基于循环神经网络的语音频带扩展技术毕业论文
2020-03-30 12:16:10
摘 要
由于历史原因和经济原因,大多数通信系统所传输的语音信号的带宽一般都小于4kHz。与宽带语音相比,窄带语音在清晰度和自然度等方面均表现不足。语音频带扩展技术可以提高传输语音的质量,满足更多场合对高质量语音传输的需求。因此,研究语音频带扩展方法有重要意义。
语音作为典型的时间序列信号,每帧数据之间具有很强的关联性。传统深度神经网络模型通过拼接多帧相邻语音特征的方法引入上下文信息;为了更加充分地利用语音序列间的关联性,本文采用具有时序建模能力的循环神经网络模型来预测宽带语音的频谱;在循环神经网络模型基础上,本文还引入了注意力机制,有效避免了普通循环神经网络存在的梯度爆炸和梯度消失的问题,并实现了长时依赖。
实验结果表明,通过拼接帧的方法引入上下文信息比无上下文信息的频带扩展系统的合成语音质量要更好;而能够充分利用语音序列信号强关联性的长短时记忆网络取得的主客观评估结果要优于拼接帧的系统;在此基础上加入了注意力机制的训练模型则取得了比长短时记忆网络模型更高的估计准确率,进一步提高了频带扩展系统的性能。
关键词:频带扩展;循环神经网络;长短时记忆单元;注意力机制
Abstract
Due to historical and economic reasons, the bandwidth of speech signals transmitted by most communication systems is generally less than 4 kHz. Compared with wideband speech, narrowband speech does not perform well in terms of clarity and naturalness. The speech bandwidth extension technology can improve the quality of speech transmission and meet the demand for high-quality speech transmission on more occasions. Therefore, it is important to research the speech bandwidth extension method.
As a typical time series signal, speech has a strong correlation between each frame of data. The traditional deep neural network model introduces context information by splicing multiple frames of adjacent speech features. To make full use of the correlation between speech sequences, a recurrent neural network model with time series modeling capability is used to predict the frequency spectrum of wideband speech. Based on the model of recurrent neural network, the article also introduced the attention mechanism, which effectively avoided the problems of gradient explosion and gradient vanishing in recurrent neural networks, and achieved long-term dependence.
The experimental results show that the splicing frame method introduces better context information than the bandwidth extension system without context information; and the subjective and objective evaluation results obtained from the long-short-term memory network that can fully utilize the strong correlation of the speech sequence signals. The system is superior to the splicing frame system; on the basis of this, the training model with the attention mechanism is adopted to obtain a higher estimation accuracy than the long short-term memory network model, which further improves the performance of the bandwidth extension system.
Key Words: bandwidth extension; recurrent neural network; long short-term memory unit; attention mechanism.
目 录
摘 要 I
Abstract II
第 1 章 绪论 1
1.1 背景和意义 1
1.2 国内外研究现状 1
1.3 语音质量评估方法 3
1.3.1 客观评估方法 4
1.3.2 主观评估方法 4
1.4 主要研究内容和论文结构 5
1.4.1 主要研究内容 5
1.4.2 论文结构 6
第 2 章 基于深度神经网络的频带扩展方法 8
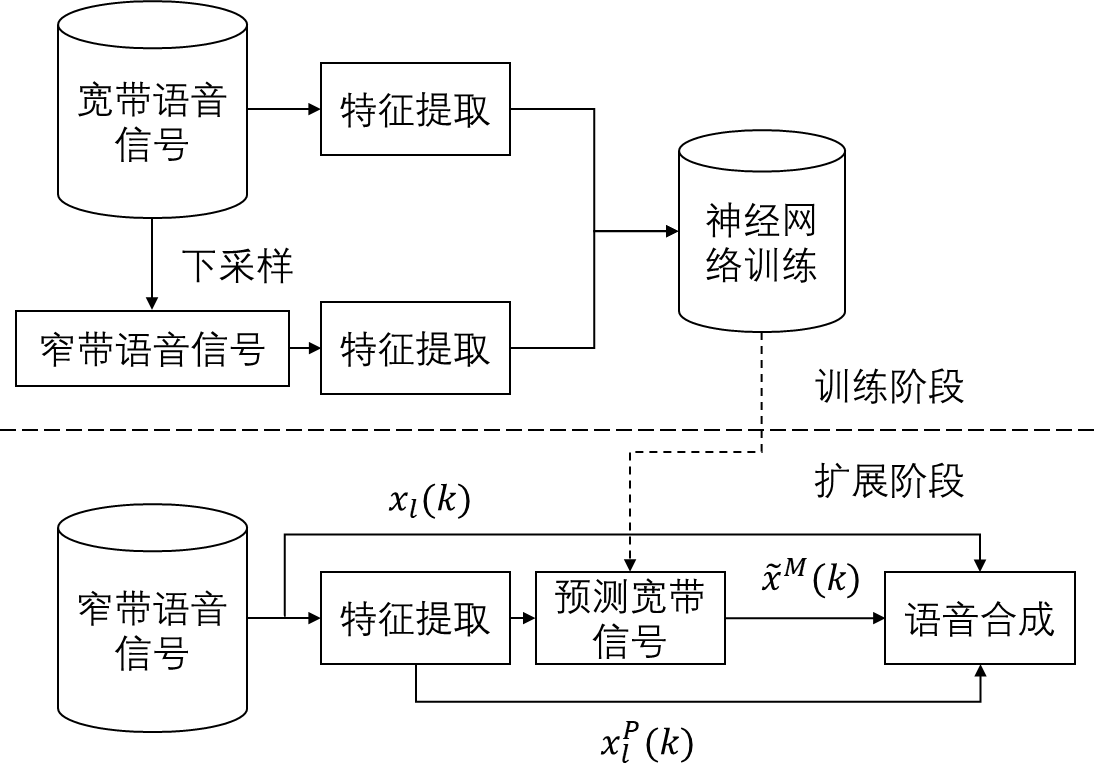
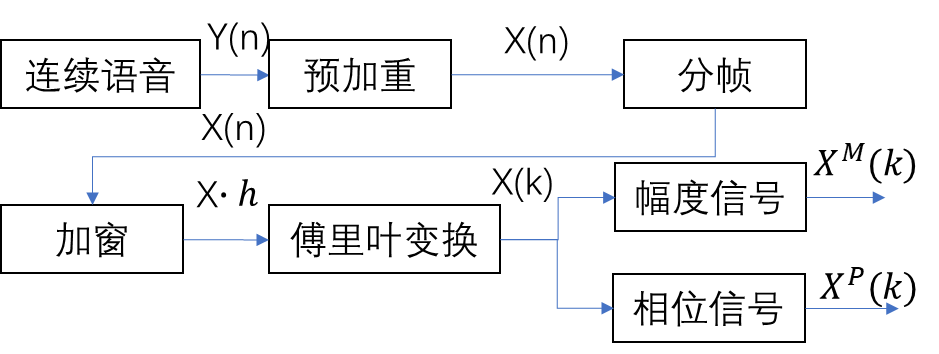
2.1 特征提取 8
2.2 深度神经网络训练模型 10
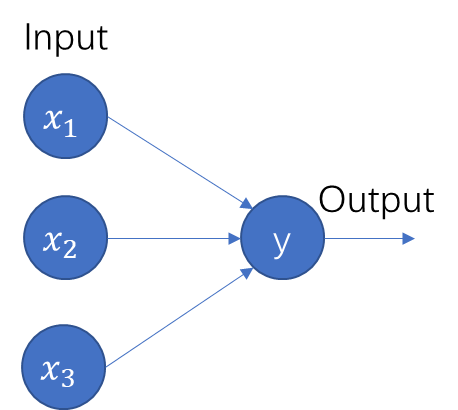
2.2.1 感知机 10
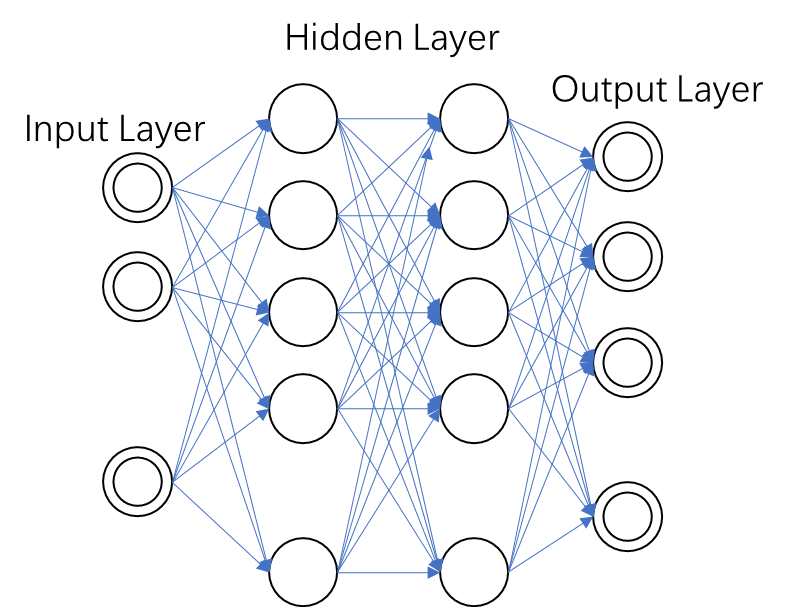
2.2.2 深度神经网络 10
2.2.3 训练模型 11
2.3 基于上下文信息的DNN训练模型 13
2.4 语音合成 13
2.5 实验结果 14
2.5.1 客观评测 15
2.6 本章小结 17
第 3 章 基于循环神经网络的频带扩展方法 18
3.1 循环神经网络训练模型 18
3.1.1 循环神经网络和长短时记忆单元 18
3.1.2 训练模型 20
3.2 基于注意力机制的循环神经网络训练模型 21
3.2.1 注意力机制 21
3.2.2 训练模型 23
3.3 实验结果 24
3.3.1 客观评测 24
3.4 本章小结 27
第 4 章 总结与展望 28
参考文献 30
致 谢 32
绪论
1.1 背景和意义
声音作为可以承载特定信息的信号,对于人类社会有着非比寻常的意义。人类不仅可以发出上万赫兹的声音,也可以听到20Hz-20000Hz频率范围内的声音,因此语音已经成为了人类社会生活中获取信息和传播信息的重要手段。人类语音的信息主要包含在50Hz-8kHz的频率范围内,但受到通信网络中诸多方面因素的影响,大多数公共语音传输系统只能在300Hz-3.4kHz的频谱区域提供语音服务,该频率范围的语音信号称为窄带语音信号。
随着人类社会的进步,信息技术高速发展,人们可以凭借无线通信手段摆脱地域束缚,利用移动通信设备进行快捷便利的交流。生活水平的提高,使人们不再满足仅仅能听到声音,开始渴望更真实的语音通话服务。虽然窄带语音降低了语音传输系统的经济成本,但为此丢失了语音中高频区域的信息,牺牲了语音的自然性。在很多对语音通话质量要求比较高的场合,窄带语音不太能满足使用者的需求。研究表明,语音信号的高频区域蕴含丰富的声学信息,因此宽带语音的清晰度、可辨识度、音色和自然度等比窄带语音要强很多。由于很多辅音的频谱能量主要集中分布在高频区域,所以高频信号成分的缺失会降低原始语音的表现力,导致语音质量下降,同时会导致语音的可辨识度下降,影响听者对说话人的辨识。为了满足语音视频通话和电视电话会议等新兴市场需求,宽带语音传输已经成为通信系统发展的必然趋势。
作为一种有效提高音频质量的方法,语音频带扩展技术已经成为了音频处理领域的研究热点。频带扩展技术通过对解码后缺少高频信息的窄带音频信号进行高频重建生成平行的宽带信号,它可以由低频信号或低频信号加少量高频信息扩展出原始信号的高频部分[1] 。一个高效的频带扩展方法不仅可以结合各种音频编解码器,从音质和实时性上大幅度提高音频传输的质量。也可以结合语音研究领域中其它研究方向的技术方法,进一步改善相应研究方向的系统性能。
1.2 国内外研究现状
随着生活质量的提高与现代化步伐日渐加快,人们已不满足现有的只能够传输窄带语音信号的公共语音传输系统,更加追求语音信号的质量。显然,带宽不足的语音信号难以满足人们对高质量语音的需求。针对这一问题,研究人员已经研究出了很多基于不同方法的频带扩展系统。根据是否利用表示高频的信息,可将语音频带扩展方法分为非盲式和盲式两大类[1] 。非盲式的频带扩展方法除了要在信道中传输低频信息外,还需要附加一部分高频信息,所以增加了传输系统的成本;而盲式的频带扩展方法只传输低频信息,不需要添加任何高频信息,相应的成本也低于非盲式的方法。因此盲式频带扩展方法成为了语音频带扩展领域的研究重点。
盲式频带扩展方法通常依照源-滤波器模型进行建模[2] 。源-滤波器模型一般包括两个模块,即带宽激励信号估计和宽带谱包络估计模块。宽带谱包络估计模块有多种形式,较为普遍的几种形式为码本映射(Codebook Mapping, CM)[4] ,线性映射[5] ,高斯混合模型(Gaussian Mixture Model, GMM)[6] ,隐马尔科夫模型(Hidden Markov Model, HMM)[7] 和人工神经网络(Neural Network, NN)等。
码本映射(N.Enbom等人)通过对大量已有数据进行某种算法,训练得到一对映射码本。这对码本分别是窄带语音提取的特征矢量和对应的宽带语音提取的特征矢量。码本映射的过程:输入窄带语音的特征矢量后,通过在预先训练好的窄带码本中查找与输入矢量最接近的码字并得到该码字的索引,将该索引映射到宽带码本中,从而得到其对应的码字作为输出矢量。常用的码本映射方法有:内插码本映射,直接码本映射和多重码本映射。码本映射在训练码本阶段假设语音的高频频谱信息存在一定的规则,基于这种假设重建的语音信号质量相对较差。
线性映射(Y.nakatoh等人)作为另一种估计谱包络信息的频带扩展方法,其映射关系如公式1.1所示:
(1.1) |
其中,x表示窄带信号的特征矢量,y是待估计的宽带信号的特征矢量,A是通过大量已有数据训练得到的转换映射矩阵。窄带信号特征矢量通过转换映射矩阵得到宽带信号特征矢量。常用的线性映射方法有:直接线性映射和分段线性映射。线性映射假设宽带特征参数与窄带特征参数满足线性映射关系,而语音的宽带特征参数和窄带特征参数之间并不是简单的线性关系,所以得到的宽带特征矢量误差较大。
传统的高斯混合模型以窄带特征参数矢量x为输入,计算窄带特征参数和宽带特征参数的联合概率密度函数,其结果即为宽带信号特征矢量y的值。虽然该方法和传统的码本映射等方法相比估计的宽带矢量准确度更高,但由于协方差估计不准确导致扩展的宽带特征的细节信息丢失,从而容易产生预测的特征矢量过度平滑的现象。由此合成的语音音质也会有所下降。
统计映射法中不同语音信号特征参数的概率分布由高斯混合模型生成,同时宽带信号的特征参数通过窄带信号特征参数和高斯混合模型估计得到。高斯混合模型可以较好的描述窄带特征参数和宽带特征参数之间的相关性和非相关性,所以与传统映射方法相比提高了估计的准确度,但是该方法没有考虑语音的时序相关性。针对这个问题,隐马尔科夫模型假设当前帧语音与上一帧语音相关,这种改进有效地减少了不必要的噪声。可是使用该模型进行频带扩展时,如何选择合适的特征参数是一个很大的挑战。
虽然传统的HMM、、GMM等统计模型在语音频带扩展研究中表现的比传统的码本映射等方案出色,但这些模型依然存在极大的不足。例如 这些声学模型只能对低纬数据进行建模,合成的语音存在主观听感表现力不足、声音情感度不够丰富等问题。近年来,神经网络的出现逐渐替代了这些传统的声学模型,一系列基于神经网络的深度学习方法被应用在语音频带扩展研究中来。神经网络之所以优于这些传统的声学模型,原因有二:(1)人工神经元的非线性特性可以构成非线性的神经网络,使神经网络可以更好的针对复杂的非线性的声学参数进行建模,提高了模型的学习精准率;(2)神经网络没有任何对输入特征的先验假设,其输入特征是原始语音信号的特征矢量。当神经网络模型更强大、更复杂,学习能力更强的时候,就可以处理更丰富的特征。在语音频带扩展研究中,传统的建模方法只适用于对梅尔倒谱或者线谱对系数等低阶谱表征的建模,而神经网络(Neural Network, NN)直接对原始的谱包络参数或者幅度谱特征进行建模[7] ,更好的保留了频谱细节,使神经网络具有更加精准的声学建模能力。实验表明基于神经网络的频带扩展方法与传统的GMM、HMM的频带扩展方法相比,在对数谱失真(Log Spectral Distortion, LSD)和客观语音质量(Perceptual evalutation of speech quality, PESQ)评估等客观指标和主观倾向性测听上都具有明显的优势。
1.3 语音质量评估方法
语音质量包括清晰度和自然度两个方面的内容。清晰度衡量语音中字、词和句的清晰程度,自然度主要指说话人的辨识度。语音质量评价从评价主体上讲可以分为两大类:主观评价和客观评价。主观评价依靠测听者给语音进行打分,直接反应人本身的观点,更能体现人耳对语音的倾向性;但主观评价的缺点是费时费力,重复性差,难以组织实施,不够灵活,同时容易受人的主观因素影响等。客观评价要是针对主观评价方法的不足提出的,它通过对比原始语音信号和合成语音信号的特征参数,借用算法计算误差率或者得分情况对合成语音的质量进行评估。本文主要采用的客观评价方法是:客观语音质量评估(Perceptual evaluation of speech quality, PESQ)和对数谱失真(Log Spectral Distortion, LSD)。
1.3.1 客观评估方法
(1) 客观语音质量评估(Perceptual evalutation of speech quality, PESQ)
PESQ将原始信号和合成信号通过电平调整,再用输入滤波器模拟标准电话听筒进行滤波。原始信号和合成信号要在时间上对准,并进行听觉变换,这个变换包括对系统中线性滤波和增益变换的补偿和均衡。两个听觉变换后的信号之间的不同作为扰动,即为差值。分析扰动曲面提取出两个失真参数,在频率和时间上累积起来,映射到主观平均意见分的预测,即可得到PESQ结果。PESQ得分范围在-0.5-4.5之间。得分越高表示语音质量越好。(2) 对数谱失真(Log Spectral Distortion, LSD)
LSD的计算公式如下:
(1.2) |
其中,和分别代表原始语音信号和合成语音信号第t帧中第k个频点对应的对数谱幅度,T是语音分帧后的帧数,N是短时傅里叶变换中的频点数目。
对数谱失真的评价准则:LSD值越小,说明预测得到的宽带语音信号更接近原始值。
1.3.2 主观评估方法
虽然客观评价方法使用简单方便,但是计算的数据结果不能完全代表人类对语音的主观感受,因此本文设计了一种主观测听实验,用来比较不同方法合成的语音信号的主观听感。
具体测试方法如下:选择5个人进行实验,为每个测听者随机选取多组测听信号,每一组包括五段语音信号,第一段语音是原始语音,第二段到第五段语音分别是经过不同方法合成的语音信号,将这四段语音分别标记为D信号,M信号,L信号和A信号。为了保证测听结果的公正性,测听者每测听一组数据后休息3分钟再继续测听,每段语音信号时长最好保证在10秒左右。评价准则为测听者对语音信号的倾向性,通过测听语音信号给出其认为听起来最舒服的文件标号,同时为同组的其它语音进行排序。
1.4 主要研究内容和论文结构
1.4.1 主要研究内容
本文研究主要基于神经网络进行频谱映射来估计缺失的高频频谱。结合目前流行的多种深度学习方法,以训练性能更为优越的神经网络模型为目的开展语音频带扩展的研究工作。虽然基于神经网络的频带扩展方法较传统方法已经取到了很大的进展,但是其依然有提升的空间。
基于深度神经网络(DNN)的频带扩展方法中每一帧之间是相互独立的,几乎未曾考虑帧与帧之间的关联性。语音信号作为一种典型的时间序列信号[11] ,其时间序列上的相关性是很强的,充分利用语音信号时间前后的强关联性可以提升语音频带扩展系统的性能。因此本研究以基于DNN的语音频带扩展方法为基线系统,在其基础上通过拼接时间帧引入了语音的上下文信息,但这只是对语音信号帧之间关联性的模拟实现。针对该问题,本研究提出了循环神经网络(Recurrent Neural Network, RNN)[11] ,它通过神经元的自连接达到了利用序列帧间相关性的目的。然而普通RNN存在着梯度消失或者梯度爆炸的问题,这就导致RNN在实际中只能处理短期依赖关系。LSTM作为一种特殊的RNN网络[13] ,它不仅避免了梯度消失或者梯度爆炸的问题,而且可以解决长期依赖的问题,这表明它可以更好地利用语音信号的长时相关性。此外,本文研究也受到了Attention机制的启发[14] ,Attention机制最早是在视觉图像领域提出来的,但现在已经广泛应用于语音识别、自然语言处理等领域。LSTM模型对每帧数据的权重设置是一样的,而Attention机制会从大量信息中有选择地筛选出少量重要信息,忽略大多不重要的信息。将Attention机制引入频带扩展任务可以使神经网络模型可以将更多的注意力放在关键信息上,更好地学习多种内容模态之间的相互关系,从而提升频带扩展的性能和合成语音的质量。
本研究将针对上述提到的几种基于神经网络的语音频带扩展方法进行研究,论文的技术路线如图1.1所示,整个研究工作主要包含以下三个研究点:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: