基于深度学习的图像分类方法分析与研究毕业论文
2020-04-01 11:01:16
摘 要
图像分类问题是计算机视觉领域中的重要问题之一,并且在实际中也有着各种各样的应用,所谓图像分类就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签并分配给该图像的问题。由于受图像视角、大小、光照、背景等问题的影响,图像分类存在诸多难点。图像分类大量利用了机器学习的方法,机器学习中的分类算法一般可以分为两类,一是基于人为构造特征的分类方法,如 K-近邻算法、支持向量机、逻辑回归等;二是以卷积神经网络为基础的,直接将图片作为输入而不需要人为构造特征的深度学习方法。目前后者已经可以达到很高的正确率,成为图像分类问题采用的主要方法,并且应用的范围也越来越广。
本文首先讨论了两类机器学习算法,着重分析了卷积神经网络算法,分析了基于卷积神经网络的经典网络模型,AlexNet、VGGNet、GoogLeNet和ResNet。然后以卷积神经网络算法为基础,基于CIFAR-10数据集,训练卷积神经网络模型,在测试集上正确率达到90%以上。最后本文实现了可视化,输入特定格式的图片,直观的展示分类结果。结尾会对图像分类问题做出总结,并对未来的方向进行探讨。
关键词:图像分类;卷积神经网络;深度学习;
Abstract
Image classification is one of the most important issues in computer vision, and it also has a variety of applications in practice. The so-called image classification is a set of fixed classification labels, and then for the input image, find a classification tag and assign it to the image from the classification label set. Machine learning can be used to solve this problem. Due to the influence of image perspective, size, light, background and other issues, there are many difficulties in image classification. Image classification uses a lot of machine learning methods. The classification algorithms in machine learning can generally be divided into two categories. Those based on human structural features, such as K-nearest neighbor algorithm, support vector machine, logistic regression, etc. The other one is convolutional neural networks, which are based on the direct use of pictures as input without the need for artificially constructed features for deep learning. At present, the latter has already reached a high accuracy rate, and has become the main method used for image classification problems, and has been applied for many areas.
Firstly, this paper studied two types of classification algorithms, one is traditional machine learning algorithm, and the other one is deep learning. I also analyzed classical network models based on convolutional neural networks, such as AlexNet, VGG, GoogleNet, and ResNet. Then, based on the CNN algorithm and CIFAR-10 dataset, I constructed a convolutional neural network. The model achieved good performance on the training set and the test set. I also implemented the GUI, which inputs images in a specific format, and visualizes the classification results. Finally, I summarized the problems of image classification and discuss the future direction.
Key Words: image classification; CNN; deep learning;
目 录
摘 要 1
Abstract 2
第1章 绪论 1
1.1 课题研究背景与意义 1
1.2 国内外研究现状 1
1.3 论文主要工作 3
1.4 论文组织结构 3
第2章 分类算法研究 4
2.1 传统机器学习分类方法 4
2.2 卷积神经网络 5
2.2.1 概述 5
2.2.2 卷积神经网络特点 6
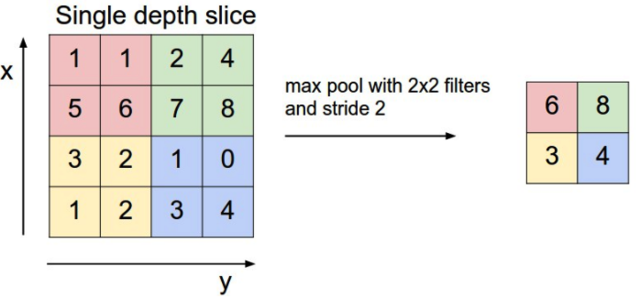
2.2.3 卷积神经网络结构 7
2.3 经典图像分类模型 9
2.3.1 IMAGENET数据集 9
2.3.2 ALEXNET 10
2.3.3 VGGNET 12
2.3.4 GOOGLENET 13
2.3.5 RESNET 14
2.4 本章小结 15
第3章 基于卷积神经网络的图像分类系统实现 16
3.1 CIFAR-10数据集 16
3.2卷积神经网络模型设计 16
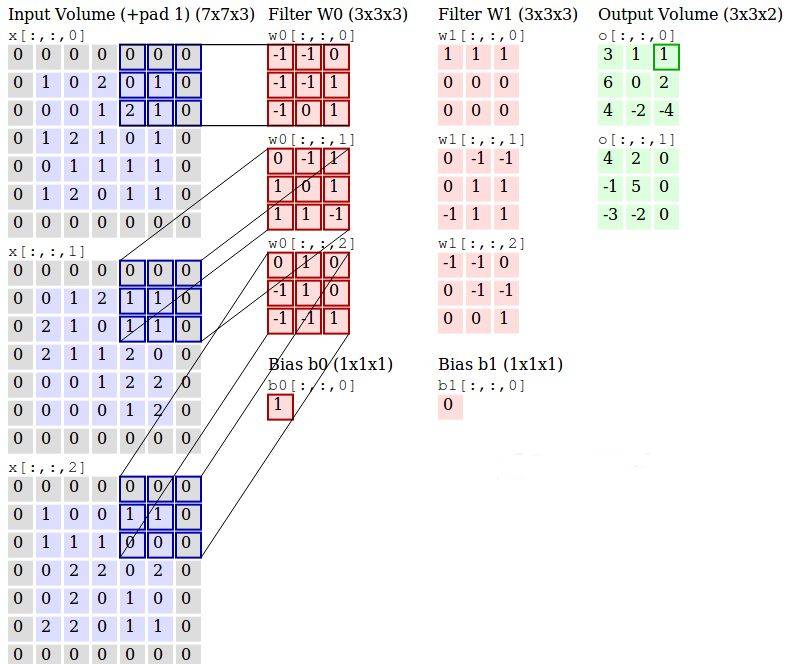
3.2.1 卷积层 17
3.2.2 全连接层 18
3.2.3 输出层 19
3.3 训练方法 20
3.3.1 反向传播算法 20
3.3.2 参数初始化 22
3.4 训练结果分析 23
3.5 本章小结 23
第4章 可视化实现 24
4.1 Electron简介 24
4.2 设计与实现 25
4.3 本章小结 28
第5章 总结与展望 29
5.1 本文总结 29
5.2 研究展望 29
参考文献 30
致谢 31
第1章 绪论
1.1 课题研究背景与意义
随着互联网的飞速发展和各种硬件设备的发展,图像、视频等视觉数据正义极快的速度增长,近几年移动互联网的爆发式发展更是促进了互联网中的视觉数据规模的扩大。以图像搜索为例,实际也包含图像分类的应用,由于人工分类存在低效、成本高等致命缺点,这种方式已经无法满足实际需求。此外,图像分类在很多其它领域也有着广泛应用,例如人脸识别、交通场景识别、视频分析、自动相册归类、医学图像识别[1-3]等。图像分类还是计算机视觉领域中的、、、等其他图像识别任务的基础。
通过机器学习的方法建立分类模型,让图片可以自动分类有非常重要的实际意义,可以有效地提高效率、降低成本。随着学术界和工业界对机器学习研究的不断深入,特别是深度学习和大数据的迅猛发展[4],使用更大的数据规模和更复杂的模型成为可能,同时硬件性能的发张也让机器对图像的识别能力正不断上升,在一些标准数据集上的识别错误率于最近几年也不断降低,甚至超过了人类。
如今,不止学术界,工业界的一些如Google、Facebook和百度等大公司和许多新兴的创业公司都加大了在深度学习领域的投入,并做出了瞩目的成果,例如来自Google的DeepMind团队推出的围棋程序AlphaGo在2016年战胜世界级棋手李世石;微软还推出了名为“牛津计划”的机器学习应用程序界面,可让产品轻松受益于机器学习,对这个方向的投资可以为未来的产品竞争提供机会。在大数据时代,互联网每时每刻产生的数据都蕴含丰富的商业价值,挖掘这些价值不仅对企业也对社会都具有重要的意义,而图像识别技术正是挖掘这些价值的重要工具之一。
1.2 国内外研究现状
图像分类是领域中的一个重要问题,一直以来都备受研究人员的关注,也不断有新的解决方案被提出来,例如利用决策树模型和图像空间关系对图像进行分类[5],运用贝叶斯模型对图像进行识别[6]。图像分类的研究可以分为两部分,一是传统机器学习,二是深度学习。传统的机器学习领域中,图像分类的流程是首先对图片进行特征提取和筛选,这个工作被称为特征工程,比较有名的特征提取算法有(Scale-invariant feature transform,SIFT)、(Histogram of Oriented Gradient, HOG)等;然后将得到特征向量输入合适的分类算法完成特征分类,常用的分类算法有支持向量机(Support Vector Machine,SVM)、决策树和逻辑回归等。这种方法特别依赖于所提取的图像特征,在神经网络之前,图像分类问题主要就是特征提取的问题,提取的特征好,整体效果就好。神经网络是另一类方法,特别是卷积神经网络,采用深度学习的方法已被证明可以得到很好的分类效果。
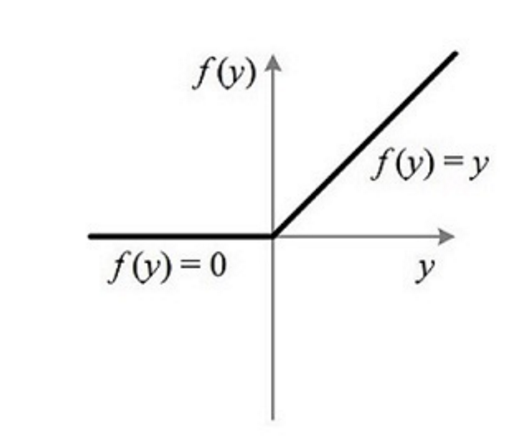
上世纪六十年代,Frank Rosenblatt提出了感知核函数[7],感知核函数的是一个简单的数学模型,这个运算过程可以想象成通过计算一系列带权重的事件是否发生来做判断。现在的神经网络模型中大多使用其它激励函数,例如Sigmoid、Tanh、ReLU等,但感知核函数仅通过叠加把带权输入求和,然后判断是否超过阀值这个操作,就能够模拟各种复杂的逻辑运算,体现了神经网络的强大,对机器学习的发展具有十分重要的意义。
神经网络很早就被提出,是受到生物神经网络功能的运作启发而产生的,最早的神经网络被称为感知机,只有一层,随后又提出了多层感知机,其中重要的一个里程碑就是反向传播算法的提出。但是使用神经网络的方法进行图像分类,得到的效果并不好,效果还不如已有的SVM等方法,优化也十分困难。现在的神经网络一般包括、和,每层由一定数目的神经元构成。输入层处理原始的数据,隐藏层是神经网络的主体部分,可以是一层也可以是重复的多层,输出层为输入数据各种类别的得分,神经网络一般采用Sigmoid等激活函数来增加网络模型的非线性特性。
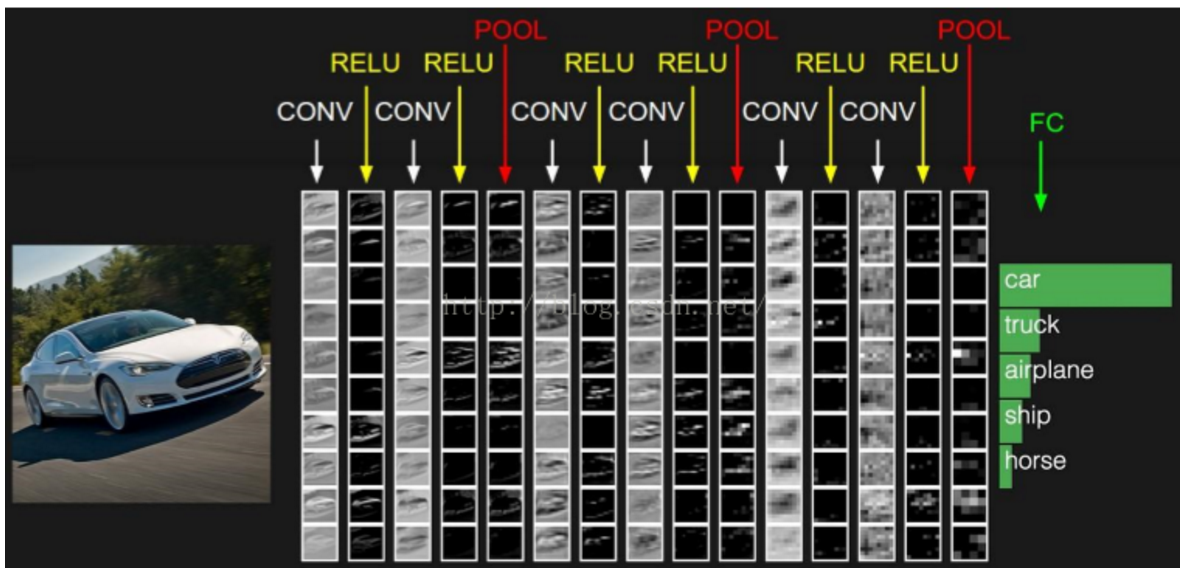
(Convolutional Neural Network,CNN)是一种前馈人工神经网络,它的结构使其特别适合用于视觉图像分析,除此之外,也可应用于时间序列信号分析、推荐系统和自然语言处理等。相比于传统的机器学习分类算法需要使用SIFT等算法人工提取特征,卷积神经网络可以直接利用原始的图像来进行训练,自动提取图像特征,不依赖于任何人工特征提取。
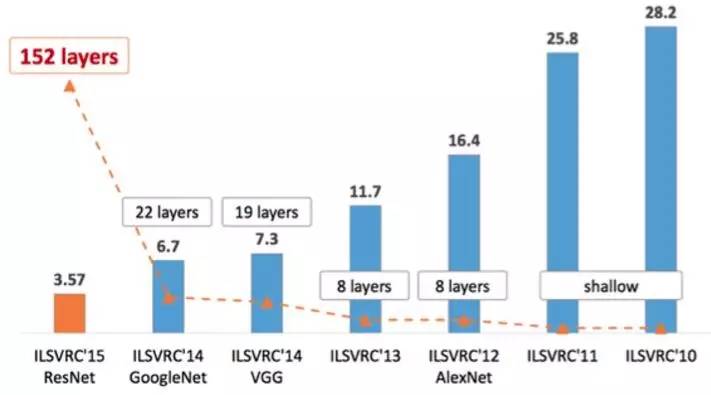
2012年,Alex Krizhevsky等人突破性的提出了基于卷积神经网络的AlexNet网络结构[8],借助卷积神经网络和深度学习的方法,将图像特征的提取、筛选和分类三个部分集成于一个卷积神经网络模型内。最终AlexNet以15.3%的TOP-5错误率打破了世界记录,夺得了2012年的基于ImageNet的大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)[9]年度冠军,并且远远低于第二名26.2%的错误率。AlexNet的提出和优秀表现让研究人员意识到了深度学习的力量,深度学习开始爆发式的发展。
在2014年举办的ILSVRC中,来自Google的团队构造出了GoogLeNet[10],此时的深度学习,已经历ZF-Net(获得了2013年ILSVRC的冠军)[11]等的进一步精炼,对网络深度、卷积核大小、反向传播中梯度消失问题等都有了详细的讨论,Google在这些技术基础上引入了Inception单元,打破了卷积神经网络各层的固有排列方式,将ImageNet分类TOP-5错误率降低到了6.7%的高水平[11],而同年的第二名VGGNet也取得了TOP-5错误率7.3%的优异成绩[12]。
在卷积神经网络结构越来越复杂、网络层数越来越多的趋势下,深度神经网络的训练越来越难,识别错误率的降低也变得缓慢。2015年,来自微软亚洲研究院(MSRA)的Kaiming He等人将残差学习的概念引入深度学习领域[13]。他们通过实验发现,40层的网络没有20层的精度高,认为网络存在退化现象,根本原因是网络不存在恒等映射,因此引入将网络改为学习输入的恒等映射和残差的方式,提供了一条恒等映射的通路,进而使得反向传播可以很好的将梯度传播到浅层,而不像传统网络中梯度消失,从而使得深层网络得以训练。残差学习的出现,在加深网络深度提高模型表现的前提下保证了网络训练的稳定性。ResNet以3.6%的TOP-5错误率获得了2015年度的ILSVRC冠军,已经超越了人类的识别水平。
1.3 论文主要工作
本文以CIFAR-10数据集为基础,设计和实现一个图像分类系统,具体研究工作包括三个方面:图像分类算法和模型分析、CNN训练和可视化实现。
(1)本文介绍了传统的机器学习算法,着重分析了卷积神经网络算法,最后分析了4个经典的CNN模型:AlexNet、VGG、GoogleNet和ResNet。
(2)基于CIFAR-10数据集训练一个卷积神经网络模型,并对神经网络模型进行调整和优化,使正确率达到预期需求。
(3)基于Electron实现GUI界面。
1.4 论文组织结构
本文共分为五章,在深入分析各种分类算法以及CNN的基础上,基于Tensorflow平台和CIFAR-10数据集训练一个效果良好的图像分类器,并实现GUI,直观的展示结果。具体章节安排如下:
第1章为绪论,介绍了本文研究的背景、国内外的研究现状和本文的研究内容,同时说明了本文的组织结构。
第2章介绍了各种分类方法,着重分析了卷积神经网络算法,章节最后又分析了几个经典的图像分类模型。
第3章详细介绍了如何基于CIFAR-10数据集训练CNN网络模型,以及采用各种优化方法和网络调整以便达到不错的正确率。
第4章详细介绍了基于Electron GUI界面实现。
第5章总结了本文的主要内容,并对图像分类问题的未来做出了探讨。
第2章 分类算法研究
2.1 传统机器学习分类方法
使用传统的机器学习方法进行图像分类,首先要使用SIFT等算法提取和筛选图像特征,这一过程又被称为特征工程,然后将得到的特征向量输入合适的分类算法完成特征分类,如图2.1所示。
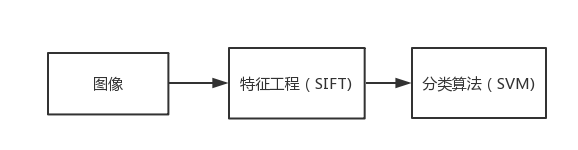
图2.1 传统图像识别方法
特征工程是机器学习领域很重要的工作,可以说是成功的关键,一些竞赛的优胜者,如Kaggle,可能没有用到什么特别的算法,但是其特征工程做得一定十分出色。特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳效果的特征的过程,就是将原始数据提取特征的过程,所以特征工程也可以称为特征选取。对于机器学习,特征工程的重要性毋庸置疑,选取的特征越好,构建的模型越简单性能也越好。典型的特征工程包括数据清理、特征提取、特征选择等过程。
SIFT是计算机视觉领域中用来检测和描述图像特征的一种算法,在机器学习中常用来做图像识别的特征工程,由英属哥伦比亚大学的David Lowe于年发表于计算机视觉国际会议 [14],之后又有许多基于SIFT的改进算法被提出来。SIFT具有十分广泛的应用,例如、、、3D建模、手势识别、视频跟踪、野生动物个体识别和匹配移动等等。SIFT可以检测图像的局部特征,是一种局部特征描述算子。SIFT算子把图像中检测到的特征点用一个特征向量进行描述,一幅图像经过SIFT算法处理后可以表示为一个特征向量集,该特征向量集对图像中的特征缩放、平移、旋转、光照有一定的不变性,是一种鲁棒性比较高的局部特征描述算法。
分类是机器学习中监督学习的一类基本问题,分类算法使用包含特征以及分类标签的训练数据来构建预测模型。这些预测模型可以使用它从训练数据中所挖掘出来的特征来对新的、未曾见过的数据集进行分类标签预测,最终的分类结果是相互分离的。近几年兴起的深度学习也是机器学习的一种实现算法,在深度学习之前,机器学习中有多种分类算法,例如逻辑回归、K-近邻(K-Nearest Neighbors,KNN)、SVM、决策树和朴素贝叶斯等算法,这些方法主要基于图像的色彩、纹理、形状和空间关系等特征来对图像进行分类。分类结果的优劣直接由选择的特征类型决定,所以深度学习之前,特征工程是图像分类竞赛的关键,提取的特征好,方法的整体效果就好。
2.2 卷积神经网络
2.2.1 概述
常规深度神经网络的结构如图2.2所示,由输入层、隐藏层和输出层构成,每个隐藏层都有一系列相互全连接的神经元构成,所以也称为全连接层,最后输出层的每个神经元代表类别的概率。常规神经网络的全连接结构不适合处理高清图像,例如对一幅的图像,全连接层的每一个神经元将会有120000个权重,权重会增加的非常快,同时这种全连接的结构会导致神经网络拥有巨量的参数,也会很快发生过拟合,显然常规神经网络的这种结构并不适合处理高清图像。
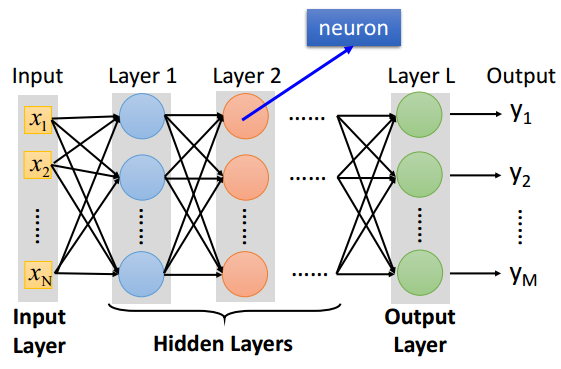
图2.2 常规神经网络结构
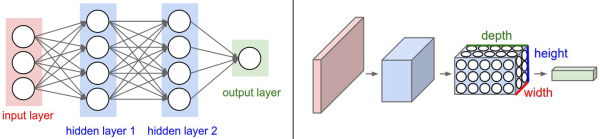
图2.3 左为常规神经网络结构,右为CNN结构
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: