基于跨模态的图像检索方法研究毕业论文
2021-12-09 17:17:38
论文总字数:27000字
摘 要
随着计算机技术的发展,人们对图像检索的要求也越来越高,单一模态的图像检索方式已经不能满足人们日益增长的媒体检索需求,因此跨模态的图像检索方法应运而生。所谓模态就是指媒体数据类型,跨模态检索就是在不同数据类型的媒体数据之间实现数据搜索。本文主要采用了机器学习的方法,利用已有的数据集建立了一个图像和文本相互映射的模型。通过已经训练好的模型,我们可以对新输入的图像进行分类并打上对应的标签,之后,使用标签对现有文本进行同义词检索。相反,在文本检索图像时,本文先识别文本中的词组,又因为数据库中的图像都有着对应的标签,我们就可以利用词组和标签之间的匹配来达到跨模态检索的目的。本文涉及的方法的成功率受限于图像识别的准确度与同义词识别的效率,总体在使用的数据库中,简单数据检索效率达到了近86%。
关键词:跨模态;图像检索;机器学习;同义词;多分类;
Abstract
With the development of computer technology, people have higher and higher requirements for image retrieval. The single-modal retrieval method cannot meet the increasing needs, so the cross-modal image retrieval method came into being. The so-called membrane state refers to the media data type, and the cross-modal retrieval is to realize the data search among the media data of different data types. In this paper, machine learning is used to build a model of image and text mapping. Through the trained model, we can classify and label the new input image, and then use the tag to retrieve the synonyms of the existing text. Meanwhile, in the process of text retrieval, we first identify the phrases in the text, and because the images in the database have corresponding tags, we can use the relationship between phrases and tags to realize the cross-modal retrieval. The success rate of the methods involved in this paper is limited to the accuracy of image recognition and the efficiency of synonym recognition. In the overall database used, the efficiency of simple data retrieval has reached nearly 86%.
Key Words:cross-modal; image retrieval; machine learning; synonym; Multiclassification;
目 录
第一章 绪论 1
1.1 研究工作背景 1
1.2国内外研究现状 1
1.2.1 基于监督学习的跨模态信息检索方法 1
1.2.2 基于半监督学习的跨模态信息检索方法 3
1.2.3 基于无监督学习的跨模态信息检索方法 4
1.3 本文研究方法 5
1.4本文章节编排 6
第二章 相关研究 8
2.1 基于机器学习的图像识别 8
2.1.1 样本训练阶段 8
2.1.2 图像识别阶段 10
2.2 同义词识别 10
2.3 跨模态检索映射 11
2.3.1线性矩阵映射 11
2.3.2 哈希函数映射 12
2.3.2 神经网络关联映射 12
第三章 跨模态图像检索方法 14
3.1 图像识别 14
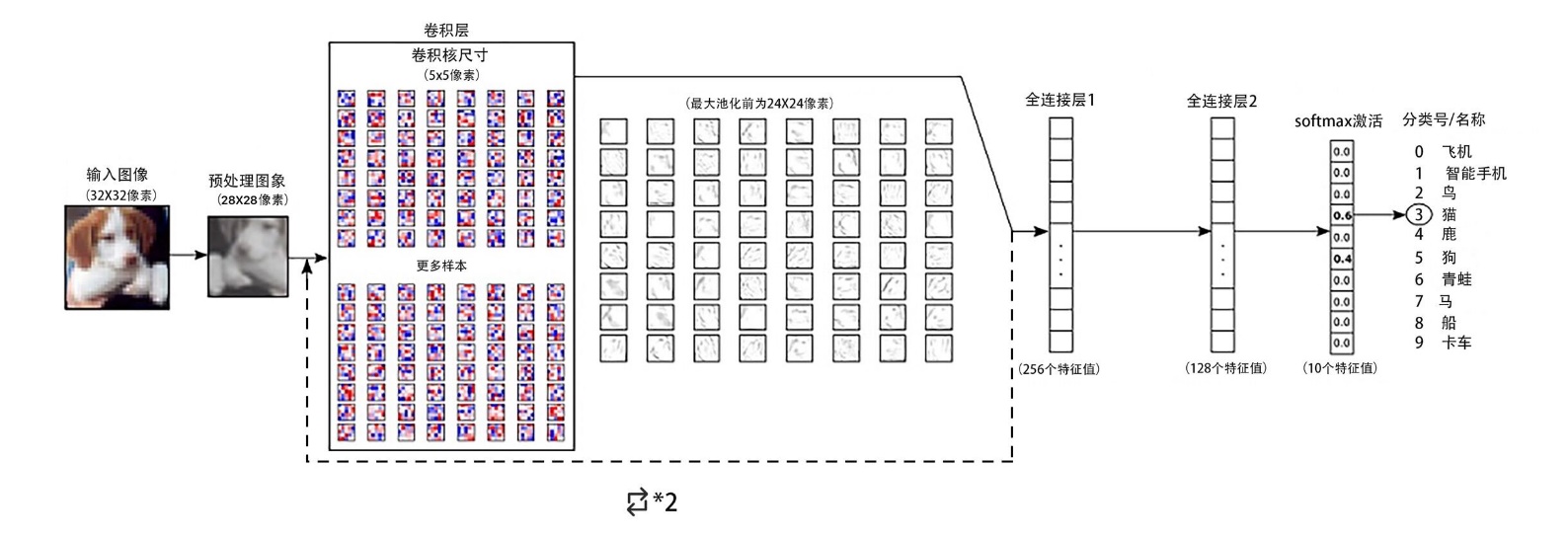
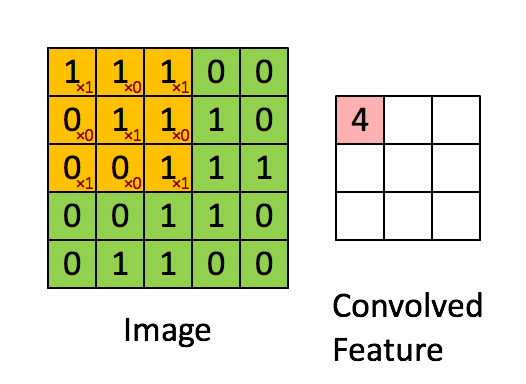
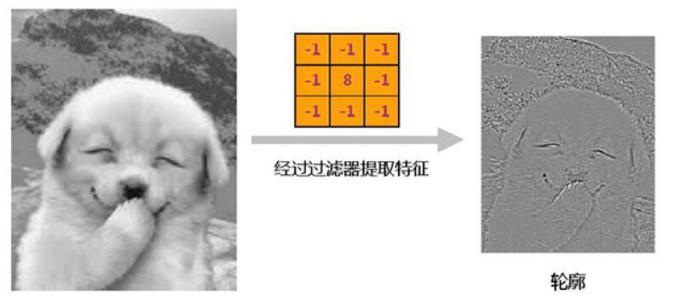
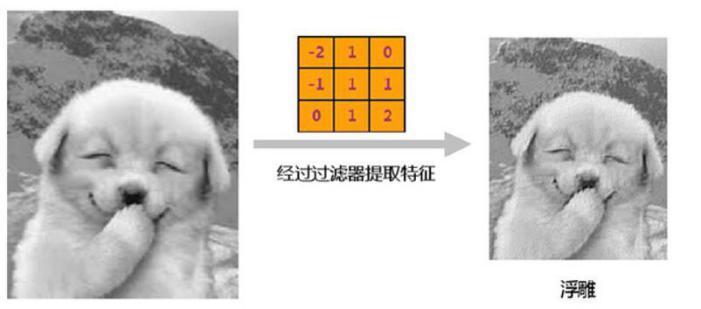
3.1.1 卷积层 14
3.1.2 池化层 16
3.1.3 全连接层 17
3.2 同义词识别 18
3.2.1 词组划分 18
3.2.2 同义词查找 18
3.3 相似度计算 19
第四章 实验 21
4.1 数据预处理 21
4.1.1 数据集介绍 21
4.1.2 图像预处理 21
4.2 图像识别实现 21
4.3 同义词判断实现 23
4.4 跨模态图像检索 23
4.5 实验结果 24
4.5.1评价标准 24
4.5.2 结果对比 24
第五章 总结 26
参考文献 27
致 谢 29
第一章 绪论
1.1 研究工作背景
如今我们已经迈入了信息大爆炸的时代,有数据显示仅仅是YouTube这一个视频分享网站,每分钟都会发布近300小时的视频[1];微博、Instagram、Flickr等社交网站上,全世界的人们每天都将发出数以亿计的各类图片;海量的文字信息每时每刻都在互联网上传播,如何提供有效的、多样的信息检索方法成了亟待解决的问题。传统的信息检索网站,如必应、谷歌、百度、搜狐等等,这些搜索网站的搜索引擎都是基于单模态的搜索方式。所谓单模态搜索,就是在检索目标信息时使用的是与目标信息相同类型的关键词,比如在搜索一张关于“桥”的图片时,我们只能在被命名为“桥”或者“桥”的同义词的图片中进行匹配,并根据相应的优先级输出搜索的结果,而不能做到直接对“桥”这一个字所对应的桥这一意象作出准确的识别与返回正确的结果,倘若一张关于桥的图片被命名为其它不相关的名字,单模态图像检索方法就不能返回正确的结果,这就是传统单模态搜索引擎的局限性。
具体关于多模态的研究可以追溯到1976年,科学家对人脑的研究发现,人脑对外界信息的处理并非是单一模态的,人脑在处理信息时往往需要在听觉、触觉、视觉等等多个维度中进行跨越与判断,这一研究表明人脑对于各类信息的理解是多模态的、综合的[2]。基于这一项发现,再加之人们日益增长的信息搜索需求,多模态图像检索的方法应运而生。而多模态检索方式实现了文字、图像、声音、视频、3D模型等不同媒体类型之间的相互搜索。传统方法一般是通过统计分析将不同的媒体数据投影到一个线性矩阵中,来做到不同数据间的相关性分析[3]。后来,受限于媒体识别技术,跨模态图像检索发展缓慢,但之后随着计算机技术的发展,机器学习在1986年重新走上历史的舞台[4],使得跨模态图像检索有了新的表达方式,即利用机器学习,得出不同媒体之间的关联程度,从而实现跨模态检索。
1.2国内外研究现状
国内外跨媒体检索的研究十分火热,也出现了非常多的技术种类与实现方法。跨模态图像检索的核心是实现跨模态数据的映射,本文就几种常见的实现方法作简单的介绍,以便横向对比研究。
1.2.1 基于监督学习的跨模态信息检索方法
由Hotelling等人提出的,典型相关分析[5]即CCA(Canonical Correlation Analysis)是基础的涉及跨模态信息处理及其相关性分析的理论算法。典型相关分析是研究两组变量相关关系的一种统计方法,其主要思想是针对两种不同的特征变量,首先对其主要成分进行降维,而后利用一个联合变量来综合表现这两种不同的特征变量,将原始的特征参数用联合变量来代替。这一类联合变量被称为典型变量(或典则变量)。在基于CCA的跨模态图像检索算法中,首先是对特征进行降维,将高纬度的主要特征变量压缩至一维线性向量,而后,通过求解这两个线性向量的相关系数,并以得到的结果做相关性分析。传统CCA算法为解决跨模态的信息处理提供了一些思路,但其仍有不小弊端。从对CCA算法的描述中不难看出,传统CCA算法局限于线性特征变量且其准确程度依赖于降维方法的选择与降维后计算出的相关系数之间相关性衡量的方法,这使得非线性问题无法通过CCA算法解决。
针对CCA算法的缺陷,Akaho等人提出了改进算法KCCA(Kernel Canonical Correlation Analysis),即核典型关联分析[6]。相较于CCA算法,KCCA算法引入了核函数的概念,将低维的数据映射到高维的特征空间(核函数空间),并通过核函数方便地在核函数空间进行关联分析。KCCA算法的优点就是将非线性因素代入到了跨模态数据映射的模型中,但其受限于其内核函数的固定,该算法的映射方式也随之受到限制,无法灵活改变。此外,由于KCCA算法是非参数方法,其训练时间与训练集大小关系不大,这导致该算法在较小的数据集中表现较差。
Galen Andrew等人针对KCCA的缺点进一步对跨模态数据映射、检索算法进行改进,他们提出了DCCA(Deep Canonical Correlation Analysis),即深度典型相关分析[7]。“深度”网络具有两层以上的结构,能够表示非线性函数,因此DCCA算法能够轻松解决CCA算法的主要矛盾,此外这些函数涉及多层嵌套的高层抽象,这类抽象可能是精确建模复杂的真实数据所必需的。虽然深度学习网络通常用于学习分类标签或映射到另一个有监督的向量空间,但在DCCA中,其被用来学习两个数据集到一个数据高度相关的空间的非线性转换,而深度学习算法利用参数对映射函数进行模拟,其时间复杂度与参数数量与样本数量正相关,良好的解决了小样本情况下KCCA算法表现较差的问题。DCCA的主要问题是,该方法仅考虑了两种模态数据间的映射,而没有考虑到多种数据的交互。
北京大学计算机科学与技术研究院的彭宇新教授课题组提出了跨媒体深层细粒度关联学习方法[8]。该方法将图像、文本、音频等的媒体数据投入到通过机器学习算法训练好的模型中,并利用损失函数来突出不同媒体的语义特征,强调不同媒体的语义特性,并在一个同一空间中将不同媒体类型的数据约束至其语义中心。通过这种方法可以减小不同媒体之间表意方式的不同,从而达到相似性判断的目的。最后,使用一个函数将不同表现形式的同一语义映射在一起,以此将表达同一语义的各个媒体链接在语义空间中,在出现某一模态的关键词时就可以查找到其他模态的媒体信息了。该方法增加了多种媒体跨模态检索的应对方案,当增加新的模态的媒体信息时,就只需要训练针对新的模态的机器学习模型即可,在成功训练完毕后,只需要将其结果同样映射到语义空间中对应的语义就可以完成新模态跨模态检索的实现。
另外,还有基于潜语义主题加强的跨媒体检索算法[9],该方法与KCCA算法类似,但其为实现跨模态信息检索时不同模态之间相似度计算提供了新的思路。该算法先通过多分类机器学习模型划分出不同类别的图像与文本,然后利用分类模型计算图像和文本基于多分类的后验概率,之后利用皮尔逊相关系数计算不同类别图像与文本之间的相关程度,最终根据计算出的相关程度得出检索结果。
1.2.2 基于半监督学习的跨模态信息检索方法
半监督学习方法与监督学习的方法最主要的不同是半监督学习使用的数据,一部分是标记过的,而大部分是没有标记的。和监督学习相比较,因为半监督学习只需要人为得打上部分标签即可进行,无需给每个样本都人为给出正确答案,因此半监督学习的成本较低,但是又能达到较高的准确度。半监督学习综合利用有类标的和没有类标的数据,来生成合适的分类函数。而基于半监督学习的跨模态信息检索则相对于1.2.1中有监督的跨模态图像检索而言其成本更低,但同时带来的是相对较低的识别准确度。
首先Matthieu Guillaumin等人在KCCA的基础上修改了机器学习部分,使其能够在半监督学习中有效工作。他们提出了一种半监督学习方法[10],以两步的过程来利用标签中包含的信息与未标记的图像。首先,他们使用标记的图像来学习一个多分类器,它使用图像内容和标签作为特征。他们使用多内核学习(MKL)框架将基于图像内容的内核与编码与每个图像关联的标记的第二个内核结合起来。该MKL分类器用于预测未标记训练图像的标签与相关标签。在第二步中,该方法使用标记数据和分类器对未标记数据的输出来学习第二个仅使用视觉特征作为输入的分类器。该方法与大多数半监督学习的工作不同,因为该方法中标记和未标记数据具有测试数据所没有的额外特征,即实现了跨模态媒体特征训练的部分,以实现跨模态媒体关联信息的计算。
请支付后下载全文,论文总字数:27000字
相关图片展示: