基于生成对抗神经网络的人脸图像生成技术研究与实现毕业论文
2020-02-14 15:04:15
摘 要
随着计算机硬件技术的提升和深度学习理论的迅速发展,越来越多的人致力于人工智能的研究,而无监督学习又是其中重要的一环。自从2014年Ian Goodfellow提出生成式对抗网络以来,学界涌现出了许多GAN模型的衍生模型,而且它们往往有着不错的效果,到目前为止,GAN已经可以通过学习大量的图片来生成可以控制指定属性的、1024*1024分辨率的高质量人脸图片,这是一个巨大的突破,可以预见的是,未来的一段时间内,GAN仍将是人们关注的重点。
为了生成可以控制指定属性的人脸图像,本文在研究和总结前人工作的基础上,完成如下工作:
1、分析并对比了GAN、DCGAN、PGGAN三种模型的结构,总结了三者各自的优缺点。
2、分别使用DCGAN AttGAN模型和PGGAN ACGAN模型生成可控属性的人脸图像并将两种方法进行对比,结果表明后者在celebA数据集上的生成效果比前者要优秀。
3、将上述两种模型训练好后部署到web系统中,使得用户可以通过网页来生成他们想要的人脸图片。
关键词:深度学习;生成对抗网络;人脸生成;属性控制;
Abstract
With the improvement of computer hardware technology and the rapid development of deep learning theory, increasingly, people are devoted to the research of artificial intelligence, and unsupervised learning is an important part. Since Goodfellow proposed a generative adversarial network in 2014, many derivative models of GAN have emerged in the academic world, and they often have good effects. So far, GAN has been able to generate high-quality face images of 1024*1024 resolution that can control specified attributes by learning a large number of pictures. This is a huge breakthrough.And it is foreseeable that GAN will remain the focus of attention for some time to come.
In order to generate a face image that can control the specified attribute, this paper does the following work on the basis of researching and summarizing the previous work:
1. Analyze and compare the structure of the three models of GAN, DCGAN and PGGAN, and summarize the advantages and disadvantages of them.
2. Use DCGAN AttGAN model and PGGAN ACGAN model to generate the face images with controllable properties and compare the two methods, the results show that the latter method is better than the former method in the celebA dataset.
3. Train the above two models and deploy them to the web system so that users can generate the face images they want through the web page.
Keywords: deep learning; generative adversarial network; face generation; attribute control;
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.3 本文研究内容 3
1.4 本文组织结构 3
第2章 GAN模型的结构及优缺点 4
2.1 GAN模型的原理 4
2.2 GAN模型的结构 4
2.3 GAN模型的优点与缺点 5
第3章 特定属性人脸图像生成 6
3.1 特定属性人脸图像生成的定义 6
3.2 特定属性人脸图像生成的一般方法 6
3.3 使用AttGAN DCGAN模型进行特定属性人脸图像生成 6
3.3.1 DCGAN模型的结构和优缺点 6
3.3.2 AttGAN模型的结构 8
3.3.3 使用AttGAN修改DCGAN生成的人脸图像属性 9
3.3.3.1 DCGAN的实现 9
3.3.3.2 AttGAN的实现 9
3.3.3.3 效果展示 10
3.4 使用ACGAN PGGAN模型进行特定属性人脸图像生成 13
3.4.1 PGGAN模型的结构和优缺点 13
3.4.2 ACGAN模型的结构 15
3.4.3 使用ACGAN对PGGAN生成的人脸图像进行属性控制 16
3.4.3.1 ACGAN的实现 16
3.4.3.2 PGGAN的实现 17
3.4.3.3 效果展示 18
3.5 两种模型的对比总结 21
第4章 web原型系统的开发 22
4.1 总体设计 22
4.1.1 系统功能描述 22
4.1.2 Flask框架介绍 22
4.2 前端设计 23
4.2.1 主页设计 23
4.2.2 生成图像展示模块设计 23
4.2.3 人脸属性选择模块设计 24
4.3 后台设计 25
4.3.1 参数处理 26
4.3.2 模型调用与图像生成 26
4.3.3 效果展示 26
第5章 总结与展望 28
5.1全文总结 28
5.2下一步工作 28
参考文献 29
致 谢 31
第1章 绪论
1.1 研究背景与意义
近年来,由于人工智能的迅速发展,越来越多的人开始投身于相关的研究之中。在人工智能的诸多研究方向之中,又数神经网络最受人关注,自深度学习出现的10余年以来,各种各样的模型层出不穷,而GAN(生成式对抗网络)则是其中最令人激动的一种。
GAN模型最大的成功之处在于Goodfellow等人将对抗的思想引入了深度神经网络之中。生成器(generator)和判别器(discriminator)不断进行相互对抗,直到其达到或逼近纳什均衡,这时我们有理由认为生成器已经可以成功地学习到真实数据的分布,使得其生成的数据无法或者至少难以被判别能力达到极限的判别器所判别。这样它便可以在某种程度上“无中生有”,创造出现实世界原本不存在的事物或数据,这便类似于我们人类所拥有的“创造力”和“想象力”。
目前人工智能在大量样本下的学习效果,往往比创造出它的人类还要出色许多,但是在少量样本下的学习和纯粹的“创造”上的表现便远不如人类。人工智能的目标应该是研究出一种媲美或者超过人类智能的程序,以此推动人类世界科学技术的发展并提高人类的生活质量。于是,我们现今阶段创造出的所谓的人工智能的差距便很明显了,进一步的,我们未来应该努力的方向也清晰可见:提高人工智能的“创造力”,使得有一天机器的知识不再仅仅只来源于人类,而是可以彼此之间相互交流,相互学习,共同创造。
无监督学习中的聚类便是一个提高人工智能“创造力”的研究的典型例子,程序对大量杂乱无章的数据自动地进行聚类,这便是无中生有的智能。GAN的出现是对这种致力于“创造力”研究的极大推动。通过GAN,我们可以生成诸多现实世界不存在的人脸图像,甚至已经可以做到1024*1024的可以进行属性控制的人脸图像的生成,并且生成的结果栩栩如生,仅凭人眼几乎无法判别。这也只是GAN诸多应用中的一种,除此之外,GAN带来的这种“想象力”还可以被用于去模糊,帮助我们将原本模糊的监控画面清晰化,便于我们获取需要的信息等等。
于是,可以预见的是,GAN极可能成为或者已经成为我们未来数年,甚至数十年内的主流研究方向。
1.2 国内外研究现状
自从GAN模型被提出以来,学界涌现出了大量的衍生模型,其中一些比较重要的模型如下:
1、GAN模型。2014年,Ian Goodfellow等人第一次提出了生成式对抗网络GAN[1]。将对抗的思想引入了深度神经网络之中,当生成器和判别器达到或逼近纳什均衡时,可以认为生成器生成的图片就是真实的图片。
2、DCGAN模型。2016年,Alec Radford等提出了深度卷积生成式对抗网络DCGAN[2]。DCGAN用卷积层代替了全链接层,生成器使用了RelU激活函数和tanh激活函数,判别器都使用了LeakyReLU激活函数,此外整个网络中没有pooling层和上采样层的存在,作者使用步幅卷积代替了上采样,以增加训练的稳定性。
3、由于GAN的目的是在高维的空间中达到纳什均衡,而梯度下降的方法只能找到损失很低的点,但是达不到纳什均衡,于是2016年,Tim Salimans等人提出了包括Feature Matching、MiniBatch discrimination、Historical averaging、One-side label smooth[3]等在内的方法来提高网络的收敛。
4、PGGAN模型。2017年,NVIDIA深度视觉实验室的Tero Karras等人提出了一种训练GAN的方法——PGGAN[4]。这篇文章改进了网络初始化的方法,提出了一种渐进式的网络训练方法,实现了通过GAN生成高分辨率(1024*1024)人脸图像的目标。
5、StyleGAN模型。2018年Tero Karras等人借鉴了风格迁移[5]等相关论文实现了一种基于风格的生成器[6]。这种生成器实现了风格混合,随机变化以及全局效应与随机性的分离。除此之外,还提出两种可应用于任意生成器架构的新型指标——感知路径长度和线性可分性。
6、WGAN模型。2017年,Martin Arjovsky等人提出的WGAN[7]是GAN模型成长历史上的一大步。相比于DCGAN通过大量实验告诉我们什么样的GAN网络结构会比较稳定,WGAN则是通过研究GAN的理论直接改进了网络,使得我们不必花大量时间在网络的设计上也能得到一个稳定的网络。其改进WGAN-GP[8]则是在WGAN的基础上提出了一些小的改进来解决前者有时生成低质量的图片的问题。
7、CGAN模型。2014年,Mehdi Mirza等人提出的CGAN[9]是一个大胆的尝试,它通过直接在网络中加入条件c来控制网络的输出,证明了GAN生成指定标签的图像是可行的。
8、ACGAN模型。2017年,Augustus Odena等人提出的ACGAN[10]对判别器的要求更严格一些,它不仅要求判别器输出图像的真伪,还要求其输出图像所属标签的类别,通过这样来做到属性控制。
9、AttGAN模型。2018年,Zhenliang He等人提出的AttGAN[11]通过增加encode层和decode层实现了在原始图片上直接修改你期望修改的属性特征,而不影响其他的原始特征的功能。
10、InfoGAN模型。2016年,Xi Chen等人提出的InfoGAN[12]的改进在于它让网络学习到了可以解释的特征表示,而不是像以往的工作那样,生成器将输入的随机噪音z高度耦合,以至于我们无法知道更无法控制生成图像的属性。
此外,其余一些论文也为GAN的发展做出了重要贡献,例如有的提出了重要的batch normalization操作[13],有的从理论方面讨论了如何训练GAN才是有效的方法[14],还有的对现在GAN的发展做了总结,并提出了一些前瞻性的意见供人们参考[15]。
总体来看,GAN模型,DCGAN模型,PGGAN模型,WGAN模型这四个模型主要是被用于进行图像生成的,其偏重于进行人脸整体的生成、器官及其分布的生成和调整,而StyleGAN模型,CGAN模型,ACGAN模型,AttGAN模型,InfoGAN模型这五个模型则主要被用于进行生成图像的属性控制,其偏重于对人脸图像的细节属性特征进行生成和调整。
至今为止,以PGGAN模型架构为基础,添加了诸多模块的StyleGAN有着特定属性人脸生成领域最好的实现效果,其实现了1024*1024分辨率下的特定属性人脸生成,且其生成的人脸图像皮肤质感真实,属性特征细腻,仅凭肉眼几乎无法区别生成的图像和真实的图像。
1.3 本文研究内容
图像生成是人工智能领域中的一个重要研究方向,主要通过深度学习或者其他方法,以随机的噪声为输入,生成人类难以辨别的逼真图像。本文主要完成以下几方面的工作:
(1)分析GAN模型的结构和优缺点。
(2)分析DCGAN和PGGAN的结构,优缺点,并与GAN进行对比。
(3)将AttGAN与DCGAN结合,用前者修改后者生成的图片的属性。
(4)将ACGAN与PGGAN结合,直接生成指定属性的人脸图片。
1.4 本文组织结构
本文分为五章,具体章节安排如下:
第1章为绪论部分,从研究背景与意义、国内外研究现状、本文研究内容几方面进行了介绍,同时说明了本文的组织结构。
第2章是对GAN结构、优缺点的分析。
第3章是对AttGAN DCGAN模型和ACGAN PGGAN模型生成特定属性人脸图片方法的介绍及对比。
第4章是对web原型系统的介绍。
第5章总结了本文的主要内容,提出了研究的不足及下一步工作方向。
第2章 GAN模型的结构及优缺点
2.1 GAN模型的原理
Generative Adversarial Networks,生成对抗网络,顾名思义,它是通过对抗的方式来实现生成目的的模型。它通过判别器和生成器的互相对抗让两者不断学习,直到生成器学习到真实的样本分布,使得判别器对其生成的图像有50%的概率认为是真实的图像,这时训练便完成了。
2.2 GAN模型的结构
在GAN模型中,有两个模块,一个是生成器Generator,下文中用G代替,另一个是判别器Discriminator,下文中用D代替。GAN模型的整体结构如下图2.1所示。
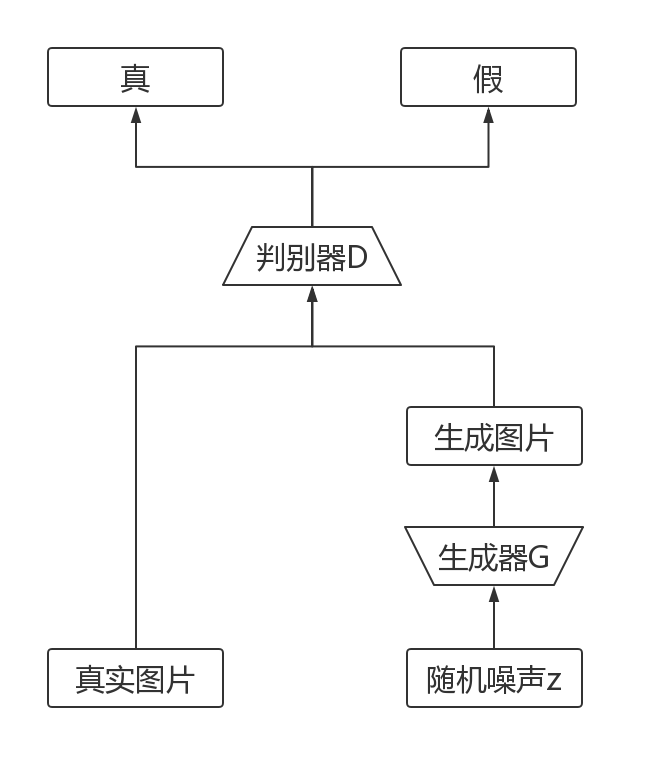
图2.1 GAN整体结构
G的功能是接收外界输入的随机噪声z,并将其转化成图像进行输出,D的功能是接收外界输入的图像,然后判断这幅图像是真实的图像还是由G生成的图像,并给出一个“该图像在多大概率上是真实图像”的概率值。而无论是G还是D,它们全都使用了全连接层。
在训练中,先将噪声输入G,生成图像G_image,然后将G_image输入D得到概率D_fake,接着将真实的图像输入D得到概率D_real。接下来定义G和D的损失函数G_loss和D_loss,并使用反向传播算法来更新参数即可。
2.3 GAN模型的优点与缺点
GAN模型最大的优点在于其对抗的思想,它为无监督学习找到了一条新的路径。但是GAN模型并不完美,它仍然有许多问题:
首先,“达到纳什均衡”这一点就比较难以做到,我们常用的梯度下降法并不能保证这一点,因此,GAN的训练并不稳定。
其次,GAN的训练中存在梯度消失的问题,当判别器太优秀的时候,生成器梯度消失,其损失函数难以下降,当判别器太无能的时候,生成器又不能稳定下降,这就使得GAN的训练很困难,我们必须要平衡生成器和判别器才能得到理想的生成结果。
第三点,GAN存在模式崩溃的问题,在我使用GAN生成手写字体的时候便发生了这样的情况——生成器发现了判别器的某种漏洞,然后不断地利用这个漏洞生成可以骗过判别器的图像,以至于我的训练结果全部都是数字8,失去了图像的多样性。
在WGAN[7]的论文中,作者总结了GAN的各种问题,给出了这些问题的解决方法,并提出了令人惊叹的WGAN模型,极大地推进了生成对抗网络的发展。不过也正是因为GAN的诸多不完美之处,才使得人们投身于GAN模型的改进和发展,于是才有了后面的DCGAN,PGGAN等衍生模型。



