资源动态推荐算法研究及应用毕业论文
2020-02-19 18:14:22
摘 要
当下移动互联网不断地发展,人们每天都会在网络上浏览许多有关电子商务、新闻资讯、音乐视频等许多领域的内容资源。但是面对海量无序的信息,单靠用户自己来查找往往效率低下,大多数时间都会浪费在搜索与自己兴趣相关的内容上。为了满足用户对于个性化的需求,本文设计了一种资源的动态推荐算法,利用个性化推荐技术针对用户当前感兴趣的资源来动态地调整推荐列表,发掘用户的兴趣,为用户推荐更多的可能感兴趣的信息。
本研究主要从传统的协同过滤推荐算法来展开,通过结合矩阵分解模型和基于物品的协同过滤算法构建了一个动态推荐资源的算法,并进行了一定的优化改进,从而弥补了二者单独完成推荐的不足。首先根据过滤并加工过的用户行为记录来计算物品间的相似度并得到相关表,同时利用SVD算法离线训练好矩阵分解模型。再根据目标用户当前感兴趣的物品,结合相关表与用户的历史行为计算其兴趣度,生成特征-物品相关的初始推荐。而后通过SVD模型对初始推荐结果进行优化,最终生成新的推荐列表。该算法在实际的公开数据集MovieLens上进行了有效性验证。通过对比实验的结果表明,本研究提出的ItemCF-SVD-IP模型取得了良好的推荐效果,从而证明了该算法能够捕捉用户当下的兴趣偏好,并提供高质量的推荐结果。
关键词:个性化推荐;动态推荐;协同过滤;SVD
Abstract
With the development of the mobile Internet, people browse a large number of content resources on e-commerce, news information, music videos and many other fields on the Internet every day. However, in the face of massive and disordered information, it is often inefficient to search by users themselves, and most of the time is wasted looking for information related to their interests. In order to meet the individual needs of users, this thesis designs a dynamic recommendation algorithm for resources, which uses personalized recommendation technique to dynamically adjust recommendation lists for users' current preference, explore user interests, and recommend more information that may be of interest to the user.
This research is mainly based on the traditional collaborative filtering algorithm. By combining the matrix decomposition model and the item-based collaborative filtering algorithm, we construct a dynamic recommendation resource algorithm and carry out certain optimization and improvement, so that it can make up for the lack of the two to complete the recommendation. Firstly, based on the filtered and processed user behavior records, the similarity between the items is calculated and the related table is obtained. At the same time, the matrix decomposition model is trained offline using the SVD algorithm. Then, according to the items currently of interest to the target user, the preference degree is calculated according to the relevant table and the historical behavior of the user, then the feature-item related initial recommendation is generated. Next, the initial recommendation results are optimized by the SVD model, and a new recommendation list is finally generated. The algorithm is validated on the real public data set MovieLens. The results of the comparison experiments show that the ItemCF-SVD-IP model proposed in this study has achieved good recommendation performance, which proves that the algorithm can capture the user's current interest preferences and provide high-quality recommendation results.
Key Words:Personalized recommendation; dynamic recommendation; collaborative filtering; SVD
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.1.1 研究背景 1
1.1.2 研究意义 1
1.2 国内外研究现状 2
1.3 论文的主要研究内容 3
1.4 论文的组织结构 4
第2章 推荐系统相关技术综述 6
2.1 推荐系统结构和推荐流程介绍 6
2.2 推荐系统基本算法 7
2.2.1 推荐算法介绍 7
2.2.2 推荐算法对比 8
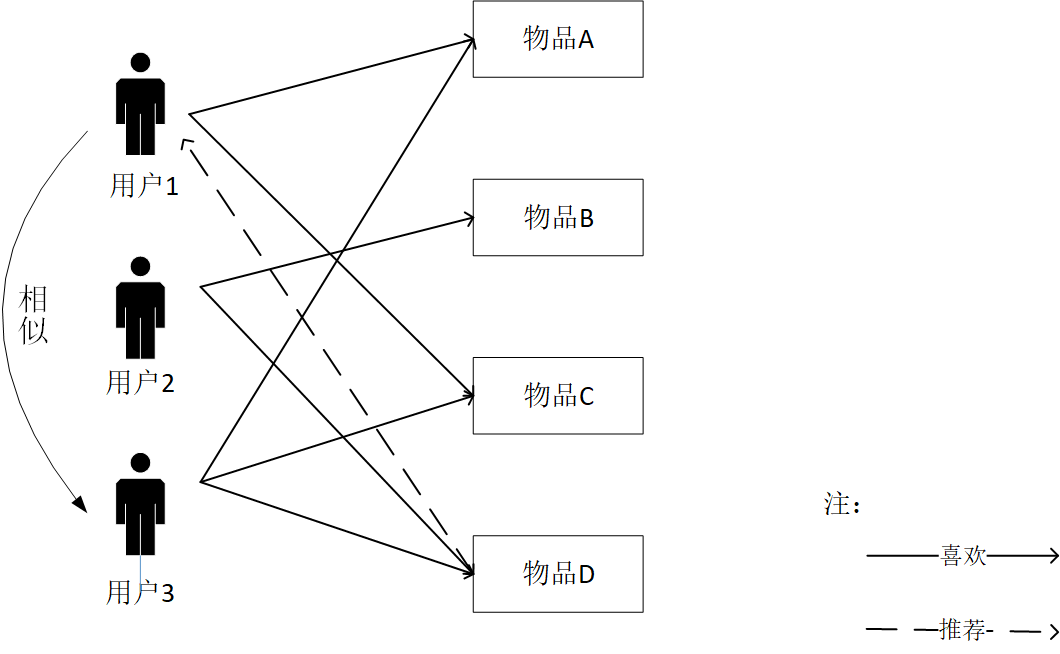
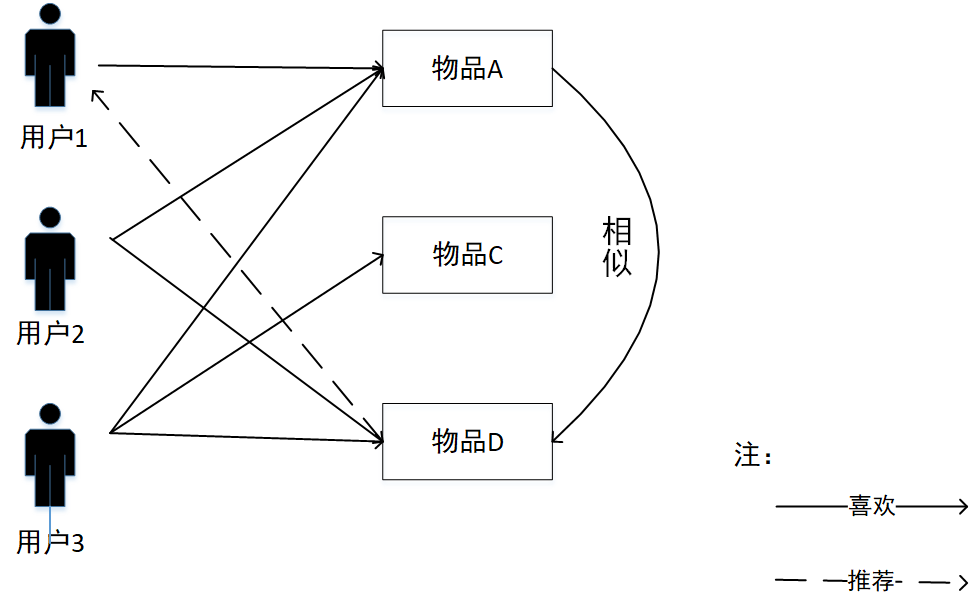
2.3 协同过滤 9
2.3.1 协同过滤分类与原理 9
2.3.2 协同过滤算法对比 11
2.4 SVD算法 12
2.4.1 SVD算法提出背景 12
2.4.2 SVD算法原理 12
2.5 本章小结 13
第3章 动态推荐算法的设计及实现 14
3.1 数学符号定义 14
3.2 算法设计 14
3.2.1 计算物品的相似度 14
3.2.2 生成初始推荐结果 16
3.2.3 SVD生成推荐列表 17
3.3 算法改进 17
3.3.1 用户活跃度的影响 17
3.3.2 物品相似度的归一化 18
3.4 本章小结 18
第4章 实验评估 19
4.1 实验设置 19
4.1.1 实验环境描述 19
4.1.2 数据集描述 19
4.1.3 参数设置 19
4.1.4 评价标准 20
4.2 实验结果及分析 20
4.3 本章小结 21
第5章 总结与展望 22
5.1 论文工作总结 22
5.2 研究工作展望 22
参考文献 24
致 谢 25
第1章 绪论
1.1 研究背景及意义
1.1.1 研究背景
近年来,移动互联网的规模和覆盖面随着智能手机的迅速普及而不断发展扩大。5G时代的到来,标志着我们获取信息的渠道和方法更加丰富。而云计算和大数据的发展也使得互联网信息量呈指数性增长。技术为创新与发展提供了动力,同时也带来了一些消极影响,“信息过载”就是其中之一。不断增加的信息量和大量的冗余信息使我们难以对有用信息进行准确的分析和正确的选择,从而使得获取信息的成本不断上升。尽管搜索搜索引擎的出现使得用户可以通过关键字的搜索来主动获取其需求相关的信息,但随着Web 2.0的发展,用户不再只满足于基于关键字的检索方式获取到的信息,而更倾向根据自身喜好来获得个性化的信息服务。与搜索引擎相比,推荐系统真正做到了主动推送,而不需要用户提供明确的需求。
近年来推荐系统逐渐被应用于各个领域,例如电子商务、社交网络、电影推荐等。其价值在于帮助用户解决信息过载以及做出更好的选择,也是目前互联网领域中最强大和最流行的信息发现工具之一。
1.1.2 研究意义
传统的推荐技术根据系统中所有登录用户的历史行为记录,计算并得到整个用户群的行为特点,把大众用户普遍喜欢的信息,即所谓的热门信息,推荐给目标用户。这种方法推荐的结果对关注时事新闻、追赶新潮的用户相对有效,但由于没有考虑到个体的兴趣差异,针对有需求的特定用户来说不够理想。为了能够更精准地为每个用户进行推荐,个性化推荐这一概念被提出。
个性化推荐系统(Personalization Recommendation System)[1]通过收集用户行为数据,对于用户每一个清晰表达的请求结合物品属性等各类知识利用一定的算法进行分析,挖掘出用户的偏好信息与即时需求,从而分别建立起适用于每个用户的兴趣模型。然后把待推荐的信息与用户的兴趣模型进行匹配,通过设置一定的阈值来对信息进行过滤,进而把合适的信息推荐给用户。用户对推荐的接受与否,将作为系统立即或过一段时间进行再次分析所利用的反馈信息。然而,用户的需求不是一成不变的,物品也有自己的生命周期,推荐的内容要持续更新,这些动态特征都决定了动态推荐的重要性。只有能够及时捕捉用户兴趣和物品等属性变化的个性化推荐系统,才可以帮助用户找到更加适合自己的物品,给用户带来惊喜感,提升用户体验并增加用户粘性,从而在实际应用中为信息生产者带来更高的利润与更强竞争力。
1.2 国内外研究现状
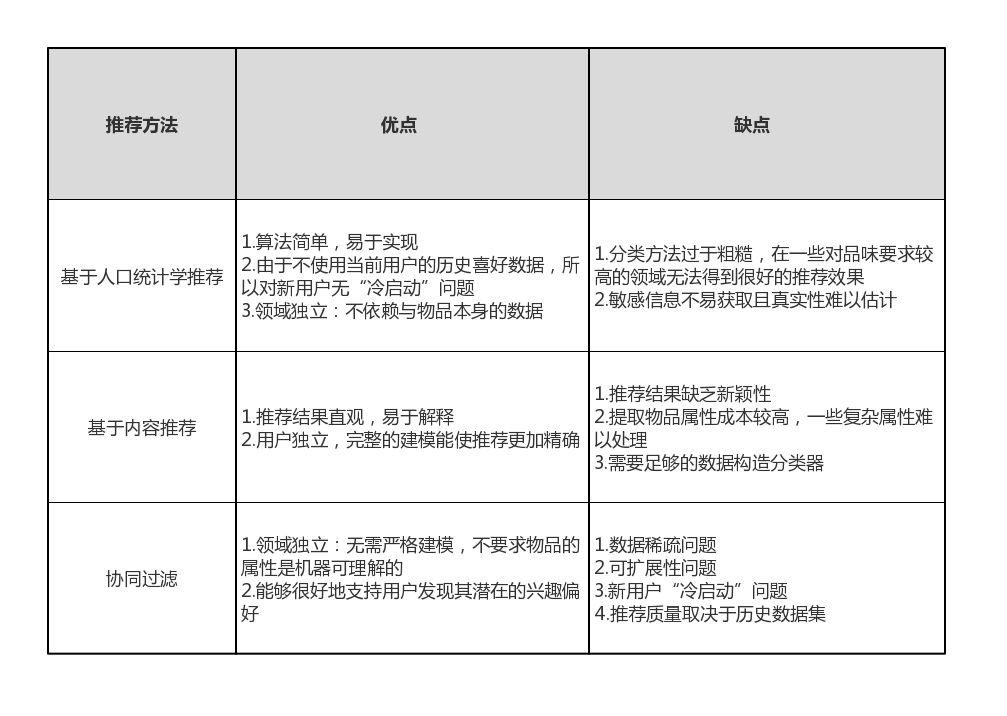
在上世纪90年代中期,推荐系统成为一个相对独立的研究方向,开始被用于物品推荐的研究和用户兴趣的预测。传统的推荐系统算法主要包括基于人口统计学的推荐、基于内容的推荐[2]-[3]、基于协同过滤的推荐[4]以及混合推荐。其中最典型的是基于内容的推荐和协同过滤推荐。它们在一些有很高评价的网站中,例如国外的Amazon.com、Facebook、Netflix、YouTube,国内的淘宝、今日头条、京东等,都扮演了非常重要的角色。
个性化推荐系统能够在一定程度上解决信息过载的问题。但是随着物品数量的不断增加,推荐引擎的数据处理能力逐渐降低。如果不对传统算法进行进一步的研究与修正,推荐效果将变得差强人意,从而导致用户不断流失。为了获取更加精准的推荐结果,需要对推荐领域存在的问题进行更加深入地研究。目前,最常见的有冷启动、数据稀疏和扩展性问题[5]:
- 冷启动问题(Cold-start):由于缺乏数据而产生的推荐困难问题,主要包括用户冷启动、物品冷启动与系统冷启动。用户冷启动主要解决针对第一次进入网站的没有行为数据记录的新用户,如何对其进行有效的个性化推荐。主要解决方法为提供非个性化的推荐,例如给用户展示热门排行榜。等到系统采集了一定数量的用户数据后,再切换为个性化推荐。物品冷启动主要解决对于系统中新加入的物品,没有用户对其表达过偏好信息,如何将其推荐给可能感兴趣的用户。通常可以利用物品内容信息来缓解这类问题。而系统冷启动主要解决如何在一个新开发的网站上加入个性化推荐模块。一般可以通过专家进行标注,以一定的有效方式建立起初始的物品相关度表。
- 数据稀疏问题(Sparsity):推荐引擎在推荐时,需要将用户行为数据以用户-物品评级矩阵的形式进行存储。该评级矩阵是协同过滤实现推荐的基础,通过这些数据来挖掘用户的偏好信息,从而向用户进行推荐。显然,这些依赖的数据越多,矩阵越完整,推荐就越准确。然而通常系统中只有少部分用户对少量物品进行显性评级,评级数量往往低于5%[6],目前最常用的MovieLens数据集的稀疏度是4.5%,Netflix是1.2%,而Delicious只有0.046%[7]。数据稀疏问题在本质上是一种信息缺失的表现,在这种情况下计算的推荐结果会存在较大的偏差。
- 可扩展性问题(Scalability):优质的推荐系统可以实时、准确地完成对目标用户的推荐。用户行为数据的增多有利于提高个性化推荐系统的精准度,然而当面临上百万甚至数千万的用户和物品需要处理时,一般的推荐算法会遭遇严重的扩展性瓶颈,如海量数据的存储和算法的计算效率问题,即所谓的可扩展性问题。在难以同时满足二者的情况下,如何均衡推荐时效性与算法的可扩展性已然成为了当前推荐领域研究的重点之一。目前这类问题可通过离线计算和分布式并行计算得到一定的解决[8]。
1.3 论文的主要研究内容
本文主要的研究内容是围绕现有的资源推荐算法,设计一个实际的资源动态推荐算法。主要从三个方面展开研究与设计,分别是用户特征提取、特征-物品相关表的构建和推荐结果的优化。同时,对传统算法的缺点进行有一定针对性的改进,旨在实际推荐中设计算法能够更加满足用户的需求,从而提高推荐的质量。具体的研究内容如下:
- 用户特征提取
为了让推荐结果符合用户口味,我们必须深入挖掘用户的兴趣。由于用户兴趣和需求是难以表述且动态变化的,我们需要通过一定的方式自动采集记录用户行为的数据,从中推测出其偏好兴趣。实际网站通常会通过日志。系统将用户在界面上的各种行为记录到用户行为日志中,并存储于内存缓存或数据库中。我们需要从中拿到用户的行为数据,通过对其分析来生成当前用户的特征向量。
- 特征-物品相关推荐
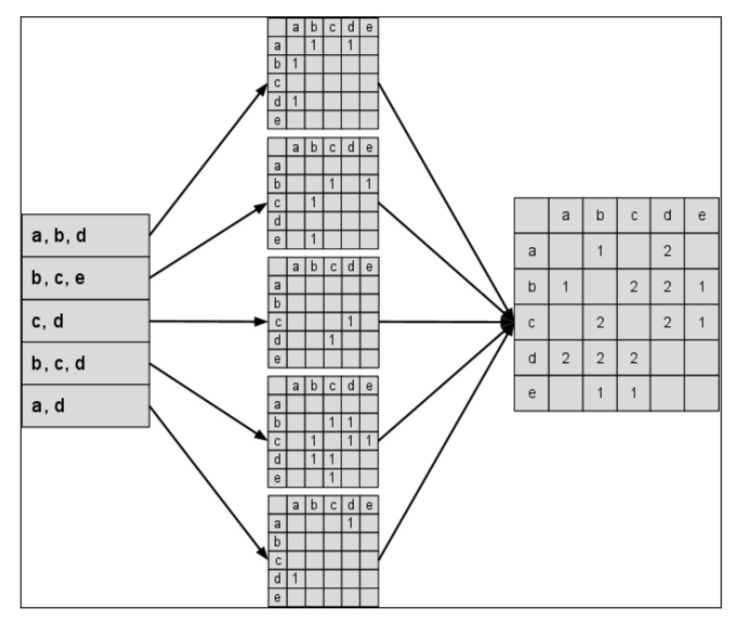
该模块为研究工作的核心部分。由于针对不同的需求,系统的推荐任务也有一定的多样性,如给用户推荐多种类型的物品、将需要宣传的或新上线的物品推荐给用户等。不同的推荐目标需要不同种类的推荐引擎来承担生成相应物品相关表的任务。推荐算法再根据特定的相关表,结合用户特征向量并通过一定的算法进行计算,从而得到初步的物品推荐结果。在这一模块的算法设计中,我们通过分析不同推荐算法的优势和劣势,选取了相对来说最适合的算法——基于物品的协同过滤。该算法可以满足我们推荐所期望的动态性,它将相关表缓存在内存中,能够基于用户产生的新行为在线进行实时计算,从而生成一个新的推荐结果。我们在考虑用户活跃度和相似度的归一化后在算法的基础上进行了一定的改进,进而得到推荐的初步结果。
- 推荐结果优化
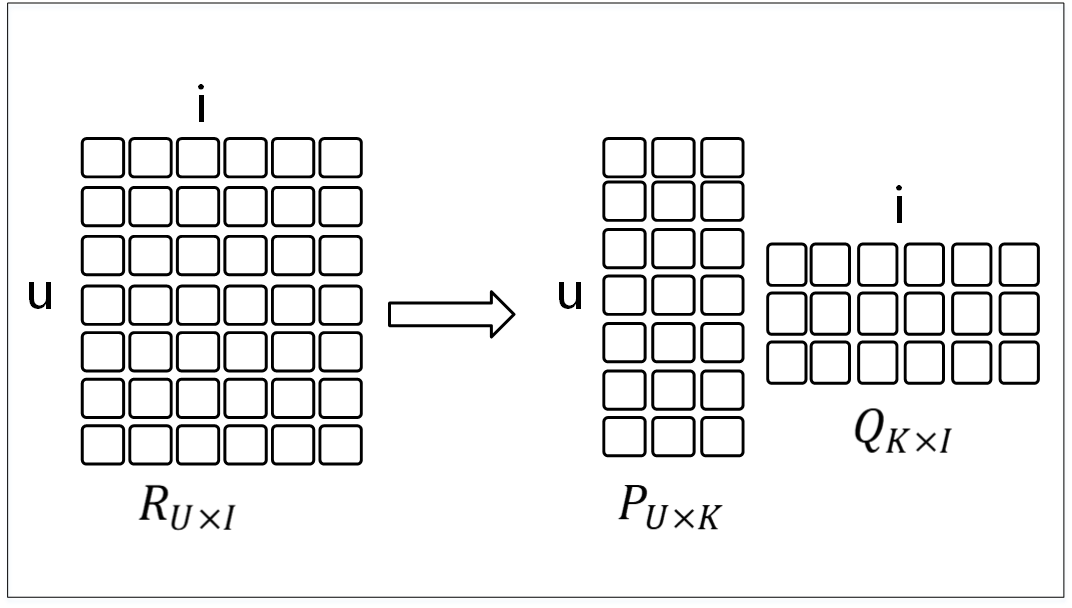
初始推荐列表生成后,为了提高推荐的准确性和用户的满意度,我们需要对结果进行更进一步地优化。上一模块中使用的基于邻域的模型在检测局部的关系中十分有效,他们依赖一些明显的邻居关系,然而实际却中会忽略绝大多数其他用户的评分,无法捕获所有用户行为中包含的弱信号的总量。所以在该模块下,我们引入隐语义模型[9],它能够有效地估计与大多数或所有物品同时相关的总体结构。但由于该模型在检测小部分密切相关的物品之间的强关联性方面不够理想,这正是邻域模型做得最好的地方。故本算法将在生成初始列表中采用基于邻域的模型,在该模块下采用隐语义模型对排序列表进行优化,生成最终展示给用户的推荐列表。
本文的主要工作路线如下图1.1所示:
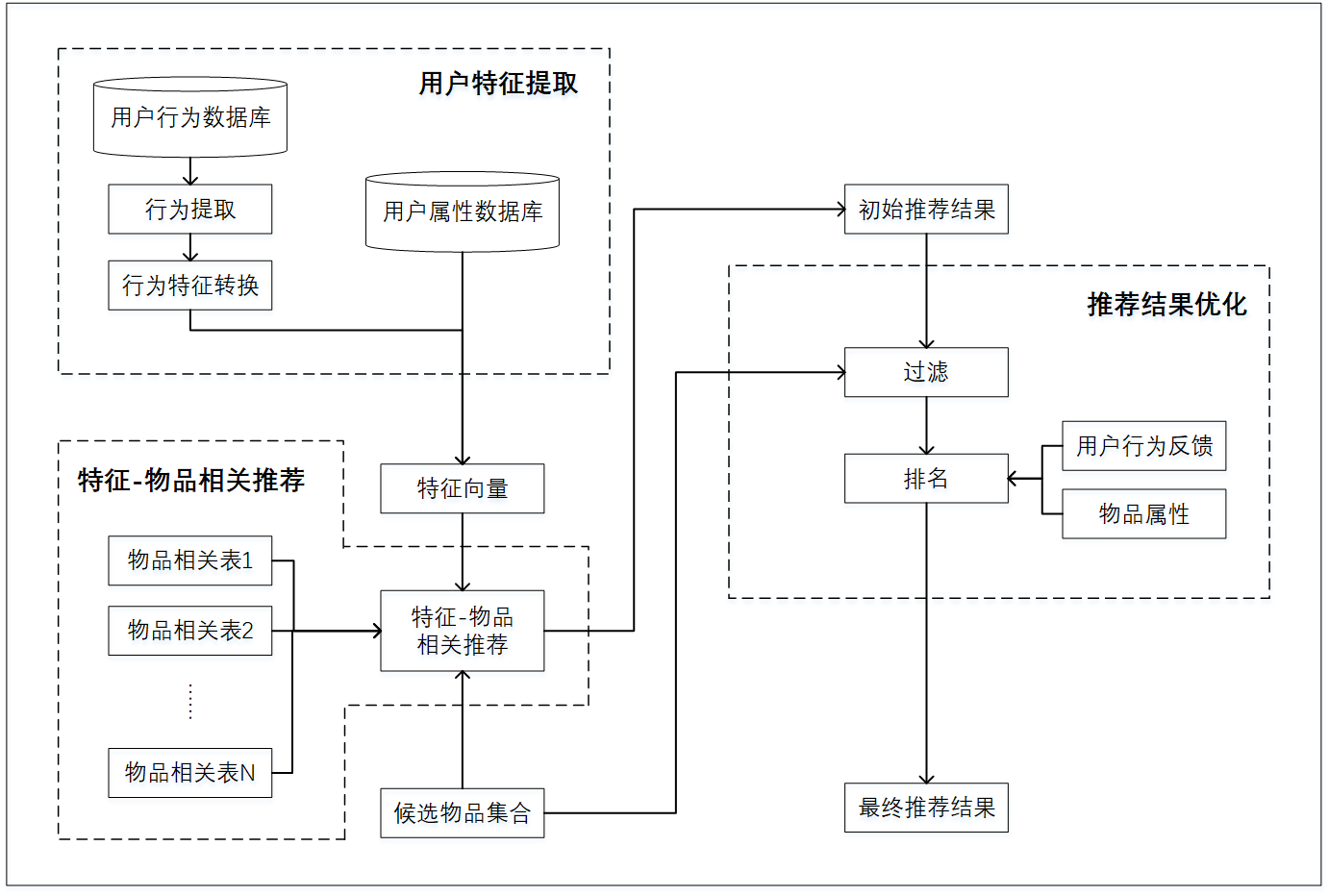
图1.1 本文主要工作路线图
1.4 论文的组织结构
根据上述研究内容,本文一共分为五个章节。每个部分的具体内容详细安排如下:
第1章:对推荐系统的研究背景及资源动态推荐算法的研究意义进行了阐述,并对国内外研究现状及推荐领域目前面临的主要问题进行了介绍。最后对本文中的主要研究内容与工作路线进行了阐述。
第2章:推荐系统相关技术综述。首先介绍了推荐系统的整体结构和实现推荐的典型流程。其次对基本的推荐算法进行了阐述,重点解释了协同过滤算法的原理和分类,并分析和比较了不同算法的优点和缺点。最后对SVD算法的原理进行了详细介绍。
第3章:算法的设计及实现。首先对公式中涉及到的主要数学符号进行定义和说明。然后对本研究中算法每个步骤的实现原理都进行了详细的介绍,并在此基础上提出了一定的改进。
第4章:实验评估。本章实现了第3章所提出的算法,通过与传统的算法ItemCF进行比较,表明了本文提出的算法在准确率、召回率和覆盖率的评估指标上取得了良好的效果,进而证明了算法的可行性。
第5章:总结与展望。这一章主要对本文主要的研究内容进行了归纳和总结,针对文中提出的资源动态推荐算法中的待改进之处进行了分析,并展望下一步工作。
第2章 推荐系统相关技术综述
2.1 推荐系统结构和推荐流程介绍
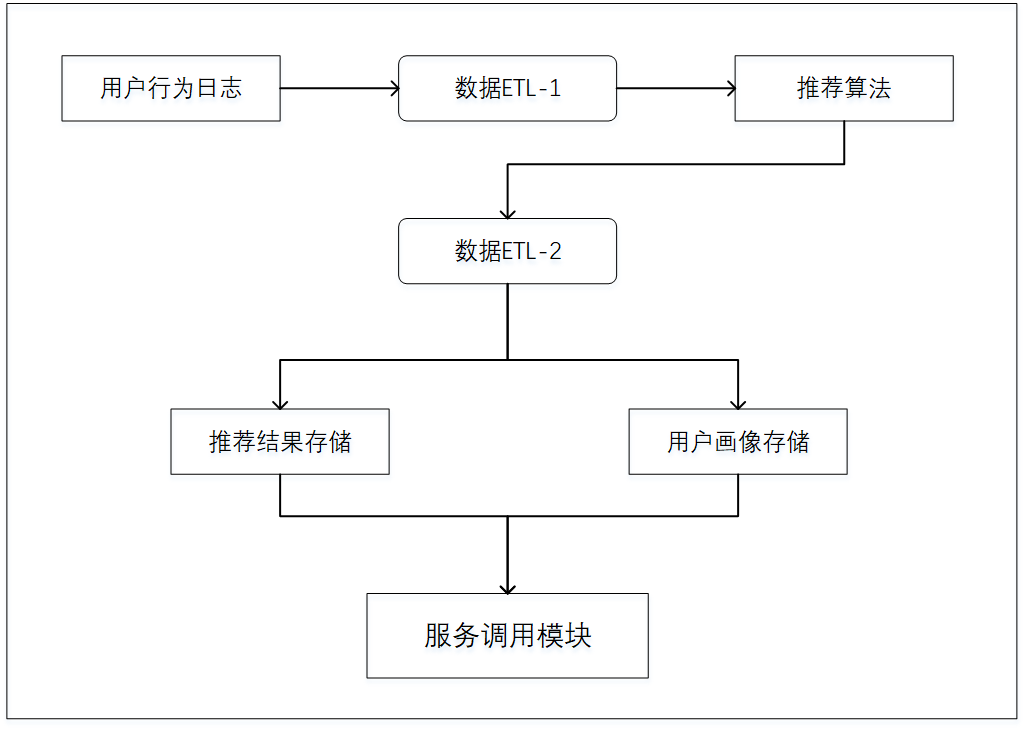
个性化推荐系统实现的重要基础之一是用户的行为数据,所以推荐系统在网站中通常以一个应用的形式而存在。如今,在互联网的各类网站中都可以看到推荐系统的应用,如社交网络、电子商务网站、个性化广告等。不同种类的网站中推荐系统的整体框架以及与网站中其他系统的接口是类似的,其外围架构主要分为3个模块:输入层(后台日志存储系统)、中间层(推荐算法系统)、输出层(UI系统),如图2.1所示:
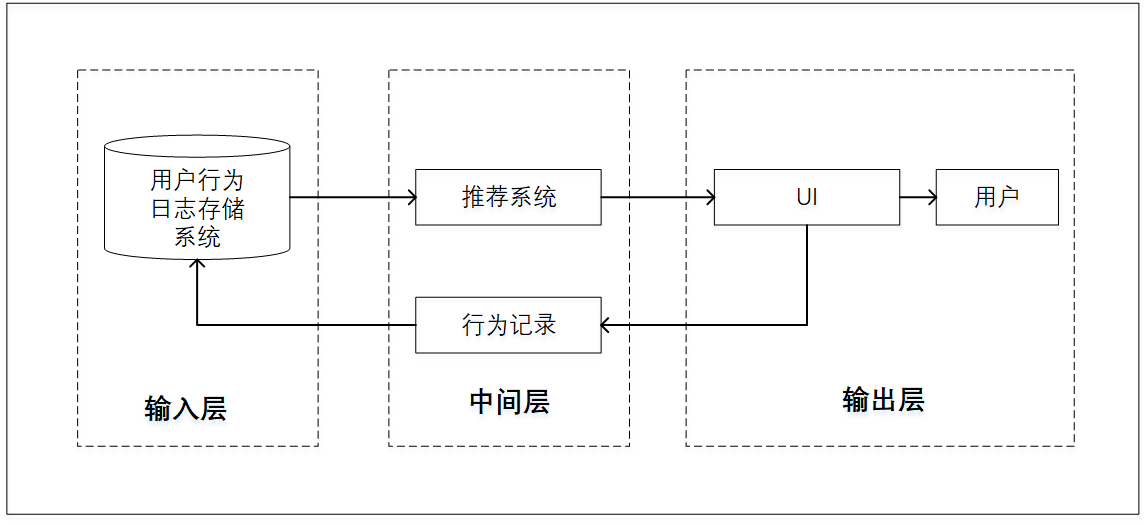
图2.1 推荐系统外围架构
个性化推荐系统在这些网站中的核心工作是分析用户在网站下产生的行为,发掘其偏好信息,据此对每个用户展示相应的个性化内容。优质的推荐能够帮助提高网站的点击率、转换率及盈利能力。网站中的UI系统作为用户与系统相连接的媒介,主要负责展示页面内容并与用户进行交互。在完成用户行为数据的收集后,该系统通过网络接口的调用将数据记录到日志,传送至服务器并进行存储,然后通过中间层的推荐算法对这些数据进行分析并建模。个性化推荐系统内部的典型流程如图2.2所示,其生成的推荐列表最终将在UI界面展示。
数据ETL-1:将日志数据转换为推荐算法所需要的格式,作为下一步算法的输入。主要针对原始的用户行为等数据进行过滤、加工,如字段的设置、数据的格式化等。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: