基于字典学习的行人重识别算法设计研究毕业论文
2020-02-23 18:22:32
摘 要
Abstract II
第 1 章 绪论 1
1.1 背景 1
1.2 目的及意义 2
1.3 国内外研究现状 2
1.4 课题研究内容 3
第 2 章 针对行人重识别问题的耦合边缘化自动编码器框架 5
2.1 耦合边缘化自动编码器 5
2.2 针对跨域多视角行人重识别问题的模型 6
2.3 模型迭代优化学习方案 10
2.4 本章小结 13
第 3 章 模型构建 14
3.1 基于patch特征的自动编码器模型构建 14
3.2 基于patch模型的无监督显著性优化方案 16
3.3 基于image特征的自动编码器模型构建 18
3.4 模型融合及结果分析 18
3.5 基于Java Swing的匹配结果可视化 21
3.6 本章小结 22
第 4 章 总结与展望 23
4.1 总结 23
4.2 展望 23
参考文献 25
致 谢 27
摘 要
行人重识别,旨在从不同地点配置的各种相机识别同一行人的图像。运用计算机视觉、机器学习方法进行行人重识别可以有效帮助工作人员在海量视频中快速发现、追踪行人目标,本文主要针对行人图像跨视角且分辨率不同这一具体问题,应用耦合边缘化自动编码器方法来实现行人重识别。
耦合边缘化自动编码器模型构建了两个边缘化去噪自动编码器分别用于低清图像、高清图像的重构,同时,为了耦合了两个自动编码器的学习添加了一个特征映射在高清域和低清域之间迁移知识,最后在低清重构的输出层上学习行人间的区分性特征,进行行人重识别。本文的主要工作如下:
针对模型构建,在已有的耦合边缘化自动编码器中,使用了高清矩阵和低清矩阵的依赖关系,重新建立了模型的迭代优化学习方案,同时引入低清重构的权重,使模型更有利于解决行人重识别问题。
在基于patch特征的模型构建中应用显著性方法进一步优化性能,并将优化后的patch模型和基于image特征构建的模型进行融合。实验结果表明,融合后的模型行人匹配性能得到比较明显的改进,在VIPER数据集上, rank1达到了 22.78%,取得了较好的结果。
基于Java Swing实现了行人匹配的可视化展示,对于每个待查询行人,我们将展示检索库中与其最相近的前21个行人图像,同时标记正确的行人图像。
关键词:行人重识别;跨域多视角;耦合边缘化自动编码器
Abstract
Person re-identification, aimed at recognizing images of same person from various cameras at different locations. The use of computer vision and machine learning methods for person re-identification can effectively help workers quickly find and track target person in massive videos, such as lost children, the elderly, and suspects. This dissertation focuses on the specific issue of cross-view and different resolutions of pedestrian images. We use Coupled Marginalized Auto-Encoders for cross-domain multi-view learning.
Coupled Marginalized Auto-Encoders designs two Marginalized Auto-Encoders for the reconstruction of low-resolution person images and high-resolution person images. To better couple the two denoising auto-encoders learning, they incorporate a feature mapping, which tends to transfer knowledge between the high-resolution domain and low-resolution domain. Finally, they learn more discriminative features on the output layer of low-resolution domain to solve person re-identification problem. The main work is as follows:
For the model construction, based on the existing Coupled Marginalized Auto-Encoders, the dependence relationship between the high-resolution matrix and the low-resolution matrix is used to re-establish the model's iterative optimization learning scheme. At the same time, the weights of the low-resolution reconstruction are introduced, and the model is more conducive to achieving pedestrian fine-grained classification.
In addition, we apply salience methods on the patch-based model for further performance optimization. The optimized patch model and image model are merged to get the final score of each pair of person. The experimental results show that the merged model's pedestrian matching performance has been improved significantly. On the VIPER dataset, Our Rank1 reached 22.78%, and achieved good results.
Finally, we made a visual display of the matching results based on Java Swing. For each pedestrian to be queried, we will display the first 21 pedestrian images closest to it in gallery and mark the correct pedestrian image.
Key Words: Person re-identification; cross-domain multi-view; coupled marginalized automatic encoder;
绪论
1.1 背景
不论是走失儿童或老人的搜寻还是犯罪嫌疑分子的追踪,监控系统都给我们的生活带来极大的便利。但是在实际搜寻过程中,由于涉及的监控摄像头数量多且每个摄像头拍摄的视频量大往往需要耗费大量的人力和物力,因此很容易错过搜寻的最佳时机。
2018年5月,一名12岁小学生上学后迟迟未归,其父母向派出所报警求助。禅城公安共8名警力,调取了孩子家到学校一路的大量视频监控,但视频只能看到孩子离家后进入了一条小路,之后就再没有看到他的身影。监控视频不重叠性(非连贯性)及分岔路口搜索方向的多样性都将导致搜索范围扩大,搜索难度增大。在实际的儿童失踪案件中,各路口监控视频无重叠信息同时需处理的视频数据量巨大都是常见的问题,随着搜索时间变长,搜索难度指数式增长,儿童找回率也急剧降低,儿童的生命安全很可能受到危害。行人重识别问题即是从非重叠的摄像机视域的视频序列中匹配识别行人目标的问题,高效地解决该问题将能有效地帮助人们在海量视频中发现、追踪目标,将产生非常重要的现实意义。
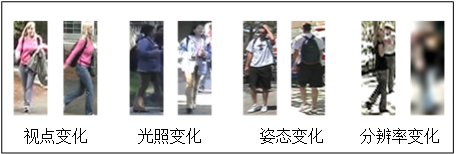 对于犯罪嫌疑人的追踪,以震惊全国的南京“1.6”银行枪击案为例,南京公安机关案发后不久就调集了5000名警力查看了数以万计遍布整个南京城的监控视频路线,经过两个月的排查才找到了与犯罪嫌疑人相关的近330段视频。不难发现,完全依赖于人工浏览的视频侦查方式不仅耗时费力而且完全不能满足公安高效的业务需求。自动地对特定嫌疑目标进行检索、分析、比对在视频侦察过程中已经成为亟待解决的重要课题。
对于犯罪嫌疑人的追踪,以震惊全国的南京“1.6”银行枪击案为例,南京公安机关案发后不久就调集了5000名警力查看了数以万计遍布整个南京城的监控视频路线,经过两个月的排查才找到了与犯罪嫌疑人相关的近330段视频。不难发现,完全依赖于人工浏览的视频侦查方式不仅耗时费力而且完全不能满足公安高效的业务需求。自动地对特定嫌疑目标进行检索、分析、比对在视频侦察过程中已经成为亟待解决的重要课题。
但是,行人重识别相对于通用图像检索具有其特殊性。如图1.1,在实际视频监控中,行人对象的画面质量较差、分辨率较低,而且还存在明显的视角、光照变化。行人姿势的变化等也对行人重识别问题产生很大影响,在不同监控摄像头中,不同行人对象的图像视觉特征可能比同一个行人对象的视觉特征更相似。为了解决非限定条件下的行人重识别问题,我们必须考虑更复杂的行人重识别情景,以满足实际视频侦查需求。
图1.1 行人重识别研究难点
1.2 目的及意义
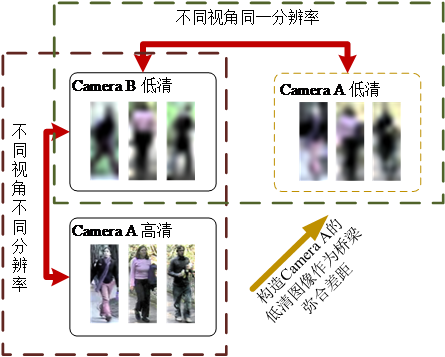
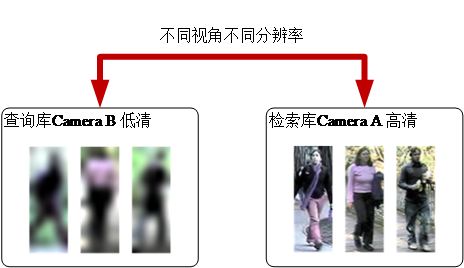
为了尽可能拟合实际生活中可能遭遇的情形,我们将试图解决行人图像具有多视角变化,多分辨率变化的行人重识别问题。如图1.2,检索库图像是来自Camera B的高清图像而待查询图像是来自Camera A的高清图像。
图1.2 跨分辨率行人重识别
解决以上问题的行人重识别技术将更有利于其在实际生活中的应用。随着检索准确率检索速度的提升,行人重识别技术将更可能像人脸识别技术一样被投入实际应用中,节约人力物力的同时提高搜索效率,在更短的时间找到搜寻目标。
1.3 国内外研究现状
用于解决行人重识别问题的研究工作主要集中于行人表达和距离度量两个方面。前者提取行人图像的视觉特征,进而表达行人对象。后者利用大量标记样本学习得到查询行人图像和检索库行人图像之间的距离度量函数。
- 特征表示
Farenzena M 等人提出构建一种有利于在各种相机中识别不同行人的区分性视觉描述[11]。他根据行人对象上下不对称性和左右对称性提出进行多特征累积、组合多种颜色、纹理特征来表达行人。Gray D等人提出局部化特征集合 (Ensemble of Localized Features, ELF)来适应视点不变行人重识别[3]。Zhao R提出了一种基于无监督显著学习的行人重识别新视角,他将人类识别方面的显著性纳入到行人表达中以提高行人重识别的准确性[4]。
- 距离度量
距离度量的目标是通过使用一组已标记的训练数据学习到适当的度量函数。大多数距离度量方法可以总结为学习一个统一的马氏度量矩阵 M,然后用这个矩阵 M 来计算不同行人图像特征之间的距离,最后得到图像的排序结果[22]。
Wang Z在统一距离度量的基础上考虑了行人重识别的零样本和细粒度特征,研究了两个摄像机间的交叉视图支撑一致性和交叉视图投影一致性。提出了一种数据驱动的距离度量(Data-Driven Distance Metric, DDDM)方法,利用训练数据个性化了每个查询图库对的度量[21]。
特性复杂化后,针对分辨率不同这一具体问题,2015年,在Jing X Y超分辨率重建研究的影响下[12],Wang S提出了半耦合字典(Semi-Coupled Dictionary Learning, SCDL)模型,有意识地发现低清和高清图像特征之间的关系并将低分辨率图像上转换为高分辨率图像[13]。SCDL模型同时学习了一对字典和一个映射函数,其中字典对可以很好地表征两种风格图像的结构域,而映射函数可以揭示两种风格域之间的内在联系。在SCDL模型中两个字典不会完全耦合,因此可以为映射函数提供很大的灵活性以便跨分辨率进行精确转换。
如何将低分辨率查询图像与高分辨率图库图像进行匹配可视为跨领域学习问题。目前存在多种跨领域学习的技术,包括特征自适应学习、分类器自适应学习和字典学习。其中,特色自适应学习旨在寻求一个共同的特征空间,在这个特征空间中域分歧将会降低[16]。分类器自适应学习旨在训练一个域的分类器,然后再适应另一个域[17]。字典学习旨在建立一个或两个字典作为基础,为两个领域产生更多的判别特征[18],SCDL即属于字典学习。最近,深度学习也在相关应用中引起了很大关注,其目的在于构建深层结构以捕获更具分辨性的信息[19]。这些跨领域学习技术都旨在寻找一个共同空间,在这个空间中域转移被减轻。但是行人重识别有其根本性存在的视角变化问题等,分布差异涉及多个因素。为此Wang S提出耦合边缘化自动编码器方法,添加一个中间域,检索库图像的低清版本,作为桥梁帮助解决学习问题[2]。
1.4 课题研究内容
在本文中,我们应用耦合边缘化自动编码器方法解决跨域多视角行人重识别问题,建立针对行人重识别的模型构建方案同时添加低清重构参数以灵活调整模型的整体倾向,基于patch模型进行显著性优化,将基于patch的模型与基于image的模型融合得到最终模型,匹配结果由基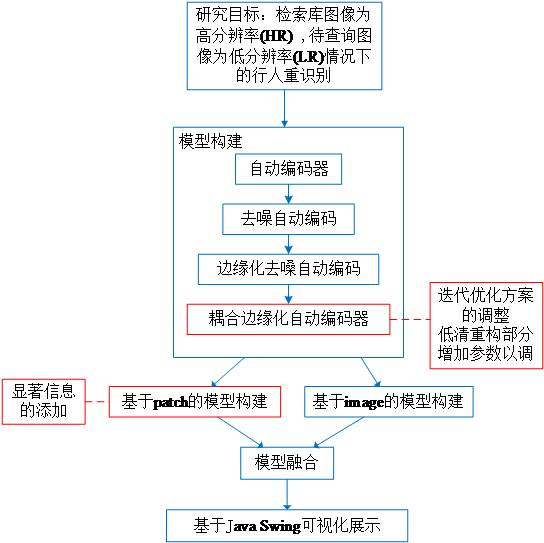 于Java Swing的系统可视化展示。
于Java Swing的系统可视化展示。
图1.3 技术路线图
针对行人重识别问题的耦合边缘化自动编码器框架
本章我们将详细介绍耦合边缘化自动编码器模型框架,同时我们使用了高清矩阵和低清矩阵之间的依赖关系,重新建立了模型的迭代学习方案,引入低清重构的权重使模型更有利于解决行人重识别问题。
2.1 耦合边缘化自动编码器
耦合边缘化自动编码是在自动编码器、去噪自动编码器、边缘化去噪自动编码器的发展基础上构建的。在本章中我们将依次介绍自动编码器、去噪自动编码器、边缘化去噪自动编码器、耦合边缘化去噪自动编码器及它们之间的发展关系。
1. 自动编码器
1986 年Rumelhart 提出了自动编码器的概念,并将其用于高维复杂数据处理促进了神经网络的发展。自编码神经网络是一种无监督学习算法,它使用了反向传播算法让目标值等于输入值,相同的输入和目标框架使隐藏层中的神经元成为输入数据的标识保留表示。
给定维输入视觉描述符,自编码器包含两个转换:
“输入-gt;隐藏单元h”和“隐藏单元-gt;重构输出”作为编码器和解码器。
(2.1)
其中是一个维矩阵,并且 是偏移矢量。是非线性激励函数。
传统上,自动编码器被用于降维或特征学习,它被认为是具有单隐层的基本构建块以构成深层结构[5]。
- 去噪自动编码器
去噪自动编码器(Stacked Denoising Autoencoders, SDA)通过从部分损坏的输入重建干净输入来训练其具有去噪能力[6]。他们探索了一种基于堆叠去噪自动编码器的深层网络的策略,这些自编码器在本地进行了训练,使其可以对输入的损坏版本进行去噪。SDA最终的算法是普通自动编码器堆叠的直接变体。它显著降低了分类错误并且以纯粹的无监督学习的方式进行更高层次的表示也有助于提高随后的支持向量机(Supported Vector Machine, SVM)分类器的性能。定性实验表明,与普通自动编码器比,SDA能够从自然图像patch中学习Gabor类边缘检测器。这项工作证明了使用去噪标准作为易于处理的无监督学习目标有利于获得更高层次的表示。
- 边缘化去噪自动编码器
然而,由于非线性优化,SDA存在严重的局限性,它的计算成本很高。为此,Chen M提出边缘化自动编码器(Marginalized Denoising Auto-encoders, mDAE),它用线性转换矩阵来替代编码器和解码器[7]。公式如2.2,其中是的含噪声样本。
(2.2)
它解决了SDA的两个关键限制:计算成本高和缺乏高维特征的可伸缩性。与SDA相比,mDAE方法可以消除噪声,因此不需要随机梯度下降或其他优化算法来学习参数。事实上,由于mDAE是以封闭形式计算的,只要20行MATLAB就可以实现的mDAE将SDA显著提速了两个数量级。此外,mDAE获得的表示与传统的SDA一样有效,在基准任务中获得几乎相同的准确度。
- 耦合边缘化去噪自动编码器
为了使提出的模型更加灵活,比较之下,Wang S仍然保留编码解码步骤,但是采用了一种线性化的方式,如2.3:
(2.3)
其中,是的破坏版本。我们可以把当作编码步骤,当作解码步骤。为了降低方差,mDAE将m次损坏版本的平方损失最小化:
(2.4)
其中,是的第j个损坏版本,定义,是它的m次重复版本,是它的损坏版本。公式(2.2)可以被制定为:
(2.5)
具有普通最小二乘的封闭形式解。
耦合关系将在两个mSDA的隐藏层间被构建。具体的耦合边缘化自动编码器模型将在下一节详细介绍。
2.2 针对跨域多视角行人重识别问题的模型
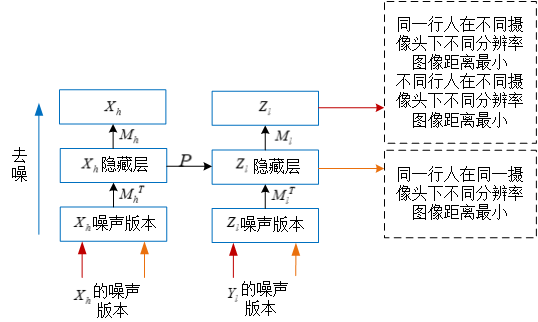
Wang S提出了一种耦合边缘化自动编码器框架来解决跨域多视角问题。具体来说,他们设计了两个mSDA 分别用于高清图像和低清图像的重构。为了更好的耦合两个mSDA的学习加入了一个特征映射,用来在高清域和低清域之间迁移知识。此外,输出层上的最大间距准则,即类内相似性和类间相异性,被用于在不同的域上以学习具有更多区分性的特征。
针对跨视角且分辨率不同的行人重识别问题,具体来说,检索库是来自Camera A的高清图像,查询库是来自Camera B的低清图像。我们可以简单的通过对来自摄像头A下的图像进行采样来获得与检索库相似分辨率的中间集(图 2.1),该中间集和Camera A有相同的视角。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: