基于分布式的可拔插计算调度框架的设计和实现毕业论文
2020-02-23 18:19:17
摘 要
计算机网络技术的迅速发展给人们的生活提供方便快捷和个性化服务的同时,用户每天也产生了大量的数据。在面对用户提交的海量数据,单个服务器计算节点的计算能力与可靠性很难得到保障,而对于用户来说短时间或低频率的宕机都是难以容忍的,企业必须及时对用户请求做出响应。在面对大量的计算集群的时候如何合理的分配资源、分发任务,保证整个系统的高效稳定运行是很多公司或者用户亟待解决的问题,在这样的场景下分布式计算系统的研究与设计就得到了广泛的关注。
本文设计了一种分布式计算调度框架,它拥有轻量级、可拔插、可配置、可移植、可扩展等特点。采用主从结构,中心节点负责系统的调度与任务的分发工作,任务节点对任务进行计算并把结果反馈给中心节点。采用ZooKeeper技术进行服务注册与发现,使用Netty框架开发网络底层通信协议,对于二进制数据进行了序列化与反序列化的处理,同时使用远程过程调用保证对从节点的任务调用。
本文的难点在于结合优先级、定时任务、上传时间等多方面制定动态任务分配算法,中心节点根据动态分配算法将任务分发到任务节点。使用心跳检测机制中心节点可以实时的获取服务节点的运行状态,确保当任务节点出现单点故障时能够及时的进行任务重传保证系统具有容错性。
关键词:分布式;远程过程调用;任务调度
Abstract
With the rapid development of computer network technology, people's lives are provided with convenient and personalized services. At the same time, users also generate a large amount of data every day. In the face of massive data submitted by users, the computing power and reliability of a single server computing node can hardly be guaranteed. For users, short-term or low-frequency downtime is hard to tolerate. Enterprises must handle these in a timely and accurate manner. Data and feedback to the user. When faced with a large number of computing clusters, how to reasonably allocate resources and distribute tasks to ensure the efficient and stable operation of the entire system is a problem that many companies or users need to solve urgently. In such a scenario, the research and design of distributed computing systems are obtained. A wide range of concerns.
This paper designs a distributed computing scheduling framework that is lightweight, pluggable, configurable, portable, and extensible. With the master-slave structure, the central node is responsible for the system's scheduling and task distribution. The task node calculates the tasks and feeds the results back to the central node. ZooKeeper technology is used for service registration and discovery. The Netty framework is used to develop the underlying network communication protocol. Serial data is serialized and deserialized. At the same time, remote procedure calls are used to ensure that the slave node is called.
The difficulty of this paper is to formulate a dynamic task assignment algorithm based on priority, timed tasks, and upload time. The central node distributes the task to the task node according to the dynamic allocation algorithm. Using the heartbeat detection mechanism, the central node can obtain the operational status of the service node in real time to ensure that the task retransmission can be performed in a timely manner when the task node has a single point of failure to ensure fault tolerance of the system.
Key Words:Distributed; Remote Procedure Call; Task Scheduling
目 录
第1章 绪论 1
1.1研究背景 1
1.2 分布式计算机软件架构发展现状 1
1.3 研究目的及意义 3
1.4 课题研究内容 3
第2章 核心开发技术相关知识 5
2.1 Netty框架 5
2.2 远程过程调用技术 5
2.3 ZooKeeper架构 6
2.4 Quartz任务调度框架 7
第3章 轻量级分布式计算调度框架的设计 8
3.1 系统设计目标 8
3.2 系统设计思路 9
3.3 体系结构与功能模块 10
3.4 工作机制与处理流程 10
第4章 任务调度系统主要技术及实现 12
4.1 系统底层通信设计 12
4.1.1 中心节点与任务节点的通信协议 12
4.1.2 中心节点与客户端的通信协议 14
4.2 任务分配及任务节点管理 14
4.3 任务接口及其执行过程 16
4.4 容错机制 16
第5章 系统测试与分析 18
5.1 测试环境 18
5.2 功能测试 18
5.3 性能测试 21
5.3 任务调度算法测试 21
第6章 总结与展望 23
致谢 24
参考文献 25
绪论
本章主要从研究背景、研究目的、研究意义、国内外研究现状、课题研究内容及预期目标几个方面进行相关的阐述。
1.1研究背景
随着现代网络技术的高速发展,人们的生活方式也不断改变。人们在享受互联网技术带来的便捷和个性化服务的同时,也面临着数据的大爆炸。自从计算机网络诞生之日起,客户端/服务器或浏览器/服务器的系统模式得到了所有人的认可,集中式计算的架构在当时的网络计算水平下能够较好的为用户提供服务。用户对网络带宽的需求逐渐变大,我们的主流媒体也从文字过渡到图片,并逐渐向音频、视频等流媒体形式发展。在这样的背景下,新的网络应用形式带来的信息传输量呈现了指数型增长,与此相对应的服务器硬件水平与网络带宽都在一定程度上遇到了发展的瓶颈,这种情况下对于分布式计算架构的需求就显的越发明显。多客户端共享一个或多个计算机集群可以使大量的作业共享软硬件资源,并且相互之间不存在干扰。为了缩短响应时间,很多分布式系统都采用了并行计算的技术,需要多个节点或者虚拟主机搭建分布式计算集群[1]。分布式系统的存在是有效避免单点故障所造成的灾害,它是保证服务可用性的一个有效手段。分布式系统的开发过程中,良好的系统架构设计是重中之重,一个合理的计算调度算法可以解决不同作业的服务质量、优先级等问题。凭借合理的算法机制,我们可以根据作业的工作量、完成率、完成效率等各种信息,动态的计算出资源分配和作业调度方案来满足系统的性能需求。
系统架构设计是分布式计算调度框架的设计核心,它可以清晰明了的将分布式系统运行过程中各个组件之间的相互通信结构进行阐述,尤其是面对复杂的大型的分布式系统时,一个良好的架构设计是软件开发的基础。随着功能的增加与服务器负载的增加,组织结构复杂程度将会呈指数型上升[2]。运用自顶向下的模块化原则,将功能划分并分别分配到不同的分布式集群中,每台或每几台服务器按照相同的软件架构组合在一起,模块的划分能够降低集中式处理产生的单点负载压力,提高服务的稳定性。当前业界主流的客户端/服务器架构、浏览器/服务器架构随着服务量和访问量的提升分布式系统是其保证服务可靠性的唯一技术手段,因此分布式系统的研究对于提高软件设计的稳定性、可移植性和可扩展性具有重要的意义。
1.2 分布式计算机软件架构发展现状
伯克利开放式网络计算平台[3](Berkeley Open Infrastructure for Network Computing)是目前主流的分布式计算平台之一,它由加州大学伯克利分校计算机学院发展而来。这个分布式系统的最初设计是为了汇集全球各地志愿者的智能终端设备,无论是电脑或是移动终端,将其空闲时的运算能力提供给研究者。它原本是为了SETI@home[4]项目而设计,随着后期的发展逐渐加入了数学、医学、天文学和气象学等方向的研究。在志愿者的电脑进入屏幕保护程序时,BOINC会自动使用CPU或GPU进行科学运算,如果电脑正在使用,它会自动利用空闲的CPU周期来进行运算,而且由于科学并行计算的特点,如果志愿者的电脑上装有NVIDIA、ATI或Intel的GPU并选择使用其作为运算硬件,运算速度会比单纯的CPU设备提升数倍。项目服务器负责协调各个志愿者电脑的运算资源,单次运算的结果并不会被服务器信任,服务器会将相同的工作任务发给多台志愿者设备上进行运算,如果结果匹配一致才会成为研究人员看到的结果,这样保证了数据的可靠性,防止恶意攻击行为。BOINC分布式计算平台的存在对于计算机网络的发展具有开创性的意义[5],它不仅仅为分布式计算系统的发展提供了借鉴意义,同时其运算结果对于科学的发展与进步有更大的意义,它的存在为基础科学的发展起到了推动作用。
Hadoop[6]是开源分布式计算框架的优秀代表,Hadoop的灵感来源于Google发表的两篇论文,第一篇发表于 2003 年,其主要内容为谷歌的分布式系统(GFS)[7],描述了关于Google对搜索网页数据设计的存储架构,基于此存储架构的灵感,Hadoop 开发出了分布式文件系统(HDFS)[8]。在2004年,Google又发布了一篇关于 MapReduce计算框架[9]的论文,Hadoop也实现在框架中。它们分别代表了数据在分布式条件下的存储与运算功能,它们的提出为解决分布式问题提供了一个全新的思路。Hadoop能够使用多台计算机组成的计算网络来解决海量数据的存储与计算问题,用户不再需要专门购买设备,利用传统的商用硬件就可以轻松构建计算集群。由于在设计之初就考虑到了分布式条件下的硬件故障和网络故障,所以框架对于这部分棘手的问题都能自动处理,提高系统服务的可靠性与稳定性。HDFS中最重要的是冗余备份,对于文件副本的持久化处理是保证在发生硬件单点故障时能够即时恢复的关键,MapReduce中的Map和Reduce分别对应映射和规约,在映射任务中把一组键值对映射成一组新的键值对,发送给一个指定的规约任务,在规约任务中计算出最终结果。在Hadoop框架的基础之上,又有像Spark[10]这类优秀的框架涌现,分别在不同的计算领域有着不同的应用场景。
Dubbo[11]是阿里巴巴的开源高性能分布式计算框架。它是基于SOA 服务的治理解决方案的核心框架。典型如电商平台。其主要内容包括远程通信,集群容错和自动发现三个方面。同时,Dubbo还可以与Spring框架[12]无缝集成,即Dubbo采用了Spring依赖注入方式,透明化地接入应用,没有任何的API侵入,只需要通过Spring加载相关的配置。随着框架的不断进步,已经取得了较好的工业应用,比如阿里的电商平台有2000多个对内对外服务,通过Dubbo分布式计算平台,能够完成大于30亿次的巨量的在线交易。
支持大量数据处理作业的编程模型需要一个集群高效、可靠的运行,通常还需要多个任务并发执行。尤其是像Hadoop这样的技术的提出,对分布式计算产生了重要意义,其中每个分支框架都是特定场景下的分布式软件应用,本文在研究学习Hadoop、Dubbo的同时开发了一个轻量级的分布式框架,旨在一定程度上解决中小型公司在分布式系统框架开发中遇到的问题。
1.3 研究目的及意义
面对复杂的业务逻辑,如果将分布式系统直接与逻辑结合在一起,就会出现低内聚高耦合的情况[13],这是违背软件开发设计原则的,而且当个别业务修改的时候需要对整个服务进行重启也会使得其它业务受到影响。一个独立的分布式计算调度框架就可以通过框架的部署以及按照框架的模板进行业务的开发,保证各个业务之间的相互独立型,特定业务的修改不影响整个系统功能。
本次对分布式系统的调度算法所进行的研究就是希望能够提供一种合理的方法来对计算资源进行合理分配和监管,通过对系统的配置与服务接口的代码编辑,用户可以快速的完成对于分布式资源的合理利用,同时进行即时的系统资源管理以保证系统的稳定运行,减少对运维人员的依赖,以期实现系统的自动化处理流程。
1.4 课题研究内容
基于分布式的可拔插计算调度框架,主要需要实现一个灵活的、动态的、可拔插的任务解析器和一个针对用户透明的分布式计算调度框架。能够很好的动态解析用户提交的复杂计算任务,同时,为用户提供良好的编程接口,确保可移植性和可扩展性。
分布式任务计算调度框架的设计与实现主要有以下五个方面的工作:
- 系统各模块之间的相互通信。通信速度与可靠性是对于分布式系统传输速率最重要的一环,本系统采用Netty技术定制了各模块之间的通信协议,通过序列化、反序列化方法保证可靠性。
- 对任务节点资源的合理分配与任务分发。设计合理的动态任务分配算法将任务按照优先级、定时器、上传时间等因素进行排序。针对具体任务,本文会记录任务节点的运行状态,将可用的任务节点自动调配实现负载均衡。
- 任务计算结果的可靠性。系统在获取到客户端上传的任务之后,如何确保任务节点计算结果的可靠性也是值得深入探究的内容。本文通过 Java 反射机制和RPC远程过程调用,使得任务节点将通过中心节点暴露出来的服务接口进行调用,保证计算的准确性。
- 加入了定时任务处理机制。系统在获取到客户端上传的任务的时候,允许用户提交一个基于quartz定时任务框架的触发器,当满足条件的时候,服务器会根据相应的任务内容执行任务。
- 可拔插的配置服务接口。框架在完成之后,用户不需要了解框架具体的细节实现,只需要按照系统提供的服务接口进行扩展,可以轻松的进行服务的增减,降低框架与系统的耦合程度。
第2章 核心开发技术相关知识
本章主要对开发过程中用到的技术进行详细系统的介绍。
2.1 Netty框架
Netty[14]是一款基于Java的网络应用框架,相较于传统的Apache服务器它的主要特点是异步事件驱动,常用于高性能协议网络服务的开发。因为它极大地简化了TCP和UDP套接字服务器等网络编程,所以也经常用于开发Java网络应用程序的非阻塞I/O客户端-服务器框架。Netty包含了编程的反应器模式的实现,除了是一个异步事件驱动的网络框架之外,还内置了HTTP,HTTP2,DNS,WebSockets和更多协议的支持,允许在servlet容器内运行,并与Google Protocol Buffers[15]集成,支持SSL / TLS。在本文的设计中采用Netty作为底层通信协议框架,将自定义的协议通过Netty进行传输,保证了传输效率和稳定性,同时异步通信的设计模式也使得服务器负载能够大大降低,降低了中心节点的服务器压力。
2.2 远程过程调用技术
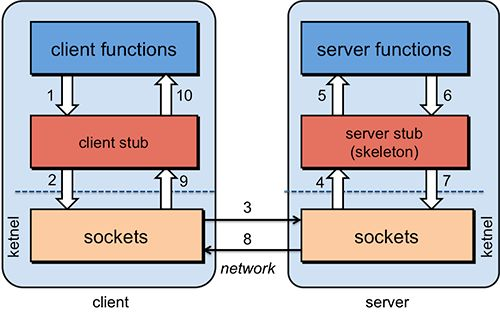
在分布式计算中,远程过程调用[16](Remote Procedure Call)是指通过该协议一台计算机能够向客户计算机发送一个请求,服务器接收到请求之后进行计算并将运算结果反馈给客户端。在这个过程中程序员可以直接在客户计算机调用远程服务器的服务接口,而不用管服务器的具体实现就可以直接获得结果。这是客户端/服务器交互的一种形式(调用者是客户端,执行者是服务器),通常通过请求-响应消息传递系统来实现。在面向对象的编程范例中,远程过程调用由远程方法调用(RMI)表示。 远程过程调用意味着一定程度的位置透明性,它是进程间通信的一种形式。不同的进程具有不同的地址空间,如果在同一主机上,即使物理地址空间相同,它们也具有不同的虚拟地址空间。而如果它们位于不同的主机上,则物理地址空间不同。在本文的设计中,远程过程调用技术,是保证中心节点能够准确控制任务情况的保证。通过底层通信协议传输的任务协议,将中心节点中存储的的Stub与服务节点中存储的Skeleton结合在一起,使得两者之间相互绑定。
远程过程调用的实现中,如图2.1所示主要有以下几个层次:
- 确定底层Socket通信机制,在客户端与服务器之间使用Netty框架开发的异步事件驱动的通信协议。使用按需连接的方式建立TCP连接,传输二进制数据,即时释放计算资源;
- 解决寻址问题,使用ZooKeeper作为注册中心,所有的节点在启动时将会创建一个临时节点保存服务器IP地址和端口号,这样保证了分布式条件下的服务器地址动态配置问题;
- 在客户端与服务器之间分别创建一个代理,代理是服务器或客户端虚拟机中的一个对象,在客户端中代理被称为Stub在服务器中代理称为Skeleton,他们负责利用网络协议进行相互的通信。因为设计的网络通信协议是二进制的,所以我们要实现对数据的序列化与反序列化。在一方将数据序列化后通过网络协议发送给另一方再将数据反序列化恢复为内存中的表达形式;
- 客户端程序只需要进行常规的方法调用,像是服务的具体实现都在本地,这正是系统设计希望提供给开发者的,开发者无需掌握底层的设计只需要按照框架的设计进行调用即可获得预期的效果。