基于CNN的评语情感分类算法研究毕业论文
2020-02-19 18:14:20
摘 要
随着微博、豆瓣等社交平台的蓬勃发展,越来越多的网民在互联网上发表自己的看法,导致网络评语数量的急剧增长。面对大量的内容相似、表达随意的评语文本,要从中提取有价值的信息绝非易事,针对评语的情感倾向问题,探究行之有效的评语情感分类方法。文本的情感分类作为自然语言处理领域中的一个重要研究分支,一直是最热门的研究问题之一。众多研究人员对于情感分类开展了一系列研究,但是传统的研究方法,有很多弊端需要改进。针对传统支持向量机模型人力标注性能较差,提出一种针对文本处理的卷积神经网络模型。该模型通过词向量嵌入和dropout策略、以及L2正则化,在原始的Text-CNN模型的基础上将准确率提高了2%,并进一步降低了训练时间,具有良好的性能。
关键词:情感分类、卷积神经网络、词向量、深度学习、CNN模型
Abstract
With the vigorous development of social platforms such as Weibo and Douban, more and more netizens have expressed their opinions on the Internet, resulting in a sharp increase in the number of online reviews. Faced with a large number of commentary texts with similar content and random expressions, it is not easy to extract valuable information from them. For the emotional tendency of comments, we should explore effective method of rating emotions. The emotional classification of texts, as an important research branch in the field of natural language processing, has been one of the most popular research issues. A number of researchers have conducted a series of studies on sentiment classification. But traditional research methods have many drawbacks that need to be improved. Aiming at the poor performance of traditional support vector machine model, a convolutional neural network model for text processing is proposed. The model improves the accuracy by 2% based on the original Text-CNN model through word vector embedding and dropout strategy, and L2 regularization, and further reduces the training time and has good performance.
Key Words:Sentiment Classification、Convolutional Neural Network、Word Vector、Deep learning、CNN model
目录
第1章 绪论 1
1.1 概述 1
1.2 国内外研究现状 1
1.3 研究目的和意义 2
1.4 课题研究内容 2
1.5 本文组织结构 2
第2章 情感分类与机器学习相关理论 4
2.1 卷积神经网络 4
2.2 词向量word2vec 4
2.3 TensorFlow 5
2.4 损失函数 5
2.5 L2正则化 6
第3章 情感分类模型设计 7
3.1 情感分类算法 7
3.2 文本表示 7
3.3 改进Text-CNN模型 8
第4章 算法实现与结果分析 10
4.1 算法概述 10
4.2 数据集介绍与处理 12
4.3 评价指标 13
4.4 模型实现 13
4.5 参数设置 14
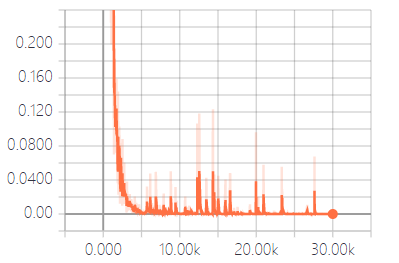
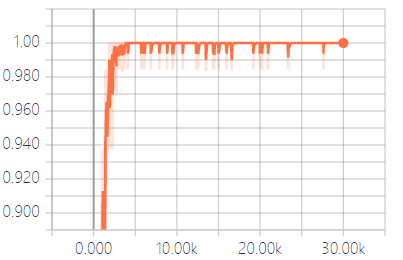
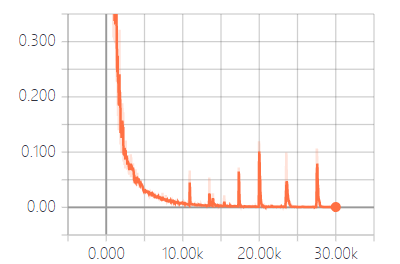
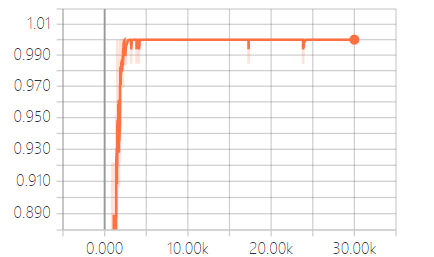
4.6 实验结果分析 15
第5章 总结与展望 20
5.1 研究总结 20
5.2 展望 20
参考文献 21
致 谢 22
第1章 绪论
1.1 概述
评语情感分类(Sentiment classification)做的工作主要是将互联网上各大平台上的评语进行分类。分类类别可以是二分类,或者是类似于豆瓣评分那样按照情感强烈程度分为五类。本文做的是文本的二分类问题,即将评语分为积极倾向的评语和消极倾向的评语。进行情感分类的方法主要分为两种。一类是传统的基于情感词的词性标注方法,另一类是应用机器学习的相关算法。前者依靠提取句子中词语的情感特征来判断句子的情感倾向,后者则是对于语料库的大量信息进行抽象凝合,分析学习其中的本质特征来分辨句子的情感极性。
深度学习(Deep Learning)作为机器学习(Machine learning)的一个重要研究方向,是一个抽象精炼的过程。通过多层处理逐渐将原始的低层特征表示转化为高层特征表示,训练一个特定模型完成复杂的分类等学习任务。近年来,深度学习相关算法在计算机视觉、图像处理领域有着成熟的应用。研究人员发现语料文本和视觉图像在本质特征上没有太大的区别,进而将深度学习相关算法应用在自然语言处理(Natural language processing,NLP)中,也有了一些不错的成果。因为卷积神经网络相比于传统的人工提取,在对信息的特征提取方面有很大的优势,使其在计算机视觉和语音识别等领域得到广泛的应用。2014年,Kim[1]提出了一种经典的用于英语文本分类的Text-CNN模型。该模型将经过预处理的原始语料,输入到CNN模型中,训练模型以实现句子级别的分类工作。与经典的模型相比,本文的主要工作是对原始Text-CNN模型的几个可以改进的方面进行了提高和优化。对句子进行字级的词向量构建,以学习更加具体的特征,同时定义多种不同尺寸的卷积滤波器,提高模型的分类能力,并引入dropout策略和L2正则化,提高模型的泛化能力。
1.2 国内外研究现状
近年来,研究人员提出应用于计算机视觉的CNN模型,经过修改后在NLP方面效果显著,并且在句子建模、语义分析等方面取得了优异的效果。虽然CNN在情感分类方面实现了较好的效果,但互联网上的评语文本存在格式多样、语法随意、缩写频繁等问题,给情感分类的语料处理工作造成很多不便。为了解决这些问题,不同时间阶段的研究人员给出了自己的方法。
2012 年,Yang 和 Xu [2]等人提出了基于支持向量机(Support Vector Machines, SVM)的情感分类算法。优势是改善了传统的情感分类方法对于人工特征提取过度依赖的缺点,缺点是在实际的分类问题中没有很好的普适性。2016年,张英[3]等人针对传统的长短时记忆(LSTM)模型的进行了创新,提出一种基于双向长短时记忆(BLSTM)的循环神经网络(RNN)模型。该模型对于文本评语的情感提取工作有了很大提高,分类准确率也上升了一个台阶。但是该模型受限于文本的长度,仅仅适用于互联网上的短文本。随后,杜昌顺[4]等人提出了基于CNN模型的情感分类算法,将准确率提高到91%,大大增强了模型的性能。但是,模型的训练时长比较长,需要后续的优化。文献[5-11]主要针对中文文本的特点,尤其是对微博平台的文本进行提取,提出了各自不同的模型算法,针对不同的角度对之前提出的模型进行了对比优化提高。2018年,尹化荣[12]分别针对传统神经网络模型拟合能力较低、神经网络训练时间较长、传统情感分析需要人工参与且识别率较低,大规模应用成本较高的不足提出了改进的CNN模型。同一年,郝利栋[13]提出了MMCNN和SA-LSTM分别从增加特征提取的种类和加入Attention机制的方式,克服了无监督学习对词典的依赖和监督学习对特征的依赖问题。随后,郑雅雯[14]提出基于LS-SO算法的文本情感分类方法和基于Attention 机制的Bi-LSTM模型的文本情感分类方法,较以前的文本情感分类方法在有些方面有所优化与改进。
综合分析以上方法的提出,目前的情感分类算法研究主要分为基于SVM、基于LSTM、基于CNN和基于RNN这几种模型算法。虽然每种算法都有各自独有的优势,对于文本的处理有着自己的独到之处,在具体的应用中取得了一定的成果,但是没有哪种模型是完美的,所以有很多问题需要我们去解决和优化。这些模型的短板不是一时半会儿就能解决的,这里面牵扯了太多包括矩阵、概率统计等领域的知识,需要我们深入学习。本文的研究主要解决以下三个方面的问题:
- 传统的情感分类方法依靠人工特征提取,在面对大型语料库时,不仅效率低而且工作量巨大。
- 面对海量的原始语料,情感分类模型的训练容易产生过拟合问题,对文本的分类难以达到理想的结果。
- 传统的情感分类算法的模型训练时间比较长,在实际应用中体验较差。
1.3 研究目的和意义
传统的情感分类方法需要人工提取文本语料的情感特征,工作量大又麻烦。针对这个弊端,卷积神经网络有着先天的优势,能够进行自动化的情感特征提取。并且卷积神经网络具有层次结构,层次越多提取的特征越精确,从而模型的分类能力越强。所以本文将卷积神经网络相关算法应用于评语情感分类的研究。同时,针对原始的Text-CNN模型在特征提取过程、训练效率以及模型的拟合能力等方面有很大的提高空间的情形,考虑从这几方面入手研究,进一步调整优化以提高模型的性能。
1.4 课题研究内容
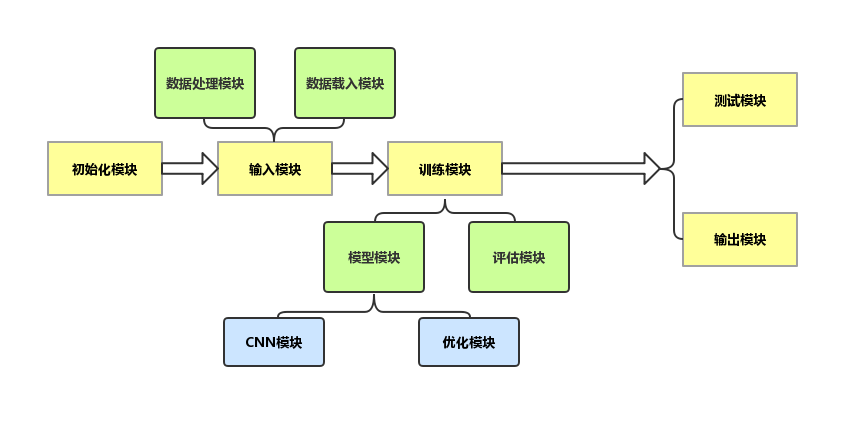
本文的主要工作是在Text-CNN模型的基础上,训练一个改进的CNN模型,将从互联网上获取的评语语料处理成词向量,输入到有监督的神经网络模型中进行卷积、池化操作。在训练过程中进行比较分析,保持词向量静态并不断更新模型的相关参数。之后手动对超参数进行调整,使我们训练的模型在测试过程中得到理想的结果。通过微调、提前终止等策略来改进模型,提高模型的精准度。我们的工作可以证明CNN模型不仅在图像处理等方面有很好的优势,对于文本的处理、分类也有其适用性。
1.5 本文组织结构
本文针对情感分类的研究现状,以及CNN在情感分类方面的应用进行了介绍和说明,概括了情感分类工作的难点和局限性,对CNN模型算法和自然语言处理的基本知识进行了简单介绍,分析和研究了Text-CNN模型可以优化和改进的点,概述了其工作流程并解释了其工作原理,并对其结果进行了分析和总结。
第一章为绪论部分,举例介绍情感分类的国内外研究现状,说明本文的研究目的及意义,简要概述了本文的研究内容。
第二章介绍了本模型用到的自然语言处理和神经网络的一些预备知识,包括对卷积神经网络、词向量、情感分类等的概述,以及对TensorFlow的介绍,为后文详细讲解本模型的工作原理做好知识铺垫。
第三章详细描述了本模型中的算法基础、模型的原理和本模型的优化重点。
第四章细致地说明本次研究的实验设计过程,包括数据获取和预处理、评价指标、参数设置等,得出并分析实验结果。
第五章对本文的研究工作进行了深刻总结,并对研究方法、模型优化和后续深入研究提出了展望。
第2章 情感分类与机器学习相关理论
情感分类和卷积神经网络都是自然语言处理领域的热门研究内容,它们之间的相互结合是情感分类研究的伟大尝试,把CNN模型运用到文本的处理,是对图片、音频等信息的拓展,模型能够有效提取文本信息的特征,高度抽象化后以实现情感分类的功能。
本章主要把模型设计需要的理论知识、训练效果的评价指标、框架选择等基础内容进行一下简单的介绍,为后文模型的实现奠定基础。
2.1 卷积神经网络
在深度学习领域中,研究人员提出了许多模型,其中卷积神经网络(Convolutional Neural Networks,CNN)得到了广泛的应用。其本质是一个多层次的感知器,因其带有卷积结构(卷积层)所以被称为卷积神经网络。CNN模型一般由卷积层、池化层和全连接层堆叠而成,主要有三个优点,其一是稀疏的交互(sparse interaction),其二是参数共享(parameter sharing),其三是等价表示(equivalent respresentation)。由于深度学习在计算机视觉方面落地的比较早,所以基于CNN的图像处理研究远多于对于文本分类的研究,近些年在NLP方面也取得了卓越的成就。模型先通过卷积层提取一般特征 ,然后经过池化处理后进一步抽象出更关键的信息,充分挖掘原始语料的信息,通过大量的原始语料来学习文本的特征以实现后续的功能。本文将CNN模型应用于情感分类研究中来解决评语的情感分类问题。
2.2 词向量word2vec
在自然语言处理中,原始语料中的词语在计算机中有两种表示方式,一种是one-hot编码,另一种是分布式表示。
One-hot表示方法比较直接,就是用一个“长向量”来表示一个词,向量中只有该词对应的编码位置为“1”,其余的位置均为“0”。这也就保证了每一个词在词典中都有唯一索引,向量长度就是词典的长度。这种简单粗暴的表示方法好处就是简单易于理解,但是有很大的隐患,容易造成维度爆炸的问题。还有一个问题就是词与词之间是孤立的,不能够很好地联系起来。
分布式表达方式是将词变成一种分布式表达方式,也就是词向量。词向量与one-hot编码最大的区别,也是其最大的优势,在于它是一个“短向量”(相比one-hot编码的稀疏向量,词向量是一个稠密向量),这样在进行存储的时候节省了很多内存空间,提高了模型训练的速度。词向量不仅避免了维度爆炸的问题,因为其词语之间联系紧密,词语之间可以通过“距离”判断相似性,有利于语义信息的处理。
word2vec,它是一种无监督的学习模型,可以在一个语料集上(不需要标记,主要思想是“具有相似邻近词分布的中心词之之间具有一定的语义相似度”),实现词汇信息到语义空间的映射,最终获得一个词向量模型(每个词汇对应一个指定维度的数组)。
word2vec就是分布式词向量表达的一个典型应用。Word2vec本质就是一个神经网络的简化形式,一般包括CBOW和Skip-Gram两种模型。两者思路完全相反,CBOW的输入是某个词上下文相关的词对应的词向量,输出是这个词对应的词向量。而Skip-Gram则是输入某个词的词向量,输出上下文词向量。前者适用于小型语料库,后者适用于大型语料库。
2.3 TensorFlow
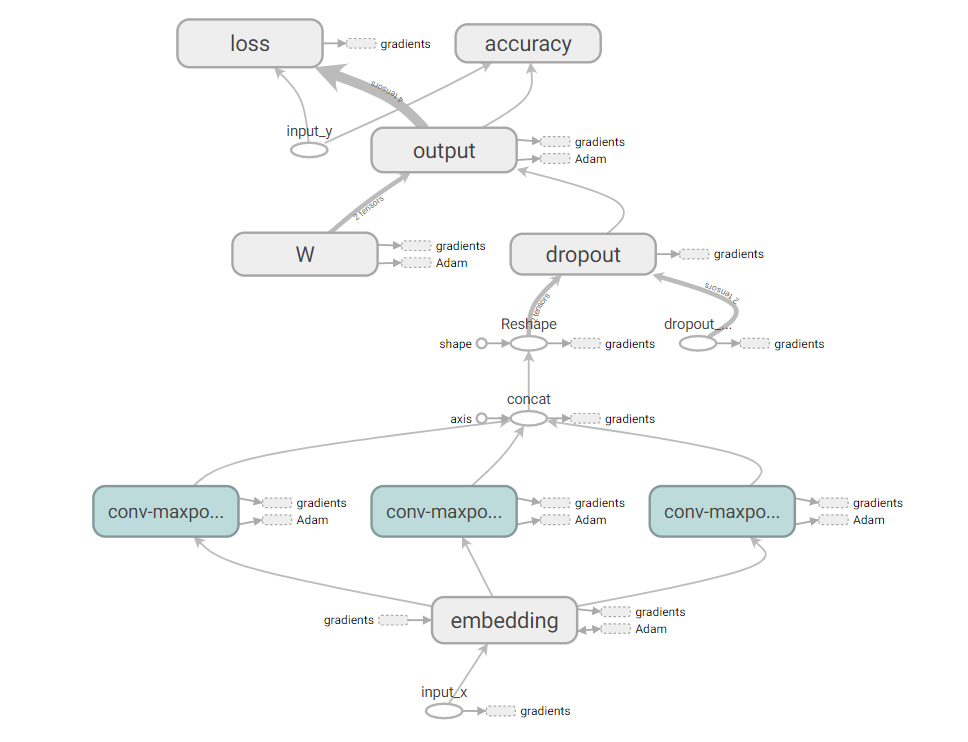
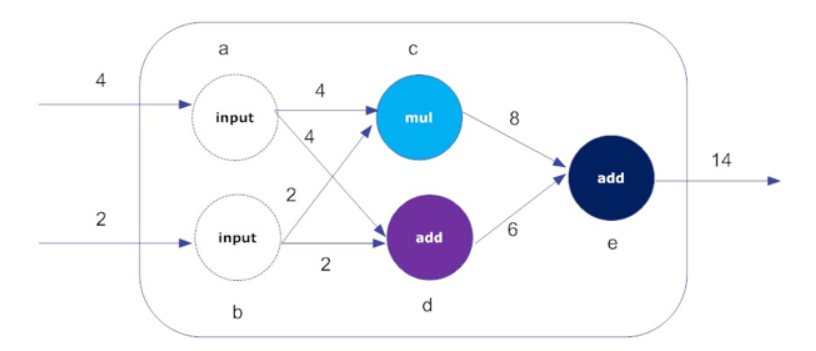
TensorFlow是Google开发的一个开源框架,用于机器学习和深度神经网络方面的研究,其优秀的通用性使其在其他的计算领域也得到了广泛的应用。Tensorflow框架采用数据流图(data flow graphs)的方式,使系统的开发过程清晰透彻。
数据流图由点和线组成。点表示一种操作,一般是数学运算。线表示数据在不同节点之间的输入输出过程。线还可以用来输运“尺寸可动态调整”的多维数据数组,即“张量”(tensor)。这个框架取名为“TensorFlow”的原因就是因为可以形象地描述张量从图中流过的直观图像的过程。
TensorFlow具有如下几个优点:
- 具有高度的灵活性;
- 在可移植性方面表现优秀;
- 将科研和工业界产品联系在一起;
- 提供包括自动求微分的各种强大的库函数;
- 提供多语言支持,不仅对python友好;
- 可以在浏览器中训练模型。
2.4 损失函数
在模型的训练过程中,损失函数是必不可少的一个环节。其本质是模型的真实值和预测值的差值,能够评估模型的训练效果。损失函数常被研究人员选择作为算法的目标函数,尤其是在分类问题或者是回归问题中。一般来讲,损失函数的值越小,其模型的性能越好,拟合能力越强。在这里,简述几种常见的损失函数:
1)0-1损失:最简单的损失函数,当真实值和与预测值相等,值为0,不相等时值为1,其表达式为:
(2.1)
2) 均方差损失:常用在最小二乘法中,求解拟合曲线的最小距离,其表达为:
(2.2)
3) 交叉熵损失:通过一个Sigmoid函数,输出概率值,差值与L成正相关,其表达式为 :
L(Y,P(Y|X))=- (2.3)
本文要解决的问题是二分类问题,所以在卷积神经网络模型训练中选择了交叉熵损失函数来评估模型训练效果,这也是神经网络模型最常用的损失函数。
2.5 L2正则化
由于模型的训练过程涉及到众多参数,会导致模型的复杂程度变高,进而会导致过拟合问题的发生。过拟合,顾名思义,即模型的拟合程度过高,具体表现就是模型在训练集上准确率极高,但是在测试集上不高。为了解决这种问题,引入L2正则化的概念。
L2 正则化的公式简单直观,公式如下:
L= λ (2.4)
在原有损失函数(训练样本误差)Ein的基础上加上权重参数的平方和构成L2正则化的公式,其中,λ是正则化项的参数。
损失(loss)是用来评估网络模型性能的标准参数,我们的目标是尽可能减少网络的误差。为了达到这个目的,最简单的做法就是减少w的数目,但是求解困难。一般采用更简单的限定条件:
(2.5)
在上式中,对w的平方和上限进行了限定,w的平方和不大于参数C。这样,我们的目标就变为最小化损失函数,在w的平方和不大于参数C的条件下。接下来,用图来说明如何进行最小化。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: