知识图谱构建技术研究毕业论文
2020-02-23 18:20:59
摘 要
随着大数据时代的到来,数据成为了驱动应用开发的一个动力,如何有效的将以前的大量数据进行组织利用起来,如何将Web上的大量非结构化信息利用起来,成了一个研究的热点问题。知识图谱就是上述问题的一个解决方法,它将知识表示成一个图结构的数据,图的节点就是实体,节点之间的边就是实体之间的语义关系,图节点还保存有实体的属性信息。在人工智能时代,知识图谱是人工智能领域的一项底层技术,像人的大脑一样存储“知识”,基于知识图谱,我们可以做语义搜索,挖掘一些隐含的知识。
现有的大规模知识图谱都是大规模通用领域的知识图谱,司法领域的知识图谱的构建还处于初步阶段。本文先研究了知识图谱构建的相关技术,然后将一些比较成熟的知识图谱构建的技术方法应用到司法领域,构建一个司法领域的知识图谱。
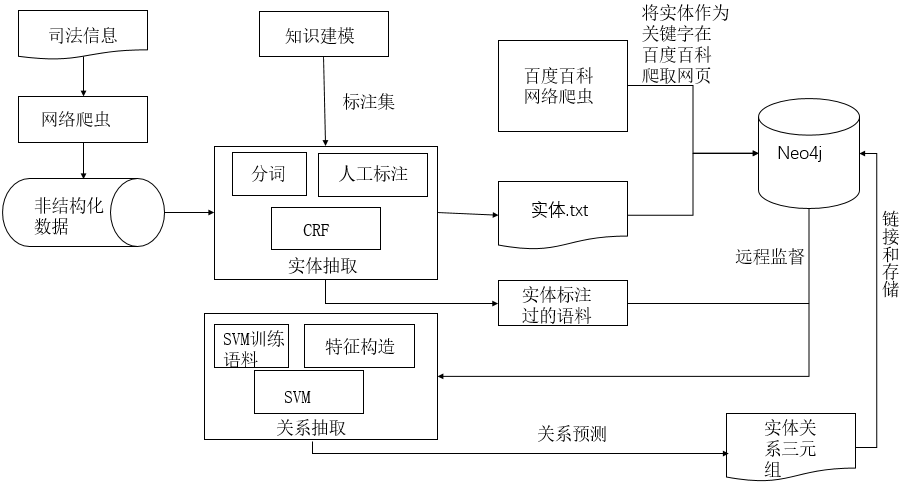
本文所选取的数据源是半结构化数据和非结构化数据,在实体抽取阶段,本文使用了CRF算法来识别司法领域的实体,实体抽取实验的一些评价指标如精确率和召回率都很高。在关系抽取阶段使用的是基于远程监督和支持向量机的方法,此方法省去了人力标注的时间,选取一些词法特征和句法特征进行分类,抽取效果和效率都很好。对于知识存储,本文使用开源的图数据库Neo4j来存储抽取的实体、属性和实体之间的语义关系。
关键词:知识图谱;实体抽取;关系抽取;司法;远程监督
Abstract
With the advent of the era of big data, data has become a driving force for the development of applications. How to effectively use the large amount of data in the past and how to use a large amount of unstructured information on the Web has become a research hotspot problem. The knowledge graph is a solution to the above problems. It represents knowledge as the data of a graph structure. The nodes of the graph are entities, the edges between nodes are the semantic relationships between entities, and the graph nodes also store the attribute information of entities. In the age of artificial intelligence, knowledge graphs are a low-level technology in the artificial intelligence field. They store “knowledge” like human brains. Based on the knowledge graphs, we can do semantic search and discover some hidden knowledge.
The existing large-scale knowledge graphs are knowledge graphs in a large-scale general domain. The construction of the knowledge graph in the judicial field is still at a preliminary stage. This thesis first studies the related technologies of knowledge graph construction, and then applies some more mature technology methods of knowledge graph construction to the judicial field to construct a knowledge graph of the judicial domain.
The data sources selected in this thesis are semi-structured data and unstructured data. In the entity extraction stage, this thesis uses the CRF algorithm to identify the entities in the judicial field. The entity extracts some evaluation indicators of the experiment, such as high accuracy and recall rate. In the relation extraction phase, the method based on distant supervision and support vector machine is used. This method saves the time of human annotation, selects some morphological features and syntax features for classification, and has good extraction efficiency and efficiency. For knowledge storage, this thesis uses the open source graph database Neo4j to store the extracted semantic relationships between entities, attributes, and entities.
Key Words: Knowledge Graph; Entity extraction; Relationship extraction; Judicial; Distant supervision
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 研究现状 2
1.3 本文研究目标及内容 3
1.4 论文结构 4
第2章 知识图谱构建技术 5
2.1 知识图谱 5
2.1.1 知识图谱定义 5
2.1.2 知识图谱构建的流程 5
2.2 实体抽取的方法研究 7
2.2.1 基于规则的实体抽取 7
2.2.2 基于统计机器学习方法的实体抽取 8
2.2.3 基于深度学习的实体抽取 8
2.2.4 实体抽取的方法比较 8
2.3 关系抽取 9
2.4 知识存储 10
2.5 条件随机场算法概述 11
2.6 远程监督算法概述 13
2.7 支持向量机算法概述 13
第3章 司法知识图谱构建概览 16
3.1 整体流程与算法步骤 16
3.2 开发环境介绍 17
第4章 司法知识图谱构建实现 18
4.1 知识建模 18
4.2 数据获取 19
4.3 基于CRF的实体抽取 20
4.3.1 使用CRF进行司法方面的实体抽取 21
4.3.2 实验 24
4.3.3 实体抽取结果 25
4.4 基于远程监督 SVM的关系抽取 26
4.5 知识存储 32
第5章 结束语 37
5.1 论文工作总结 37
5.2 问题与展望 37
参考文献 39
致 谢 41
第1章 绪论
1.1 研究背景与意义
随着互联网时代的发展,各行各业的以及Web上的数据信息成指数级增长,人们可以在互联网上获得很多信息,但是在Web上的信息大都是半结构化和非结构化的数据,通过构建通用领域和行业领域的知识图谱可以有效的将行业数据和Web数据组织起来,然后基于知识图谱可以开发各类智能应用。
人类社会已经进入智能化时代。各行各业纷纷踏上智能化升级与转型的道路,各类智能化应用需求大量涌现。这些智能化应用需求对于机器认知水平提出了全新要求。实现机器认知智能的关键技术之一是知识库技术。知识图谱作为大数据时代的重要的知识表示方式之一,为机器语言认知提供了丰富的背景知识,使得机器语言认知成为可能,因而也成为了行业智能化转型道路上的关键技术之一。
知识图谱概念于2012年由Google提出,用于其改善自己的搜索引擎,之后国内外各大搜索引擎公司纷纷推出了自家的知识图谱产品。所以,知识图谱作为AI领域的一项底层技术是越来越火了,被提及到的频率也远高于以前。
对于各个行业,利用自家企业的数据就可构建一个知识图谱,基于知识图谱可以开发很多智能应用,比如智能问答、语义搜索、深层关系推理。在司法领域涉及法律法规、司法流程、司法解释、参考文献、典型案例、裁判文书、审判业务信息系统等大量非结构化信息,使用知识图谱技术有机高效的处理和整合这些数据,构建司法领域的知识图谱,可以为司法体系的各类业务高效和准确处理提供有利支撑。构建司法领域的知识图谱是司法智能应用的必然路径。近年来,知识图谱在司法领域的运用悄然兴起,帮助从业人员快速地在线检索相关的法务内容,提高法院审判工作质量和效率。
所以本文在这样的背景下对知识图谱的构建技术进行研究,然后将知识图谱构建过程中一些比较成熟的技术应用到司法领域来构建一个司法知识图谱。
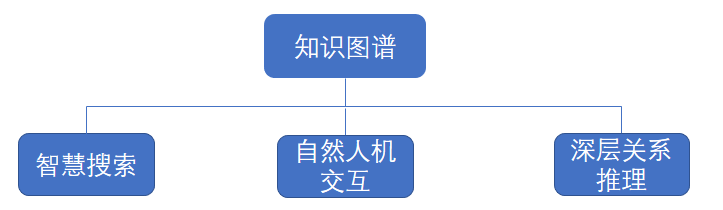 对于知识图谱的应用可以列举如下:
对于知识图谱的应用可以列举如下:
图1.1 知识图谱的几个应用
对于智慧搜索,国内搜狗公司已经推出了“搜狗立知”知识图谱产品来改善其搜索引擎,比如在搜狗搜索引擎下查询“姚明的身高”,直接以一个知识卡片的形式返回给用户。如图1.2所示。以前的搜索引擎搜索问题时是对于用户输入的关键词进行关键词匹配,返回一系列包含该关键字的网页并排序。现在搜狗搜索引擎已经实现了基于语义的搜索,背后的强大支撑就是知识图谱技术,首先将“姚明的身高”识别为“姚明”实体并映射到知识图谱上并查询姚明的身高属性并返回给用户。搜索引擎理解了用户查询目的并返回了更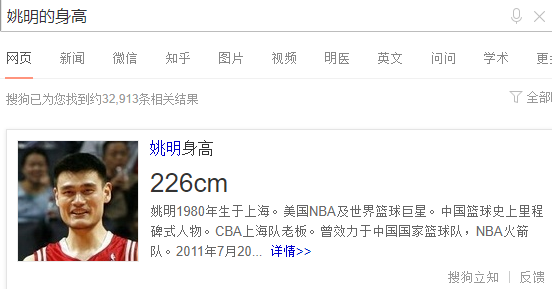 加精确的结果。
加精确的结果。
图1.2 用搜狗立知搜索“姚明的身高”的结果
对于自然人机交互,比如现在各个移动端的移动个人助手,它的实现主要就是语音合成技术、自然语言处理技术加上背后强大的知识图谱,有了知识图谱这个强大的“大脑”,就有了机器认知的基础。
对于深层关系推理方面。在王宝强离婚的时候,就有人想知道为什么王宝强找张起准当律师。如果用人物关系图谱分析的话,就会发现王宝强与冯小刚是好朋友,冯小刚经常徐静蕾和赵薇这两个演员进行合作,她们的法律顾问就是张起准。这样的关系链路分析可以挖掘出王宝强与张起准之间的深层次关联。也就可以解释这个问题了。
所以学习知识图谱构建的相关技术,并将其应用到司法领域,是一项非常有意义的工作。它可以让一些零散、非结构化的司法数据得以利用起来,将这些数据构建成知识图谱,然后基于知识图谱我们可以开发一些查询应用或者一些智能问答应用,可以帮助普通群众来获得法律方面的信息或知识。
1.2 研究现状
知识图谱(Knowledge Graph)这一概念由Google公司提出,Google将知识图谱技术应用到自己的搜索引擎上,用于改善Google搜索所返回的结果。Google高级副总裁Amit Singal博士认为”The world is not made of strings,but made of things”,意思是世界是由实体组成,而不是字符串。这是相对于以前的搜索引擎是基于字符串关键字匹配的查询,现在更加智能化的搜索引擎则是以知识图谱为基础,将搜索的自然语言中的实体链接到知识库中进行查询。
自从Google提出知识图谱之后,国内外纷纷效仿Google推出自己的知识图谱产品。
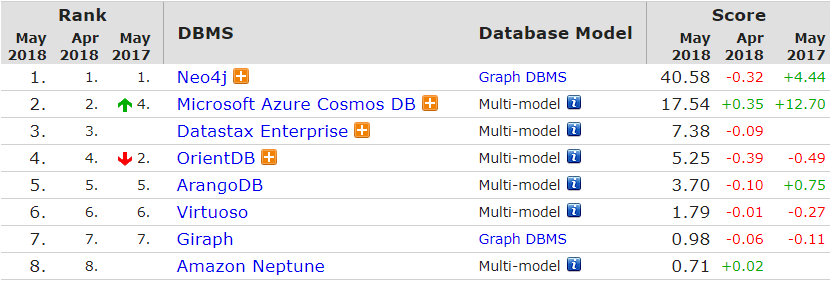
在国外,已经有一些大规模通用领域的知识图谱被构建,比如,Google Knowledge Graph、Freebase、DBpedia等,如下表所示,它们的实体数量已经达到了百万级别,关系数量已经达到了千万级别。如表1.1所示:
表1.1 国外几种大规模通用领域的知识图谱大小数据
知识图谱 | 大小 | ||
实体 | 关系类型 | 三元组 | |
Freebase | 40M | 35000 | 637M |
Wikidata | 18M | 1632 | 66M |
DBpedia | 4.6M | 1367 | 538M |
YAGO2 | 9.8M | 114 | 447M |
Google Knowledge Graph | 570M | 35000 | 18000M |
在国内,知识图谱方面也取得了一些不错的成果。工业界比如一些搜索引擎公司继Google之后也在自家的搜索引擎后面添加了知识图谱的支撑,比如前面说到的“搜狗立知”,百度推出的“知心”,用以优化搜索引擎。在学术界,复旦大学知识工场研究团队专注于各类大规模知识图谱构建、管理以及应用理论与方法研究,目前,知识工场已经发布了CN-DBpedia(大规模通用领域结构化百科)[1]、CN-Probase(大规模中文概念图谱)、 ProbasePlus以及一些智能问答产品。如CN-DBpedia的实体数量已经达到了千万级别,关系数量达到亿的级别。
对于司法领域知识图谱的构建,国内的国双公司正尝试将事例图谱与传统的知识图谱结合起来搭建司法图谱,让机器尽可能的像人类一样思考:做什么,怎么做,让司法大数据更智能的协助司法工作者。
1.3 本文研究目标及内容
本文的研究目标是把知识图谱构建涉及的技术流程应用到司法领域来构建一个司法领域的知识图谱。
本文的研究内容主要先进行需求分析,定义实体类型和关系类型,然后获取司法网站上的一些非结构化数据,接着利用统计学习方法对获取的非结构化数据进行司法方面的实体抽取,然后对句子级别的实体对进行关系提取,最后将提取的关系三元组存入数据库中。
所以本文的完成的主要工作包括:
(1)司法网站的非结构化数据的获取与存储。
(2)对(1)中获取的非结构信息进行实体抽取。
(3)对每个句子中的实体对进行关系抽取。
(4)将抽取出的实体和关系三元组存入Neo4j图数据库中。
1.4 论文结构
针对本文的研究目标及内容,本文的组织结构如下:
第一章,绪论。这一章主要介绍了知识图谱构建技术研究的研究背景及意义,然后分析了国内外对知识图谱的研究现状,最后阐述了本文的研究目标及内容。
第二章,知识图谱构建技术。这一章主要介绍了知识图谱的构建流程以及涉及的算法。
第三章,司法知识图谱构建概览。这一章主要介绍了对于司法领域知识图谱构建的总体流程和开发环境。
第四章,司法知识图谱的构建实现。这一章主要详细介绍了司法知识图谱构建的具体实现,主要有知识建模、数据获取、实体抽取、关系抽取、知识存储。
第五章,对本文的研究进行总结,指出了构造的司法知识图谱的不足,以及如何后期如何进行后续的研究来改善。
第2章 知识图谱构建技术
这一章首先介绍一下知识图谱的定义和构建流程,然后介绍了实体抽取和关系抽取相关的方法,最后介绍了在本研究使用的条件随机场算法、远程监督算法和支持向量机算法。
2.1 知识图谱
2.1.1 知识图谱定义
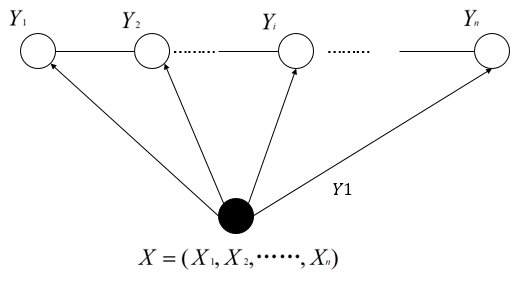
刘峤等[2]在知识图谱构建技术综述一文中阐述知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及相关属性-值对,实体间通过关系相互连结,构成网状的知识结构。
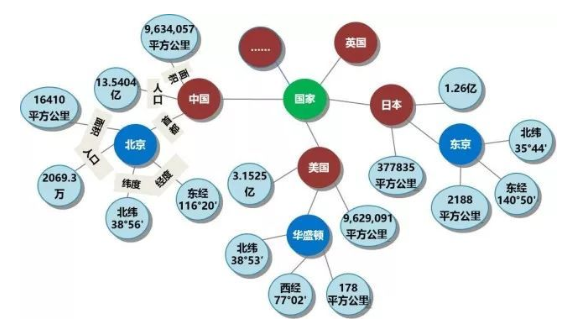 知识图谱在逻辑上可以分为两层:数据层和模式层。数据层主要是实体存在知识图谱中,模式层则以实体提炼的概念体系存在知识图谱中。
知识图谱在逻辑上可以分为两层:数据层和模式层。数据层主要是实体存在知识图谱中,模式层则以实体提炼的概念体系存在知识图谱中。
图2.1 地理位置知识图谱部分截图
如图2.1所示,这是一个地理位置知识图谱的部分截图。“国家”就是相当于知识图谱中的模式层,表示实体的类型。“中国”、“日本”等则是“国家”的实例,也就是实体,属于知识图谱的数据层。“中国”与“北京”之间有一条边,即表示这两个实体之间的语义关系,即“北京是中国的首都”,“中国”与“13.5404亿”之间的边“人口”即表示“中国”这个实体的“人口”属性值为“12.5404”亿。
2.1.2 知识图谱构建的流程
知识图谱有自顶向下和自底向上两种构建方式,不过也有采用自顶向下和自低向上相结合的方式进行知识图谱的构建。
自顶向下:利用百度百科等结构化数据,从高质量的数据中提取出本体和模式,加入到知识库中。
自底向上:借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的新模式,经人工审核之后,加入到知识库中。
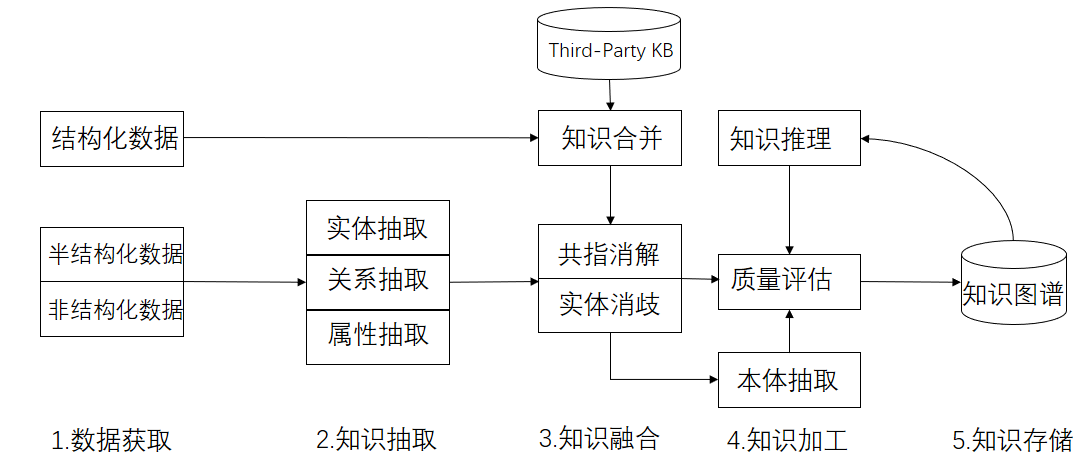 目前关于知识图谱构建的研究已经很多,大多数人的构建流程都大同小异。主要可以分为数据获取、知识抽取、知识融合、知识加工和知识存储。
目前关于知识图谱构建的研究已经很多,大多数人的构建流程都大同小异。主要可以分为数据获取、知识抽取、知识融合、知识加工和知识存储。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: