基于Python的股票数据分析毕业论文
2020-02-19 18:13:59
摘 要
在证券行业发展态势良好的今天,有海量数据留存于市场。但对于券商来说,他们会更加注重于新客户的挖掘来提升业绩。会有更多的新客户流入市场,一方面也是因为大家的生活水平日益提高,另一方面也是得益于股票市场可以获得相对可观的回报。但是由于股票市场财务数据繁杂,及时是有一定投资经验的人也会有如何有效获取并利用这些数据的困惑,于是用一定的技术方法来评估利用这些数据则成了一个值得学习研究的问题。
本文的内容主要是使用Python以及现有的数据挖掘算法,对股票的价格走向进行预测分析,再与股票市场的实际走向进行比较来评估这几个算法在股票分析方面的有效性。基于国内外的研究成果,阐述了关于数据挖掘的部分理论,使用了时间序列方法等技术对证券市场进行建模和分析预测。而对时间序列方法中还进行了细分,在一次指数准确度不够高的情况下使用了两次指数使得误差得到一定的减小。另外,还运用了马尔科夫链模型以及其改进方法,对股价涨跌进行一定范围内的预测,虽然相比LSTM算法来训练网络权值的方法而言计算量小些,但在预测效果上则稍有不足。最后的神经网络模型得到的预测效果则是在三者当中最为突出的,但是也有其自身的缺陷,计算量比较庞大。
关键词:股票市场;数据挖掘;Python;马尔科夫链;神经网络;
Abstract
Today, with the development of the securities industry in good shape, there are huge amounts of data remaining in the market. But for brokers, they will pay more attention to the new customers to improve their performance. There will be more new customers coming into the market, on the one hand because of the increasing living standards of everyone, and on the other hand, the stock market can get a relatively good return. However, due to the complicated financial data in the stock market, people who have certain investment experience in time will have the confusion of how to effectively obtain and use the data. Therefore, using certain technical methods to evaluate the use of these data has become a problem worth studying and studying.
The content of this paper is mainly to use Python and existing data mining algorithms to predict and analyze the stock price trend, and then compare the actual trend of the stock market to evaluate the effectiveness of these algorithms in stock analysis. Based on the research results at home and abroad, some theories about data mining are expounded, and the time series method is used to model and analyze the securities market. The time series method is also subdivided, and the use of two indices in a case where the index accuracy is not high enough causes the error to be reduced. In addition, the Markov chain model and its improved method are used to predict the stock price rise and fall within a certain range. Although the calculation is smaller than the LSTM algorithm to train the network weight, the prediction effect is It is slightly insufficient. The prediction effect obtained by the final neural network model is the most prominent among the three, but it also has its own defects, and the calculation amount is relatively large.
Key Words:Stock market;data mining;Python;Markov chain; neural network
目 录
第1章 绪论 1
1.1 选题的背景和意义 1
1.2 国内外研究现状 1
1.3 本文结构 2
第2章 数据挖掘与股票分析概述 4
2.1 数据挖掘技术概述 4
2.2 数据挖掘方法 5
2.3 数据挖掘过程 6
2.4 股票分析概述 7
2.4.1 股票的基本分析 7
2.4.2 股票技术分析 8
第3章 项目可行性分析及数据准备 9
3.1 数据挖掘技术在股票中的适用性 9
3.1.1 数据挖掘技术优点 9
3.1.2 股票市场的特点适合数据挖掘 9
3.1.3 Python适用于股票分析 10
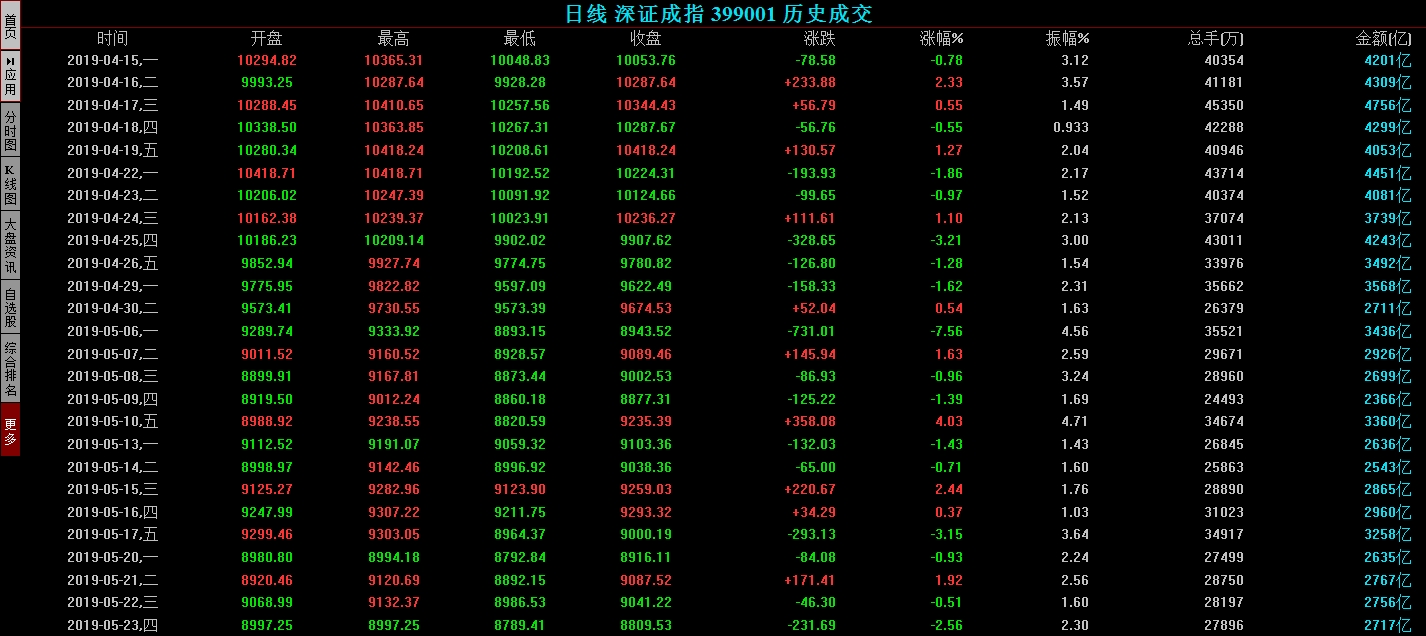
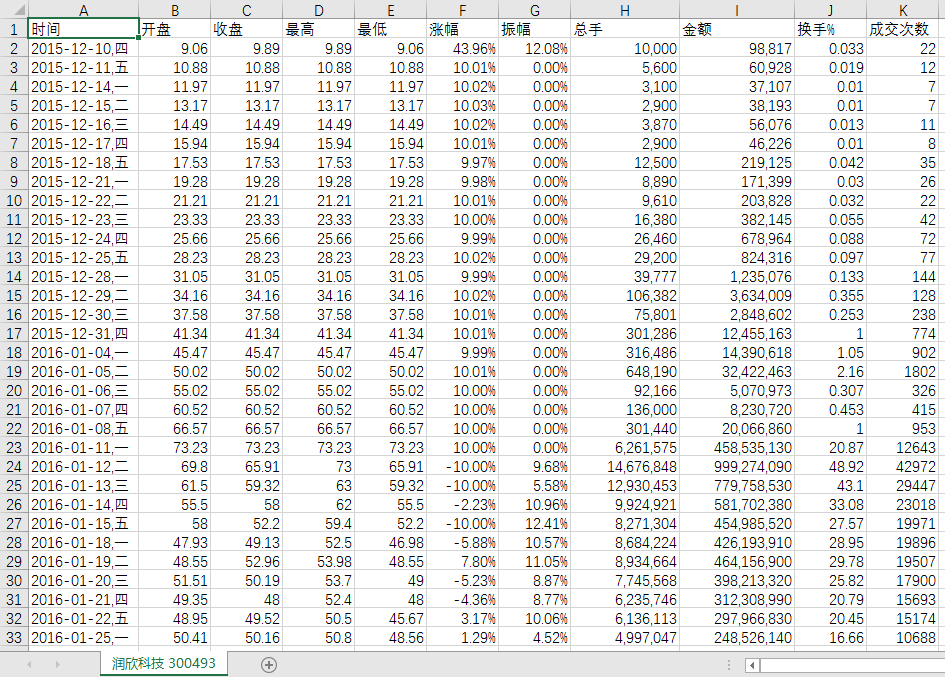
3.2 数据来源及数据准备 11
第4章 基于数据挖掘方法的预测实现 14
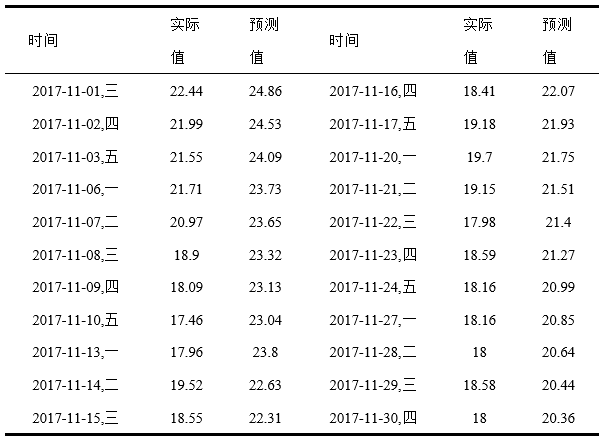
4.1 时间序列方法 14
4.1.1 一次指数平滑预测 14
4.1.2 两次指数平滑预测法 16
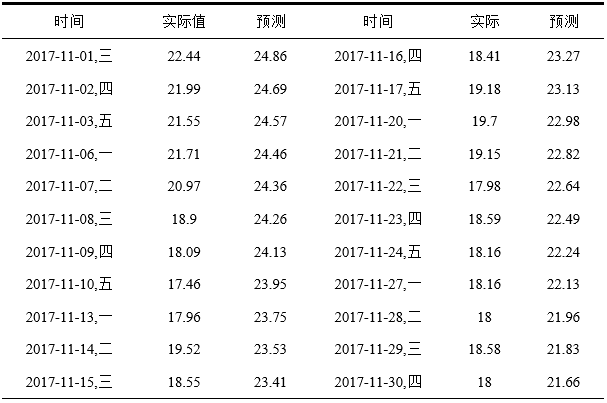
4.1.3 时间序列预测结果及分析 17
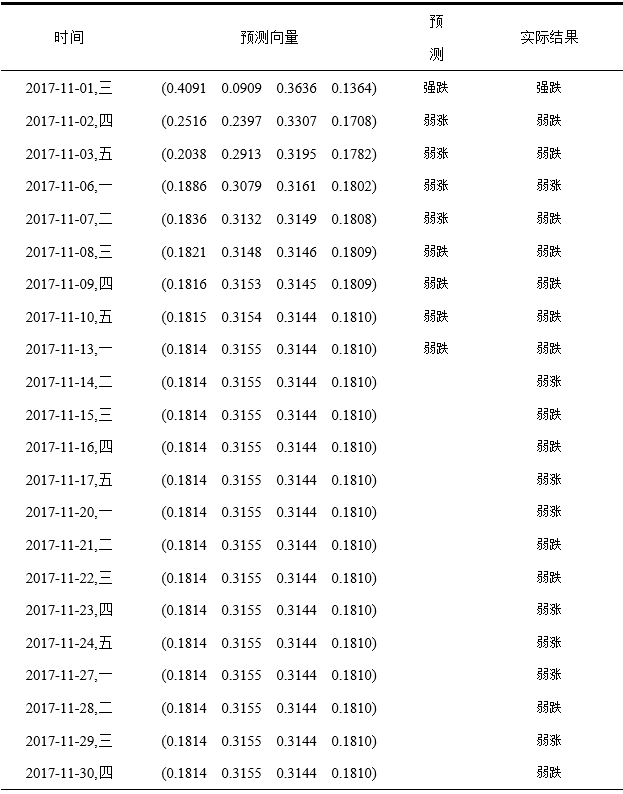
4.2 马尔科夫链的预测实现 17
4.2.1 马尔科夫链概述 17
4.2.2 马尔科夫模型构造及预测 18
4.2.3 马尔科夫链结果分析 21
4.3 人工神经网络 23
4.3.1 LSTM算法介绍 23
4.3.2 使用神经网络模型进行股票预测 24
4.3.3 神经网络模型预测结果及分析 24
第5章 总结与展望 27
5.1 总结 27
5.2 展望 27
致谢 29
参考文献 30
绪论
选题的背景和意义
从改革开放至今四十年来,国内生产总值增速逐年递增,相比于世界上其它国家的经济增长率更是遥遥领先,我国人民的经济观念也有了一定提升,越来越多的人有了理财投资的意识,存储在银行这种低风险且低回报的投资方式逐渐不被部分人所接受认可,转而将目光投向了具有更高受益的证券市场。经过几十年的建设发展,中国的资本市场也产生了翻天覆地的变化,相比以前已经有了许多的进步,且在社会的经济发展中也发挥着不可低估的作用,中国上海和深圳的股票交易所A股市场总市值也屡创佳绩。证券市场中投资队伍的规模也是呈逐年递增的架势,股票总市值也在不断攀升。与此同时,实体经济的状况也会收到证券市场运行情况的影响,它们两者之间的相互作用是不可忽略的。所以,证券市场作为从它诞生起就备受关注的金融行业中的重要组成之一,与大家的生活也是休戚相关的。
自股票诞生以来,就已经有许多研究学者、经济学家以及金融机构,为股价市值等数据制定了一些指标,如KDJ指标,还有众多的分析方法,如K线分析法、波浪理论等[1]。但这些指标又很复杂,有些计量模型还对来源数据有着刻板的限定,如要求有一定的平稳性,没有太大的噪声等。但这些条件在实际中则难以达到,其中的风险也是不言而喻的,因为证券市场的数量庞杂,数据间的关系也是错综复杂,它还会收到市场中诸多因素影响,难以寻觅其中达到规律,这些都会对投资带来较大的困难。
在数据量剧增的背景下,潜藏着一些对投资来说十分有价值的信息我们还没有发掘。因此对这些信息进行数据挖掘技术则可以更好的利用这些数据,找到它们之间的关联关系以及对未来走向的影响来提高我们对历史数据的有效利用率。基于此,本文使用Python作为分析工具,来研究数据挖掘技术在股票市场中的应用。而Python作为一门编程工具,也提供了许多便利的工具包,现在也有越来越多的人使用Python来完成金融量化交易。本文想运用时间序列、马尔科夫链以及人工神经网络来分析这些数据,大致预测股票的走势,协助投资者进行合理的决策,给予一定的参考作用。
国内外研究现状
数据挖掘技术在海量数据面前可以产生不错的效果,于是在其诞生以来就受到许多专家学者的广泛关注并投入大量研究。1992年的Stannlog等人,通过聚类等方法为基础开发了一个自动投资的智能系统来搜索股票在什么时候投资的回报是最佳的。Harman et al.(2000)将澳洲的众多指数如物价以及经济增长情况和当地的通货膨胀指数并结合回归算法来预测股票的选购,确定应该在什么时候买入。并得到用决策树模型的结果将会回报以18.7%的年平均报酬。Fang,Wada,Moody(2003)使用的是人工神经网络,并对纽约及美国的证券交易所从上世纪七十年代到本世纪初三十年的数据进行分析,并发现波动较大的股票它也同样具有较大的惯性。2005年Barak S, Modarres M等人先是通过调查确定对股票风险和受益的所有可能特性,然后再基于函数的聚类以及滤波器的基础上开发了一种混合算法:选择风险和回报预测的重要特征,然后选择风险和回报重新预测[2]。同年还有Patel J, Shah S等人比较了人工神经网络(ANN),支持向量机(SVM),随机森林(random forest)和朴素贝叶斯四种预测模型,对2003年至2012两支股价进行评估,通过计算10个技术参数得到随机森林在整体性能上优于其他三种预测模型的结论[3]。Khedr A E, Yaseen N基于财经新闻和历史股票市场价格的情绪分析,通过考虑与市场和公司相关的多种类型的新闻和历史股票价格,研究三家公司的股票价格数据集,得到的模型准确度又进一步得到了提高[4]。
在近年来,关于股票分析的研究也有许多,并且理论研究也在不断的进步。如2009年唐文慧使用了各种国内外主流的数据挖掘技术,分别论述了时间序列分析、决策树、人工神经网络这4种数据挖掘技术对股票进行预测,主要是它的技术分析方面,并建立相应模型然后对各类算法的使用程度做了一个评价[5]。2011年孙媌从股票的技术分析和基本分析两个方面分别使用决策树、向量机、聚类技术进行研究,建立相应的模型并在最后进行实证分析和比较[6]。2016年王爱平等使用改进BP神经网络算法,结合以往数据并对股票的近期走势进行预测,结果表明模型具有良好的预测效果,得到的误差也比较小[7]。2018年,曾武序等以Python为工具基础来爬取数据,并在BP神经网络中调整隐含层结点个数用的是批量梯度下降法,以获得更好的阈值和连接权值,进而预测股票的价格走势情况,以供投资者进行决策时借鉴[8]。
本文结构
本设计以Python作为语言工具,并应用数据挖掘中的相关技术来对股价的未来走向进行预测。本设计的目标是建立几个模型,而模型的基础则是依靠数据挖掘里面的常见算法,并利用这些模型对预测得到的股价进行分析,达到将数据挖掘技术与股票分析相结合的目的。
文章主要内容将从以下4个方面进行阐述:
第二章,主要介绍的是数据挖掘技术和证券市场的基本理论,对整个论文背景理论进行介绍。
第三章,阐述了项目的可行性,以及数据准备,主要是关于前期的准备工作。
第四章,给出了基于时间序列方法的股票市场模型并且本文将采用三种方法分别来对股价走势进行分析;然后使用Markov模型,一种动态随机模型,利用历史数据来分析随机变量的现实情况并对情况进行分类进而预测它们未来的变化情况,本文是将其跌涨情况分为四类,并根据Markov相关性质对股票走势有一个大致预测;最后以神经网络作为理论基础,调节权值及策略结合的方式来建立一个三层的神经网络来对股票走势进行预测,结果显示该法相较于前两者方法更为精确。
第五章,是对上述几种方法的结论进行比较并进行一个总结,对本设计中的缺陷以及未来需要进行的改进进行展望。
数据挖掘与股票分析概述
数据挖掘技术概述
如今,有很多数据的存在形式都是以数据结构的方式存储在网络上。而随着数据库及网络技术的快速发展,海量数据会产生并存储在互联网上。在数量如此庞大的信息面前,传统分析方法就显得心有余而力不足,人们常常从中获得有效信息。为了得到信息中可能包含的隐含价值,把杂乱无章的数据转变为有条理的内容,数据挖掘便适应时机而产生了。数据挖掘技术的自诞生以来发就发展迅速,并为这个信息时代带来了极大的便利。
数据挖掘(Data Mining),这个概念在上世纪的九十年代便已经诞生,但是截止至今在国际上还没有给出过统一的定义,但是它们都有一个共同的主题思想:从大量、有噪声、不完整的数据当中,利用该技术获取到潜藏在这些应用数据中的实际价值,进而对其进行分析,为决策提供一定的参考。它与传统的和数据进行简单比较或查询不同,数据挖掘要求对数据中各个层次进行分析并综合处理,以达到解决实际问题的目的。它还可以用来发现隐藏在数据当中的某些规律,为预测分析提供参考。
数据挖掘是一门比较综合的学科,它与许多的学科及技术上有联系并且经常为这些学科提供便利,其中融合了应用统计学、机器学习、可视化、模式识别技术等许多领域的知识,如图2.1。
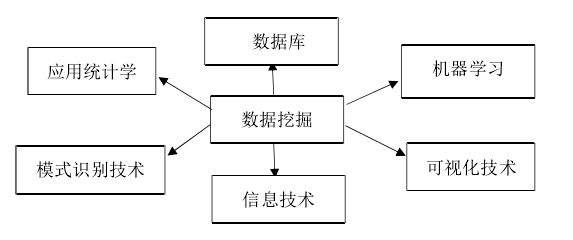
图 2.1 数据挖掘与不同学科之间的联系
从目前的发展形势来看,数据挖掘还在许多行业都有广泛应用,如电子商务、零售业、金融业、电商等,并且随着近些年来网购的迅猛发展,数据挖掘在前两个方面中的应用越来越广。而在金融行业里,数据挖掘也有其综合性的应用,如在银行的信用风险中、股票短期的趋势预测等。由此可见,数据挖掘的作用在各行各业都越来越受到重视。近些年,得益于数据挖掘技术在理论研究方面的不断完善和发展,进而推动了其在实际行业中的运用,尤其在一些数据使用率相对较高的方面则得到了进一步的提升。如拼多多、苏宁等电商,它们的数据库中记录着大量的客户行为数据,而这些电商行业则会使用数据挖掘的相关技术来对这些数据加以利用,比较典型的则是利用关联方法为用户推荐商品,增加某些商品的曝光率与销售额。
总之,数据挖掘技术,指的是从原有存储的庞杂数据中找出未发觉的、隐藏的具有价值的信息过程。数据挖掘是一项知识密集型技术,它基于应用统计学、数据库、AI、machine learning等多项技术,关联数据集当中的数据进而作出概括性的结论,获取潜在的信息模式,达到为信息挖掘者提供便利与具有参考价值的决策目的。
数据挖掘方法
这里主要介绍几种数据挖掘方法:
(1)关联分析:该方法将重心落在对象之间的相关性研究。它可以表示为X→Y,X代表前提B代表后续,意思是当发生X的时候,后续条件Y也会跟着触发。比较常见的关联规则挖掘算法有Apriority,、DHP、AIS等。
(2)序列分析:它与关联分析有些类似,但它着重的是不同对象在时序上的先后,它也可以表示为X→Y,表示事件Y会在X发生后发生。序列分析大致过程:在某个时间序列集合中,其中的每个元素都是根据发生的时间先后顺序来排列得到的一组交易集,将挖掘序列函数应用于该集合,然后返回该集合中出现次数较多的元素。
(3)分类分析:它要解决的问题就是对事物进行分类。分类分析既能用来分析已有数据也可用来预测。分类分析具体而言就是通过对历史数据的研究进而得到的预测模型。
(4)聚类分析:聚类的工作是首先把数据集分成不同组,并希望得到的群之间有较明显的差异,而同群之间数据的相似度要很高。在开始这项工作前,我们是无法知晓这些数据要如何划分以及分为几组,此时就需要某领域专家进行一定的指导。且一般一次聚类效果会不太好,需要经过几次反复的增删变量的方式来得到一个比较满意的结果。常见方法有K均值与神经元网络。
(5)神经网络:神经网络的数据处理能力很强,它是基于自学习的数据模型。面对海量数据时也可以进行分析且完成对于人脑来说相对复杂的分析任务。它在不同背景下可以有不同的形式,比如有指导性的学习或是无指导性的聚类,但它们在神经网络中的表现形式都是统一的,均为数值形式。
根据环境和需求的不同自己选择合适的挖掘方法,没有哪种方法是绝对的好和坏的,需要结合不同的情况进行具体分析。而本设计主要是运用时间序列、马尔科夫及神经网络三种方法来进行,在第四章会有具体介绍。
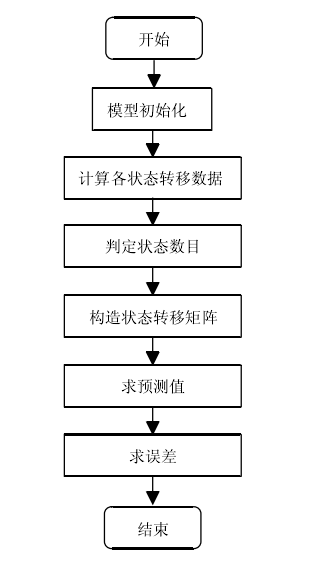
数据挖掘过程
数据挖掘过程是反复的,它的几个步骤也通常是有相互关联的,虽然在不同场景与需求下它的处理方式会有所不同,但数据挖掘的通常都会有以下几个步骤。如图2.2
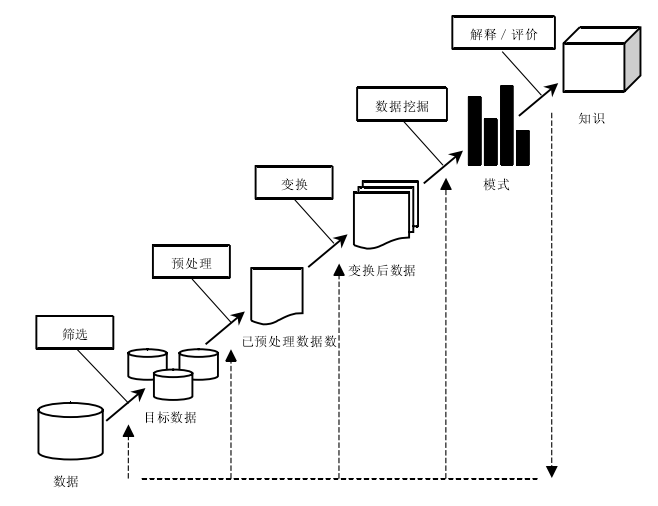
图 2.2 数据挖掘过程示意图
(1)定义问题:在数据挖掘开始前,首先要明确的是我们要达到怎样的一个目标,解决一个什么样的问题。确立目标则是数据挖掘前一项重要的准备工作,因为它的结果是不确定的,我们无法提前预测数据挖掘的结果,但我们可以先确立方向使得工作不会盲目进行。然后再对一些数据挖掘技术进行对比,比较它们的特点哪些更加适合该问题。
(2)数据准备:数据挖掘通常要处理的数据具有数量大、有噪声、有冗余、不完全等特点,所以在这个阶段我们需要对数据进行筛选、预处理和转换。数据筛选则是搜索有关项目的数据,从当中选取适合该项目及符合数据挖掘要求的。数据预处理则是为了提高数据的质量,如对数据进行必要的清洗、集成、选择等为接下来的工作准备[9]。
(3)建立模型:实际上就是数据转换的过程,它将我们得到的数据在挖掘算法的基础上转换得到一个适合进行挖掘的模型。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: