用于预测消费行为的深度学习模型设计与实现毕业论文
2020-02-23 18:22:09
摘 要
现如今网络广告的推送铺天盖地,根据用户的订阅行为可以观察出用户对于哪类广告更感兴趣。而网络广告的井喷促使更好地预测广告的点击率。其中广告点击也属于消费行为中的一类,通过预测广告点击率可以对客户更关注哪一类的广告以及对这类广告的价值有明确的认识。
传统的深度学习模型在广告点击预测上对顺序广告展示的不可改变的传播在有效建模动态点击预测方面存在局限性,而CNN深层架构的池化和卷积层可以从顺序广告展现中充分提取本地-全局关键特征。因此本文使用并对基于CNN的深度学习模型进行了评估,本文的主要工作内容如下:
- 模型分析
本文使用卷积神经网络对输入实例进行建模,交替使用宽卷积层和最大值池化层,构建灵活的卷积神经网络模型,同时对该模型进行代码层面上的分析。
- 数据处理
本文使用Hash算法中的MD5对预处理数据提取摘要,通过对摘要进行处理再加以一定的辅助函数完成数据预处理过程。
- 训练数据
本文把测试数据放入模型中进行训练,并根据训练结果分析其可用性以及不足之处。在Kaggle 2015中Azavu数据集上的实验结果表明本文使用的模型能够提高广告预测点击率的预测效果,其ACC值达到88.02。
本文的特色在于将卷积神经网络运用于广告点击预测方向上,并对该卷积神经网络进行了细致的模型分析以及对数据预处理、训练结果做出了具体的分析。
关键词:网络广告;卷积神经网络;深度学习;点击率预测;
Abstract
Nowedays,the push of online advertising is overwhelming.According to the user’s subscription behavior,we can observe which type of advertisement the user is more interested in.The blowout of online advertising has led to a better prediction of the click-through rate of advertisements.Advertising clicks also belong to the category of consumer behavior.By predicting the click rate of advertisements,it is possible to pay more attention to which types of advertisements the clients care about and the value of such advertisements.
The traditional deep learning model has unreliable propagation of sequential advertisements on ad click prediction.It has limitations in effectively modeling dynamic click prediction.The pooling and convolutional layers of CNN deep architecture can be fully extracted from sequential advertisement display with Local-global key features.Therefore,this paper uses and evaluates the CNN-based deep learning model.The main contents of this paper are as follows:
(1)Model analysis
In this paper,a convolutional neural network is used to model the input instances,and the wide convolutional layer and the maximum pooling layer are alternately used to construct a flexible convolutional neural network model.At the same time,the model is analyzed at the code level.
(2)Data processing
This paper uses MD5 in Hash algorithm to extract the abstract of the preprocessed data.Through processing the digest and then adding some auxiliary functions.the data preprocessing process is completed.
(3)Training data
This article puts the test data into the model for training and analyzes its availability and deficiencies based on the training results.The experimental results on the Azavu dataset in Kaggle 2015 show that the model used in this paper can improve the predictive effect of ad prediction clickthrough rate,with an ACC value of 88.02.
The characteristic of this paper lies in the application of convolutional neural networks to the direction of advertisement clicks, and a detailed model analysis of the convolutional neural network and a detailed analysis of the data preprocessing and training results.
Key Words:Online Advertising;Convolutional neural network;Deep learning;Click-through rate forecast;
目 录
摘 要
Abstract
1 绪论
1.1研究背景
1.2目的及意义
1.3国内外研究现状
1.4基本内容和技术方案
2实现方法概述
2.1项目目标
2.2模型结构图
3.广告点击预测模型实现
3.1 模型简单介绍
3.2 模型详细介绍
3.2.1 模型入口
3.2.2 Embedding层
3.2.3 数据切片
3.2.4 二维卷积层Conv2D
3.2.5 二维池化层MaxPooling2D
3.2.6 激活函数
3.2.7 Flatten层
3.2.8 全连接层
3.2.9 创建模型
3.3 数据集选取及预处理
3.3.1 获取数据集
3.3.2数据集预处理
3.4 训练模型
4实验和结果
4.1实验过程
4.2实验结果分析
4.2.1 交叉熵loss与准确率acc
4.2.2 Pearson相关性系数
5结语
参考文献
致谢
第1章 绪论
1.1 研究背景
如今处在互联网的大环境下,当每个人在接触互联网的时候,必然会在互联网的大数据海洋中遨游,遨游的过程中就会接触到各种各样的搜索引擎如Baidu,Google等。这些搜索引擎已然成为互联网之中的巨头,每天向数以亿计的互联网探索者提供相应的服务。在各大搜索引擎中,搜索广告是主要的变现方式。按点击付费又是搜索引擎中被最广泛应用的计费模式[4]。因此,对广告搜索方向上的研究可以使我们对搜索引擎的运作方式有更好的认知。
每个人的日常生活中,或多或少都会遇到各种形式不同的广告。这些广告价值有高有低。本文主要围绕广告点击预测为中心,对一种基于卷积神经网络的点击预测模型进行评估。
1.2 目的及意义
对于电子商务平台而言,用户消费行为预测(主要研究购买倾向,即用户购买某一商品的可能性)直接关系着其广告投放、商品推荐。在电商卖家对用户消费行为分析上急需通过用户消费行为预测模型来跟踪用户消费趋势,实现商品对口用户,从而提高商家的盈利。很多对用户行为分析进行研究的案例已经出现在国内外。经过分析建模在线用户行为,学者们构造了包含推荐系统,社交影响力分析在内的众多应用,并且在这些应用上也有不错的效果[1]。
用户消费行为预测是一个强相关和紧耦合的非线性问题。在处理此类问题的众多方法中,深度学习独领风骚,以非常高的准确率成为国内外学者及大型企业钟爱的方法。优良的深度学习模型可以挖掘用户行为的特征,并自发地处理众多特征之间的关联关系,从而达到对该非线性问题准确拟合的效果,作出准确预测。
1.3 国内外研究现状
自2006年以来,深度学习逐渐成为学术界的新星.成为研究深度学习的重镇的有斯坦福大学、纽约大学、加拿大蒙特利尔大学等.2010年,深度学习项目得到美国国防部DARPA计划的首次资助,参与方有纽约大学、斯坦福大学和NEC美国研究院[3]。
相比于过去的方法,深度学习模型目前在很多如语音识别、图像分类等领域都显示出了其独特的作用。事实上,数据集上的某项评价指标被刷新背后或多或少都出现了深度学习的论文的身影。通过与吴恩达研究组合作,谷歌研究院建立了共有 10 亿个参数的深度网络,成为当时史上最大的神经网络。他们通过复杂的计算机集群对该网络训练了一周,在 ImageNet 数据集上与当时最好的结果作对比分析时,准确率提高了 70%。在语音识别准确率方面,百度公司中过去 15 年进展的总和甚至比不上过去一年的进展,这个互联网巨头通过深度神经网络使得以图搜图的准确率提升到 80%[2]。
深度学习技术在很多领域上取得了阶段性的突破,但在近年来广告点击预测上仍只是使用DNN深度神经网络进行模型构建。传统上,搜索引擎巨头公司如Google,Baidu等是以机器学习上的逻辑回归(logistic regression)模型对广告价值进行预估,到了2012年开始,百度开始意识到广告CTR预估的关键点是模型的结构,LR只能处理扁平结构的模型学习和抽象特征,不足以描述元素的潜在特征或揭示这些元素之间的复杂关系[3]。而作为推荐系统中广泛使用的技术,校对过滤方法中的矩阵分解(MF)方法也用于点击预测。 MF方法分解和重建依赖矩阵,以学习页面和广告的潜在语义表示。后来,因式分解机器(FM)是多元素空间中MF的扩展,获得了每个元素的潜在语义形成,能够更好地模拟各元素之间的关系。但是,MF和FM模型捕获了单个广告展示中的成对元素的相关性,并忽略了这些元素之间的高阶互动。
为了突破这样的限制,百度开始尝试使用DNN来做搜索广告的神经网络模型。在百度的DNN系统中,特征数从1011级别降低到103,从而能被DNN进行正常的学习。这套深度学习系统于2013年5月开始正式启动,每天为数以亿计的网民服务[3]。
为了挖掘复杂动态景观中的重要语义特征,深度神经网络是一个不错的选择。如上所述,对于单个广告印象的点击预测,MF和FM方法仅揭示了成对元素之间的相关性,但卷积神经网络(CNN)可以将单个广告印象中的不同元素视为一个整体并得到它们之间的复杂交互。
另外,最近关于CNN架构的一些研究成功地模拟了各个领域的重要语义特征。 CNN在语音识别,图像识别,信息检索这些领域取得了很大的进步。动态卷积神经网络(Dynamic Convolutional Neural Network,DCNN)被证明是自然语言处理中的有效句子模型,可以分析语义内容并提取句子的关键特征。
1.4 基本内容和技术方案
本文最终目的是对实现广告点击预测模型,将结果以id:click的形式展现出来,并分析该模型与传统RNN模型之间的差异。该过程首先是需要获取真实可靠的广告相关条目,获取完条目之后对数据进行一个初步的预处理,然后构建所需要使用的基于卷积神经网络实现的广告点击预测模型,构建完模型后对模型进行训练,以及相应的结果评估。研究内容包含以下方面:
(1)研究基于卷积神经网络的预测模型的实现。
(2)研究广告数据预处理过程,观察如何能对广告数据进行合适的预处理。
本文所采用的技术方案及措施方法如下:
(1)在Windows10环境下安装Anaconda,通过这个包管理工具对深度学习相关框架tensorflow,keras做一个相关包的导入,并确保python版本与框架版本一致。
(2)使用keras相关api实现CNN广告点击预测模型,其中keras的后端使用tensorflow。
(3)使用集成开发环境Spyder对相应的python代码进行调试。
第2章 实现方法概述
2.1 项目目标
该项目包括模型构建,数据预处理,数据训练几个部分。而总的来说对该项目的评判应该从以下几个方面着手:
(1)模型合理性
对于卷积模型的构建是否合理需要从多个角度进行评判,根据结果判断该模型是否能运用到相应的数据集上。
(2)数据预处理有效性
只有当数据预处理后得到的数据集是能被模型所识别的,才能说明数据预处理过程是有效的。本文数据预处理过程理论与实际相结合,可以正确地传入模型。
(3)训练方法适用性。
只有根据训练结果能合理分析出相应不足之处,并给出其相应的解决方案,且训练数据确保真实可靠,才能说明本次模型的训练方法具有适用性。
2.2 模型结构图
本文使用卷积神经网络作为模型结构,其中交替使用卷积层以及最大值池化层,模型初步结构如图1所示[5]:
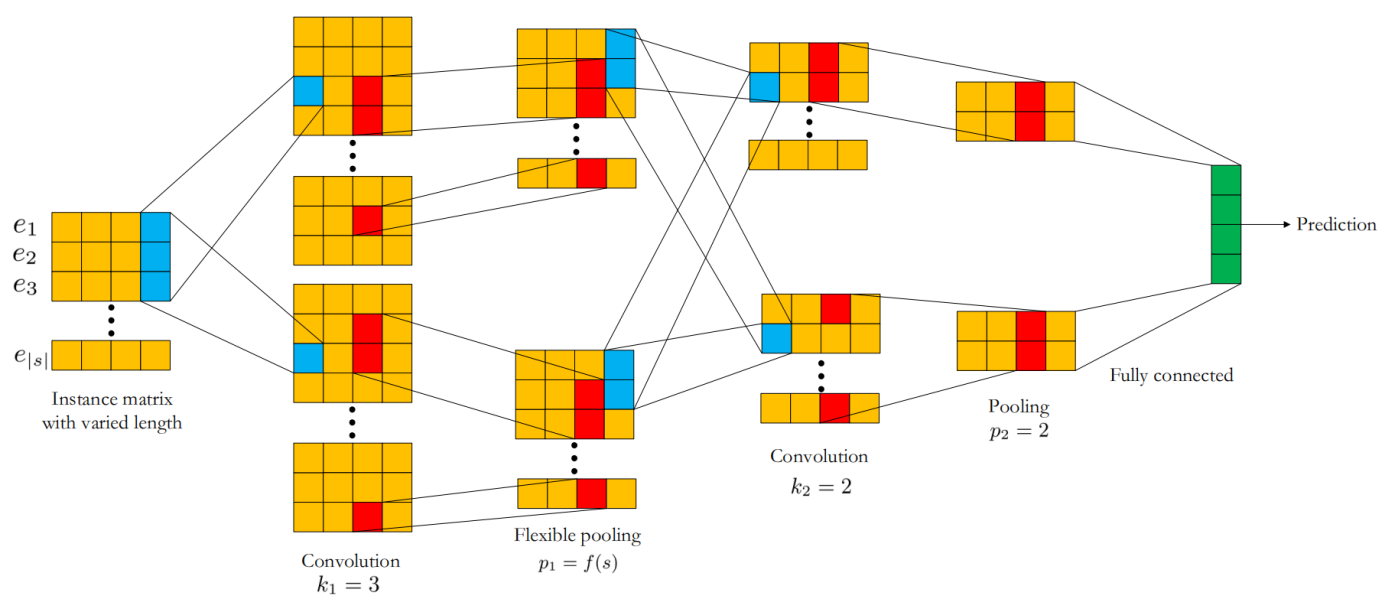
图1 模型结构图
第3章 广告点击预测模型实现
3.1 模型简单介绍
本次广告点击预测模型主要由如下组成。
首先整个模型需要定义一个输入的入口,通过这个入口将数据传入到模型中。
其次将数据传入到模型中,首先要进行一个Embedding层的特征映射。Embedding层大致作用是将张量的维度进行扩张,使得扩张后的张量在扩张后的维度(Embedding_dims)上具有一致的特征。
接下来对Embedding_dims中的各个维度,将它们分别进行矩阵切片操作,使得其数据能更好地传入卷积层进行处理。
然后就是对数据进行卷积操作。在卷积操作中重复将数据卷积三次。这里每次卷积操作又将数据传入三层模型中,每一层均使用tensorflow的backend生成对应格式的训练数据格式,卷积操作的第一层是填充层,在其中将输入张量对其填充w-1维,并将这w-1维全部填充0,第二层是对二维输入使用二维卷积层进行卷积[10],第三层则将第二层卷积得到的结果进行二维最大值池化。经过了填充,卷积,池化后,对通过三层得到的数据使用激活函数sigmoid进行激活。这样便完成了一次卷积操作。重复这样的三次卷积操作后,便得到该数据的一个特征图。
再然后,得到特征图后,其实得到的是一个多维的张量,此时就需要经过Flatten层,将多维张量转变成一维数据。
最后通过全连接层获取最终的输出。其中全连接层使用的激活函数为tanh。
通过上述描述,可能读者对模型有了一个初步的了解,接下来就对模型从思路和代码上进行一个详细的分析。
3.2 模型详细介绍
3.2.1 模型入口
在模型入口处需要为模型定义一个输入入口,该入口为一个张量(tensor),其中它的形状(shape)为输入数据的行数(maxlen)加上自动扩充的列数,类型(dtype)为int32位。代码如下:
main_input = Input(shape=(maxlen,), dtype='int32') |
3.2.2 Embedding层
对于Embedding层,官方的定义是:“把正整数(索引)转换为固定大小的稠密向量”。使用Embedding层有如下原因:
(1)独热编码(One-hot encoding)向量是高维且稀疏的。场景一旦切换到自然语言处理(NLP)下,假如说提供一个字典,它包含2000个单词,那么在我们使用独热编码的过程中,会出现使用含有2000个整数的向量来表示一个单词这样的情况,而这个向量中的1999个整数都是0。在大数据集下这种方法的计算效率是很低的。
(2)每个嵌入向量在训练神经网络时更新。通过嵌入层,我们可以将多维空间中词语的相似程度可视化,如下图所示。同样,我们能将这些类似的嵌入向量做一个相似程度的划分[14]。
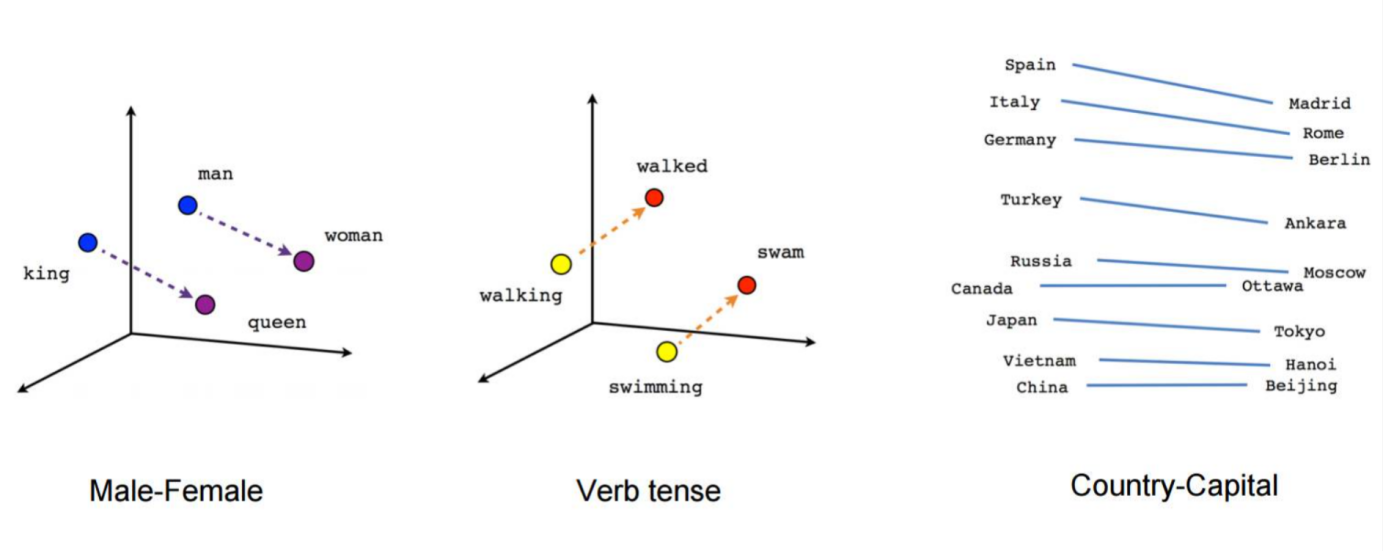
在我的理解中,使用Embedding层有以下原因。首先Embedding层将原张量进行一个映射,将原先的属性所在空间映射到一个新的多维空间上去。而且使用Embedding层是通过它来为我们的输入张量进行维度扩张,扩张成一个具有更多维度的张量,使用这个更多维度的张量可以有效减少嵌入向量的稀疏性。通过Embedding层为各个行为分配索引,并通过这些去构建一个完备的行为序列。我们从keras.layers包中引入Embedding,实际的Embedding层代码如下:
embedding_map = Embedding(output_dim=embedding_dims, input_dim=max_features, input_length=maxlen,W_regularizer=l2(reg_conf[0]))(main_input) |
其中,input_dim为输入的字典长度,output_dim为全连接层嵌入的维度,input_length为输入序列的长度,W_regularizer为嵌入矩阵的规则项,加入该项是为了避免过拟合。
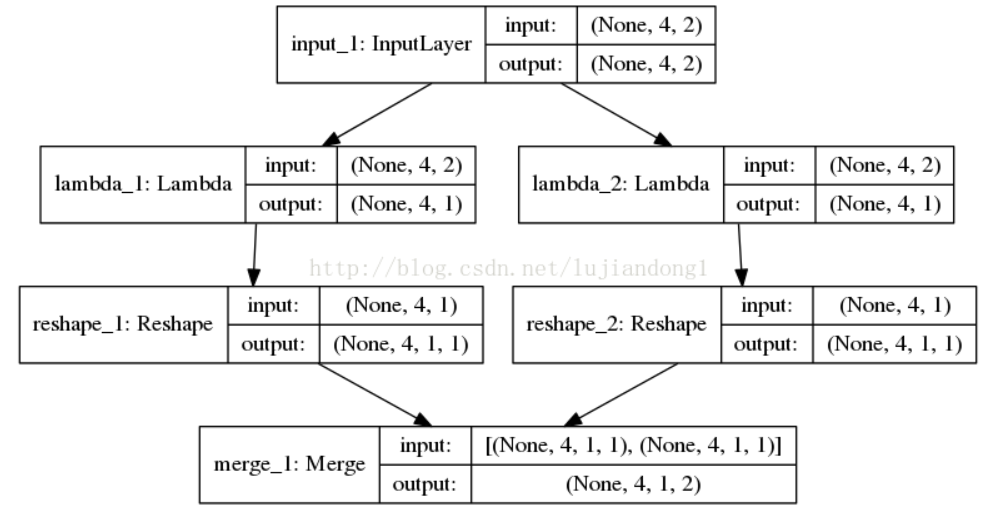
3.2.3 数据切片
通过3.2.2得到了一系列的embedding_dims,而这些还不能直接放入卷积层中进行处理。此时要经过一项叫做数据切片的工作。数据切片的目的是将矩阵的每一列提取出来,然后单独进行操作,最后再拼在一起。如下图所示: