民众对新政策、社会热点事件的情感倾向,也可以使企业更迅速地了解产品的优缺点,理解产品对应的消费者需求,以此来优化产品的设计方式和推广策略。目前全世界已经有许多针对用户评价进行的研究,文本挖掘技术变得越来越有意义。目前业界常用的文本挖掘方法包括:全文检索、关键词提取、中文分词、文本摘要、句法分析、文本聚类、智能问答、文本分类等等,相关技术的整体流程如下所示:
截至2016年12月,中国的网民人数达到了7.3亿,网络已经全面渗透到社会生活中。在这个时代下,人们也开始习惯于在网络上分享自己对热点新闻的观点,或者对某个产品的评价。这些非结构化的文本遍布在互联网的各个角落,它们篇幅短小、表达风格自由,通常包含了发表人鲜明的喜怒哀乐。合理地利用这些海量信息,提取并整合分析数据中包含的观点,可以为政府提供决策支持,及时掌握广大民众对新政策、社会热点事件的情感倾向,也可以使企业更迅速地了解产品的优缺点,理解产品对应的消费者需求,以此来优化产品的设计方式和推广策略。目前全世界已经有许多针对用户评价进行的研究,文本挖掘技术变得越来越有意义。目前业界常用的文本挖掘方法包括:全文检索、关键词提取、中文分词、文本摘要、句法分析、文本聚类、智能问答、文本分类等等,相关技术的整体流程如下所示:
图1.1 文本挖掘的流程
实际上从数学原理的角度来看,分类是一个不难理解的操作,如下所示:假设一个类别集合,一个待分类的项集合,以及一个分类器,使得对任意而言,有且仅有一个能够使得成立。其中核心的影响因素是分类器的性能,许多研究学者因此花费大量时间和精力不断地优化分类算法,以此提升分类器的质量和性能。而文本分类的目的则是构建一个能够对输入文本进行分类的分类器,这种自动分类技术使得用户能够对海量的信息有一个更加直接和清晰的认知。
在对文本自动分类的需求越来越火热的趋势下,可以发现互联网上只要有海量文本信息的地方,都能利用文本分类技术进行适当的挖掘并得到利益。全民影评时代的来临,越来越多的人开始在网络上发表自己的观影评论。据统计,2016年中国的电影总票房已经达到457亿元,观影人次将近14亿,这导致一部热门电影通常在上映后的短短几天之内,在一些电影社区网站上就能得到几万条甚至几十万条短评。通过相关的技术挖掘这些影评包含的观众情感并进行分析,无论是对电影制作人还是投资商都有着巨大的价值。而目前中国在电影评论这块的情感分类研究还比较少。
1.2 国内外研究现状
针对电影点评的情感分类,实际上属于文本情感分类的一个范畴。文本分类的基本流程如下:
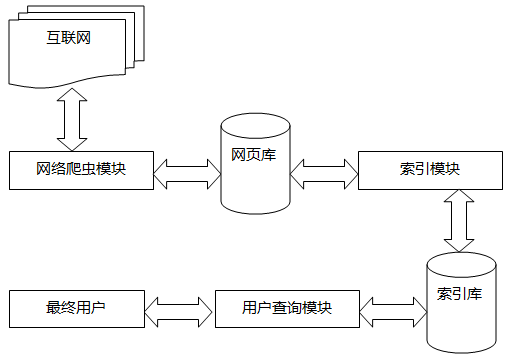
图1.2 文本分类的基本流程
文本情感分类的方式有很多种,通常研究学者会结合其中的多个方法来更好地进行分类。其中基于语义的方法主要分析文本中词语的语义以及词性,这种方式的优点是领域的应用范围广,但针对中文的文本分类,其存在的歧义问题可能会影响精度。另外还有基于监督学习的分类算法,也可以称为基于统计的方法,其目的是通过大量的样本数据来计算出一个目标函数或者目标分布。这种方法构建出来的分类器一般拥有比较高的分类精度,但是也非常容易受到训练样本的影响。
对于文本分类,大多数的研究实验都是根据以下几个阶段进行:首先是文本的预处理,然后进行特征选择,最后使用某种分类算法进行训练。其中文本处理一般包含分词、词性标注等等。
Recchia G等人使用点互信息的度量值来得出某个词语和极性词之间的相似度,并以此来判断该词语的类别倾向性[15]。
Abhiteja Gajjala提出了一个多层次模型的分类系统,并在实验中分别使用了软件Weka的朴素贝叶斯分类器、软件包SVMlight的SVM分类器、软件包Scikit Learn的随机梯度下降分类器。实验结果表明了采用随机梯度下降分类算法的分类器拥有较高的分类精度[8]。
徐军等人使用包含正面和负面的新闻和评论进行实验,实验过程中分别采用词频方法和二值方法计算特征权重。实验结果表明,如果文本分类是基于主题的,那么采用词频方法得到的效果要好一些;如果是基于情感的,那么采用二值方法得到的效果要好一些。同时他们还发现使用最大熵分类方法,在多数情况下其准确率要比贝叶斯分类方法高一些。除此之外,他们研究了对否定词的处理方式,比如将其和后面跟着的第一个对象进行结合,组合为一个特征,实验证明这种处理对分类的准确率有一定的提升效果[11]。
文本中可能有几万个不同的词条,不能将所有词条都作为分类时的依据,例如“的”、“了”这些助词实际上并不会影响分类的结果。如果最终参与分析的特征词个数越多,那么分类器进行计算的时间就需要花费得更多,而整个模型也会变得更加复杂,考虑到分类器的运行效率,特征提取是非常有必要的,这个处理步骤也称为降维。
特征提取一般可以被分成是特征选择和特征抽取两种方式,其中特征选择方法是从词条集中提取出具有代表性的较少量的词条作为特征,特征抽取方法则是从词条集中重构出新的结构,比如利用LSI(潜在语义索引)方法将其转为矩阵,使得生成的特征能够拥有更强的代表性。这些方法有助于降低矩阵的维度,去除文本噪音,提高计算速度和分类效果。许多人专门对特征选择方法进行了研究。
刘志明等人针对微博平台上的数据进行了研究。在实验过程中使用了不同的计算特征权重的方法以及特征选择方法,结果表明结合支持向量机分类算法、信息增益特征选择方法以及TF-IDF权重计算方法进行分类,产生的效果要好一些[10]。
Yang Y等人采取不同的特征选择方法进行了实验,结果表明信息增益方法和CHI方法在平面文本分类的实验中产生了较好的影响,同时也在文献中指明了当信息增益方法和CHI方法的计算成本太高时,词频方法也是一个可以依赖的方法[9]。
唐慧丰等人使用N-Gram模型并结合不同词性的词语来作为文本的表示方式,实验中采取了多种特征选择方法,比如信息增益、文档频率以及互信息等,并结合不同的分类算法来进行分类实验。实验结果表明信息增益方法可以产生较好的结果[14]。
1.3 研究内容
在本文中,将会使用豆瓣网的电影短评作为样本训练分类器,然后通过多次实验来改进相关的算法,最后将分类器应用到具体的一部电影评论情感分析中,并将分析结果以图形化展示。
本文主要研究了以下几个方面:
分析豆瓣网的平台特点和反爬虫策略,设计特定的多线程影评数据爬取程序,收集到的数据要能保证包含各种风格和质量的电影。
研究中文分词的原理,并深入了解相关的分词工具。
研究特定的特征选择方法和机器学习算法,并针对项目进行算法的修改和完善。
实现一个简单的影评分析系统,以此将分类器投入到实际的应用中,并结合可视化技术将结果展示出来。
第2章 数据采集
本章将对豆瓣网平台以及爬虫的原理进行分析,并以豆瓣网的影评为数据源,实现多线程的随机爬虫。
2.1 豆瓣网
豆瓣网是目前最火热的书影音相关的在线社区网站,其在2012年的时候就已经拥有了超过1亿的月独立用户数量,网站的每天访问量也达到了1.6亿。在豆瓣网上,核心用户群是白领和大学生,这些群体热爱活跃于互联网上,分享自己喜爱的电影、书籍和音乐,他们可以依据自己的喜好自由地发表一些观点。同时豆瓣网简洁亮丽的界面风格和不定期举办的线上主题活动,也吸引了许多文艺青年驻扎在他们感兴趣的社区里,这使得豆瓣网从创办至今仍保持着强健的用户增长速度。
本文将豆瓣网作为爬虫程序的采集目标,不仅仅因为它有着非常活跃的电影社区,从而包含了丰富的语料资源,更重要的是用户的每条评论都可以配备一个星级评分,等级总共为5个,对应的分值分别是10、20、30、40和50分,这将有利于基于监督学习的分类算法的标签输入。
豆瓣网为每一部电影都分配了一个ID号,比如电影《叶问》的ID为3041806,那么可以拼接出这部电影的第一页评论的虚拟目录为:



