新闻网页的自动识别和过滤毕业论文
2020-08-20 20:01:52
摘 要
近几年互联网的快速发展,导致了大量网页的出现,而这些网页包含的信息资源内容广泛和形式各异,当然也包括了无用、不健康的信息资源。那么该如何自动过滤这些网页并提取出这些网页包含的重要信息呢?传统的人工甄别新闻网页、提取新闻内容的方式显然已无法适应现在的互联网环境。
本文引入的新闻网页的自动识别与过滤的软件系统,通过在研究、分析大量的新闻网页的属性特点前提上,从而来构建网页的分类器,通过Web页面来接收URL的输入,接着系统执行自动识别任务,判定其是不是为新闻网页;如果系统判断出该URL对应的网页是新闻网页,那么接下来根据建立好的规则,抽取网页中的新闻标题和新闻内容,从而达到过滤网页广告、相关链接等噪音。
新闻网页的自动识别与过滤系统,对于从大量的网页中过滤、识别新闻网页具有很大的作用,它不仅可以节省不必要的人工时间,还可以大大地提高工作效率。
关键词:识别 过滤 新闻网页
Abstract
As the Internet develops rapidly,which results in the appearance of large diverse webpages ,and these webpages contains diverse and different information ,of course ,useless and unhealthy contents included.Then how can we filter these webpages and extract useful information ? the traditional approach of recognizing the news webpages can not work.
This article brings in automatic recognition and filtering of webpages。On the basis of studying the features of news webpage, we build up the classifier ,the System can take the URL of webpage by the input tag。Next ,the system starts to recognize the news webpage to decide where the webpage belongs to news webpage。we extract the title and content of news based on the rule to filter the advertisement and so on。The system can replace the traditional approach , improving the efficiency of work.
The system is beneficial to recognizing and filtering news webpages ,which can not only save the artificial time ,but also improve the efficiency.
Key Words: filtering ;recognition; news webpage
目录
摘 要
Abstract
第一章 绪论
1.1 项目背景
1.2 项目意义
第二章 可行性分析
2.1 技术可行性
2.2经济可行性
2.3操作可行性
第三章 需求分析
3.1功能需求
3.1.1系统目标
3.1.2功能需求分析
3.2系统性能要求
3.3运行环境
3.4数据流图
第四章 设计与实现
4.1 总体设计
4.1.1系统代码架构
4.1.2系统模块划分
4.1.3数据库结构设计
4.2 新闻网页源抓取模块功能介绍
4.4 网页结构处理模块功能介绍
4.5 网页内容处理模块功能介绍
4.6 网页识别综合模块功能介绍
4.7 新闻标题、内容提取模块功能介绍
第五章 系统测试与验证
5.1软件测试的相关知识
5.1.1 软件测试的基本定义
5.1.2 软件测试基本概念
5.2软件测试方法种类
5.2.1 黑盒测试、白盒测试、灰盒测试
5.2.2 冒烟测试、回归测试、随机测试
5.3模块测试
5.4测试与验证
参考文献
结论
致谢
第一章 绪论
1.1 项目背景
互联网的快速发展导致互联网上的网页数量迅速地膨胀、增多,里面包含了各种类型的网页,当然,里面也含有许多无用的、不健康的内容,这些网页深深地污染着互联网和用户,因为不仅仅浪费用户的宝贵时间,而且虚假、不健康的内容也会对用户产生误导作用,为了能够快速且准确地寻找到我们需要的信息资源,自动识别与过滤新闻网页已经成为了当前的研究热点,希望能够以自动识别和过滤的方式取代传统人工工作的方式。
对网页进行分类和识别的传统做法是人工来进行执行相关的操作,由人工在查看过网页的内容来确定当前网页属于哪一种类别。但是网页数量的爆炸性增长导致了传统的做法无法适应这种需求。由于网页数量的快速增长,机器学习的方法代替了手工分类的做法。自动识别和过滤新闻网页成为了当今的研究热点,它不仅可以解放人工做法,也可以提高执行的效率,快速地从海量级网页数据中提取出新闻网页,并提取出新闻标题和内容。
从当前的研究进展来看,在新闻网页的自动识别与过滤方面,相关的技术发展的已经相对比较成熟,对于新闻网页的分类,已有的技术包括利用网页内容的特征、基于网页链接(即URL)、综合网页内容和链接特征的方法,相关的算法包括:K近邻、支持向量机SVM、决策树、神经网络、最小线性平方适配法LLSF等技术方法[ 1 ]。
1.2 项目意义
新闻网页的自动识别与过滤可以用来替代传统的人工识别新闻网页的方式,可以快速和准确地识别新闻网页并能清除网页内的相关噪音,从而提取出新闻的标题和内容。为了能够实现新闻网页的自动识别与过滤,我在总结大量新闻网页的特征基础上,构建了新闻网页的自动识别与过滤的系统,该系统主要分为两个部分:新闻网页识别部分和新闻内容提取部分,其中,新闻网页识别部分包括训练模块和识别模块,训练模块接收前期抓取的Web网页作为输入源,通过URL处理器、网页内容处理器、网页结构处理器,用来训练建立一个分类器,识别模块用来判断识别的URL对应的网页是否是新闻网页;新闻内容抽取部分用来从新闻网页中提供新闻标题以及新闻内容。
本文介绍的系统可以替代人工省查网页的方式来识别出新闻网页,并根据用户输入的路径规则来提取新闻标题和内容。该系统有很多的实用领域,首先新闻媒体行业可以利用该系统从互联网上众多网页中识别出真正的新闻网页,过滤掉无用的网页,可以大大地节省人工识别花费的时间。新闻阅读器从网络中爬取新闻内容时,需要识别爬取到的网页是否时新闻网页,并需要提取出新闻标题和新闻内容,本文的系统可以满足这样的需求。该系统也可以帮助搜索引擎从大量的搜索结果中去除非新闻网页,利用提取模块快速获取新闻网页中的新闻标题和内容。
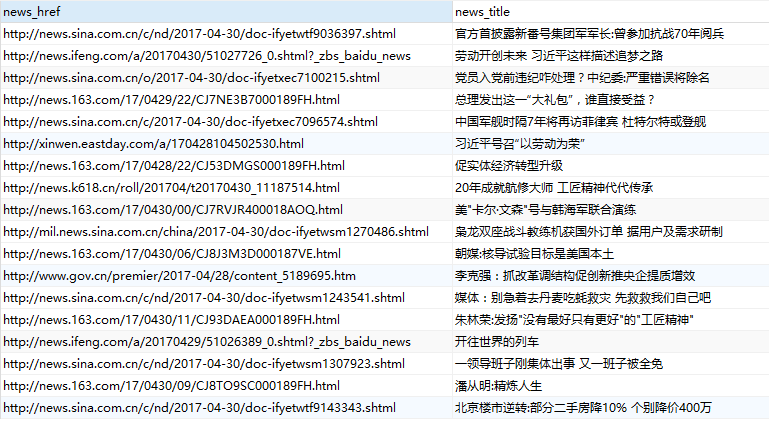
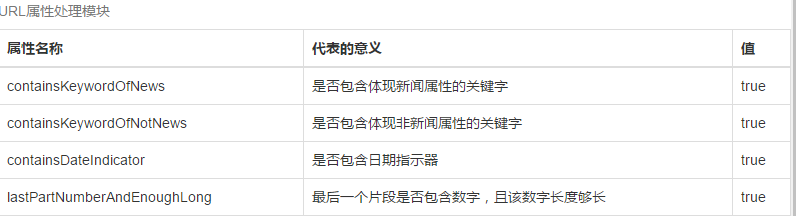
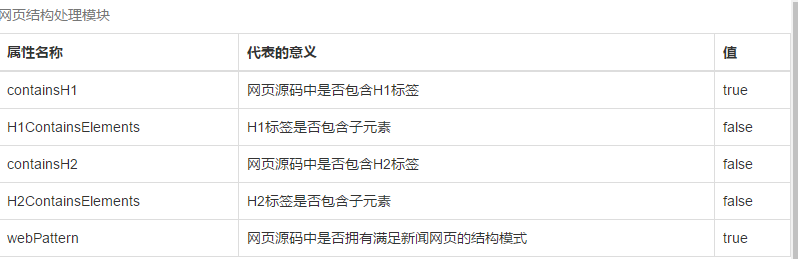
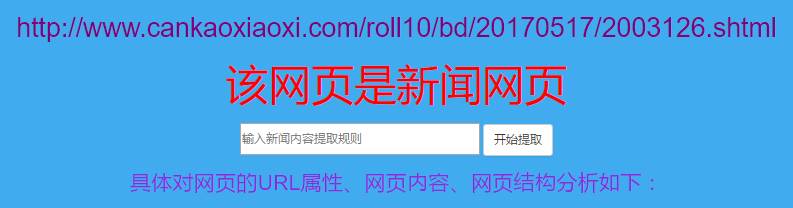
相关图片展示: