基于全卷积网络的道路图像分割方法研究毕业论文
2020-02-16 22:49:02
摘 要
道路图像分割是自动驾驶领域的研究热点之一,目前主要的问题是小物体的识别能力差、分割图像道路边缘模糊以及处理时间较长。本文针对这些问题在全卷积网络的基础上做了相关分割方法的整理和学习,同时针对分割后图像在边缘处粗糙的问题学习了条件随机场的相关概念。由于小物体识别能力差、道路边缘结果模糊和处理时间长的问题严重影响道路图像分割结果和其在自动驾驶中的应用,因此基于全卷积网络的道路图像分割具有广泛的应用和学习价值。
本文首先对若干个不同的网络模型结构进行研究分析,阐述各自在图像分割方面的优缺点。然后针对道路图像分割结果边缘粗糙的问题,选择条件随机场作为后端图像处理方法,将条件随机场和全卷积网络融合,得到了新的模型。最后在KITTI数据集上进行了相关实验,分别为多个经典网络的对照实验、条件随机场的分割实验、融合FCN和CRF的道路图像分割综合实验,并将其与原FCN网络以及FCN RGBD网络进行对比。
最终实验表明,条件随机场方法在道路分割结果边缘处表现良好,因此使用条件随机场作为模型的后端,对输出图像进行处理,使道路边缘更加清晰,整体结果更加优秀。由于自动驾驶对实时性的要求非常高,融合了FCN网络和条件随机场的模型在结果指标方面虽然不是全部最优,但是其在时间性能方面相对于其他模型有了很大提升。综合考虑之下,该方法拥有较为优良的性能。
关键词:全卷积网络;道路图像分割;RGB-D;条件随机场
Abstract
Road image segmentation is one of the research hotspots in the field of automatic driving. At present, the main problems are the poor recognition ability of small objects, the blurring of road edges of segmented images and the long processing time. In this paper, the correlative segmentation methods are sorted out based on the fully convolutional network for these problems, and the related concepts of the conditional random field are learned for the rough edges of the segmented images. Due to the poor recognition ability of small objects, fuzzy road edge results and long processing time, the results of road image segmentation and its application in automatic driving are seriously affected. Therefore, road image segmentation based on the full convolution network has extensive application and learning value.
This paper first analyzes several different network model structures and expound their advantages and disadvantages in image segmentation. For the problem of rough edges in road image segmentation, CRF is selected as the back-end image processing method. Finally, in combination with the method of FCN and CRF, a control experiment of several classical networks was carried out on KITTI at first, followed by a CRF segmentation experiment, and finally, a fusion experiment of FCN and CRF was conducted and compared with the original FCN network and FCN RGBD network.
The final experiment shows that the CRF has better performance at the road edge. Therefore, the CRF is used as the back end of the model to process the output image to clearer the road edge while better the final result. Since the requirements for real-time driving are very high, the model incorporating the FCN network and the CRF is not all optimal in terms of the result index, but it has greatly improved in terms of time performance compared to other models. Taken together, this method has very good performance.
Key words: fully convolutional networks; lane image segmentation; RGB-D; conditional random field
目 录
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 2
1.2.1 道路识别图像预处理方法研究现状 2
1.2.2 常见图像分割方法研究现状 4
1.3本文研究内容 5
1.4论文组织结构 6
第2章 基于全卷积网络的道路图像分割方法研究 7
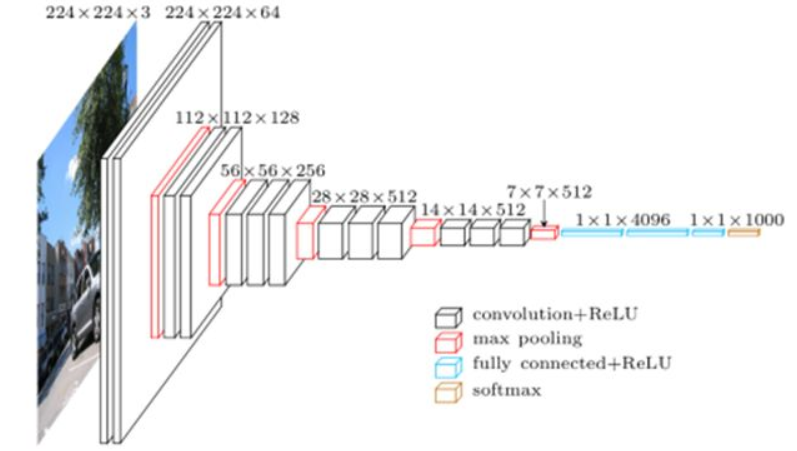
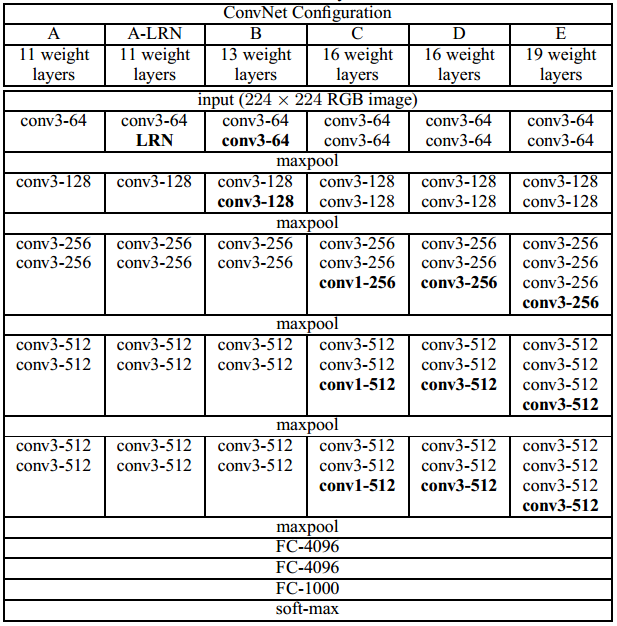
2.1 基于VGGNet的图像分割方法分析 7
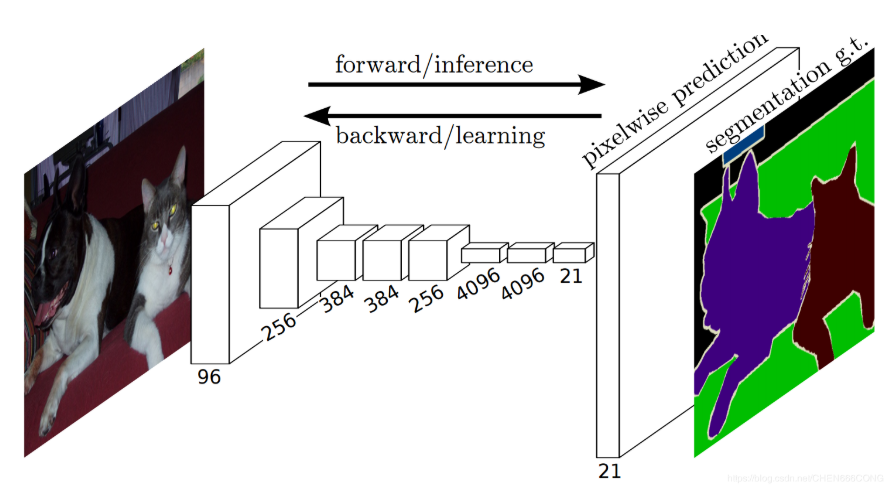
2.2 基于FCN模型图像分割方法分析 9
2.3 基于U-Net的图像分割方法分析 11
2.4 条件随机场(CRF)的模型分析 13
第3章 实验结果及分析 14
3.1 实验环境 14
3.2 KITTI数据集与评价指标介绍 14
3.3 综合实验结果分析 16
3.3.1不同网络的实验结果分析 16
3.3.2 CRF 实验结果分析 17
3.3.3 网络与CRF结合实验结果分析 18
第4章 总结与展望 20
4.1 本文总结 20
4.2 研究展望 20
参考文献 22
致 谢 24
第1章 绪论
1.1 研究背景与意义
近年来自动驾驶技术发展越来越迅速,且软件与硬件的迅速兴起,使得不论是学术界还是工业界都投来了目光。车道识别应是实现自动驾驶的基础工作,准确地来说,车道识别在不同的领域如自动驾驶、障碍检测以及智能汽车等应用中都拥有着较为重要的价值。在车辆行驶过程中不仅要保证行驶的道路正确无误,还需要得到一些其他的辅助信息提供给相关的控制系统。由此而来,车道识别还拥有其他相关的分支比如车道线识别,车辆识别,行人识别等,这些都是为了自动驾驶更好地实现而引发的技术。
在自动驾驶的过程中,需要收集道路相关的信息,而在收集道路信息时,道路形状的不确定性是难题之一。车道虽然大多数是直线,但是还包括很多弯道以及特殊形状的道路。另外由于车内视角的限制,车前视野是否开阔、车辆的密集程度也是很重要的影响因素。还有由于外部原因例如:天气、不同光照造成的阴影、行人、障碍物等的影响,使得道路的信息变得复杂得多。另外,程序分析的速度即实时性非常重要,由于自动驾驶速度可能较快,更快的分析速度也就意味着更低的风险。因此,如何能够更快速精准地排除诸多干扰因素,将道路准确地识别出来,成为学术界一直在探讨的难题。
图像分割最为常用的是卷积神经网络(convolutional neural network,CNN)以及全卷积神经网络(fully convolutional network, FCN )。最初的CNN网络是在卷积层之后加上几个全连接层,如此以来就可以将卷积层处理生成的特征图(feature map)映射成长度几乎不变的特征向量,最后可以获得该图像的一个概率向量,最终得到图像输出若干个分类的概率。当使用CNN来判断图像中的某一个像素是否属于车道时,通常需要分析其相邻的若干的像素,而窗口的大小就决定哪些临近的像素被考虑。将窗口截取到的图像输入CNN后,其输出就是位于中心位置图像的分类(属于或者不属于车道),当滑动这个窗口时,就可以给出图像每个像素的分类,其计算过程如图1.1所示。
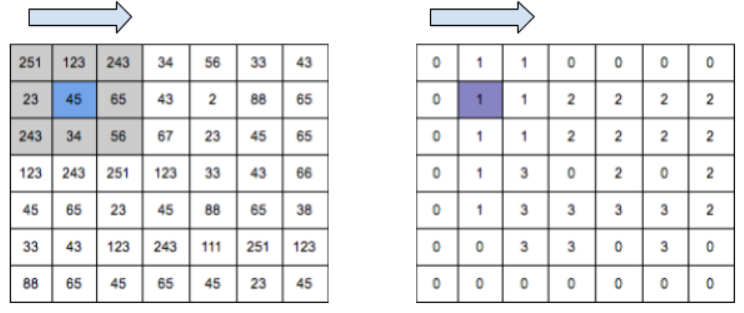
图1.1 窗口计算过程
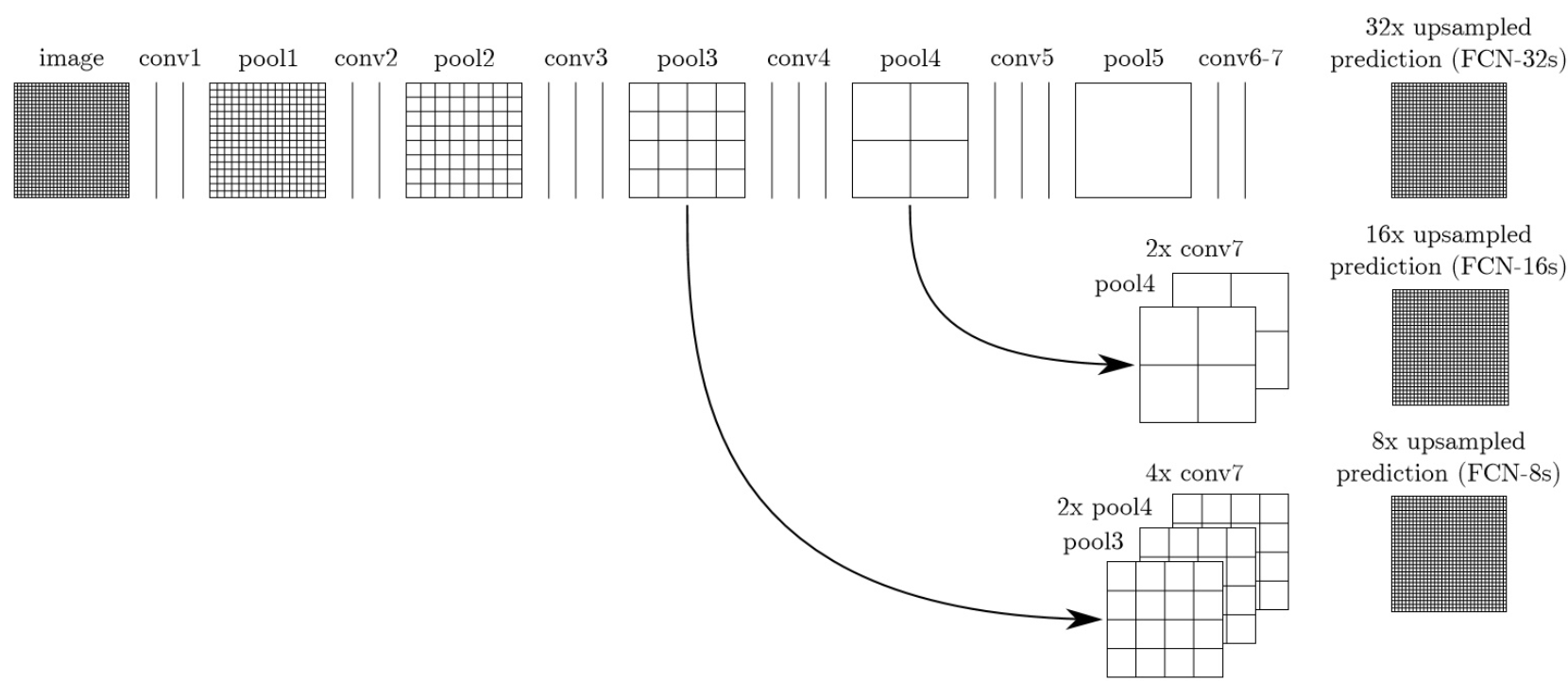
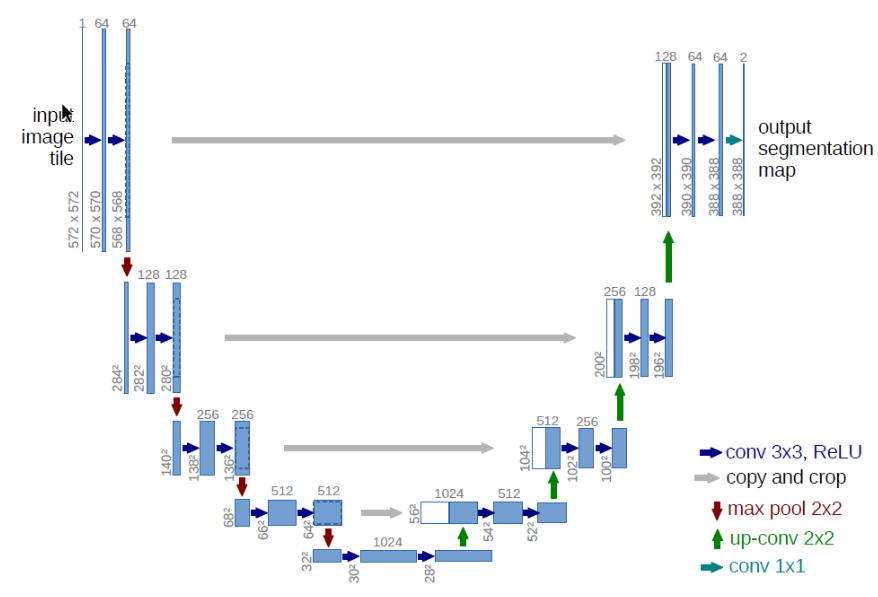
不过滑动窗口的方法有着很明显的缺点,其计算量巨大,存储开销大,窗口大小也是凭借经验选择,整个网络处理速度已经达不到实际的要求。在精度方面由于窗口大小的选择会对最终精度产生巨大的影响,但在实际运算时并不一定能找到最合适的窗口大小,导致最终精度也不能够保证。为了弥补CNN在图像分割问题中的众多缺点,Long等人[1]在CNN的基础上加以修改和深化,全卷积神经网络(FCN)应运而出。FCN的优点在于它在像素这个微小级别的分类中表现出色,将图像分割带入了语义级别的分割领域。由于CNN最后三层是全连接层,FCN就是使用卷积层代替这三个全连接层,并使用上采样对feature-map进行还原,通过这种方式使输出图像的尺寸恢复到与输入图像相同,从而在保留原图空间信息的同时,对每个像素都进行预测和分类,从而实现逐像素操作。一个典型的CNN与FCN的结构与输出差别如图1.2所示。
图1.2 典型的全卷积网络架构
1.2 国内外研究现状
首先论述图像分割方法的情况,常见的分割方法有基于阈值、区域、边缘、神经网络的分割方法等。下面将论述图像预处理的方法的研究现状,然后逐个阐述相关的部分原理和现状。
1.2.1 道路识别图像预处理方法研究现状
道路识别图像预处理方法是在进行道路识别之前,对相关的图像进行处理,使其能够得到更加显著的特征,从而得到更好的道路分割结果。李琳辉等人[2]提出通过半全局立体匹配算法获取视差图D与原RGB图像结合所得到RGB-D图像并进行平滑处理,以此来建立样本库。图1.3为从使用的数据集中随机选取的一对三维道路图像经过处理的结果,其中(a)为原图,(b)为未经特殊处理的视差图,(c)为使用特殊方法得到的视差图,从图中可以很明显得看出,经过平滑处理操作的视差图将物体的信息更好地呈现出来,其边缘和轮廓信息更加的明显。最终基于RGB-D的分割精度优于基于RGB图像的分割精度。

- 原图

- 未特殊处理的视差图

- 使用特殊方法后得到的视差图
图1.3 立体视觉图像匹配结果
RGB-D早期应用于室内的语义分割,后来为了方便其他学者研究学习,Silberman 等人[3]制作了数据集 NYUv2,并且整个数据集是基于RGB-D的,由于物与物之间实际上是有支撑关系的,所以他们提出了一种相关的语义分割方法。实验结果表明,基于 RGB-D 的图像分割方法相比基于RGB图像的分割方法具有更高的环境适应度和分类准确性,由此为基于RGB-D图像的道路分割提供了借鉴。对于室外复杂的交通环境而言,网络需要获取数据量更大的、距离更遥远的深度信息。与此同时,还需要效率更高的获取深度信息的方法以及深度学习方法。另一个方面,Florian Wulff等人[4]将相机数据复合以后放入多维占用网格中进行处理,最终得到94.23%的准确率并且可以达到10hz的实时检测率。而熊志勇等人[5]从另一个角度则是通过将图片分为三个尺度作为网络的输入,最后再通过将得到的多尺度特征融合,获得分割的结果。其在像素的分类和感知物体轮廓方面取得了不错的成果,但是在轮廓边界方面并没有做到很精细,对于很小的物体难以做到准确的识别。
1.2.2 常见图像分割方法研究现状
近些年来,随着图像分割和识别领域的热度不断提升,越来越多的目光聚焦于此,众多专家学者也曾提出许多优秀的图像分割算法。从传统的领域来讲,在2003年王茜等人[6]提出一种自适应阈值为基础的图像分割方法,采用最大类间方差的思想,使用分割出的前景-背景区域的灰度值统计量来对分割结果进行后续的判断,不过该方法普适性较差。Sirshendu Horel等人[7]在阈值分割的基础上提出阈值与区域生长集成的交互技术,提出一种基于像素强度的均匀性,并通过人工选择、迭代法、Otsu法、局部阈值法等多种方案确定阈值,以获得最佳的阈值。该方法比传统的阈值和区域生长法都取得了更好的实验结果。但是,由于它是一个交互式系统,种子的选择是手动选择的,这就不免会出现由于种子选择而导致最终的分割成果有很大的不确定性的问题。虽然其在抗噪性能方面已经有了进步,但仍对噪声略为敏感,在某些情况下会导致部分图片像素块有空洞的产生。此外,它并不是并行算法,而是串行算法,在一些情况下会导致分割速度明显变慢,例如遇到目标较大、区域模糊等情况时。
对于基于边缘的检测,在车道检测方面可以说是基于车道线的检测,如图1.4所示,(a)为原图,(b)为车道检测结果图。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: