区域房价预测系统的设计与开发毕业论文
2020-02-16 12:09:10
摘 要
当前二手房的价格受市场影响较大,市面上现有的房价预测系统均无法同时具备高准确率和免费使用的特性,这对二手房商家为房屋定价产生了巨大影响。
针对上述问题,本文通过使用Requests和PyQuery库对链家官网上武汉市各区域二手房价的信息进行爬取,利用Python语言及numpy,pandas,matplotlib等相关扩展库进行数据处理和数据分析,再使用房价数据集和scikit-learn中的不同算法训练产生对应的模型,最终挑选出一个准确率较为可靠的模型,通过该模型预测不同区域的二手房房价数据。
研究结果表明二手房价主要受房屋面积、所处地段、周边设施等三方面因素的影响,同时对于房价的预测分析表现最好的机器学习模型主要是GradientBoostDecisionTree算法和基于Ridge回归的AdaBoost算法。
本文通过对各种算法的分析比较,最终建立以Ridge算法为基回归器的AdaBoost方法模型并应用于房价预测,在保证准确率的前提下实现免费、快速、区域化的预测房价。为方便二手房商家的使用,本文基于Flask框架搭建Python后台,基于Android系统开发用户前端界面,最终完成一套实用性较强的区域房价预测系统。
关键词:机器学习;数据分析;房价预测;Android;Flask
Abstract
The current price of second-hand houses is greatly affected by the market. The existing house price forecasting system on the market cannot simultaneously have high accuracy and free use characteristics, which has a huge impact on the pricing of second-hand houses.
In response to the above problems, this article uses Requests and PyQuery library to crawl the information of second-hand housing prices in various areas of Wuhan City on the chain official website, using Python language and numpy, pandas, matplotlib and other related extension libraries for data processing and data analysis, and then use the price The data set and the different algorithms in scikit-learn train to generate the corresponding model, and finally select a model with more reliable accuracy, and predict the second-hand housing price data in different areas.
The research results show that second-hand housing prices are mainly affected by three factors: housing area, location and surrounding facilities. At the same time, the best machine learning model for housing price forecasting analysis is GradientBoostDecisionTree algorithm and Ridge regression-based AdaBoost algorithm.
In this thesis, through the analysis and comparison of various algorithms, the AdaBoost method model based on Ridge algorithm is finally established and applied to house price forecasting. Free, fast and regional forecasting of house prices is realized under the premise of ensuring accuracy. In order to facilitate the use of second-hand housing business, this thesis builds Python background based on Flask framework, develops user front-end interface based on Android system, and finally completes a set of practical regional price forecasting system.
Key Words:Machine Learning; Data Analysis; House price Predict; Android; Flask
目 录
第1章 绪论 1
1.1研究背景及意义 1
1.2国内外研究现状分析 1
1.3研究内容及目标 3
1.4本文的组织结构 4
第2章 区域房价数据采集与分析 5
2.1数据获取 5
2.2数据预处理 6
2.3数据分析 8
2.4小结 16
第3章 基于机器学习的房价预测模型 17
3.1模型训练及分析 17
3.1.1回归算法 17
3.1.2决策树和随机森林 19
3.1.3AdaBoost和GradientBoost 23
3.2模型选择及结果分析 28
3.3小结 30
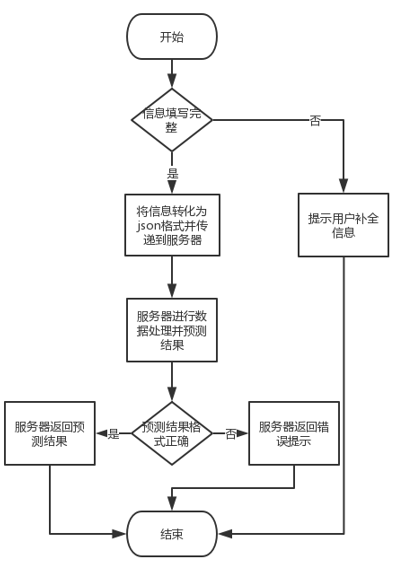
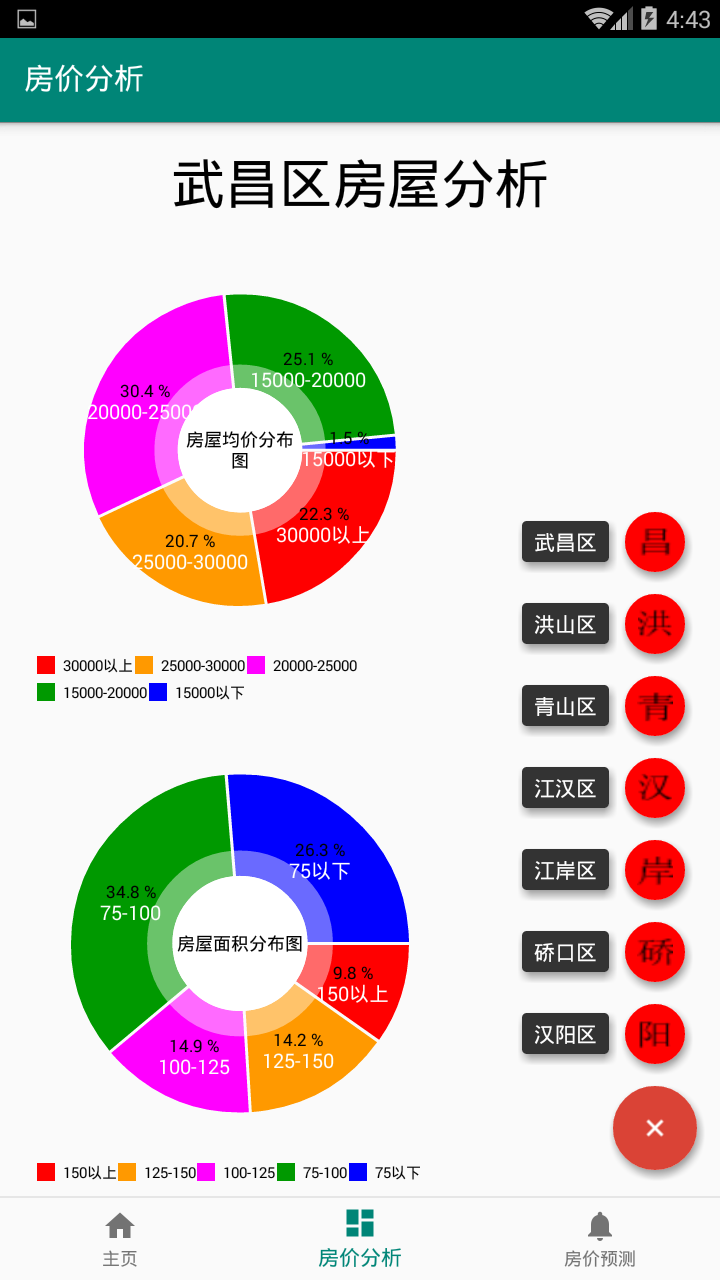
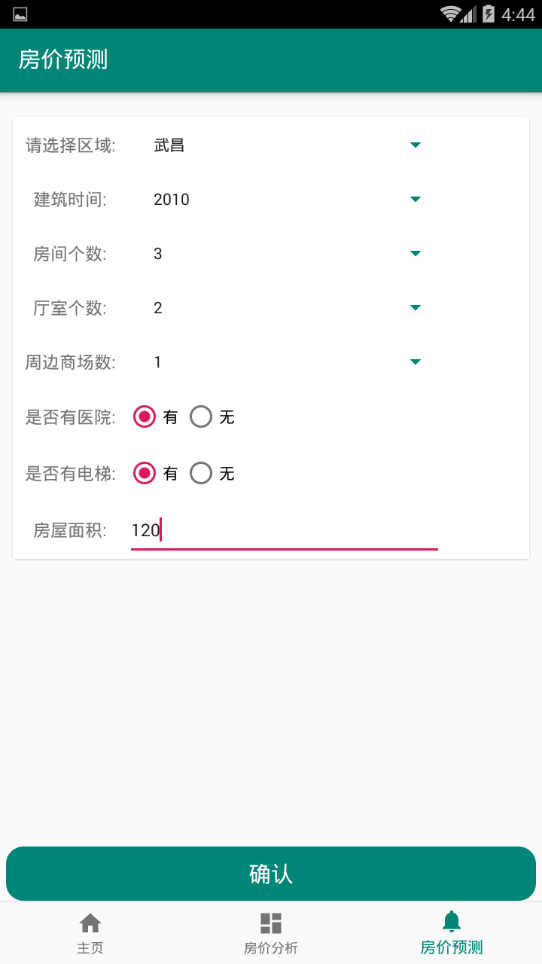
第4章 区域房价预测系统设计及开发 31
4.1用户界面 31
4.2后台设计 36
4.3系统测试 38
第5章 总结与展望 41
5.1本文总结 41
5.2未来展望 41
参考文献 43
致 谢 44
第1章 绪论
1.1研究背景及意义
近年来房价的变化趋势越来越难以捉摸,随着各大开发商的不断提价和政府相应政策的不断改变,仅凭人们自己的经验来准确预测房价走势变得不切实际,二手房商家在卖房定价时也饱受困惑。但随着计算机技术的迅速发展和机器学习领域的不断突破,利用相关算法预测不同区域的房价逐渐成为可能。
随着时代的发展,机器学习算法也在诸如金融交易、个性化、人工智能、网络安全等诸多领域被广泛应用,在提高大众生活品质和加快社会经济发展等方面做出了巨大贡献。目前常见的机器学习算法包括各种回归算法、决策树、支持向量机、聚类算法、集成学习算法、朴素贝叶斯等[1]。这些算法中在针对不同地区的房价数据建立模型时,最简单、基础的就是线性回归算法。
机器学习在房价预测领域的应用仍然处在研究阶段,从最早的简单线性回归算法,到后来的决策树、随机森林和集成学习的方法,以及深度学习中神经网络相关方法,都为这一领域提供了理论基础。目前市面上的房价预测系统均无法兼顾准确率、实时性、区域性和免费使用等特征。主要原因是房价的变化速度非常快,动态地训练和更新模型并预测不断变化的房价需要较高的成本,这使得软件系统不可能免费使用。而且影响房屋价格的因素很多,房价不仅仅受到房屋本身一些因素如所处城市、房屋面积、地段、周边设施、生态环境等因素的影响,还受到国家政策法规、房市、国际环境等不可控因素的影响。免费使用的软件大多不能保证预测值的准确率,同时也无法将预测范围细化到某个城市的某一区域,因此房价预测变得愈发困难[2]。
综上所述,研究并建立一个兼顾准确率、实时性、区域性的房价预测模型并开发对应的可以免费使用的房价预测系统拥有广阔前景,能够提供给人们一种预测房价的思路,并将相关算法模型应用到实际生活中,带给人们便利生活的同时推动科技的进步和房地产事业的不断发展,为二手房商家销售房屋提供了合理的定价分析,为城市大众解决房屋问题提供了前瞻性分析,有益于社会的不断发展和进步。
总之,研究区域房价数据,建立可靠的区域房价预测模型并开发这样一套集准确率高、区域化精细、实时性较高的系统,能够填补目前市场上预测区域房价的需求空缺,有利于社会大众和房地产事业的双赢。
1.2国内外研究现状分析
随着机器学习算法的不断发展,越来越多的模型被应用到日常生活中,越来越受到关注,国内外很多专家都对此做出了重要贡献。机器学习算法是通过对大量数据的学习,从数据中获取规律,并利用规律对未知数据进行预测的方法,目前广泛应用的机器学习算法有以下几种:
分类算法:支持向量机,决策树,神经网络和极端学习机[3]。
聚类算法:聚类学习是最早被用于模式识别及数据挖掘任务的方法之一,并且被用来研究各种应用中的大数据库,因此用于大数据的聚类算法受到越来越多的关注[4]。
特征选择算法:在数据挖掘、文档分类和多媒体索引等新兴领域中,所面临的数据对象往往是大数据集,其中包含的属性数和记录数都很大,导致处理算法的执行效率低下。通过属性选择可剔除无关属性,增加分析任务的有效性,从而提高模型精度,减少运行时间[5]。
目前国内外针对房价预测这一领域所使用的算法模型主要是惩罚线性回归、Boosting、随机森林、支持向量机、高斯过程以及灰色马尔科夫模型等。
惩罚线性回归是指在线性回归中加入惩罚项以正则化模型,它拥有最快的训练速度和预测速度,同时能够胜任处理大批量数据的工作,但惩罚线性回归在数据复杂程度较高时表现较差,目前惩罚线性回归主要用在房价预测的初级阶段,通过惩罚线性回归训练模型并分析模型可靠性,对原始数据集作进一步处理。
Boosting方法通过构造一个预测函数系列,将它们以一定的方式组合成一个预测函数,它可以提高任意弱学习器的准确度。Boosting方法在训练速度、预测速度和大数据量下的表现都不及惩罚线性回归,但对于特征值较复杂的数据集却有良好的表现,Boosting方法通过牺牲时间换取模型准确率和对数据的处理能力。在房价预测领域常用的Boosting方法为AdaBoost、GBDT以及XgBoost等,其中以AdaBoost最为常用。AdaBoost方法在整个训练集上维护一个分布权值向量,对错误样本分配更大权值,正确样本分配较小权值,并不断更新。AdaBoost方法的任务就是将拟合能力不强的弱学习器算法提升为拟合能力较强的强学习器。针对不同的房价数据采用不同的Boosting方法是目前房价预测领域的主流趋势,AdaBoost泛用性广,GBDT适用于数值型特征较多、类别型特征较小的房价数据集,XgBoost由于在损失函数中加入了正则项,适用于房价特征复杂但数据量不大的数据集。
随机森林算法包含多个决策树,它可以处理大批量的数据,拥有不亚于惩罚线性回归的学习速度和更高的准确率,且能够降低决策树算法训练模型时出现过拟合的可能,且随机森林算法对异常值不敏感,与惩罚线性回归相似,常用在房价预测模型建立的早期阶段或异常值处理不完全的房价数据集上。
支持向量机算法现在主要用于解决分类问题,在人脸识别、文本分类等模式识别领域有较高的应用价值,在处理回归问题上的表现不如Boosting方法。
高斯过程回归使用高斯过程先验对数据进行回归,与支持向量机相似,高斯过程回归拥有不同的核函数将特征向量转化为核向量,其计算量大于Boosting方法,常用于针对低维度和小样本的房价数据建立房价预测模型。
灰色马尔科夫模型通过灰色生成序列算子的作用弱化随机性,经过差分方程与微分方程之间的互换实现了利用离散的数据序列建立连续的动态微分方程,进而求出离散数据序列的预测结果。灰色马尔科夫模型计算量适中、应用面广,拟合能力强,但对于数据的要求较高,该算法不适合处理特征值复杂的数据集,在数值型变量较多且房屋特征值较少的数据集上有较好的表现,反之在类别型变量较多的房价数据集上表现较差[6]。
在惩罚线性回归、Boosting、随机森林、支持向量机、高斯过程回归以及灰色马尔科夫模型中,惩罚线性回归和高斯过程回归主要针对数据量小、特征值简单的房价数据集建立预测模型,Boosting、随机森林和灰色马尔科夫模型则适用于对数据量大、特征值复杂的房价数据集建立模型,其中又以Boosting方法最为常用,该方法适用范围广、拟合能力强、训练速度适中且不必直接去找通常情况下难以获得的强学习器。
1.3研究内容及目标
本文主要是利用机器学习中的回归相关算法,通过提供房子的面积、户型、建筑时间、地段等相关信息,对某一区域的二手房价进行预测。前期需要对爬取的数据进行预处理和分析,并选取不同的算法,通过提供大量的已处理数据给不同的算法训练产生相应的模型,经过对比分析后选择评价指标最佳的模型作为最终的房价预测模型。本文的研究内容主要包括:
1.机器学习算法的选择:
本文通过对比几种回归算法、决策树算法、随机森林算法、AdaBoost方法和GBDT算法所建立的模型,从中选择拟合程度最好的模型作为最终的房价预测模型[7]。回归算法是统计机器学习的利器,它简单实用,能够良好的完成80%以上的情况,但是简单的线性回归算法已经早早被时代所淘汰,决策树、集成学习的相关算法常常被用来代替早期的线性回归,本文的研究重点也主要集中在集成学习的两个常用方法AdaBoost和GradientBoost方法,分别以不同的弱学习器为基础,寻找最好的算法模型。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: