基于Web的金融数据抓取与分析毕业论文
2020-02-23 18:21:06
摘 要
随着互联网的不断发展,移动互联网、大数据、云计算、物联网等技术逐步应用到了金融领域,传统的金融行业架构发生深刻变化,原有的金融行业受到不断的冲击。本文通过网络爬虫技术获取了当天的深沪市场交易数据,并以浦发银行的历史交易数据为例进行SVM模型预测分析,验证了SVM模型对于股票预测的有效性。此外,本文还从区块链技术中找到其在证券行业中可能的应用场景,通过文献梳理和实际应用,创新性地使用IPFS对爬取到的证券数据文件进行存储,达到了分布式存储的目的,实现了文件的不可篡改和可追溯性,安全保护相关数据,提高了网络文件存储效率。
关键字:互联网金融;数据爬取与预测;区块链存储
Abstract
With the continuous development of the Internet, technologies such as mobile Internet, big data, cloud computing, and the Internet of Things have gradually been applied to the financial sector, which has caused profound changes in the traditional financial industry structure and the original financial industry has been constantly impacted. This paper obtains the trading data of Shenzhen and Shanghai markets through web crawler technology, and uses the historical trading data of Shanghai Pudong Development Bank as an example to carry out SVM model forecast analysis, which verifies the validity of SVM model for stock prediction. In addition, this article also finds its possible application scenarios in the securities industry from the blockchain technology. Through the literature review and practical application, it innovatively uses IPFS to store the captured securities data files and achieve distributed storage. The purpose is to achieve non-destructive and traceability of files, securely protect relevant data, and improve network file storage efficiency.
Key Words: Internet Finance; Data crawling and forecasting; Blockchain storage
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 国内外研究现状 2
1.3 本文的主要工作 3
第2章 基础理论介绍 4
2.1 网络爬虫概述 4
2.2 SVM技术概述 4
2.3 区块链技术概述 5
第3章 证券数据爬取 7
3.1 爬取策略的制定 7
3.2 获取HTML页面信息 8
3.3 解析HTML文档 8
3.3.1 东方财富网页面解析 8
3.3.2 百度股票网站页面解析 9
3.4 交易数据的存储 9
第4章 证券数据预测 11
第5章 证券数据存储 14
5.1 区块链核心架构与技术 14
5.2 IPFS概述 15
5.3 IPFS与HTTP的比较 16
5.4 IPFS的使用 18
第6章 总结及展望 24
参考文献 25
致 谢 26
第1章 绪论
1.1 研究背景
在互联网技术飞速发展的今天,信息化时代逐渐到来,生活中的各个方面对数据信息获取的要求都越来越高。特别是在金融领域,数据信息化和金融网络化的趋势日益明显,大量的金融数据(如股票、基金、债券等)通过网络即时发布,各类金融咨讯网站和金融交易网站充斥着我们拿到眼球,Web金融数据信息量出现爆发性的增长。面对这样数据量巨大且内容组成复杂多变的金融信息时,用户迫切需要用互联网技术代替人力来抓取和处理这些金融数据。将数据有效的检索并组织呈现出来有着巨大的应用前景。据了解,在大家普遍比较关心的证券市场领域,截止目前中国证券市场规模达到了3500家上市公司左右,其中沪市1400家,深市2095家。面对这样一个相对较大的金融市场,人们对证券市场中这些单一个股的交易数据获取及其智能量化分析将是我国金融市场趋于成熟的必然发展方向。
同时,日前火热的区块链技术作为一种新型互联网技术,也契合金融市场的发展需要。互联网金融的参与者希望金融业务信息具有更高的公开度,更广的传播度,同时还要满足良好的协作性,便捷的操作性,并尽可能的降低中间成本。因此通过互联网等工具对传统的金融行业进行创新,使其结合区块链等技术将大大改变目前金融市场以资本为中心的封闭自利情况,有效解决信息不对称风险、资金转移支付风险、信息安全风险、合约有效性风险等问题,易于双方信任的获取、提高数据安全保密性、降低信息安全风险、创新金融业务模式。具体而言,由于时间戳的使用和节点之间的相互验证和记录,用区块链存储的数据不存在被恶意修改或者造假的可能,因此区块链技术可以应用于P2P交易、数据登记与使用权确认以及智能管理等诸多领域,在很大程度上实现金融脱媒脱介。在证券市场中,目前大部分的交易都采用T 1或者T 2的交易模式进行交割,流动性不足,并且占用了大量的计算资源。区块链技术的出现将在证券发行与登记、清算和结算等方面具有广阔的发展空间。在最开始阶段的证券登记业务中,不同于传统记录数据的纸质或电子账本,区块链可以大大降低证券登记成本。通过将加密后的数据保存在区块链中进行全链公证,不仅可以实现无纸化,并且可以将所有的资产信息以非移动形式交收,还可以完全不依赖于中央证券存管机构。此外,当证券的权属关系发生变动时,区块链中相应节点将对全链广播保证所有节点数据更新,确保修改后的数据与区块链总账中的保持同步。智能合约的出现还能将证券资产的交易实现自动化,减低人工成本和提高运营效率,减少暗箱操作或内幕交易。
1.2 国内外研究现状
当前国内外对金融数据的抓取与处理工作已取得一定成果。国外的研究起步较早,取得的成果也更为显著。杨竹(2012)的文章指出国外已开发成功了Heritrix和Nutch等成熟的开源网络爬虫[1]。余春(2014)提到了两个在全世界享有盛誉的金融系统,分别是CRSP金融系统和Compustat金融数据查询系统,它们提供的数据为全球的金融研究工作提供了重要的支持[2]。但是这两个系统都不能提供免费服务,而且它们提供的金融数据存在时间滞后以及范围有限的问题,无法在瞬息万变的证券市场中快速捕捉数据,并基于此把握住每一次在股票市场中获利的机会。因此,这两个系统目前只能用于事后的金融科学研究,不适用于普通金融用户进行实时金融数据获取和分析,用户类型有限。
国内的金融数据主要来自各大门户网站,如东方财富网、新浪财经、网易股票等。通过访问互联网可以查询到大量的金融信息,但查询结果往往差强人意,使人眼花缭乱,对信息的精确提炼不够。臧凯源(2015)指出对于金融数据分析人员而言,面对复杂且重复性的数据采集与处理工作,人为的处理存在着较大的困难和资源浪费[3]。国内关于金融数据挖掘的探讨还处于开始阶段。李小琳、孙玥、刘洋(2016)的研究指出传统的股票预测大多只是基于经验判断或者技术指标的分析,包括基本面分析和K线图分析等[4]。近年来,数据挖掘的方法开始逐渐应用于证券市场预测中,但针对不同的模型算法,有文献指出,神经网络模型更容易出现过学习现象,泛化能力差。杨新斌和黄晓娟(2010)基于SVM对股价进行预测实验,结果表明SVM模型比神经网络和CAR模型具有更高的准确度[5]。同时,朱磊(2016)利用支持向量机和神经网络对样本输入不同的股票技术指标进行对比试验,结果发现在时间序列预测问题上,SVM方法均优于神经网络方法[6]。
在区块链方面,区块链技术起源于中本聪(2008)的一篇奠基性论文,该论文提出了一种电子现金系统,并基于共识机制实现了点对点的安全交易,由此产生了虚拟货币——比特币[7]。Alex Pazaitis等(2017)分析了区块链技术在共享经济中广泛应用的价值体系[8]。Fauzi等(2017)基于比特币和区块链技术进行了相应可视化系统的开发[9]。随着对比特币这种新型电子货币的好奇不断增强以及对去中心化、高安全性的需求不断提高,更多的应用领域想要实现类似的特征。因此,区块链技术作为实现比特币交易的底层核心技术被提炼出来广泛应用。袁勇和王飞跃(2016)对区块链技术进行了理论分析,详细阐述了其工作原理[10]。赵增奎等(2017)指出金融行业是区块链目前最受关注的领域,截至2016年初就有超过10亿美元关于区块链方面的投资[11]。Fanning K等(2016)分析了区块链技术将对金融基础设施的冲击[12]。2015年12月NASDAQ推出首个基于区块链的证券交易平台 Linq,同月区块链投资公司Coinsilium成为首家IPO成功的区块链公司。Larios-Hernández(2017)总结了区块链技术与银行业务之间的广泛合作关系[13]。刘瑜恒和周沙骑(2017)指出基于区块链的技术特征,它可以提升目前证券市场交易、清算以及交割环节的数字化水平,大大简化目前繁琐耗时的业务流程,将来甚至有可能取代其中的某一环节[14]。孙国茂(2017)指出利用区块链技术有助实现T 0实时全额交易[15]。此外,由于区块链具有不可篡改性和可追溯性等特征,因此以它作为底层架构可以用来开发数据库,来保证所存储的各种信息的安全性。殷龙和王宏伟(2016)指出了现有的分布式文件系统存在的问题,并提出了基于IPFS的旨在提供全球性的高效分布式文件共享系统[16]。
1.3 本文的主要工作
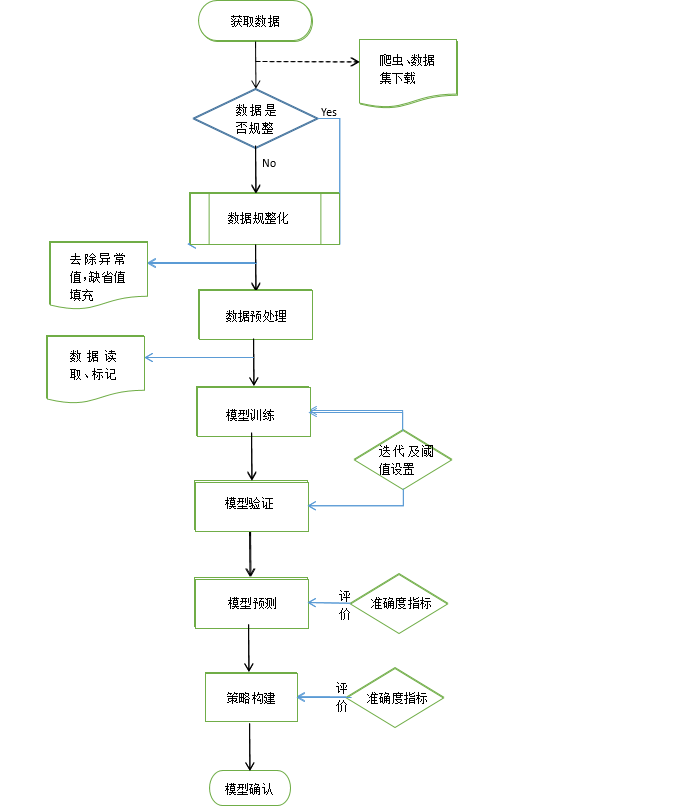
本文旨在应用数据爬取技术设计并实现基于Web的证券数据抓取与处理,使其能够自动化采集证券信息和交易数据,并使用机器学习算法对所获得的交易数据进行量化分析。同时,将采集的数据运用区块链技术进行存储,保证数据存储安全。
本论文安排如下:
第1章介绍研究背景、国内外研究现状及本文的主要工作
第2章介绍本文所用到的相关技术理论
第3章介绍证券数据的爬取工作
第4章介绍证券数据的分析工作
第5章介绍证券数据的存储工作
第6章总结主要工作并进行展望
第2章 基础理论介绍
2.1 网络爬虫概述
互联网数据的采集可采用网络爬虫(Crawler)技术。能够自动访问互联网并且将其中的网络数据按照一定的规则进行解析和存储的程序或脚本被称为网络爬虫,合理利用网络爬虫可以帮助搜索引擎从Web上下载所需的指定网页信息。网络爬虫的运行原理是首先访问用户指定的初始网页,得到该网页上存在的所有URL地址并形成列表。此后,它将不断向此列表中添加在访问Web过程中从新的页面上提取到的新的URL,满足用户预先设定的条件时才停止Web访问。在访问URL时,网络爬虫将根据预先设定的动作自动解析并提取网页 HTML代码,通过HTML代码中指向的其他网页可以实现页面跳转,也可以根据其他网页标签中的关键词,使用正则表达式等手段对网页中的相关信息进行解析和存储。
Python 是一种开源的高级程序设计语言,它提供了丰富的应用程序编程接口和工具,不仅代码编写起来简洁,使用方便,使用Python进行网络爬虫程序编写时,除了自带库urllib,还能调用强大的第三方依赖库,包括自动提交网络请求并爬取相关 HTML 页面的requests库,以及解析相应 HTML页面并提取其中关键信息的 Beautiful Soup 库等,为网络爬虫程序的编写和实现带来了极大的帮助。
2.2 SVM技术概述
SVM(Support Vector Machine,支持向量机)是一种机器学习分类算法,它是在VC维理论和结构风险最小原理的基础上建立的。其工作原理是在有限的样本中寻求模型复杂度和学习能力的平衡,以使得模型能够进行更好地推广,得到最好的泛化能力。简单来说,就是采用结构风险最小化原则,最大化最近数据点和超平面之间的距离。SVM原理图如图2.1所示。
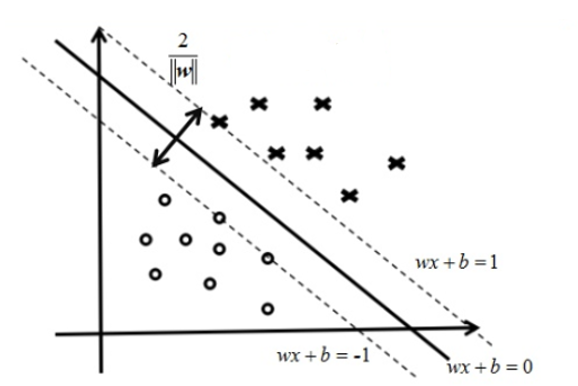
图2.1 SVM模型原理图
图中,超平面使用一般线性表达式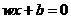 表示,其中超平面的方向由法向量
表示,其中超平面的方向由法向量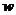 表示;从超平面到原点的距离由位移项
表示;从超平面到原点的距离由位移项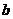 表示。为了最大化支持向量与超平面之间间隔,可以用如下数学表达式表示:
表示。为了最大化支持向量与超平面之间间隔,可以用如下数学表达式表示:
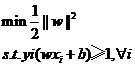
SVM并不需要真正的向量,它可以用它们的点积来进行分类。让SVM处理新的点积结果的就是核函数。核函数具有将低维数据转化为高维数据的作用,它将不可分离的问题转换成可以分离的问题。通常核函数是线性的,所以得到的是一个线性分类器。但如果使用的是一个非线性的核函数,只需要改变点积为我们想要的空间,就可以在完全不改变数据的情况下得到一个非线性分类器。核函数隐式的定义了特征空间,其选择决定了模型的准确性。常见的核函数包括线性核、高斯核(亦称rbf核)、拉普拉斯核、Sigmoid核、多项式核等。此外,还设置了两个参数以对模型更好的修正,其中gamma表示核相关系数,gamma值越大,SVM就越容易准确的划分每个训练集中的数据;c表示误差项的惩罚参数。SVM的一般流程如表2.1所示
表2.1 SVM的一般流程
序号 | 步骤 | 说明 |
1 | 收集数据 | 可以使用任意方法 |
2 | 准备数据 | 数据格式需要为数值型 |
3 | 分析数据 | 将给可视化分隔超平面提供帮助 |
4 | 训练数据 | 在训练数据阶段的任务是不断调整修正模型的c和gamma两个参数,得到最好的参数值 |
5 | 测试算法 | 实现过程较为简单 |
6 | 使用算法 | 几乎所有的分类问题都可以使用SVM算法,对于多类问题只需修改即可 |
相比与其他的机器学习算法,SVM具有更快的速度,同时对于边界清晰的分类问题效果更好,对于高维度的分类问题也具有更好的拟合效果,此外,SVM算法优先考虑正确分类,对于离散值具有更强的健壮性。
2.3 区块链技术概述
区块链是一种块链式数据结构,它是按照数据记录的时间顺序将数据区块以链式结构进行相互连接。从功能性上看,区块链利用密码学公私钥管理体系设计的分布式账本解决了拜占庭将军问题,保证数据传输访问的安全。区块链的基本原理是将数据压缩成与之一一对应的64位哈希,并将哈希写入区块链交易中,打上时间戳。一定数量的哈希将组成一个区块,区块之间链式相连就将组成一条区块链。此外,它还利用自动化脚本语言编写智能合约,用预先制定的程序来自动处理合同。总的来说,区块链的典型特征是去中心化、不可篡改性以及匿名性等,各个节点之间不需要建立原有的相互信任关系。区块链按照不同的使用场景还可以有不同的划分,包括私有链、联盟链和私有链等,不同的区块链类型之间使用者的角色定义不同,所获得的权限也不同。
第3章 证券数据爬取
3.1 爬取策略的制定
本文想要获得证券交易数据,包括日期、股票代码、股票名称、最高价、最低价、开盘价和收盘价等信息,为确保能够获取到上海交易所和深圳交易所所有股票的名称和交易信息并将其保存到文件中,本文在选择目标爬取网站时采取如下原则:(1)股票信息存储在静态HTML网站中,信息更新过程中没有JavaScript代码生成(2)没有访问限制,允许使用爬虫技术获取页面信息。
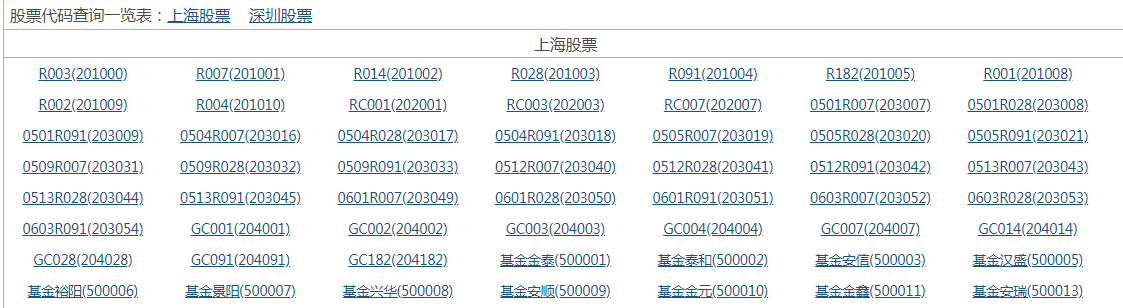
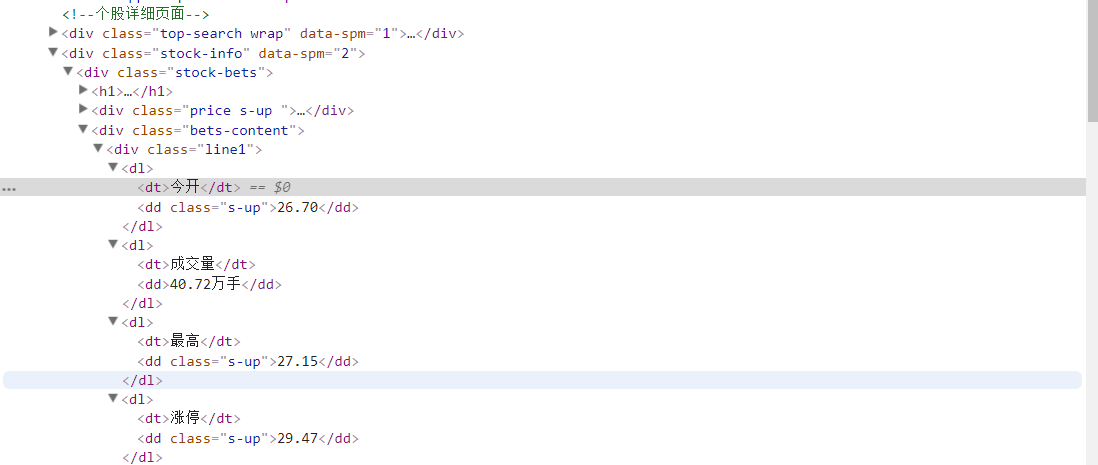
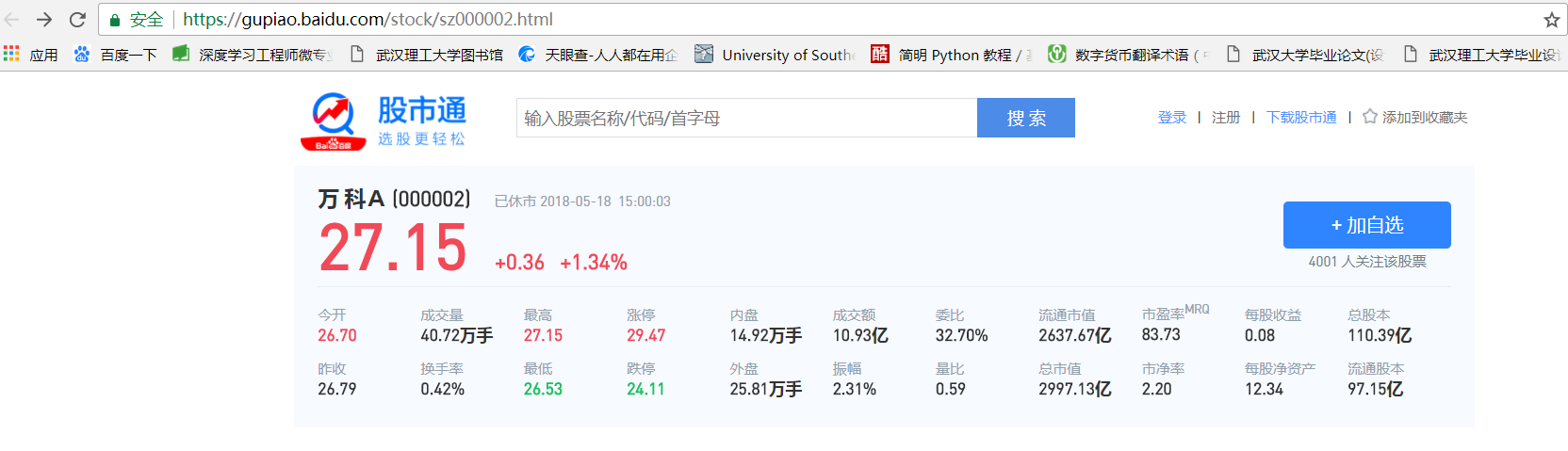
在具体实践过程中,主要查看了百度股票网站、东方财富网以及网易股票网站的源代码,查看其静态网页中是否含有股票交易数据。最终发现百度股票的数据是由HTML代码生成的,并且允许访问,符合本项目的要求。但是,百度股票:https://gupiao.baidu.com/stock/中只提供了所搜索的单个上市公司股票的交易信息,如果想要自动化的爬取其他上市公司的股票交易信息,需要提供其股票代码。如https://gupiao.baidu.com/stock/sz000002.html就是万科A的股票主页,如图3.1所示。其中sz代表万科A是在深圳交易所上市,000002代表万科A的股票代码。其余股票同理,sh代表该股票是在上海交易所上市,sz代表该股票是在深圳交易所上市,其后紧跟的六位数代码代表该股票在证监会登记注册的证券代码,具有唯一标志性。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: